本文主要是介绍IEEE TASLP | 联合语音识别与口音识别的解耦交互多任务学习网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
尽管联合语音识别(ASR)和口音识别(AR)训练已被证明对处理多口音场景有效,但当前的多任务ASR-AR方法忽视了任务之间的粒度差异。细粒度单元(如音素、声韵母)可用于捕获与发音相关的口音特征,而粗粒度单元(如词,BPE)更适合学习语言信息。此外,两个任务的显式交互也可以提供互补信息并改善彼此的性能,但现有方法很少使用。
近期,由西工大音频语音与语言处理研究组(ASLP@NPU)和腾讯TEG合作的论文“Decoupling and Interacting Multi-Task Learning Network for Joint Speech and Accent Recognition”发表在语音研究顶级期刊IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP),该工作有效地解决了上述问题。
该论文提出了一种新颖的用于联合语音和口音识别的解耦交互多任务网络(DIMNet),它由一个CTC分支、一个AR分支、一个ASR分支和一个底层特征编码器组成。具体而言,AR和ASR首先通过分开的分支和双粒度建模单元解耦,以学习任务特定的表示。AR分支来自我们先前提出的语言-声学双模口音识别模型(LASAS)[1],而ASR分支是基于编码器-解码器的Conformer模型。然后对于任务交互,CTC分支为AR任务提供了对齐的文本,而从我们的AR模型中提取的口音嵌入整合到ASR分支的编码器和解码器中。最后在ASR推断过程中,引入了一种跨粒度的重评分方法,用于在解耦后融合来自CTC和注意力解码器的互补信息。在英文和中文数据集上进行的实验证明了DIMNet的有效性。相对于基线,分别实现了21.45%/28.53%的口音识别准确率相对提升和32.33%/14.55%的ASR错误率相对下降。

论文题目:Decoupling and Interacting Multi-Task Learning Network for Joint Speech and Accent Recognition
作者列表:邵琪杰,郭鹏程,颜京豪,胡鹏飞,谢磊
发表期刊:IEEE/ACM Transactions on Audio, Speech and Language Processing
合作单位:腾讯TEG
论文网址:https://arxiv.org/abs/2311.07062

图1 发表论文截图
图2 扫码直接看论文
1. 背景动机
口音(Accent)指的是受到说话人教育水平、所在地区或母语等因素影响而产生的发音变化。尽管近年来端到端语音识别(E2E ASR)取得了显著进展,口音仍然是语音识别中的重大挑战。多任务ASR-AR框架已成为克服多口音挑战的广泛解决方案[2-3]。该框架通常由共享编码器和分别专用于ASR和AR任务的两个分支组成。共享编码器负责从输入语音中提取声学特征,以供两个分支使用,并通过这两个分支的反向传播使共享编码器学习如何同时提取语言和口音表示。虽然已经证明在联合建模ASR和AR方面有效,但任务之间的粒度差异表明,同时通过共享编码器提取特征可能不是最佳策略。此外,ASR和AR分支缺乏足够的交互,阻碍了从对方分支中充分利用互补信息。
