本文主要是介绍DL Homework 11,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
由于好多同学问我要代码,但这两天光顾着考四六级了,所以只能今天熬夜先给赶出来,第一题先搁置,晚点补上,先写第二题
习题6-4 推导LSTM网络中参数的梯度, 并分析其避免梯度消失的效果
习题6-3P 编程实现下图LSTM运行过程
 1. 使用Numpy实现LSTM算子
1. 使用Numpy实现LSTM算子
import numpy as npx = np.array([[1, 0, 0, 1],[3, 1, 0, 1],[2, 0, 0, 1],[4, 1, 0, 1],[2, 0, 0, 1],[1, 0, 1, 1],[3, -1, 0, 1],[6, 1, 0, 1],[1, 0, 1, 1]])
# x = np.array([
# [3, 1, 0, 1],
#
# [4, 1, 0, 1],
# [2, 0, 0, 1],
# [1, 0, 1, 1],
# [3, -1, 0, 1]])
inputGate_W = np.array([0, 100, 0, -10])
outputGate_W = np.array([0, 0, 100, -10])
forgetGate_W = np.array([0, 100, 0, 10])
c_W = np.array([1, 0, 0, 0])def sigmoid(x):y = 1 / (1 + np.exp(-x))if y >= 0.5:return 1else:return 0temp = 0
y = []
c = []
for input in x:c.append(temp)temp_c = np.sum(np.multiply(input, c_W))temp_input = sigmoid(np.sum(np.multiply(input, inputGate_W)))temp_forget = sigmoid(np.sum(np.multiply(input, forgetGate_W)))temp_output = sigmoid(np.sum(np.multiply(input, outputGate_W)))temp = temp_c * temp_input + temp_forget * tempy.append(temp_output * temp)
print("memory:",c)
print("y :",y)实验结果如下:

这么一看答案是不是和要求一样,确实和要求一样,而且仿照李老师给的图写的代码,但是细心的同学就会发现,代码表达的模型和李老师展示的不一致,不能说不一致,而是按照一般的LSTM模型,候选状态需要由函数作为激活函数,而我们看李老师的图,再
分别为
的时候计算得到的输入值,这里记作
,
应该是3,并且通过激活函数后还是3,这里我们直接垮掉了,因此我经历了长达1小时的挣扎,但得到的答案五花八门,不太靠谱,不得已,抱着追求真理的想法,我去再次听了一遍李老师的手撕LSTM,李老师明确指出了,他将tanh激活函数,也叫做针对输入信息和当前隐状态激活函数输出的激活函数修改了.
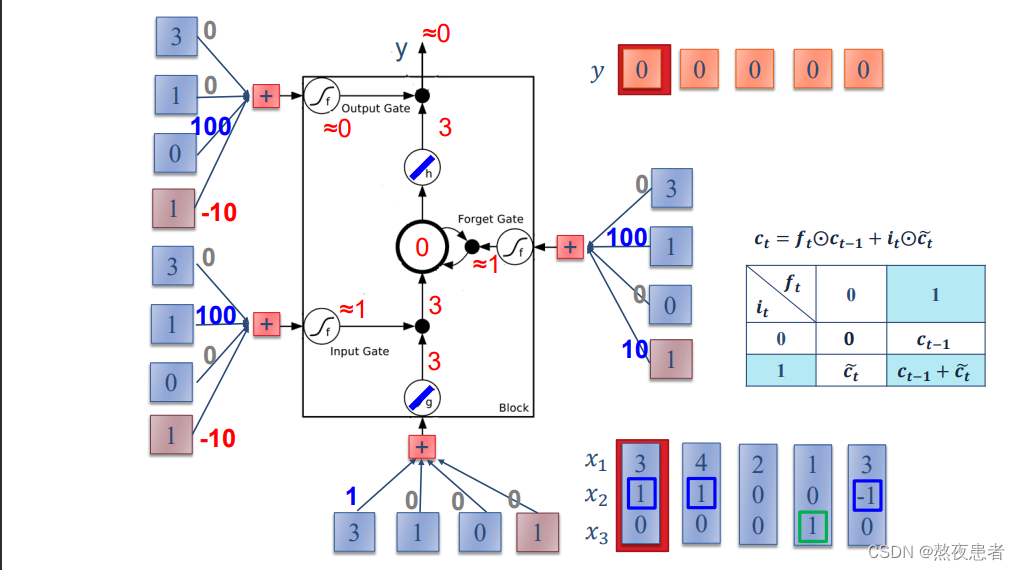
老师是这么说的:input activate function是linear的,memory cell的activate function也是linear的,总结一句话,老师将tanh激活函数换为线性激活函数。所以可以通过输入3,输出也是3
并且将sigmoid的值域修改为【0,1】,只有两个值。与一般的LSTM模型有了细微的差距
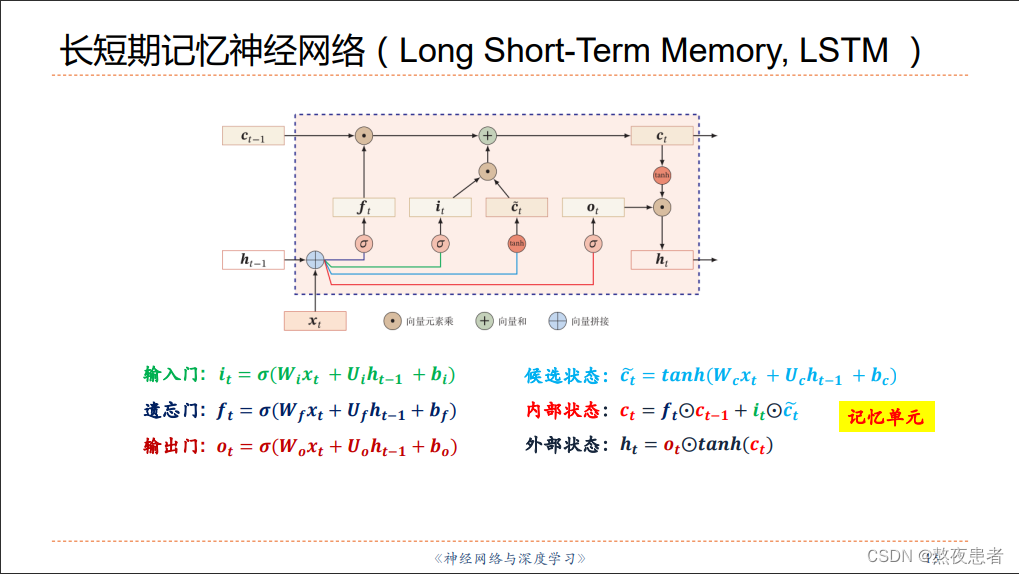
但是通过搜索了大量资料我发现Pytorch不提供修改LSTMCell和RSTM的内部激活函数的端口,所以为了验证后面两个实验的正确性,我仿照一般的LSTM模型手写了一个检测版本如下:
import numpy as npx = np.array([[1, 0, 0, 1],[3, 1, 0, 1],[2, 0, 0, 1],[4, 1, 0, 1],[2, 0, 0, 1],[1, 0, 1, 1],[3, -1, 0, 1],[6, 1, 0, 1],[1, 0, 1, 1]])inputGate_W = np.array([0, 100, 0, -10])
outputGate_W = np.array([0, 0, 100, -10])
