本文主要是介绍SLIC与目前最优超像素算法的比较 SLIC Superpixels Compared to State-of-the-art Superpixel Methods,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SLIC与目前最优超像素算法的比较
Radhakrishna Achanta, Appu Shaji, Kevin Smith, Aurelien Lucchi, Pascal Fua, and Sabine S¨usstrunk
摘要
近年来,计算机视觉应用越来越依赖超像素,但并不总是清楚什么是良好的超像素算法。为了解现有方法的优点和缺点,我们比较了目前最好的五种超像素算法,比较的指标为图像边界的粘附性,算法速度,存储效率,以及它们对分割性能的影响。然后我们介绍一种新的超像素算法,简单的线性迭代聚类(SLIC),它采用k均值聚类方法高效地生成超像素。尽管它很简单,但SLIC较以前的算法可以更好地获取边界,同时,它具有更快的速度,更高的内存效率,并且能提高分割性能,也可以直接扩展到超体元生成。
关键词-超像素,分割,聚类,k均值。

图.1:使用SLIC分割成尺寸(大约)为64,256和1024的超像素。
I.引言
超像素算法将像素组合成感知有意义的原子区域( atomic regions),其可以用于替换像素网格的刚性结构。它们捕获图像冗余,提供计算图像特征的方便原语( primitive ),并且大大降低了后续图像处理任务的复杂性。它们已经成为许多计算机视觉算法的关键构建块,如PASCAL VOC挑战中的多类对象分割[9],[29],[11],深度估计[30],分割[16],身体模型估计[22]和对象定位[9]。
目前存在许多产生超像素的方法,每种具有其自身的优点和缺点,可更好地适合于特定应用。例如,如果遵守图像边界是至关重要的,[8]的基于图的方法可能是一个理想的选择。然而,如果超像素用于构建具有更规则的晶格的图形(lattice),[23]可能是更好的选择。虽然很难定义指标来判断算法的优劣性,但我们相信以下属性通常是可取的:
1)超像素应当良好地粘附到图像边界。
2)当作为预处理步骤用于降低的计算复杂度时,超像素应当快速计算,存储 器效率高且易于使用。
3)当用于分割目的时,超像素应当增加速度并提高结果的质量。
因此,我们对五个最先进的超像素方法进行了比较[8],[23],[26],[25],[15],评估他们的速度,连接图像边界的能力还有分割性能。我们还提供这些和其他超像素方法的定性分析。我们的结论是,现有的方法不能在所有方面都令人满意。
为了解决这个问题,我们提出了一种新的超像素算法:简单线性迭代聚类(SLIC),它采用kmeans聚类以类似于[30]的方式生成超像素。虽然非常简单,但是SLIC在Berkeley基准[20]上产生显示出对图像边界的最好效果,并且在PASCAL[7]和MSRC[24]数据集上进行分割时优于现有方法。此外,它比现有方法更快,更高的存储效率。除了这些可量化的好处,SLIC还易于使用,更为的紧凑,其生成的超像素数量也更灵活,还可直接扩展到更高的维度,并且是免费使用的(意思是代码是开源的)。
II.现有的超像素生成算法
用于生成超像素的算法可以大致分类为基于图或梯度上升的方法。下面,我们回顾每个类别常见的超像素方法,包括一些最初设计不是为了生成超像素的算法。表I提供了所研究方法的定性和定量总结,包括其相对性能。
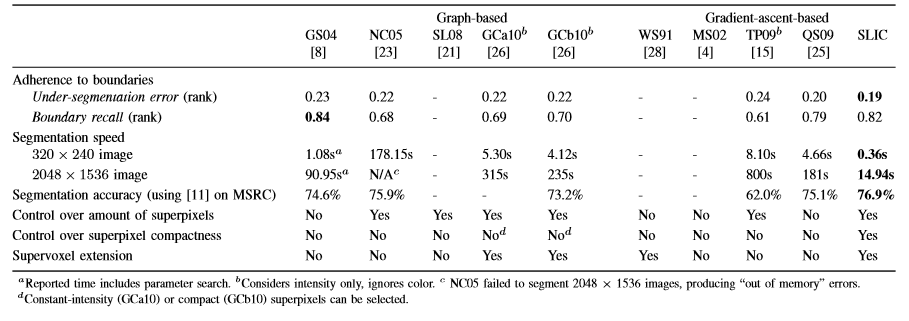
表I:现有超像素算法的总结。 超像素法粘附到边界的性能可以在伯克利数据集[20]中进行评估,其可以根据两个标准度量进行排名:欠分割误差和边界回忆(对于〜500超像素)。 我们还展示了使用具有2GB RAM的Intel双核2.26 GHz处理器分段图像所需的平均时间,以及使用[11]中描述的方法在MSRC数据集上获得的类平均分割精度。 粗体条目表示每个类别的最佳性能。 还提供了指定超像素的量,控制其紧凑性以及生成超体素的能力。
A.基于图的算法