ASR和AR之间的粒度差异:E2E ASR是一项与语言相关的任务,通常使用像BPE或字这样的粗粒度单位,以更好地表示语言信息。相比之下,AR任务与发音密切相关,需要捕捉像音高、语调和重音这样微小的声学变化,因此更适合使用音素或音节这类细粒度建模单位。因此,将两种粒度的建模单位纳入多任务ASR-AR中更为合适。然而,这两种粒度单位的序列长度不一致,难以使用单个共享编码器同时进行编码。
用ASR改进AR:早期的AR模型直接提取诸如频率和音色等低级特征[2],往往会对说话者和信道特征的过拟合。我们之前的研究[1]提出了一种基于语言-声学相似度的口音偏移(LASAS)AR模型。为了估计带口音的语音话语的口音偏移,我们首先将帧级对齐的文本映射到多个与口音相关的锚点空间,然后利用声学嵌入与这些锚点之间的相似性作为口音偏移。与仅使用纯声学嵌入作为输入相比,LASAS额外使用了对齐文本作为第二种输入,这带来AR性能的显著提高,并且可以充分利用来自ASR的信息。
用AR改进ASR:口音信息也有助于语音识别。许多研究探索了使用补充的口音信息来提高口音语音的ASR性能。然而,不同类型的口音嵌入对ASR性能的影响可能会有很大差异。此外,口音信息与ASR的整合方式也有优劣之分。因此,有必要进行全面的研究,以评估每种方法的可解释性和对ASR分支的性能影响。
DIMNET:我们的目标是克服ASR和AR分支之间的“建模单元粒度差异”挑战,并促进它们“完全交互”。为了实现这一目标,我们提出了一种名为Decoupling and Interacting Multi-task Network (DIMNet)的联合语音和口音识别模型。该模型包括一个连接主义时间分类(CTC)分支、一个口音识别(AR)分支、一个语音识别(ASR)分支和一个底层特征编码器。具体来说,我们首先通过分开的分支和两种粒度的建模单元,将口音识别和语音识别解耦,以学习任务特定的表示。AR分支来自我们之前提出的LASAS口音偏移模型,而ASR分支则是基于编码器-解码器的Conformer模型。然后,为了实现任务交互,CTC分支使用与AR分支相同的建模单元进行优化,从而为AR提供对齐文本。与此同时,我们还从AR分支中提取的口音嵌入用于改进ASR分支。另外,我们还探索口音嵌入的选择和ASR分支的融合策略。最后,我们引入了一种支持双粒度单元的重打分方法,使得有明显互补性的CTC细粒度打分和ASR粗粒度打分可以融合,进一步提高了ASR的准确率。
2. DIMNet
2.1 解耦AR和ASR
如图3所示,本文提出的DIMNet模型以CTC/attention ASR模型作为骨干网络。此外,我们还结合了LASAS AR模型[1]和三个编码器,从而在DIMNet中形成了三分支结构。
-
三编码器结构:12层共享编码器+3层CTC编码器+3层ASR编码器,均使用Conformer结构,用于解耦粗细两种粒度的单元建模过程。
-
CTC分支:使用细粒度单元建模,例如音素或拼音,主要用于提取对齐文本序列给LASAS AR分支。
-
LASAS AR分支:以细粒度的对齐文本和共享编码器提取的声学嵌入来计算口音偏移,并负责为ASR分支提供口音嵌入。该分支需要使用detach切断与CTC分支和ASR分支的耦合,否则模型整体性能会有所下降。
-
ASR分支:经典encoder+decoder结构,但在encoder和decoder的输入上均拼接了口音嵌入。

图3 口音识别模型的系统结构示意图
2.2 用ASR辅助AR
