本文主要是介绍perceptron 感知机,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

感知器 Perceptron
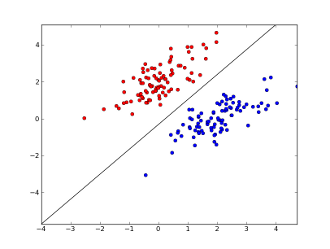
现在你看到了一个简单的神经网络如何做决策:输入数据,处理信息,然后给出一个结果作为输出!现在让我们深入这个大学录取的案例,来学习更多输入数据如何被处理。
数据,无论是考试成绩还是评级,被输入到一个相互连接的节点网络中。这些独立的节点被称作感知器 或者神经元。它们是构成神经网络的基本单元。每一个依照输入数据来决定如何对数据分类。 在上面的例子中,输入的评级或者成绩要么通过阈值 (threshold) 要么通不过。这些分类组合形成一个决策 - 例如,如果两个节点都返回 “yes“,这个学生就被学校录取了。

让我们进一步放大来看一个单个感知器如何处理输入数据。
上面的感知器是视频中来决定学生是否被录取的两个感知器中的一个。它决定了学生的评级是否应该被学校录取。你也许会问:“它怎么知道在做录取决定的时候是分数更重要还是评级更重要呢?”。事实上,当我们初始化神经网络的时候,是不知道那个信息对决定更重要的。这需要由神经网络 自己学出来 哪个数据更重要,然后来调整它如何使用那个数据。
它通过一个叫做Weights(权值)的东西来做这件事。
Weights(权值)
当数据被输入感知器,它会跟分配给这个输入的制定的 weights 相乘。例如,上面的感知器有两个输入,tests和 grades,所以它有两个与之相关的 weights,并且可以分别调整。这些权重刚开始是随机值,当神经网络学到什么样的输入数据会使得学生被学校录取之后,网络会根据之前 weights 下分类的错误来调整 weights,这也被称作是神经网络的训练。
一个更大的 weights 意味着神经网络认为这个输入比其它输入更重要,小 weights 意味着数据不是那么重要。一个极端的例子是,如果 test 成绩对学生录取没有影响,那么 test 分数的 weight 就会是零,也就是说,它对感知器的输出没有影响。
输入数据加总
所以,每个感知器的输入需要有一个关联的权重代表它的重要性,这个权重是由神经网络的学习过程决定的,也就是训练。接下来,经过加权的输入数据被加总,生成一个单独的直,它会帮助实现最终输出 - 也就是这个学生是否被录取。让我们看一个实际的例子:

我们把 x_test 跟它的权重 w_test 做点乘再与 x_grades 与w_grades 点乘的结果相加。
在写跟神经网络有关的公式的时候,权重总是被各种样式的字母 w 来表示。W通常表示权重矩阵,而w被用来表示单个权重。有时还会有些额外的信息以下标的形式给出(后面会见到更多)。记住你看到字母 w,想到权重是不会错的。
在这个例子中,我们用 wgrades 来表示 grades 的权重,wtest 来表示 test 的权重。在上图中,权重是 wgrades=−1,wtest =−0.2。你不用关注它们具体的值,他们的比值更重要。 wgrades 是 wtest 的5倍,代表神经网络认为在判断学生是否能被大学录取时, grades 的重要性是 test 的5倍。
感知器把权重和输入做点积并相加再加总的过程叫做 线性组合。在这里也就是
wgrades⋅xgrades+wtest⋅xtest=−1⋅xgrades−0.2⋅xtest.
为了让我们的公式更简洁,我们可以把名称用数字表示。用 1 来表示 grades,2 来表示 tests. 我们的公式就变成了:
w1⋅x1+w2⋅x2
在这个例子中,我们只有两个简单的输入。grades 和 tests。试想如果我们有 m 个不同的输入可以把他们标记成 x1,x2,...,xm。对应 x1 的权重是 w1 以此类推。在这里,我们的线性组合可以简洁的写成:
∑i=1mwi⋅xi
这里,希腊字母 Sigma ∑ 用来表示 求和。它意思是求解右边表达式,并把结果加总。也就是说,这里求了. wi⋅xi 的和。
但是我们从哪里找到 wi 和 xi?
∑i=1m 意思是遍历所有 i 值, 1 到 m。
这些都组合在一起 ∑i=1mwi⋅xi 表示:
- 求 w1⋅x1 并记住结果
- 让 i=2
- 求 w2⋅x2 的值并把它加到 w1⋅x1
- 重复这个过程直到 i=m, m 是输入的个数
最后,无论是我们这里还是你自己的阅读中,你都会看到公式有很多种写法。例如:你会看到 ∑i 而不是 ∑i=1m。第一个只是第二个的简写。也就是说你看到一个求和没有截止点,意思就是把它们都加起来。 有时候,如果遍历的值可以被推断,你可能会看到一个单独的 ∑。记住,它们都是相同的:∑i=1mwi⋅xi=∑iwi⋅xi=∑wi⋅xi
计算激活函数的输出
最后,感知器求和的结果会被转换成输出信号,这是通过把线性组合传给 激活函数 来实现的。
当输入给到节点,激活函数可以决定节点的输出。因为它决定了实际输出,我们也把层的输出,称作“激活”。
最简单的激活函数之一是单位阶跃函数(Heaviside step function)。如果线性组合小于0,函数返回0,如果线性组合等于或者大于0,函数返回1。 单位阶跃函数(Heaviside step function) 如下图, h 是线性组合的结果:


单位阶跃函数 Heaviside Step Function
在上面这个大学录取的例子中,我们用了 wgrades=−1,wtest =−0.2 作为权重。因为 wgrades 都是负值 wtest 激活函数只有在 grades 和 test 都是0的时候返回1。这是由于用这些权重和输入做线性组合的取值范围是 (−∞,0] (负无穷到0,包括0)。
用个两维的数据看起来最容易。在下面这幅图中,想象线上的任何一点以及阴影部分,代表所有可能对节点的输入。y轴表示对输入和合适的权重的线性组合的结果。这个结果作为激活函数的输入。
记得我们说过,单位阶跃函数对任何大于等于0的输入,都返回 1 像你在图中看到的,只有一个点的 y 值大于等于0: 就是 (0,0)原点:

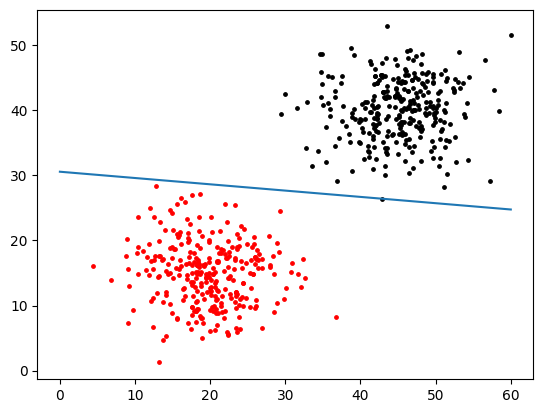
当然,我们想要更多可能的 grade/test 组合在录取组里,所以我们需要对我们的激活函数做调整是的它对更多的输入返回 1 特别是,我们要找到一种办法,让所有我们希望录取的人输入和权重的线性组合的值大于等于0。
使得我们函数返回更多 1 1 的一种方式是往我们线性组合的结果里加上一个 偏置项(bias)。
偏置项在公式中用 b 来表示,让我们移动一下各个方向上的值。
例如,下图蓝色部分代表先前的假设函数加了 +3 的偏置项。蓝色阴影部分表示所有激活的值。注意,这个结果的输入,跟之前灰色部分的输入是一样的,只是加了偏置项之后,它变得更高了。

现在,我们并不能实现知道神经网络改如何选择偏置项。但没关系,偏置项跟权重一样,可以在训练神经网络的时候更新和改变。增加了权重之后,我们有了一个完整的感知器公式:

Perceptron Formula
输入 (x1,x2,...,xm) 如果属于被录取的学生,公式返回 1 if the input (x1,x2,...,xm) 不被录取的学生,公式返回 0。输入是由一个或多个实数组成,每一个由 xi 代表,m 则代表总共有多少个输入。
然后神经网络开始学习!起初,权重 ( wi) 和偏置项 (b) 是随机值,它们用一种学习算法来更新。权重和偏置项的更新使得下一个训练样本更准确地被归类,数据中蕴含的模式,也就被神经网络“学”出来了。
现在你对感知器有了很好的理解,让我们把学到的只是予以应用。接下来,你将从之前神经网络的视频中来学习通过设定权重和偏置项来创建一个 AND 感知器。
这篇关于perceptron 感知机的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!