基于图形的超像素生成方法将每个像素视为图中的节点。两个节点之间的边权重与相邻像素之间的相似性成比例。超像素通过最小化图中定义的成本函数来创建。
NC05-归一化切割算法[23]递归地使用轮廓和纹理线索分割图像中的所有像素的图形,从而全局性地最小化在分割边界处的边缘定义的成本函数。它产生非常规则,视觉上令人愉快的超像素。然而,NC05的边界粘附相对较差,并且它是方法中最慢的(特别是对于大图像),尽管试图加速的算法存在[5]。NC05具有[15]的复杂度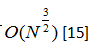
GS04-Felzenszwalb和Huttenlocher[8]提出了一种替代的基于图形的方法,已被应用于生成超像素。它将像素作为图的节点,使得每个超像素是组成像素的最小生成树。GS04在实践中很好地粘附到图像边界,但是产生具有非常不规则的尺寸和形状的超像素。它的复杂度是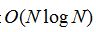
SL08-Mooreetal提出了一种通过确定将图像分割成更小的垂直或水平区域的最佳路径或接缝来生成符合网格的超像素的方法[21]。使用类似于SeamCarving[1]的图切割方法找到最佳路径。尽管作者给出的复杂的是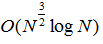
GCa10和GCb10-[26],Veksleretal。使用类似于[14]的纹理合成工作的全局优化方法。通过将重叠的图像块拼接在一起来获得超像素,使得每个像素仅属于重叠区域中的一个。这个方法有两个变种,一个用于生成紧凑超像素(GCa10),一个用于恒定强度超像素(GCb10)。
B.基于梯度上升的方法
从粗略的像素初始聚类开始,梯度上升法迭代地修改聚类,直到满足一些收敛标准以形成超像素。
MS02-In[4]中,平均偏移,用于定位密度函数的局部最大值的迭代模式寻找过程被应用于图像的颜色或强度特征空间中的第一模式。会聚到相同模式的像素定义超像素。MS02是一种较旧的方法,产生不均匀尺寸的不规则形状的超像素。它是复杂度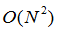
QS08-快速移位[25]也使用模式查找分割方案。它使用medoid移位过程初始化分割。然后将特征空间中的搜索点移动到最近的邻居,从而增加Parzen密度估计。虽然它具有相对良好的边界粘附,但是QS08的运行速度相当缓慢,具有复杂度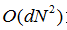
WS91-分水岭方法[28]从局部最小值开始执行梯度上升以产生分水岭,和分离集水盆地的线条。所得到的超像素在尺寸和形状上通常是高度不规则的,并且不表现出良好的边界粘附。[28]的方法相对较快(具有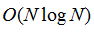
TP09-Turbopixel方法使用基于水平集的几何流动逐渐扩大一组种子位置[15]。几何流依赖于局部图像梯度,目的是在图像平面上规则地分布超像素。与WS91不同,TP09超像素被约束为具有均匀的尺寸,紧凑性和边界粘附。TP09依赖于不同复杂度的算法,但在实践中,如作者所声称的,具有大约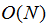
III.SLIC超像素
我们提出一种新的生成超像素的方法,比现有方法更快,更高的记忆效率,展示了目前最优的边界依从性,并提高了分割算法的性能。简单线性迭代聚类(SLIC)采用K均值算法生成超像素,相较与其他算法具有两个重要的区别:
1)通过将搜索空间限制为与超像素大小成比例的区域,显着地减少了优化中的距离计算的数量。这降低了像素数N的线性复杂度,并且与超像素k的数量无关。
2)加权距离度量组合颜色和空间接近度,同时提供对超像素的尺寸和紧凑性的控制。
SLIC类似于[30]中描述的用于深度估计的预处理步骤的方法,其没有在超像素方向进行研究。
A.算法
SLIC使用简单易懂。默认情况下,算法的唯一参数是k,其含义是大小大致相等的超像素的个数。对于CIELAB色彩空间中的彩色图像,聚类过程从初始化步骤开始,其中k个初始聚类中心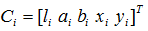