forgetGate_W = np.array([0, 100, 0, 10])
c_W = np.array([1, 0, 0, 0])def sigmoid(x):return 1 / (1 + np.exp(-x))temp = 0
y = []
for input in x:temp_c = np.tanh(np.sum(np.multiply(input, c_W)))temp_input = sigmoid(np.sum(np.multiply(input, inputGate_W)))temp_forget = sigmoid(np.sum(np.multiply(input, forgetGate_W)))temp_output = sigmoid(np.sum(np.multiply(input, outputGate_W)))temp = temp_c * temp_input + temp_forget * tempy.append(temp_output * np.tanh(temp))
# print(y)
outputs_rounded = [round(x) for x in y]
print(outputs_rounded)
# 感觉有点问题没用tanh函数啊实验结果如下:

2. 使用nn.LSTMCell实现
当然看函数的用法肯定是官方文档原汁原味,但是排除像我这种英语不好的一看英语脑袋疼,我也发现了一个特别好的中译版的和官方文档内容完全一样。
PyTorch - torch.nn.LSTMCell (runebook.dev)
LSTMCell — PyTorch 2.1 documentation
Parameters
- input_size – 输入
x中预期特征的数量- hidden_size – 隐藏状态下的特征数量
h- 偏差 – 如果
False,则该层不使用偏差权重b_ih和b_hh。默认值:True输入:输入,(h_0, c_0)
- 形状
(batch, input_size)的输入:包含输入特征的张量- h_0 形状为
(batch, hidden_size):包含批次中每个元素的初始隐藏状态的张量。c_0 形状为
(batch, hidden_size):包含批次中每个元素的初始单元状态的张量。如果未提供
(h_0, c_0),则 h_0 和 c_0 均默认为零。输出:(h_1,c_1)
- h_1 形状为
(batch, hidden_size):包含批次中每个元素的下一个隐藏状态的张量- c_1 形状为
(batch, hidden_size):包含批次中每个元素的下一个单元状态的张量Variables:
- ~LSTMCell.weight_ih – 可学习的输入隐藏权重,形状为
(4*hidden_size, input_size)- ~LSTMCell.weight_hh – 可学习的隐藏权重,形状为
(4*hidden_size, hidden_size)
- ~LSTMCell.bias_ih – 可学习的输入隐藏偏差,形状为
(4*hidden_size)- ~LSTMCell.bias_hh – 可学习的隐藏-隐藏偏差,形状为
(4*hidden_size)
这里解释一下,对LSTMCell的模型进行变量初始化的时候,为什么大小为第一维度都为4 * hidden
具体来说,lstm_cell.weight_ih 被划分为以下四个部分(按行分割):
- Forget Gate 的权重:控制前一个隐藏状态中信息被遗忘的程度。这部分的权重用于计算是否要从前一个隐藏状态中丢弃哪些信息。
- Input Gate 的权重:控制新的输入信息对当前隐藏状态的贡献程度。这部分的权重用于计算应该增加哪些新的信息到当前隐藏状态中。
- Candidate Value 的权重:用于计算更新的候选值,它包含了可能添加到当前隐藏状态中的新信息。
- Output Gate 的权重:控制当前隐藏状态对下一时刻输出的贡献程度。这部分的权重用于计算应该输出哪些信息给下一个时间步。
总结的说就是将四个门的参数以行为单位同时封装在一个矩阵中了,其他参数的第一维向量也是如次的含义,ih和hh分别代表的输入层和各个门之间的参数,hh代表输出层与各个门之间的参数。
代码如下:
import torch
import torch.nn as nn# 输入数据 x 维度需要变换,因为LSTMcell接收的是(time_steps,batch_size,input_size)
