本文主要是介绍深度学习基础模型之FCN介绍以及反卷积、上采样具体操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.FCN概述
- 2.FCN的优缺点
- 2.1优点
- 2.2缺点
- 3.FCN主要亮点
- 3.1 全卷积化
- 3.2 反卷积/上采样
- 3.3 跃层结构
- 参考
1.FCN概述
CNN对图片分类任务有很好的处理方法,有很多人认为CNN能够处理图像的一切问题。但是最早震惊大家的是AlexNet对图片分类错误率大大降低。
FCN并不能单纯算作一种模型,可以算作是一种策略,最重要的就是拿卷积层代替分类模型的全连接层,所以才叫做全卷积神经网络,还有其他的一些细节后面会讲。
FCN是论文Fully Convolutional Networks for Semantic Segmentation提出的。
作为一个图像语义级别分割(像素级别的)的解决方案。作者认为最核心的思想就是利用全卷积网络实现了任意大小的图片输入并且因为全卷积使前向传播和学习更加的高效。输出一个与原图像大小相同的像素级分类结果,即 dense prediction。
2.FCN的优缺点
2.1优点
1)利用卷积层替换全连接层,可以输入任意大小的图片
2)输出像素级别的分类图
3)更高效的计算和学习。
2.2缺点
1)图像不够精细,上采样结果比较平滑,丢失细节。
2)忽略像素间关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
3.FCN主要亮点
3.1 全卷积化
以AlexNet举例,AlexNet可以参考AlexNet论文阅读
传统的CNN分类任务是通过前面的卷积+池化+normalization层来提取特征,最后得到一个通道的特征图(二维矩阵),然后通过全连接进行映射得到一个特征向量,利用SoftMax进行概率分布计算得到分类的结果,例如AlexNet的最后一层是1000维,因为有1000个分类。
FCN做出了一下操作:
1)将全连接层全部替换成为卷积层,就可以接受任意尺寸的输入图像
为什么?
首先卷积层和全连接可以互换是因为都是采用的是点乘的操作,全连接层可以看作是一个比较特殊的卷积层。
但是全连接层计算需要维度相等,因为采用矩阵乘法,所以要求输入图像尺寸是设定的,最后到全连接层的特征图大小是一定的。卷积操作因为卷积核比输入图像小,通过设置步长(stride),用滑动的方式进行计算。所以任意图片都可以计算。
这里重要的是,那不同大小图片经过同样的网络出来的特征图大小也是不一样的。但是FCN采用上采样操作将得到的特征图回到原来图片的大小,再计算每个像素的分类概率。所以说为什么是语义级别的图像分割问题。
注意:最终的loss是所有像素的loss和
卷积相对于全连接的优点,还有就是提到的,更高效的计算和学习。卷积核的参数相对于全连接来说非常的小,因为卷积核大小比较小,还有参数共享。全连接层的参数庞大,但是很多都是无关紧要的,为了这些无关紧要的参数花费很多计算资源去更新是很不合算的,所以更新卷积,那些重要的参数是能让学习更加高效的。
在论文中用这张图表示传统 CNN 的输出与 FCN 的输出对比:

3.2 反卷积/上采样
为了生成dense prediction,需要将特征图还原到原来图片的大小,然后计算每个像素的概率,这里重要的就是如何还原。
作者对比了两种方式:
(1)shift-and-stitch is filter rerefaction
设原图与FCN所得输出图之间的降采样因子是f,那么对于原图的每个ff的区域(不重叠),==“shift the input x pixels to the right and y pixels down for every (x,y) ,0 < x,y < f." ==把这个ff区域对应的output作为此时区域中心点像素对应的output,这样就对每个f*f的区域得到了f^2个output,也就是每个像素都能对应一个output,所以成为了dense prediction。
因为要计算f^2,有一个著名的小波领域的算法the `a trous algorithm来高效的得到相同的结果。
但是实验得到的结果是不同的,因为原来的滤波器只能看见已经上采样过的输入的简化部分。为了重现这种技巧,通过扩大来稀疏滤波:
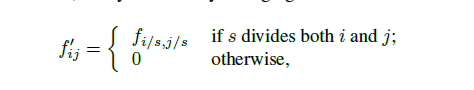
但是这些方法都被放弃了。
放弃的原因:扩大稀疏滤波后fileds无法感受更精细的信息。在Shift-and-stitch中,filters 可以看到更精细的信息,但同时 receptive fields 感受野也更小,可能损失全局 信息,而且计算花费大。