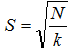
接下来,在分配步骤中,每个像素i与搜索区域与其位置重叠的最近聚类中心相关联,如图2所示。这是加速我们的算法的关键,因为限制搜索区域的大小显着地减少了距离计算的数量,并且导致相对于常规kmeans聚类的显着的速度优势,其中每个像素必须与所有聚类中心比较。这只能通过引入距离测量D来实现,该距离测量D确定每个像素的最近聚类中心,如第III-B节中所讨论的。由于超像素的预期空间范围是近似尺寸S×S的区域,因此在超像素中心周围的区域2S×2S中进行类似像素的搜索。
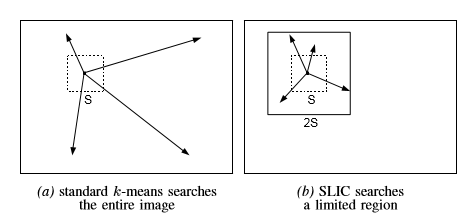
图.2:减少超像素搜索区域。SLIC的复杂性在图像O(N)中的像素数目中是线性的,而常规的k均值算法是O(kNI),其中I是迭代次数。这在分配步骤中提供了每个聚类中心的搜索空间。(a)在常规k均值算法中,从每个聚类中心到图像中的每个像素计算距离。(b)SLIC仅计算从每个聚类中心到2S×2S区域内的像素的距离。注意,期望的超像素大小仅为S×S,由较小的正方形表示。这种方法不仅减少了距离计算,而且使得SLIC的复杂性与超像素的数量无关。
一旦每个像素已经与最近的聚类中心相关联,更新步骤将聚类中心调整为属于该聚类的所有像素的平均向量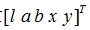



B.距离测量



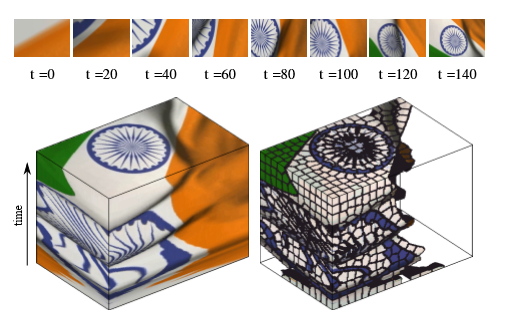
图3:为视频序列计算的SLIC超体元。(顶部)短波的短视频序列所产生的帧。(左下)包含视频的卷。最后一帧出现在卷的顶部。(右下)视频的超像素分割。为便于显示,具有橙色聚类中心的超体素被去除
C.后处理
像一些其他超像素算法[8],SLIC没有明确强制连接。在聚类过程结束时,可能保留不属于与其聚类中心相同的连接分量的一些“孤立”像素。为了对此进行校正,使用连通分量算法向这些像素分配最近聚类中心的标签。
D.复杂度

IV.与现有技术的比较
略
V.生物医学应用
许多流行的基于图形的分割方法,例如图切割[3]变得越来越昂贵,因为更多的节点被添加到图中,这在实践中会对图像大小产生限制。 对于一些应用,例如从电子显微照片(EM)的线粒体分割,这种情况下图像的尺寸是很大的,但是此时不能降低分辨率。 在这种情况下,在像素网格上定义的图形上的分割将是棘手的。 在[18],SLIC超像素显着降低图的复杂性,使分割易处理。 来自[18]的分段线粒体显示在 图3(a)和(b)。在[19],这种方法扩展到3D图像堆栈,其中可以包含数十亿的体素。 只有最节俭的算法可以在这样大量的数据上操作,而不需要以某种方式减小图的大小。 SLIC超体元将存储器要求和复杂性降低超过三个数量级,并且与常规立方体相比显着增加性能,如 图3(c) - (e)所示。
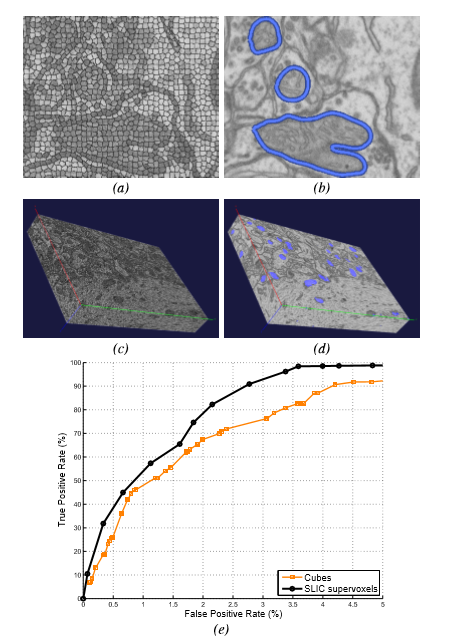
图3:SLIC应用于来自神经组织的2D和3D EM图像的线粒体。 (a)来自EM切片的SLIC超像素。 (b)来自[18]的方法的分割结果。 (c)1024×1024×600体积的SLIC超体元。 (d)使用[19]中描述的方法提取的线粒体。 (e)比较SLIC超体元与相似尺寸的立方体在(c)中体积的分割性能。
VI.结论
超像素已经成为视觉社区的重要工具,在本文中,我们为读者提供了对现代超像素技术性能的深入分析。我们以边界粘附性,分割速度和作为分割框架中预处理步骤时的性能为指标,比较了目前最好的五个超像素算法。此外,我们提出了一种基于kmeans聚类生成超像素的新方法,SLIC已被证明在几乎每个方面都优于现有的超像素方法。
虽然我们的实验是彻底的,但是有一个警告。某些超像素方法,即GC10和TP09,不考虑颜色信息,而其他方法考虑。这可能会对其性能产生不利影响。
参考文献