传统的口音识别模型只利用声学特征作为输入,当它们被整合到多任务ASR-AR中时,它们与ASR任务的充分交互能力受到限制。我们近期提出了LASAS AR模型[1],该模型使用对齐的文本和声学嵌入作为输入。具体地,对于一个带口音的语句,映射其相应的对齐文本向量到口音相关空间作为一种基准,然后通过评估输入的声学嵌入和该基准的点积相似度,实现对口音偏移的度量。然后,本文将口音偏移和文本向量拼在一起,以获得语言-声学双模态表征。最后再以此表征进行口音分类。相比于纯声学嵌入,这种双模态表征充分利用了语言和声学信息,物理意义更加丰富和清晰,从而显著改善了口音分类性能。

图4 LASAS AR结构示意图
2.3 用AR辅助ASR
通过实验,我们对比了3种不同潜表征作为口音嵌入的效果:
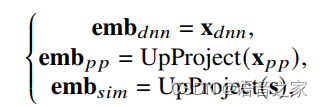
以及4种口音嵌入和ASR分支的融合方式:

2.4 双粒度重打分
在解耦AR和ASR之后,CTC解码器专注于发音,而Att解码器强调语言信息。通过利用这两种信息类型之间的互补性,预计双粒度重打分方法将比单粒度重打分方法实现更好的ASR性能。然而,目前主流的重打分方法需要两个解码器识别出的序列的长度相同,不适用于双粒度场景。因此我们引入了双粒度重打分。具体地,先使用Att解码器生成候选的粗粒度序列,并记录Att得分。然后使用词典将其映射成细粒度序列,并将其放在CTC Loss的label位置,即可获得CTC得分,最后再将两种得分相加,取最高分为最终输出。
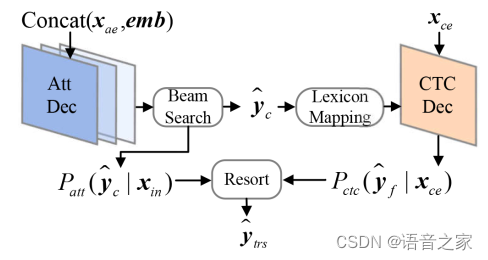
图5 双粒度重打分示意图
3. 实验配置
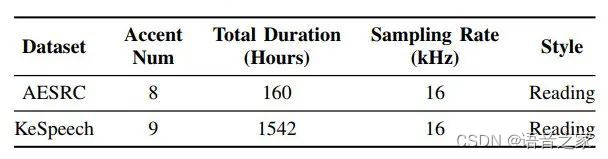
本文使用AESRC[5]英语口音挑战赛数据集和KeSpeech[6]中文口音数据集进行实验。数据集具体情况如表1所示。
表1 AESRC和KeSpeech数据集详情
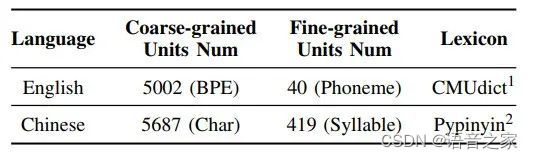
我们使用BPE-音素作为英语的两粒度建模单元,而对于中文则使用字-拼音。我们分别利用了CMUdict和Pypinyin词典。详情如表2所示。
表2 双粒度建模单元详情
4. 实验结果
4.1 DIMNet的有效性
实验结果如如表3所示。B1-B4是基线方案。其中,B1和B2之间的比较突显了双粒度单元的影响。在CTC/Attention框架中直接引入音素只能导致ASR性能略微提高。在整合了一个AR分支之后,B3的ASR性能相对于B2有所提高,这是一个被广泛验证的现象。将B4与B3进行比较,引入三重编码器结构仅对口音准确度产生了平均相对影响0.15%的微小改善,而它平均相对提高了ASR任务1.02%。D1-D13是DIMNet baseline及其消融实验,与B1−B4时,明显可以看出,DIMNet在AR和ASR方面都具有明显优势,即排除双粒度建模单元和多任务学习框架的贡献之外,DIMNet通过解耦和交互设计,相比传统方案存在显著优势。
表3 AESRC数据集上的消融和对比实验。emb指口音嵌入,AF指口音融合。G,P和B分别表示字素,音素和BPE 4.2 解耦AR和ASR
4.2 解耦AR和ASR
在D2和D3中,我们对比了建模单元对DIMNet的影响。比较D1和D2可以明显看出,与音素相比,字素具有语义相关性,但缺乏足够的发音信息。因此,它们无法有效地提高AR任务的性能,从而间接降低了ASR性能。当比较D1和D3时,明显可以看出,如果在CTC和Att分支中都使用粗粒度BPE单元,导致了性能显著下降。这一结果清楚地表明,即使使用相同的交互结构,解耦建模单元依然是提高AR和ASR性能的关键因素。此外,对比D4和D1则证明了如果没有三重编码器结构,使用两粒度建模单元会给ASR任务带来挑战。