了解Shift-and-stitch详细计算,参见语义分割–FCN中的Shift-and-stitch的详解
(2)interpolation插值法
插值法就是例如简单的双线性插值等。
放弃的原因:
只依赖输入和输出单元的相对位置的线性图最近的四个输入
(3)反卷积(deconvolutional)
其实也就是upsampling,或者说conv_transpose。
顺用了VGG的结构,可以去了解一下。
众所诸知,普通的池化会缩小图片的尺寸,比如VGG16 五次池化后图片被缩小了32倍。
反卷积和卷积类似,都是相乘相加的运算。只不过后者是多对一,前者是一对多。而反卷积的前向和后向传播,只用颠倒卷积的前后向传播即可。所以无论优化还是后向传播算法都是没有问题。图解如下:

看图最明显
首先,我们看一看卷积操作,卷积核为 3x3;no padding , strides=1
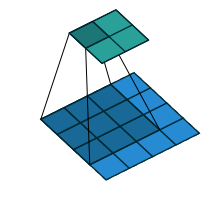
反卷积操作,卷积核为:3x3; no padding , strides=1
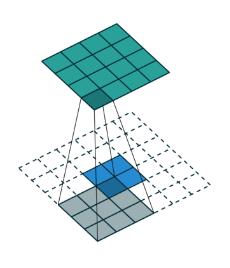
改变strides = 2,卷积操作
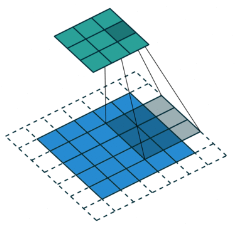
反卷积操作:
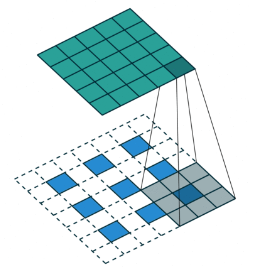
这里可以看到,为了应对不同的strides,要对得到的特征图进行不同方式的padding,padding的值为(kernel_size - 1)。不同的是strides=1的话,特征图不用动,strides不为1, 特征图要查入strides的值,总的来说就是保持kernel每次只覆盖一个特征图的值。
3.3 跃层结构
将来自深层(粗层)的语义信息和来自浅层(细层)的外观信息结合起来,得到更加精确和鲁棒的分割结果。
使用跃层结构融合多层输出,使得网络能够预测更多的位置信息。因为在浅层网络位置信息等保留的比较好,将他们加入到深层输出中,就可以预测到更精细的信息。

例如32×就是直接上采样(deconvolutional)32倍,会非常非常的粗糙。但是这里16×的话,先利用线性插值把conv7的扩大两倍,然后和pool4经过1×1卷积改造好维度(和结果匹配好)求和,再利用上采样(deconvolutional)16倍进行预测。
最后的特征图事m×m×c的,c是分类的类别数,这样才好用softmax对每个像素求概率,进行dense prediction(我的理解是这样的)。

其实这个结构了解残差网络ResNet应该会更令人印象深刻。
参考
语义分割–全卷积网络FCN详解
全卷积网络 FCN 详解
【论文笔记】FCN
FCN中的Shift-and-stitch的详解
反卷积 转置卷积的理解
这篇关于深度学习基础模型之FCN介绍以及反卷积、上采样具体操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