[1] Shai Avidan and Ariel Shamir. Seam carving for content-aware image resizing. ACM Transactions on Graphics (SIGGRAPH), 26(3), 2007.
[2] A. Ayvaci and S. Soatto. Motion segmentation with occlusions on the superpixel graph. In Workshop on Dynamical Vision, Kyoto, Japan, October 2009.
[3] Y. Boykov and M. Jolly. Interactive Graph Cuts for Optimal Boundary & Region Segmentation of Objects in N-D Images. In International Conference on Computer Vision (ICCV), 2001.
[4] D. Comaniciu and P. Meer. Mean shift: a robust approach toward feature space analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 24(5):603–619, May 2002.
[5] T. Cour, F. Benezit, and J. Shi. Spectral segmentation with multiscale graph decomposition. In IEEE Computer Vision and Pattern Recognition (CVPR) 2005, 2005.
[6] Charles Elkan. Using the triangle inequality to accelerate k-means. International Conference on Machine Learning, 2003.
[7] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The PASCAL Visual Object Classes Challenge. International Journal of Computer Vision (IJCV), 88(2):303–338, June 2010.
[8] Pedro Felzenszwalb and Daniel Huttenlocher. Efficient graph-based image segmentation. International Journal of Computer Vision (IJCV), 59(2):167–181, September 2004.
[9] B. Fulkerson, A. Vedaldi, and S. Soatto. Class segmentation and object localization with superpixel neighborhoods. In International Conference on Computer Vision (ICCV), 2009.
[10] J.M. Gonfaus, X. Boix, J. Weijer, A. Bagdanov, J. Serrat, and J. Gonzalez. Harmony Potentials for Joint Classification and Segmentation. In Computer Vision and Pattern Recognition (CVPR), 2010.
[11] Stephen Gould, Jim Rodgers, David Cohen, Gal Elidan, and Daphne Koller. Multi-class segmentation with relative location prior. International Journal of Computer Vision (IJCV), 80(3):300–316, 2008.
