本文主要是介绍Nature chemistry|机器学习可以克服自组装肽发现中的人类偏见,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

题目:Machine learning overcomes human bias in the discovery of self-assembling peptides
文献来源:Nature Chemistry | Volume 14 | December 2022 | 1427–1435
代码:https://doi.org/10.5281/zenodo.6564202(非商业化证书)
内容:
1.摘要
从组织工程和表面涂层到传感和催化,肽材料都发挥着广泛的功能。一般来说,组成肽的氨基酸序列变化会改变肽的功能作用,此外,序列长度的细微增加都会导致候选肽数量的急剧增加。肽的设计常常是由人类的专业知识和经验来决定的,并且每次研究的肽的长度常常小于10个。但是由人类决定的肽设计的方案常常不容易被推展且易受到主观偏见的影响。在这里,作者介绍了一种名为AI-expert的机器学习框架,通过使用完全自主的计算搜索引擎来发现具有潜力的自组装肽序列。该方法主要结合了蒙特卡洛树搜索,随机森林以及分子动力学模拟。作者通过有效搜索了三肽和五肽的大空间有效证明了方法的有效性。AI-expert具有与我们的人类专家相当或更好的预测效果,并提出了几个具有高自组装倾向的非直觉序列,说明了其克服人类偏见和加速肽发现的潜力。
2.背景介绍
自组装肽在不同的地方具有很多重要的作用,其自组装的结构及其功能很大程度上依赖于氨基酸序列,而氨基酸序列的选择非常依赖自然序列、人类专业知识、经验和直觉等方面。传统的肽设计方法利用疏水性尺度将氨基酸划分为亲水疏水性性以及来自于α-螺旋以或β-折叠中的氨基酸二级结构性质表。在大分子肽的设计中,这种方式往往引入对中到高疏水性的高β-sheet倾向氨基酸(例如缬氨酸、异亮氨酸和苯丙氨酸)的偏向。另一个偏差则来自于常用的模式策略,如pnnnp或npnpn(p =极性,n=非极性),它们导致富集β-折叠的纳米结构。使用这种具有偏见的方法的原因是因为肽组合的空间过大。
肽设计的一个主要挑战是需要有效地通过这个复杂的氨基酸序列搜索空间,并提出一个最具潜在性的子集。人工智能(AI)和基于机器学习的策略通过平衡探索与开发的权衡(e exploration-versus-exploitation tradeoff),使这一目标成为现实。在这篇文章中,作者使用AI-expert来识别水中高聚合的五肽,该方法涵盖了蒙特卡洛树搜索(MCTS)以及CG 分子模拟(CG)。具体流程可见图1。
利用MTCS,AI-expert会决定哪些肽序列进行MD模拟并且提供并提供建模肽(s)的分数作为反馈,以指导后续的搜索。与暴力或基于网格的方法探索所有可能性的情况相比,,MCTS通过关注搜索空间中最有前途的领域,即高评分(开发)和多样性(探索)序列,简化了搜索。通过在MCTS目标函数中引入一个新的唯一性函数概念,并利用基于随机森林(RF)的替代模型来绕过一些昂贵的MD仿真评估,提高了MCTS算法性能。该研究的评分系统由溶剂可接触面积(solvent-accessible surface)和Wimley-White尺度组成,分别量化一个肽的计算AP(aggregation propensitie)和疏水性。虽然前者是基于只有经过密集时间的MD模拟后才能获得,但后者只给定肽序列就可以立即进行评估,计算成本比较小。
在320万种的五肽中,AI-expert使用计算(MD模拟)取样并评估了大约6600个分子。以这种方法确定的前100个五肽以更长的时间尺度(200 ns)进行建模,通过使用更严格的MD模拟参数来进行AP评估。前9个序列用于实验合成和研究,其中6个序列是根据光散射和原子力显微镜(AFM)测量被发现聚集的。而人类专家提出的11个肽序列中有5个是聚集的。作者发现AI-expert不仅可以通过现有的知识给出和人类化学家相似的肽序列,也能探索未知的或者隐性的自组装肽来克服人类偏见。

图1 人类科学家和AI-expert发现自组装五肽的工作流程。由于20个氨基酸的存在,肽的搜索空间随序列长度急剧增长。虽然可以探索8000个可能的三肽(计算)使用暴力方法进行组装,但320万(M)的五肽的空间是难以解决的。人类专家使用合理的设计方法,如疏水性尺度,电荷平衡,模式化(npnpn: n, non-polar; p, polar)以及其自身独有的实验经验来设计自组装肽。在11个人类专家设计的五肽中,有6个肽显示可以聚集。这些序列体现出了人类科学家对于氨基酸V、F、K和E的偏好性。而AI-expert结合MCTS(A)、MD(B)以及打分函数(C)可以有效地搜索到自组装肽。除了再现一些直观的序列(FFEKF),AI-expert也会推荐一些创新性的序列(SYCGY,RWLDY),而这提现了其克服人类偏见的一些好处。同时,一些具有潜力的五肽的分子表示以及AFM图展示在这里。
3.结果以及讨论
3.1AI-expert的肽发现
AI-expert主要是通过MCTS以及MD模拟进行寻找评估多肽。值得注意的是,程序可以在这两个模块进行切换。为了增加MCTS的作用,作者引入了两个策略。唯一性函数f(θj)和一个随机森林(RF)模型引导的推出策略。这个唯一性的函数可以促使MCTS的选择更加多样性。而RF模型可以用来快速预测给定其序列的肽的AP,当AP低的时候,可以考虑不使用MD的计算成本,但是这个方法可能会导致错过一些具有潜力的序列。因为随机森林的计算结果和MD的计算结果只是近似。
3.2三肽验证
作者首先对三肽的空间进行研究,来证明AI-expert在发现自组装肽的能力。做出这种决定的原因有两个:三肽的空间结构有8000个,是一个可计算的空间范围。另外,以前也有MD实验进行了暴力探索三肽的研究。因此,根据AP以及疏水性和以前工作的经验可以进行自组装的有效评估。