# time_steps = 9, batch_size = 1, input_size = 4
x = torch.tensor([[1, 0, 0, 1],[3, 1, 0, 1],[2, 0, 0, 1],[4, 1, 0, 1],[2, 0, 0, 1],[1, 0, 1, 1],[3, -1, 0, 1],[6, 1, 0, 1],[1, 0, 1, 1]], dtype=torch.float)
x = x.unsqueeze(1)
# LSTM的输入size和隐藏层size
input_size = 4
hidden_size = 1# 定义LSTM单元
lstm_cell = nn.LSTMCell(input_size=input_size, hidden_size=hidden_size, bias=False)lstm_cell.weight_ih.data = torch.tensor([[0, 100, 0, 10], # forget gate[0, 100, 0, -10], # input gate[1, 0, 0, 0], # output gate[0, 0, 100, -10]]).float() # cell gate
lstm_cell.weight_hh.data = torch.zeros([4 * hidden_size, hidden_size])
#https://runebook.dev/zh/docs/pytorch/generated/torch.nn.lstmcellhx = torch.zeros(1, hidden_size)
cx = torch.zeros(1, hidden_size)
outputs = []
for i in range(len(x)):hx, cx = lstm_cell(x[i], (hx, cx))outputs.append(hx.detach().numpy()[0][0])
outputs_rounded = [round(x) for x in outputs]
print(outputs_rounded)实验结果:
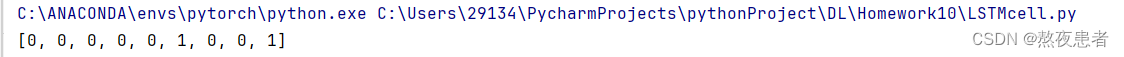
和Numpy流程的结果一致,所以答案正确。
3. 使用nn.LSTM实现
PyTorch - torch.nn.LSTM (runebook.dev)
LSTM — PyTorch 2.1 documentation
依旧是两个链接,个人建议点一下链接自己去看一下,个人感觉和RNN参数及其相似,RNN参数懂了,我感觉这个就没有难度。
Parameters
- input_size – 输入
x中预期特征的数量- hidden_size – 隐藏状态下的特征数量
h- num_layers – 循环层数。例如,设置
num_layers=2意味着将两个 LSTM 堆叠在一起形成stacked LSTM,第二个 LSTM 接收第一个 LSTM 的输出并计算最终结果。默认值:1- 偏差 – 如果
False,则该层不使用偏差权重b_ih和b_hh。默认值:True- batch_first – 如果是
True,则输入和输出张量提供为(batch、seq、feature)。默认:False- dropout – 如果非零,则在除最后一层之外的每个 LSTM 层的输出上引入
Dropout层,dropout 概率等于dropout。默认值:0- 双向 – 如果是
True,则成为双向 LSTM。默认:False- proj_size – 如果是
> 0,将使用具有相应大小投影的 LSTM。默认值:0输入:输入,(h_0, c_0)
- 形状
(seq_len, batch, input_size)的输入:包含输入序列特征的张量。输入也可以是打包的可变长度序列。有关详细信息,请参阅 torch.nn.utils.rnn.pack_padded_sequence() 或 torch.nn.utils.rnn.pack_sequence() 。- h_0 形状为
(num_layers * num_directions, batch, hidden_size):包含批次中每个元素的初始隐藏状态的张量。如果 LSTM 是双向的,则 num_directions 应为 2,否则应为 1。如果指定了proj_size > 0,则形状必须为(num_layers * num_directions, batch, proj_size)。c_0 形状为
