本文主要是介绍LVI-SAM:使用SAM的激光-视觉-惯导紧耦合里程计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转载自:https://mp.weixin.qq.com/s/MlN-0BD9rAdJwsVco7TRlg
LVI-SAM:使用SAM的激光-视觉-惯导紧耦合里程计
原创 泡泡机器人 泡泡机器人SLAM 今天
标题:LVI-SAM: Tightly-coupled Lidar-Visual-Inertial Odometry via Smoothing and Mapping
作者:Tixiao Shan, Brendan Englot, Carlo Ratti, and Daniela Rus
机构:MIT
来源:ICRA 2021
编译:段逸凡
审核: 万应才
Code:https://github.com/TixiaoShan/LVI-SAM
这是泡泡图灵智库推送的第625篇文章,欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权
摘要
大家好,今天为大家带来的文章是 LVI-SAM: Tightly-coupled Lidar-Visual-Inertial Odometry via Smoothing and Mapping。
我们通过SAM(smoothing and mapping)的方式,提出了一个 雷达-视觉-惯导的紧耦合的里程计——LVI-SAM。该里程计可以实时进行状态估计和地图构建。LVI-SAM基于因子图,分为两个子系统:视觉惯性系统(VIS)和雷达惯性系统 (LIS)。这两个子系统均以紧耦合的方式进行设计。两个系统并行的作用如下:
-
VIS利用LIS的估计进行初始化;
-
通过使用激光雷达的测量结果来优化VIS中视觉特征的深度信息,可以提高VIS的准确性;
-
LIS也可以利用VIS对位姿的估计,作为点云配准的初始值;
