本文主要是介绍An Optimistic Perspective on Offline Reinforcement Learning(ICML2020),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Abstract
\quad 该文章利用了 the DQN replay dataset 研究了Offline RL,该数据集包含了一个 DQN agent 在60款Atari 2600游戏上的 the entire replay experience 。
\quad 我们证明了 recent off-policy deep RL 算法,即使仅仅在 replay dataset 上训练,表现也比训练好的 DQN agent 要好。
\quad 为了增强 offline setting 的泛化能力,我们提出了 Random Ensemble Mixture (REM) ,一个鲁棒的 Q-learning 算法。
\quad 在 the DQN replay dataset 上训练的 offline REM 超过了 Strong RL baselines。这个结果给我们提供了一个乐观的观点,即在 sufficiently large and diverse offline datasets (大、多样化)上训练的 RL算法可以产生高质量的策略。
提出一种基于基于DQN replay dataset的offline强化学习算法。用Random Ensemble Mixture (REM)一种更加鲁棒的Q-Learning算法增强模型的泛化能力。
论文背景
\quad 离线强化学习,19年左右,有不少大佬都讨论过,普遍的观点都是:不靠谱,性能不够好。
\quad 完全不交互,全靠之前采集的数据集,训练一个RL模型,听起来就不是那么的靠谱。实际上面临主要几个问题:
- 数据集的多样性必须得保证,然而随机动作和单一策略擦采集到的数据,都会面临数据质量比较差的问题。
- 数据集的分布得尽量一致,由于离线强化没有在线交互,如果离线的数据分布和真实的数据分布不一致,那就直接凉凉。
- 强化算法对离线数据的利用效果要比较好。其中DQN和DDPG(正是前人常用的两个算法,)的利用效果就不是很好,我觉得主要是这两个算法本身就不稳定。
\quad 至于结果的话,直接挂两张图就好了:可见,虽然同样的DQN,离线的打不过在线的,但是我换成了厉害的QRDQN,那么离线的QR-DQN就能打败在线的DQN。其实已经很不容易了~
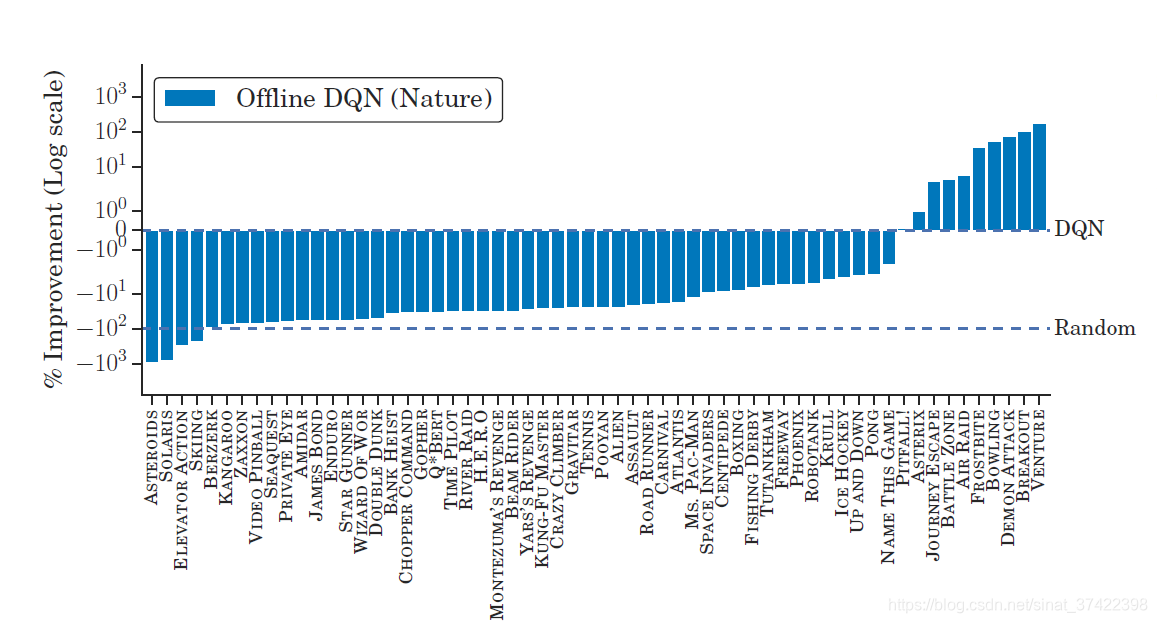
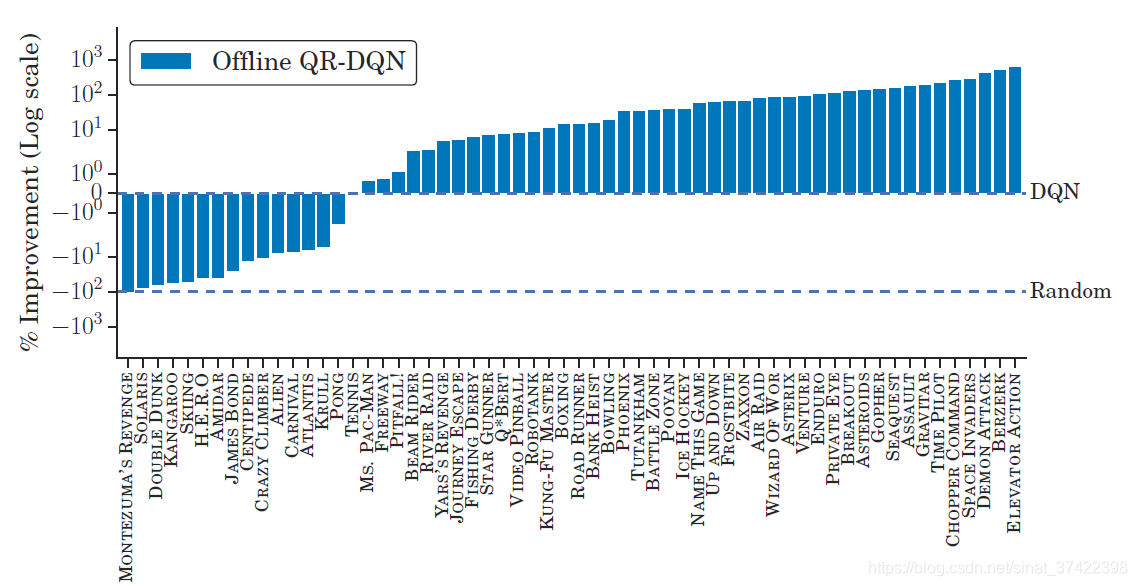
\quad Offline RL的问题在于当前策略和收集Offline Data的策略不匹配问题,策略不匹配导致的问题就是采取非相同的动作,并不知道奖励应该给多少。这篇文章就是想要验证在offline data上训练智能体,能不能不修正策略之间的分布差异也能够学地很好。
意思就是:
- 同样的设置、同样的算法、同样的数据,离线的都会比在线的差;
- 但是面对没法交互的任务怎么办呢?那就好好调调算法,换一个比较好的 offline RL 算法其实效果还是很好的。
- 然后文章给出了一个提高 offline RL 鲁棒性的算法 —— REM
4 Developing Robust Offline RL Algorithms