[12] Tapas Kanungo, David M. Mount, Nathan S. Netanyahu, Christine D. Piatko, Ruth Silverman, and Angela Y. Wu. A local search approximation algorithm for k-means clustering. Eighteenth annual symposium on Computational geometry, pages 10–18, 2002.
[13] Amit Kumar, Yogish Sabharwal, and Sandeep Sen. A simple linear time (1+e)-approximation algorithm for k-means clustering in any dimensions. Annual IEEE Symposium on Foundations of Computer Science, 0:454–462, 2004.
[14] Vivek Kwatra, Arno Schodl, Irfan Essa, Greg Turk, and Aaron Bobick. Graphcut textures: Image and video synthesis using graph cuts. ACM Transactions on Graphics, SIGGRAPH 2003, 22(3):277–286, July 2003.
[15] A. Levinshtein, A. Stere, K. Kutulakos, D. Fleet, S. Dickinson, and K. Siddiqi. Turbopixels: Fast superpixels using geometric flows. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 2009.
[16] Yin Li, Jian Sun, Chi-Keung Tang, and Heung-Yeung Shum. Lazy snapping. ACM Transactions on Graphics (SIGGRAPH), 23(3):303– 308, 2004
[17] Stuart P. Lloyd. Least squares quantization in PCM. IEEE Transactions on Information Theory, IT-28(2):129–137, 1982.
[18] A. Lucchi, K. Smith, R. Achanta, V. Lepetit, and P. Fua. A fully automated approach to segmentation of irregularly shaped cellular structures in em images. International Conference on Medical Image Computing and Computer Assisted Intervention, 2010.
[19] Aur´elien Lucchi, Kevin Smith, Radhakrishna Achanta, Graham Knott, and Pascal Fua. Supervoxel-Based Segmentation of Mitochondria in EM Image Stacks with Learned Shape Features. IEEE Transactions on Medical Imaging, 30(11), 2011.
[20] D. Martin, C. Fowlkes, D. Tal, and J. Malik. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In IEEE International Conference on Computer Vision (ICCV), July 2001.
[21] Alastair Moore, Simon Prince, Jonathan Warrell, Umar Mohammed, and Graham Jones. Superpixel Lattices. IEEE Computer Vision and Pattern Recognition (CVPR), 2008.
[22] Greg Mori. Guiding model search using segmentation. In IEEE International Conference on Computer Vision (ICCV), 2005.
[23] Jianbo Shi and Jitendra Malik. Normalized cuts and image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 22(8):888–905, Aug 2000.
[24] J. Shotton, J. Winn, C. Rother, and A. Criminisi. TextonBoost for Image Understanding: Multi-Class Object Recognition and Segmentation by Jointly Modeling Texture, Layout, and Context. International Journal of Computer Vision (IJCV), 81(1), January 2009.
[25] A. Vedaldi and S. Soatto. Quick shift and kernel methods for mode seeking. In European Conference on Computer Vision (ECCV), 2008.
[26] O. Veksler, Y. Boykov, and P. Mehrani. Superpixels and supervoxels in an energy optimization framework. In European Conference on Computer Vision (ECCV), 2010.
[27] O. Verevka and J.W. Buchanan. Local k-means algorithm for color image quantization. Graphics Interface, pages 128–135, 1995.
[28] Luc Vincent and Pierre Soille. Watersheds in digital spaces: An efficient algorithm based on immersion simulations. IEEE Transactions on Pattern Analalysis and Machine Intelligence, 13(6):583–598, 1991.
[29] Y. Yang, S. Hallman, D. Ramanan, and C. Fawlkes. Layered Object DetectionforMulti-ClassSegmentation. InComputer Visionand Pattern Recognition (CVPR), 2010.
[30] C. L. Zitnick and S. B. Kang. Stereo for image-based rendering using image over-segmentation. International Journal of Computer Vision (IJCV), 75:49–65, October 2007.
文章下载:https://infoscience.epfl.ch/record/177415/files/Superpixel_PAMI2011-2.pdf
源码地址:http://ivrl.epfl.ch/research/superpixels
这篇关于SLIC与目前最优超像素算法的比较 SLIC Superpixels Compared to State-of-the-art Superpixel Methods的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