-
闭环首先由VIS进行识别,再由LIS进行完善;
-
当任意一个系统发生故障时,LVI-SAM仍然可以稳定运行,提高了在缺乏纹理信息和特征区域的鲁棒性。
最后,LVI-SAM在各种平台,各种规模的场景中进行了实验。
主要工作与贡献
-
实现了一个紧耦合的激光-视觉-惯导系统,通过因子图同时完成了多传感器融合和全局优化(包含回环检测)两项任务;
-
通过故障检测机制,绕过出现问题的子系统,提高了整个系统的鲁棒性。
算法核心
系统框架
如图1所示,系统的输入为LiDAR点云, 单目相机, IMU,分为两个子系统LIS和VIS:
-
VIS处理IMU的输入,并使用LiDAR的数据进行优化。视觉里程计通过最小化视觉和IMU测量的联合残差获得。
-
LIS通过提取点云特征,并通过与特征地图进行匹配获得雷达里程计。特征地图通过滑动窗口的方式进行实时性优化。最后,整个状态估计任务被表示为一个估计最大后验概率(MAP)的问题,使用iSAM2通过IMU预积分约束,视觉里程计约束,雷达里程计约束,回环检测约束进行联合优化。
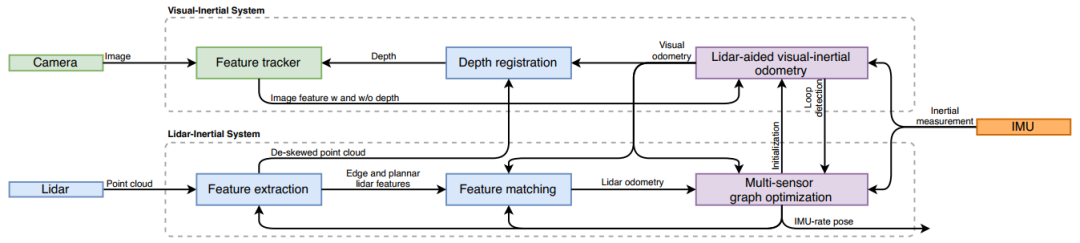
图1 系统框架图。
视觉惯导系统(VIS)
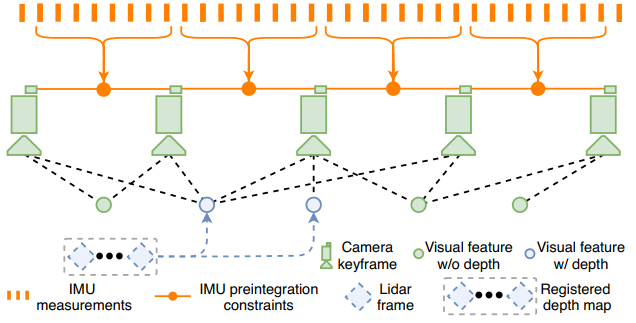
图2 VIS框架。
我们使用VINS-Mono作为VIS的baseline,如图2所示。视觉特征通过角点提取,并使用Kanade–Lucas–Tomasi算法进行跟踪。在VIS初始化时,我们使用视觉里程计产生的位姿变化,将雷达的帧配准在一起,形成一个稀疏的深度图用来获得视觉特征点的深度。
符号说明:系统的状态可以写为
, 其中x为:
其中为旋转矩阵, 为位置向量, v为速度, b为IMU bias。 为传感器坐标系到世界坐标系的转换,
. VIS的细节如下:
初始化
