本文主要是介绍lightgbm实践:Kaggle桑坦德银行客户交易预测比赛baseline,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
继上篇介绍了lightgbm的理论知识后(LightGBM源码阅读+理论分析(处理特征类别,缺省值的实现细节)_爱吃火锅的博客-CSDN博客_lightgbm源码),终于有时间来写一篇关于lgb的实践篇啦,本篇的实践是基于kaggle上面一个正在进行的比赛,其采用的是ROC评分机制,截止目前第一名得分是0.904,本篇的的结果是0.899,分数算是一个baseline吧,待优化,目的重在分享学习!!!!
本篇全部代码:python-Machine-learning/Lightgbm/Santander_Customer_Transaction_Prediction at master · Mryangkaitong/python-Machine-learning · GitHub
数据集:SantanderCustomerTransactionPrediction_免费高速下载|百度网盘-分享无限制
赛题介绍:
背景需求:
在桑坦德,我们的使命是帮助人们和企业繁荣。我们一直在寻找方法来帮助我们的客户了解他们的财务健康,并确定哪些产品和服务可能帮助他们实现他们的货币目标。
我们的数据科学团队不断挑战我们的机器学习算法,与全球数据科学界合作,确保我们能够更准确地找到解决我们最常见挑战的新方法,二进制分类问题,如:客户满意吗?顾客会购买这种产品吗?客户能支付这笔贷款吗?
在这个挑战中,我们邀请了kagglers来帮助我们确定哪些客户将在未来进行特定的交易,不管交易金额有多少。为这次比赛提供的数据与我们现有的解决这个问题的真实数据具有相同的结构。
数据:
File descriptions
- train.csv - the training set.
- test.csv - the test set. The test set contains some rows which are not included in scoring.
- sample_submission.csv - a sample submission file in the correct format.
实践:
(1)EDA

可以看到train,test数据都是是200000行,其中特征是var_0到var_199即200个特征,具体含义不得而知
接下来看一下train中的label:

可以看到样本数据不是很均衡,大约相差是9倍的样子。
接着我们再来看一下这200特征中缺省值的情况:

也就是说所有特征都没有缺省值,说得到这里如果还记得理论篇的话应该可以想到,即使有缺省值也无所谓,因为lgb是可以自动处理的
那我们再来看看每个特征下对应的具体取值:

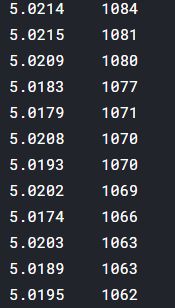
这里主要是看每个特征下有多少不同的值,可以看到大部分特征都是连续的有很多值,笔者这里只是截取了部分结果,这里面稍微有点特殊的是var_68这个特征,相比于其他其不同值最少为451,那么我们就具体在train和test上面来看看这个特征的真面貌:(截取了部分图片)

最后我们要看看的是每个特征和label的相关度,以便我们进一步了解特征的重要程度:

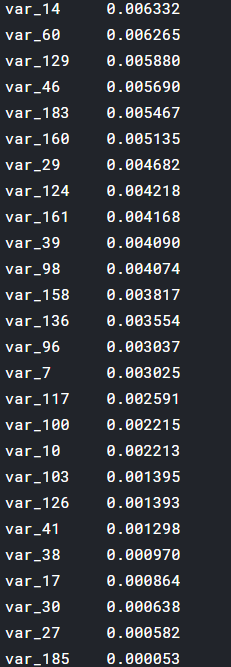
可以看到相关度最高的是var_81为0.08,相关度最低是var_185为0.00005
最后我们将特征和Label的相关度可视化一下:


这里仅仅截取了前两个特征以供参考
(2)特征工程
先将相关度不高的几个特征去掉:

关于归一化,lgb是树模型 ,有说归一化没用,各种理论分析,笔者的一般做法就是都试试嘛,与其纠结归不归好,还不如动手试一下结果一目了然,实践是检验真理的唯一标准,进过实验,这里还是不归一话的好
通过EDA部分我们也可以看到数据是有点不平衡的,我们是否可以采用均衡抽样呢?如下:

但是不论进过过采样还是欠采样都没有取得显著的效果,所以本篇是直接使用了没有经过抽样的原始数据
除了直接将相关度不高的特征去掉之外,我们还可以通过后项搜索来选择最佳特征,但是该过程耗时耗力,一班情况下最好不要使用,不过为了学习,笔者也将该代码分享出来供交流(代码中的featureSelect函数),其实很简单
(3)模型训练
这里采用的是交叉验证,即5份

后面就比较简单了,直接使用Lgb模型训练即可:
params = {'num_leaves': 10,'min_data_in_leaf': 42,'objective': 'binary','max_depth': 18,'learning_rate': 0.01,'boosting': 'gbdt','bagging_freq': 6,'bagging_fraction': 0.8,'feature_fraction': 0.9,'bagging_seed': 11,'reg_alpha': 2,'reg_lambda': 5,'random_state': 42,'metric': 'auc','verbosity': -1,'subsample': 0.9,'min_gain_to_split': 0.01077313523861969,'min_child_weight': 19.428902804238373,'num_threads': 4}
oof_lgb, prediction_lgb, feature_importance_lgb = train_model(params=params, model_type='lgb',plot_feature_importance=True)需要注意这里的超参数,有什么不懂的请看理论篇,其中有些参数没讲解的大家可以进一步百度,关于模型这里只不过进行了进一步封装,可以具体看train_model
最后来看一下结果:


说明:
那这些超参数的具体值是怎么确定的呢?哈哈,实际来说大家可以使用这些或其他一些大牛的祖传参数值先去跑一下,只要使用的参数值别太奇葩,其实结果的好坏很大程度还是取决于特征工程的,调参带来的效果还是小打小闹,所以还是把更多精力放在特征工程吧!!!!
结束:
待优化,欢迎交流
欢迎关注笔者微信公众号

这篇关于lightgbm实践:Kaggle桑坦德银行客户交易预测比赛baseline的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