4.3 用ASR辅助AR
通过比较D1和D5可以看出,如去掉从CTC分支中获得的对齐文本,将会对LASAS AR分支的准确性有重大不利影响,这一结果清楚地表明了来自CTC分支的语言信息对提高AR任务性能的重要性。D1和D6的比较则证明了AR分支的detach操作减少了AR任务对ASR任务的干扰,展示了AR分支分离操作在多任务ASR-AR中的重要性。
此外比较D7和D1,使用句级口音CE Loss可以增强AR任务的泛化能力并减轻过拟合。然而,对于口音嵌入,则使用的帧级信息在ASR任务中表现略好一些。我们认为这是因为帧级口音信息可以帮助纠正ASR任务中口音导致的细粒度错误。根据我们的经验,口音语音中并非所有词汇均体现出口音特点,而是通常仅有一小部分特定词汇会展现口音特征,而其余单词可能以标准方式发音。这种口音单词会对ASR任务构成挑战,但对AR任务来说更容易识别。因此,尽管句级pooling操作确实提高了AR任务的总体准确性,但它可能无法有效地捕捉口音单词的区分性。因此,帧级还是句级CE loss的选择取决于实际应用和AR与ASR任务之间的权衡。
4.4 用AR辅助ASR
通过比较B1和D8,我们发现尽管D8缺乏显式口音嵌入,但DIMNet结构仍然可以通过共享编码器隐式提取口音信息。然而,当将D8与D1进行比较时,我们发现口音嵌入对ASR分支的显式融合会带来更好的结果,这突显了AR对ASR交互的价值。
接下来,我们分析了不同的口音嵌入选择及其与ASR的整合。对比D1与D9和D10发现,emb_dnn表现最佳,而emb_sim表现一般,emb_pp表现最差。比较D1、D11和D12的性能,我们发现使用encoder处理口音嵌入比使用decoder更有效,但当两者同时使用时可以获得最佳性能。由于DIMNet有三重编码器结构,这在注意力分支中可以很容易地实现。
4.5 双粒度重打分
如表4所示,在CTC/attention框架内,注意力重打分可使WER平均相对降低1.63%。为了消除模型框架的影响,我们还评估了单粒度BPE单元的DIMNet模型中CTC重新打分的效果,其效果与注意力重新打分类似,约为相对1.41%。与这两种经典的重新打分技术相比,我们提出的两种粒度的重新打分实现了平均相对WER降低2.38%的效果。这证明了利用CTC和attention分支的双粒度信息的互补性,可以使最终ASR在整合它们的预测分数时能够实现更好的性能。
表4 双粒度重打分的有效性。ARS,CRS和TRS分别代表注意力重打分,CTC重打分和双粒度重打分解码

4.6 与其他公开结果的对比
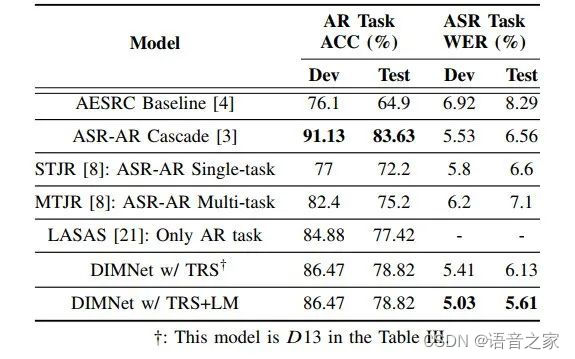
如表5所示,本文提出的DIMNet方案在不使用数据扩充的条件下,同时体现出了优良的AR和ASR性能。并且,DIMNet不需要分两步训练AR和ASR,计算成本更低。
表5 AESRC数据集上不同方法的对比
如表6所示,本文提出的DIMNet方案在KeSpeech数据集上获得了显著的AR和ASR性能提升,这证明了该方案在中文上的有效性。
表6 KeSpeech数据集上不同方法的对比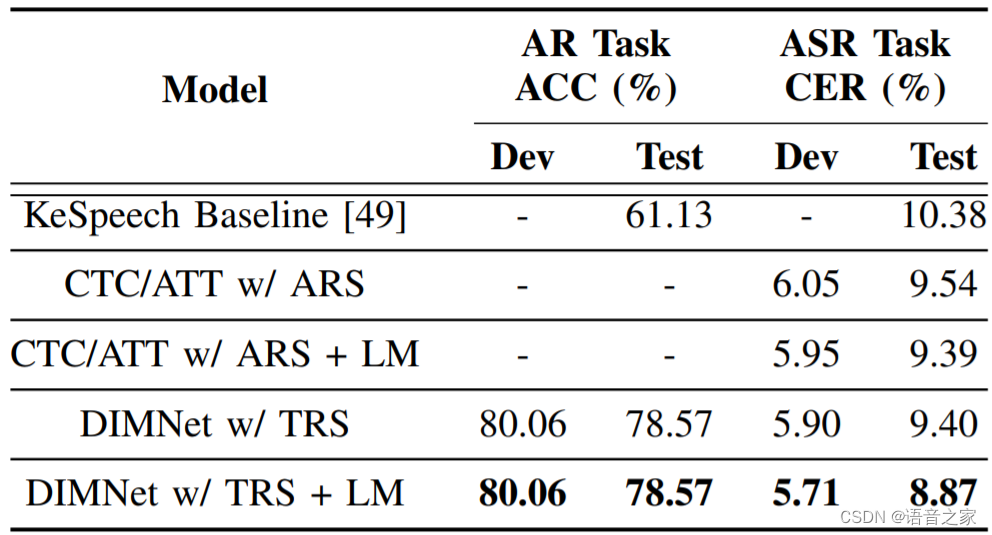
5. 总结