基于优化的VIO通常需要解决初始化时的非线性问题。初始化的效果很取决于两个因素:开始时的传感器移动,和IMU参数的准确性。在实验中,我们发现当传感器以很小的速度或者匀速运动时,VINS-Mono经常初始化失败。这是因为当加速度激励不够大时,度量尺度不能获得。IMU的参数包括一个缓慢变化的偏差和白噪声,这影响了原始加速度和角速度测量。在初始化时对这些参数进行良好的猜测有助于优化更快地收敛。
为了增强初始化的鲁棒性,我们利用了从LIS中获得的系统状态
和IMU bias , 因为雷达的深度可以直接获得,容易得到与
. 然后根据图像时间戳将它们关联到图像关键帧,并进行插值。值得注意的是,IMU bias在两个图像关键帧之间被认为是恒定的。最后,利用LIS估计出的x和b作为VIS初始化的初始猜测,显著提高了初始化速度和鲁棒性。
特征点深度
在VIS已经初始化的情况下,我们使用视觉里程计的信息,将雷达的帧进行配准。由于雷达点云的稀疏性,我们选择将若干帧堆叠在一起,来获得一个稠密的深度图。为了将图像特征点和深度值对应起来,我们首先将特征点和雷达产生的深度点投影在一个以相机为球心的单位球上。对深度点以一定的密度进行降采样,并存储它们的极坐标值。我们使用K-D tree来寻找在球坐标系下,距离图像特征点最近的三个雷达深度点。最后,特征点的深度表示为,特征点与球心的连线与上述三个深度点所形成的平面的交点的深度。如图3(a)所示。
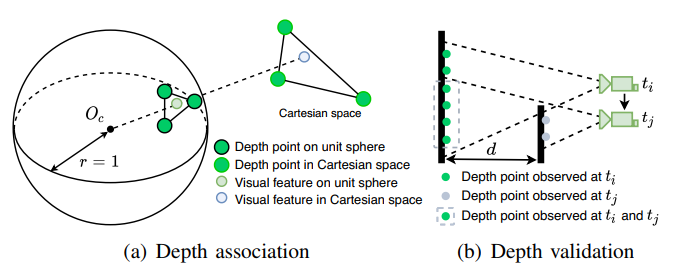
图3 视觉特征点与雷达深度点的关系。
更进一步,我们通过检查三个最近深度点之间的距离来验证特征深度。这是因为将不同时间戳下的激光雷达帧进行堆叠可能会导致深度模糊,如图3(b)所示(因为在不同的时间,观察到的前景物体和背景物体的点混在了一起)。在
观测到的深度点为绿色,
观测到的深度点为灰色。灰色虚线框里的点因为点云帧的堆叠,同时存在,这导致了对图像特征点错误的深度估计。我们通过设置深度点之间的距离的阈值来拒绝这种情况。如果深度点之间的距离大于2m,则不进行特征点的深度关联。