\quad 在一个在线的RL设置中,agent可以从环境中获取on-policy数据,这保证了一个良性循环,agent选择它认为会带来高回报的行为,然后收到反馈纠正其错误。由于在离线RL设置中不可能收集额外的数据,因此有必要使用固定的数据集进行泛化。 我们研究是否可以设计一个robust RL算法能够提高在 offline setting 中的泛化能力。 在有监督学习中, Ensembling (集成) 是一种常用的改进泛化方法。 本文研究了两种 deep Q-learning ,采用Ensemble DQN 和 REM 算法来提高稳定性。
重点 —— 所采用的的方法:
提出两个deep Q-learning算法Ensemble DQN和REM,使得其自适应集成,改善稳定性。data的收集来自大量混合策略。
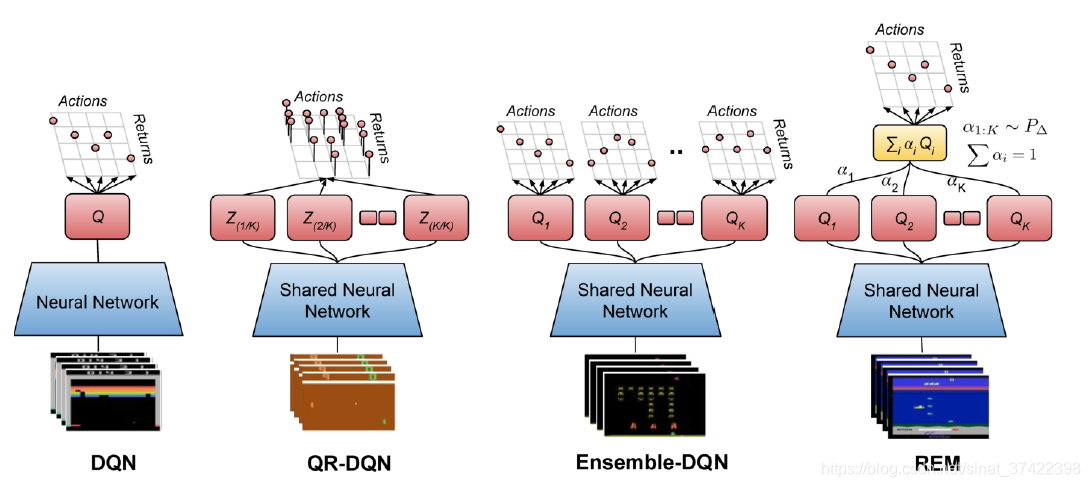
4.1 Ensemble-DQN
\quad Ensemble-DQN 是 DQN 的一个简单地扩展,通过 an ensemble of parameterized Q-functions 来近似计算 Q-values。每一个 Q-value 的计算有两个网络: Q θ k ( s , a ) Q_{\theta}^k(s,a) Qθk(s,a) 和 对应的 target 网络 Q θ ′ k ( s , a ) Q_{\theta '}^k(s,a) Qθ′k(s,a) 。Q-functions 使用 相同的 mini-batches 按照固定的顺序进行优化,初始化用不同的参数进行初始化。损失函数为:
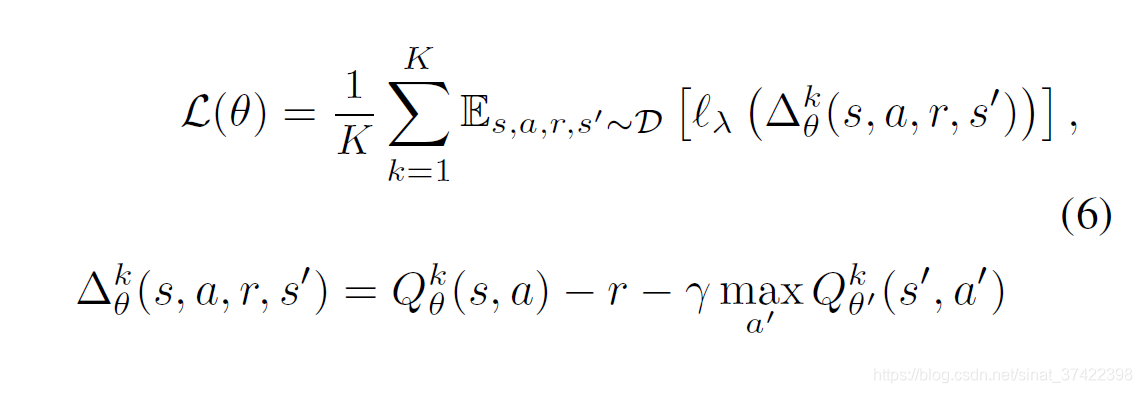
\quad 其中, l λ l_{\lambda} lλ 是 Huber loss:PJ Huber. Robust estimation of a location parameter. Ann. Math. Stat., 1964.