本文提出了DIMNet ASR-AR联合框架。首先使用三重编码器结构解耦了AR和ASR任务,该结构可以对每个任务中的两种粒度单元进行建模。然后通过引入和改进LASAS AR模型以及研究口音嵌入的选择和融合,增强了两个任务之间的交互。最后引入了一个两种粒度的重新打分方案,有效组合两种粒度的分数,进一步提高了ASR的性能。实验结果表明,与E2E基线相比,DIMNet在AESRC和KeSpeech数据集的测试集上分别实现了AR准确率的相对21.45%和28.53%的改进,以及ASR错误率32.33%和14.55%的相对降低。下一步工作目标是进一步降低DIMNet的计算复杂性,并将其应用到多语言ASR任务中。
参考文献
[1] Q. Shao, J. Yan, J. Kang, P. Guo, X. Shi, P. Hu, and L. Xie, “Linguistic-acoustic similarity based accent shift for accent recognition,” in Proc. INTERSPEECH, 2022, pp. 3719–3723.
[2] A. Jain, M. Upreti, and P. Jyothi, “Improved accented speech recognition using accent embeddings and multitask learning,” in Proc. INTERSPEECH, 2018, pp. 2454–2458.
[3] J. Zhang, Y. Peng, P. Van Tung, H. Xu, H. Huang, and E. S. Chng, “E2E-based multi-task learning approach to joint speech and accent recognition,” in Proc. INTERSPEECH, 2021, pp. 876–880.
[4] M. Najafian, A. DeMarco, S. Cox, and M. Russell, “Unsupervised model selection for recognition of regional accented speech,” in Proc. INTERSPEECH, 2014, pp. 2967-2971.
[5] X. Shi, F. Yu, Y. Lu, Y. Liang, Q. Feng, D. Wang, Y. Qian, and L. Xie, “The accented English speech recognition challenge 2020: Open datasets, tracks, baselines, results and methods,” in Proc. ICASSP, 2021, pp. 6918–6922.
[6] Z. Tang, D. Wang, Y. Xu, J. Sun, X. Lei, S. Zhao, C. Wen, X. Tan, C. Xie, S. Zhou et al., “KeSpeech: An open source speech dataset of Mandarin and its eight subdialects,” in Systems Datasets and Benchmarks Track of Proc. NeurIPS, 2021.
这篇关于IEEE TASLP | 联合语音识别与口音识别的解耦交互多任务学习网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