配准深度图和视觉特征点的效果如图4所示。绿色点为关联成功,红色点为失败。
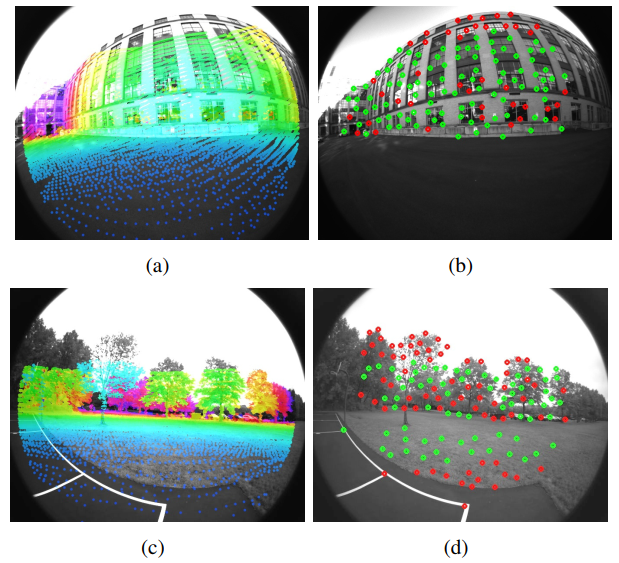
图4 视觉特征点深度关联。
失败检测
VIS容易遭受剧烈运动,照明变化和弱纹理环境而导致的失败。当机器人经历激烈运动或进入无纹理环境时,跟踪到的特征数量会大大减少,这会导致优化失败。我们还注意到,当VIS失败时,会有很大的IMU bias。因此,当跟踪的特征数低于一个阈值或IMU bias大于阈值时,我们将判断VIS失败了。当失败发生时,将会通知LIS,并且重新开始初始化。
闭环检测
使用DBoW2进行闭环检测。对每个新的关键帧,我们提取BRIEF描述子,并与之前的进行比较。通过DBoW2获得的候选者,将会发给LIS进行进一步验证。
激光惯导系统(LIS)
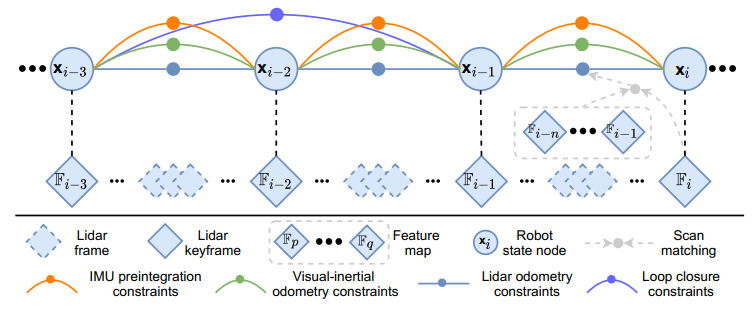
图5 LIS框架。
LIS框架与LIO-SAM类似,使用因子图来做全局位姿优化,并包含四种约束(IMU预积分,视觉里程计,雷达里程计,闭环检测)。雷达里程计通过当前帧与全局特征地图的匹配获得。我们维护了一个雷达关键帧的滑动窗口来保证计算复杂度有界。当机器人的移动大于阈值时,选择一个新的雷达关键帧,关键帧之间的雷达帧将被丢弃。选择新的雷达关键帧后,在因子图中添加一个新的机器人状态
作为节点。这种方式不仅可以实现内存消耗和地图密度之间的平衡,还有助于维护一个相对稀疏的因子图,便于实时优化。下面介绍一些提高整体系统鲁棒性的细节。
初始值估计
一个好的初始值在点云配准中扮演者重要的角色,尤其是当传感器进行剧烈运动时。初始值的来源在LIS初始化的前后是不同的。
在LIS初始化之前,我们假设机器人以静止状态从一个固定位置出发。我们假设IMU的bias和noise都为0,然后将IMU的值进行融合。融合后的关键帧之间的平移和旋转可以给出一个点云匹配的初始值。我们发现这种方法在初始线速度小于