\quad 虽然 每个 episode 中 Bootstrapped-DQN 只利用了 Q-value 估计值 中的一个来进行探索。在 offline setting 中,动作选择采用最大
我们只关心 Ensemble-DQN 有没有更好的 exploit 能力 以及 利用 Q-value 的均值进行 evaluation 的能力。
意思就是:
\quad 将 K 个 近似器取平均。最小化K个近似器的平均 TD error。
4.2 Random Ensemble Mixture (REM)
\quad 如何高效的 在指数数量级的 Q-estimates 利用 ensemble。
\quad 受到 dropout 的启发,提出 Random Ensemble Mixture (REM), 类似于 Ensemble-DQN 使用 multiple parameterized Q-functions 来估计 Q-values。REM 的关键是:用多个 Q-value 的估计值的图组合 来作为 Q-value。利用不动点理论,所有的 Q-value 都会收敛到同一个 Q-function。这样子,我们训练了一批 Q-function 近似器,这些近似器利用加权概率((K - 1)-simplex 上的概率)进行组合。
\quad 就是, REM是将多个Q值组合成一个Q值的估计,因此Q函数近似为(K − 1)个采样的混合概率。
\quad 具体的,对于每一个 mini-batch,我们随机的定义一个分布 α \alpha α,定义了K个估计的图组合来近似Q-function。这个近似器针对其相应的目标进行训练,以使TD误差最小化。loss函数如下所示:

\quad 其中, P Δ P_{\Delta} PΔ 表示 (K-1)个采样所得到的概率分布, Δ K − 1 = { α ∈ R K : α 1 + α 2 + . . . + α K = 1 , α k > = 0 , k = 1 , . . . , K } \Delta^{K-1} = \{\alpha \in \mathbb{R}^K:\alpha_1 + \alpha _2 + ... +\alpha_K = 1,\alpha_k>=0,k=1,...,K\} ΔK−1={α∈RK:α1+α2+...+αK=1,αk>=0,k=1,...,K}。
意思就是:
\quad 给K个近似器加上了可调节权重,换了个聚合的方式。
为了证明“随机”的重要性,论文里还加了一个 Averaged Ensemble-DQN (Oron Anschel, Nir Baram, and Nahum Shimkin. Averaged-dqn:Variance reduction and stabilization for deep reinforcement learning. ICML, 2017.) ,然后结果果然没有随机的好:

Averaged Ensemble-DQN


这篇文章中,用了历史的K个Q网络作为K个Q-value估计器(通过对先前学习的Q值进行平均,平均值降低了目标近似误差方差,从而提高了稳定性并改善了结果),与我们的直接随机初始化K个不同的Q-value估计器不同。


一句话总结:
Offline RL可以通过好好调整算法(主要是增加数据集的多样性),来提高算法的稳定性,从而实现与普通 online RL 一样好or更好的效果。
创新点 和 贡献
- 提出了一个随机集成混合REM的DQN算法
- 做了大量的实验,证明离线训练时,标准RL对连续控制任务无效。但是,作者发现,当对大型多样的离线数据集进行训练时,最近的连续控制代理(例如TD3)的性能与复杂的离线RL相当。(工作量很恐怖)
6 Important Factors in Offline RL
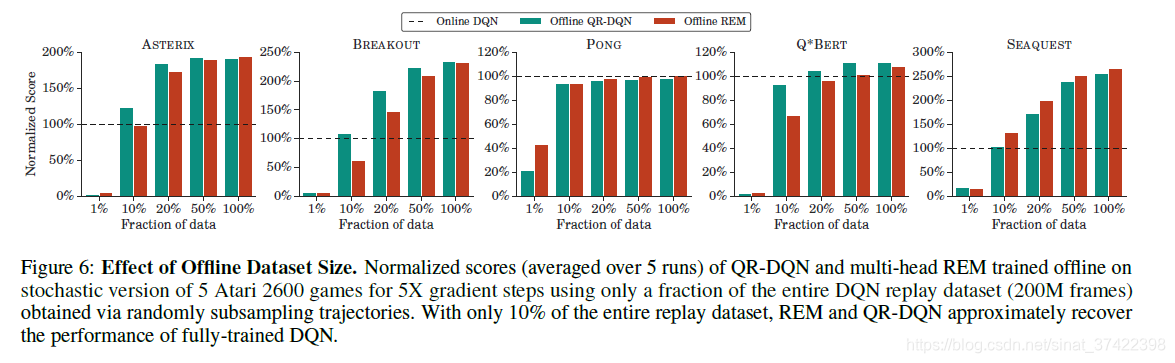
数据量越大越好
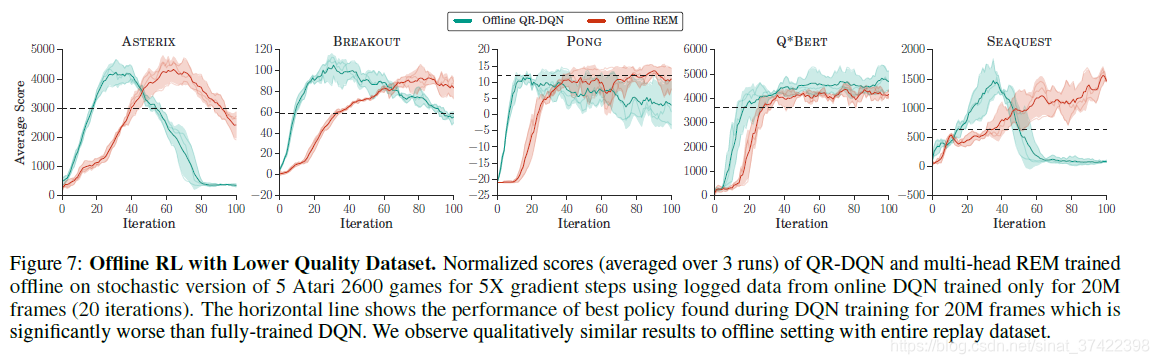
数据质量问题。该实验的 Offline data是使用仅仅训练了20轮的DQN生成的。
7 Related work and Discussion
Batch-RL
\quad 其定义是RL算法在一个固定的经验池中进行学习。在该问题下比较典型的应用是模仿学习( Imitation learning). 在模仿学习中,给定专家采集的样本作为一个经验池,RL算法从该经验池中学习,而不直接与环境进行交互。
作者的方案
1、提高数据的多样性 — 利用五个不同随机种子的DQN采集。
\quad 深度强化学习非常不稳定,同样的网络结构,就因为随机种子的原因,就能提高样本的多样性。
2、测试不同的算法对离线数据的利用效率,可以发现REM的利用效果最好。
3、同时验证了连续控制,TD3对离线数据的使用效果也不错:

第一张图TD3明显比BCQ好,第23,就不好说了,二者波动性那么大,随机种子的挑选就是一个很微妙的事情。
离线强化学习,借用强化的模型壳子,利用大量有监督学习的数据,获得比模仿学习、有监督学习,在线强化等,更好更快的性能。
参考:https://blog.csdn.net/hehedadaq/article/details/107549419
这篇关于An Optimistic Perspective on Offline Reinforcement Learning(ICML2020)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









