本文主要是介绍【2024 行人重识别最新进展】ReID3D:首个关注激光雷达行人 ReID 的工作!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【2024 行人重识别最新进展】ReID3D:首个关注激光雷达行人 ReID 的工作!
- 摘要:
- 数据集:
- 方法模型:
- 多任务预训练:
- ReID Network:
- 实验结果:
- 结论:
来源:Arxiv 2023
机构:清华大学 & 北京理工大学
论文题目:LiDAR-based Person Re-identification
本文是首个基于激光雷达的人ReID的工作,展示了在具有挑战现实世界的户外场景中,利用激光雷达进行的行人 ReID 的实用性!
论文链接:https://arxiv.org/abs/2312.03033
开源代码:https://github.com/GWxuan/ReID3D
摘要:
基于摄像头的重识别(ReID)系统在公共安全领域得到了广泛的应用。然而,摄像机往往缺乏对人类三维形态信息的感知,并且容易受到各种限制,如照明不足、背景复杂和个人隐私,如图:

在本文中,我们提出了一种基于激光雷达的 ReID 框架,ReID3D,该框架利用预训练策略来检索三维体型的特征,并引入了基于图的互补增强编码器来提取综合特征。由于缺乏激光雷达数据集,我们构建了第一个基于 LiDAR 的行人 ReID 数据集 LReID,该数据集在几个自然条件变化的室外场景中收集。
此外,我们还介绍了 LReID-sync,一个模拟的行人数据集,设计用于具有点云完成和形状参数学习任务的预训练编码器。在 LReID 上的大量实验表明,ReID3D 取得了卓越的性能,准确率为 94.0%,突出了激光雷达在处理行人重识别(ReID)任务方面的显著潜力。
数据集:
据我们所知,本文首次介绍了基于激光雷达的人ReID的研究。我们构建了 LReID,第一个基于激光雷达的 ReID数 据集,以促进利用激光雷达点云对行人 ReID 的研究。我们使用多个收集节点在几个室外场景中收集数据集,每个节点包括一个激光雷达和一个工业摄像机。LReID 数据集提供了几个独特的特点:
- 真实场景:该数据集是在室外场景中捕捉到的,行人表现出自然行为,导致行人之间的遮挡,以及存在动态物体,如车辆和自行车,可能会影响人的 ReID;
- 数据多样性:LReID 包含在不同季节、时间和光照条件下收集的 320 名行人的动态数据和注释,总计 15.6 万帧点云和图像,从而能够全面分析不同因素对行人 ReID 的影响;
- 精密度:Livox Mid-100激光雷达的距离精度为 2 cm 和角精度为 0.1°,为 ReID 问题提供了高精度的三维结构信息。
与公开的 3D 数据集对比:

下图显示了从不同的场景中收集到的两个行人的样本:
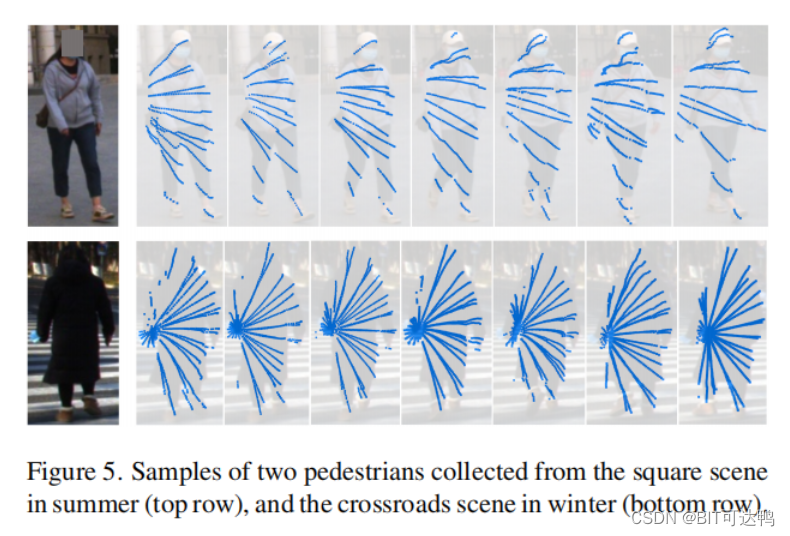
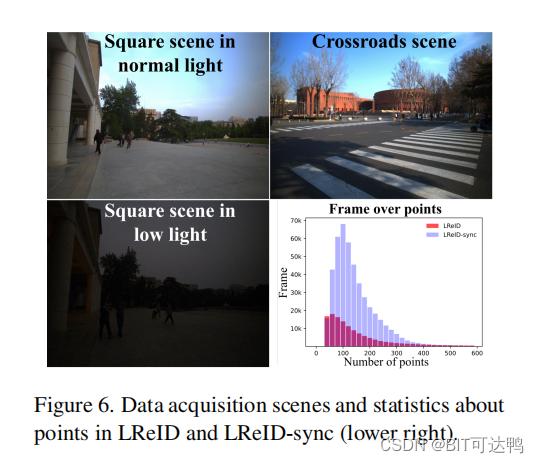
LReID 收集了两个广泛的户外场景:一个十字路口和一个建筑前的一个广场,捕捉不同的时间周期和天气条件,如图所示:
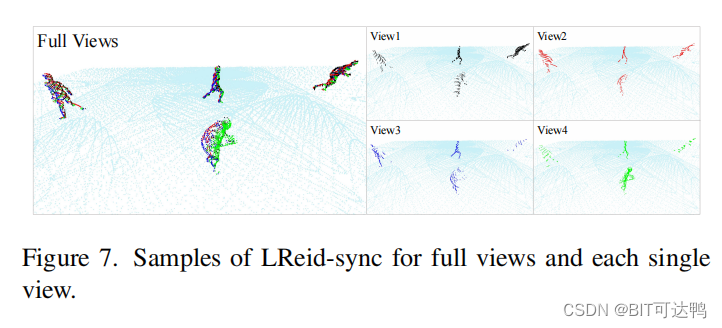
此外,我们还引入了一个模拟数据集,名为 LReID-sync,包括 360,000 帧的点云,用于由多视图同步激光雷达捕获的 600 个行人。LReID-sync 包括从单个视图到全视图的点云注释以及 SMPL 参数。LReID-sync 是使用 Unity3D 软件生成的一个新的行人数据集,它模拟了多个同步激光雷达从不同视图捕获的场景中的行人,如图所示:
方法模型:
基于点云,行人的识别依赖于他们的静态人体测量特征,包括身高、体型、肢体结构,以及他们的动态步态特征。准确地提取完整的行人形状特征对这两个方面都是有益的。为了解决这个问题,我们提出了一个有效的基于激光雷达的框架,称为 ReID3D。ReID3D 利用一种训练前策略来指导编码器学习基于 LReID-sync 的三维身体特征。此外,为了提取行人的区分静态和动态特征,ReID3D 的 ReID 网络包括一个基于图的互补增强编码器(GCEE)和一个时间模块。对LReID进行的大量实验证明了以下几点:
- ReID3D 的性能优于最先进的相机处理方法,特别是在弱光下,突出了激光雷达在处理个人ReID任务方面的显著潜力;
- 使用 LReID-sync 进行预训练,显著提高了模型的特征编码能力;
- 与常用的点云编码器相比,我们的 GCEE 在提取全面和鉴别特征方面表现出更强的能力。
多任务预训练:
根据我们的观察,可能影响ReID模型性能的关键因素是:1)在交叉视图设置下由不同观点导致的信息变化,以及 2)单视角导致的不完整的信息。此外,真实数据的收集和注释成本较高,而模拟数据的成本较低,且注释丰富、准确。
因此,我们利用模拟数据对编码器进行点云完成和 SMPL 参数学习任务的预训练。我们提出的预训练方法的总体思想如图所示,这使编码器能够有效地提取人体测量特征,并减轻视点差异的影响:
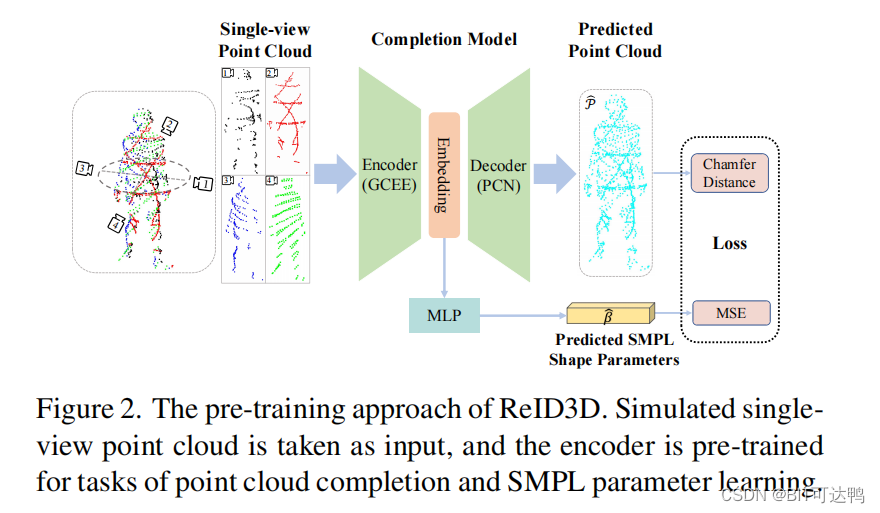
ReID Network:
为了从点云序列中提取时空特征,ReID3D 的 ReID 网络包括一个 GCEE,它由一个GCN主干和CFE组成,以及一个时间模块,如图所示:
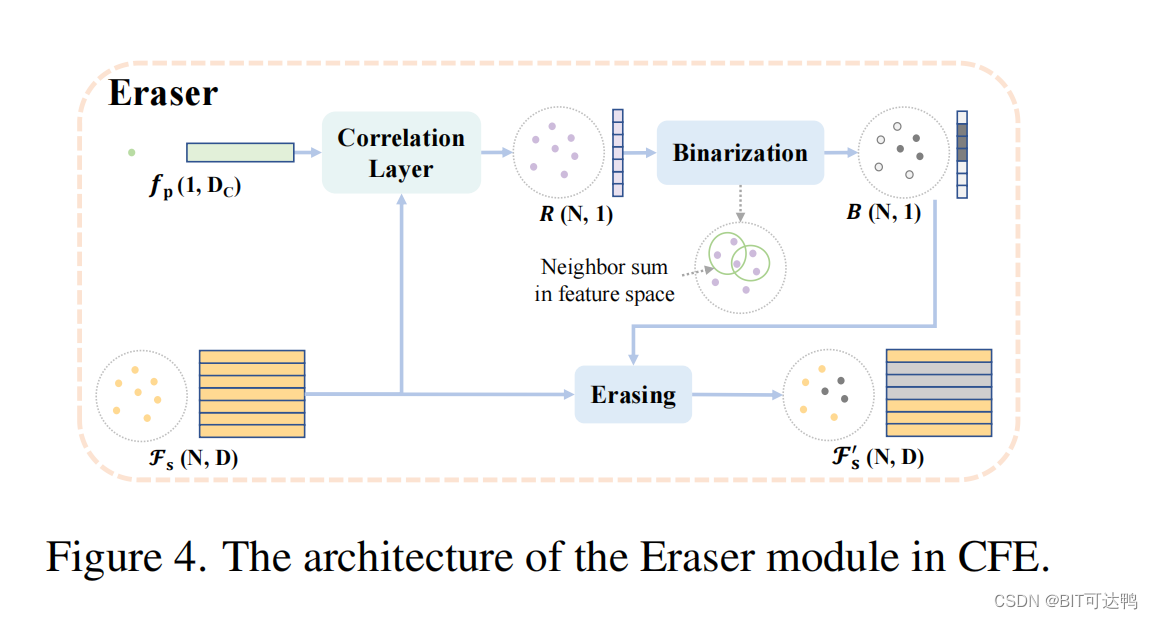
实验结果:
比较结果见下表:
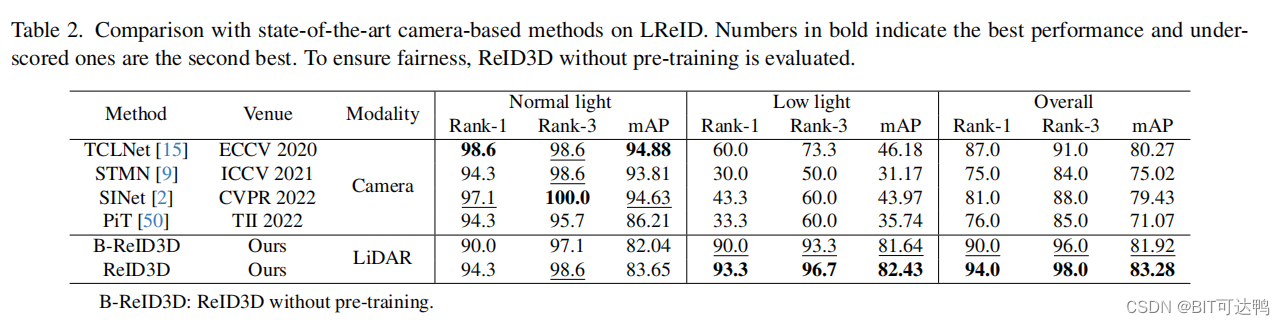
可以得到几个结论:
- ReID3D 和 B-ReID3D(不采用预训练)优于基于视频的方法,主要得益于点云的利用,而点云不受光照条件和复杂背景的影响;
- 此外,ReID3D在整体和低光条件下取得了最先进的结果,但在正常光照条件下,它落后于基于视频的方法。这是因为基于视频的方法在正常光线下充分利用了外观信息;