,角速度小于
时,可以成功初始化整个系统。一旦LIS初始化,我们就可以估计IMU的bias,机器人的位姿和速度。我们还可以把这个信息发给VIS进行VIS的初始化。
在LIS初始化之后,我们有两种途径可以获得初始值:IMU的测量值(拥有修成果的bias),VIS。当VIO可以用时,使用VIO;不能用时,使用IMU。
失败检测
当环境发生退化时,点云匹配将会发生错误。图6展示了一些激光雷达遇到的特殊情况。这里使用《On Degeneracy of Optimizationbased State Estimation Problems》中提到的方法,进行LIS失败检测。

图6 退化场景。ac中,雷达垂直于地面摆放。bd中雷达放置在空旷的无纹理的场景中。
实验
实验的器材如下:Velodyne VLP-16 lidar, FLIR BFS-U3-04S2M-CS camera, MicroStrain 3DM-GX5-25 IMU, Reach RS+ GPS(提供真值)。
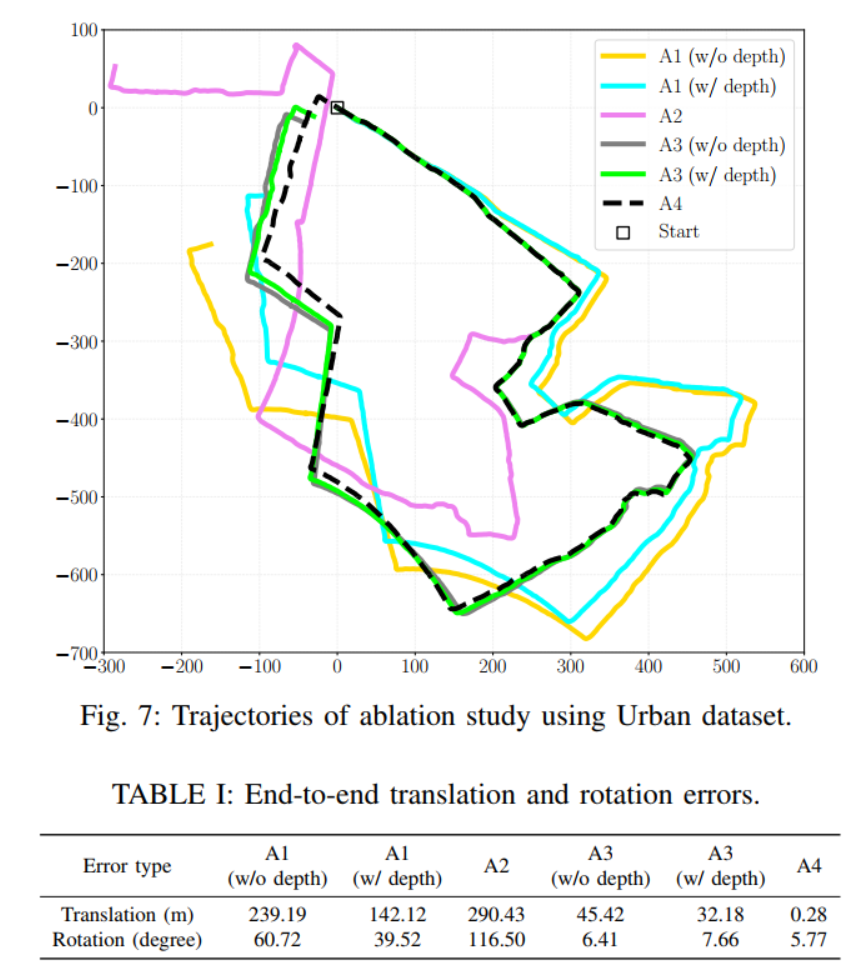
图7 消融实验。A1:不包含LIS;A2:不包含VIS;A3:LIS与VIS都用,测试VIS中深度优化的作用;A4:包含闭环检测

图8 Jackal数据集与Handheld数据集。白色的点为GPS信号覆盖区域。
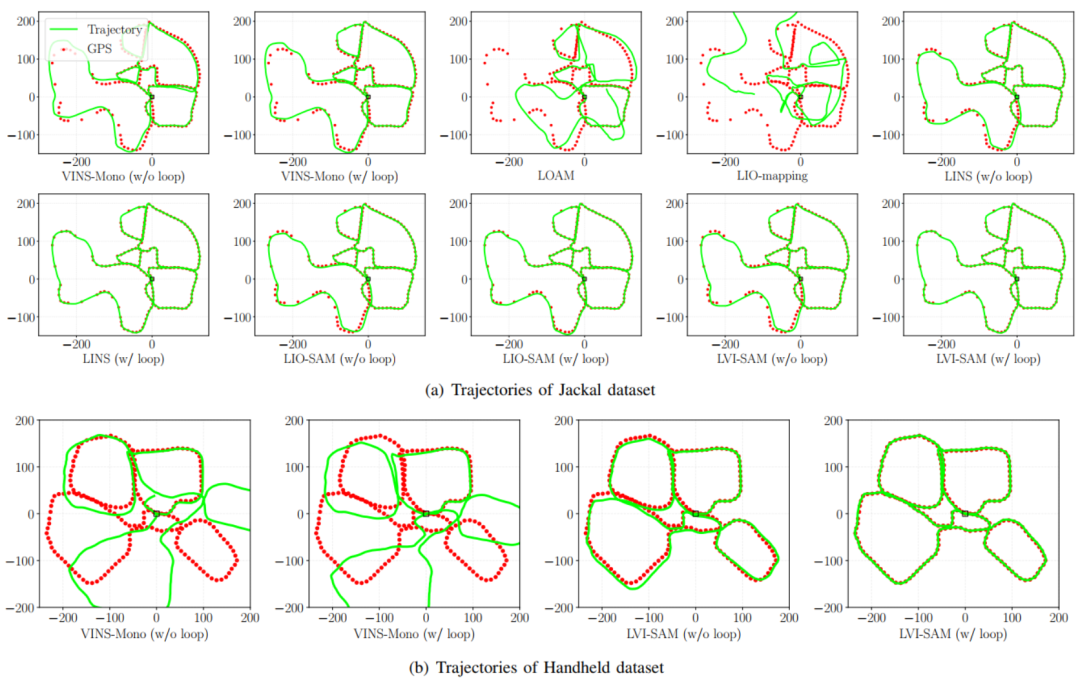
图9 在以上两个数据集中,和各种SOTA算法进行比较测试。
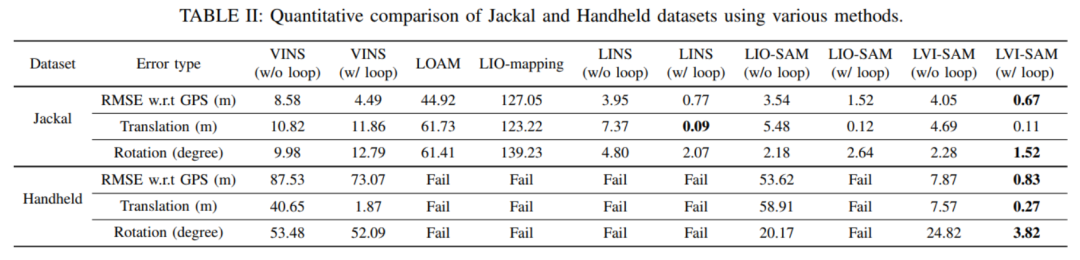
图10 比较的定量结果。

商业合作及转载请联系paopaorobot@163.com
这篇关于LVI-SAM:使用SAM的激光-视觉-惯导紧耦合里程计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