(num_layers * num_directions, batch, hidden_size):包含批次中每个元素的初始单元状态的张量。如果未提供
(h_0, c_0),则 h_0 和 c_0 均默认为零。输出:输出,(h_n, c_n)
形状
(seq_len, batch, num_directions * hidden_size)的输出:对于每个t,包含来自 LSTM 最后一层的输出特征(h_t)的张量。如果 torch.nn.utils.rnn.PackedSequence 作为输入,输出也将是压缩序列。如果指定proj_size > 0,输出形状将为(seq_len, batch, num_directions * proj_size)。对于未包装的情况,可以使用
output.view(seq_len, batch, num_directions, hidden_size)来区分方向,向前和向后分别是方向0和1。同样,在包装盒中,方向可以分开。h_n 形状为
(num_layers * num_directions, batch, hidden_size):包含t = seq_len隐藏状态的张量。如果指定了proj_size > 0,则h_n形状将为(num_layers * num_directions, batch, proj_size)。与输出一样,可以使用
h_n.view(num_layers, num_directions, batch, hidden_size)来分离层,对于 c_n 也类似。- c_n 形状为
(num_layers * num_directions, batch, hidden_size):包含t = seq_len细胞状态的张量。
代码如下:
import torch
import torch.nn as nn# 输入数据 x 维度需要变换,因为 LSTM 接收的是 (sequence_length, batch_size, input_size)
# sequence_length = 9, batch_size = 1, input_size = 4
x = torch.tensor([[1, 0, 0, 1],[3, 1, 0, 1],[2, 0, 0, 1],[4, 1, 0, 1],[2, 0, 0, 1],[1, 0, 1, 1],[3, -1, 0, 1],[6, 1, 0, 1],[1, 0, 1, 1]], dtype=torch.float)
x = x.unsqueeze(1)# LSTM 的输入 size 和隐藏层 size
input_size = 4
hidden_size = 1# 定义 LSTM 模型
lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size, bias=False)# 设置 LSTM 的权重矩阵
lstm.weight_ih_l0.data = torch.tensor([[0, 100, 0, 10], # forget gate[0, 100, 0, -10], # input gate[1, 0, 0, 0], # output gate[0, 0, 100, -10]]).float() # cell gate
lstm.weight_hh_l0.data = torch.zeros([4 * hidden_size, hidden_size])# 初始化隐藏状态和记忆状态
hx = torch.zeros(1, 1, hidden_size)
cx = torch.zeros(1, 1, hidden_size)# 前向传播
outputs, (hx, cx) = lstm(x, (hx, cx))
outputs = outputs.squeeze().tolist()# print(outputs)
outputs_rounded = [round(x) for x in outputs]
print(outputs_rounded)输出结果如下:

【23-24 秋学期】NNDL 作业11 LSTM-CSDN博客
台大李宏毅机器学习——RNN | 碎碎念 (samaelchen.github.io)
LSTM两个激活函数不能一样_lstm activation-CSDN博客
李宏毅手撕LSTM_哔哩哔哩_bilibili
这篇关于DL Homework 11的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