- 基于视频的方法在弱光下表现不佳,而 ReID3D 和 B-ReID3D 在弱光和正常光下都表现出相当的可靠性。
为了证明使用模拟数据集 LReID-sync 的预训练的有效性,我们评估了不同的预训练方法的性能。评估了以下四种方法:1)未经预先训练的ReID3D;2)采用类似的 ReID 任务进行预训练,其中预训练模型和损失与 ReID 网络一致;3)预训练,只使用点云完成的分支;4)进行多任务的预训练。
实验结果见表:
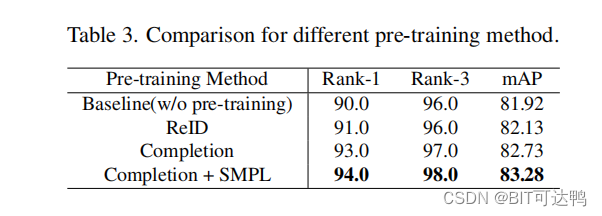
为了展示编码器通过预训练获得的鲁棒特征编码能力,我们将几个具有不同特征的真实行人点云的完成结果可视化,如图所示:
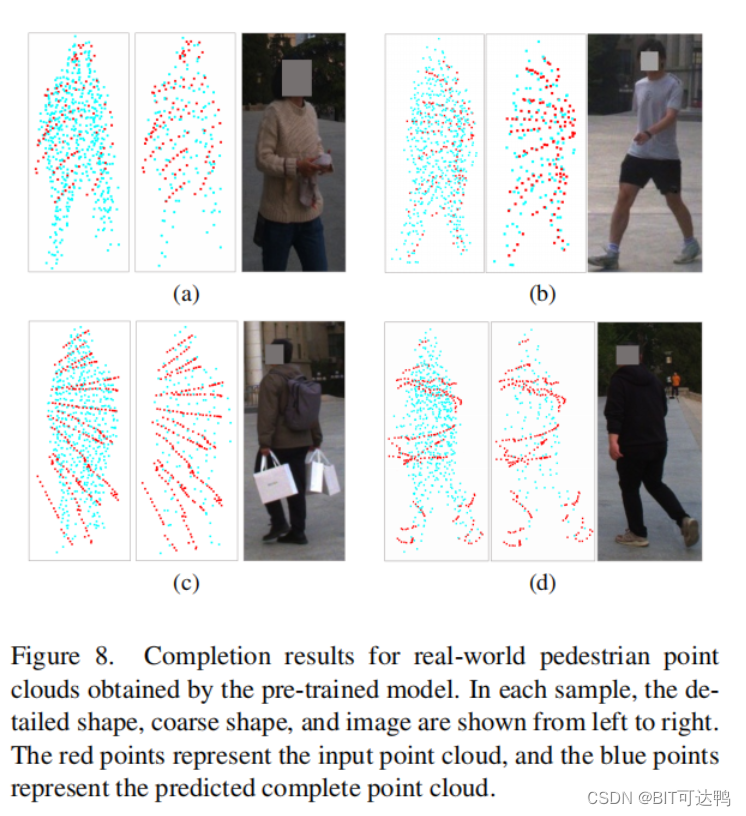
我们可以观察到:
- 从直观上看,其详细而粗糙的形状与实际的人体形状非常相似,这表明编码器已经成功地捕获了人体的完整特征;
- 详细形状是基于粗形状的扩展,具有更高的分辨率和更多的信息;
- 预先训练好的编码器有能力估计点云中缺失部分的特征。
结论:
本文首次利用激光雷达提供的精确三维结构信息对人ReID进行了研究。首先,我们提出了一个基于lidar的ReID框架,名为ReID3D,利用预训练指导基于图的互补增强编码器(GCEE)提取全面的三维内在特征。此外,我们建立了第一个基于激光雷达的人ReID数据集,称为LReID,它包含了320个在不同的室外场景和照明条件下的行人。此外,我们还引入了LReID-sync,一个新的模拟行人数据集,设计用于具有点云完成和形状参数学习任务的预训练编码器。我们提出的ReID3D在LReID上表现出了卓越的性能,突出了激光雷达在处理人员ReID任务方面的巨大潜力。
这篇关于【2024 行人重识别最新进展】ReID3D:首个关注激光雷达行人 ReID 的工作!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