图2 不同策略搜索三肽空间的性能比较 a,得分最高的三肽的例子及其计算分数的分子表示。括号中的数字表示(左)聚集倾向(AP)和(右)疏水性(logP)值。氨基酸(AA)颜色编码:酸性AAs,红色;碱性AAs,蓝色;极性AAs,黄色;芳香族AAs,橙色。b,比较从8000个病例的完整空间中搜索得分最高的三肽所需的试验次数。与随机或暴力搜索相比,使用MCTS或MCTS + RF的AI-expert搜索策略的平均试验次数更少,且找到得分最高的三肽(SYY)。c,比较使用随机、MCTS或MCTS + RF搜索策略生成的肽序列的得分。实线表示各自的归一化密度。使用MCTS + RF方案的人工智能专家在识别高评分肽方面最有效,因为其生成的肽群中有较大比例的高分数。
为了衡量AI-expert比普通方法好,作者首先对所有8000个分子进行了MD模拟,并根据他们的得分对它们进行了排序,得分函数如下所示:
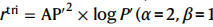
图2a展示了一些得分较高的三肽。虽然作者的结果与之前的方法有所不同,但是总体的AP以及疏水性趋势都很一致。这种差异可能是由于MD模拟的随机性或AP计算的软件选择而引入的AP计算微小变化造成的。
图2b比较了不同方法识别得分最高的三肽(SYY)所花费的时间。可以看出,与纯随机推出策略的MCTS相比,使用RF增强MCTS(标记MCTS + RF)的AI-expert平均需要识别得分最高的SYY序列的试验次数要少得多。这表明,利用模型开发的推荐策略确实有助于AI-expert有效地识别高评分肽。图2c比较了不同方案生成的肽集质量。很明显,MCTS + RF方案获得了较多的采样高评分三肽,其次是MCTS,然后是随机搜索。总的来说,这些结果验证了人工智能专家可以有效地识别高评分的多肽,而不求助于时间密集型的暴力搜索。
3.3五肽筛选
在验证了AI-expert对三肽的效率后,接下来作者使用它来发现自组装的五肽,它们有320万(M)(205)排列。如此大的搜索空间使得蛮力搜索不可能进行,并激发了对人工智能引导搜索的需求。采用MCTS +RF方案的AI-expert对奖励功能的设置略有不同,使搜索倾向于既不太亲水(容易溶解)也不太疏水(难以形成水凝胶)的五肽:
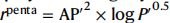
(α=2,β=0.5)
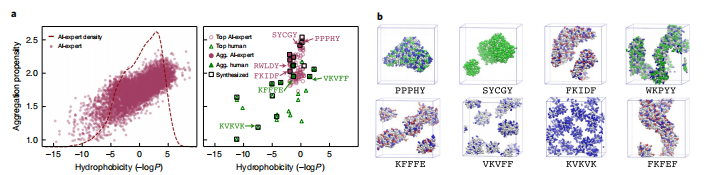
图3 来自AI-expert和人类专家的五肽的筛选。a,左:使用评分函数rpenta对AI-expert进行的基于MCTS+rf的计算搜索的结果。logP在0和−4之间的一个宽峰表明产生了中等疏水肽,在聚集倾向(AP)和疏水性之间表现出良好的平衡。AP的结果是基于较短的MD模拟(50 ns)。利用核密度估计估计人工智能专家提出的五肽的概率密度函数。右图:由AI-expert筛选的顶级肽(使用rpenta的前100名),由人类专家建议,以及那些被选择进行合成的肽。AP的结果是基于更长的MD模拟(200 ns)。b,MD模拟结果(200 ns),例如来自AI-expert(第一行)和人类专家(下一行)的得分最高的五肽,显示了不同的聚集水平。
五肽结果评估如图3a所示。从计算的角度来看,在所有选择的100个例子中都观察到大量的聚集(图3b的顶部一行显示了一些五肽结构的例子)。与AI-expert类似,几位人类专家被要求提出他们自己希望组装的五肽序列。提供了一套简单的指导方针(方法)。为此,他们收集了29个五肽。许多文献中关于自组装五肽的例子包括N端和c端修饰(分别为乙酰化或氨基甲酰化),以促进组装。然而,在这项工作中,人类专家被要求保留五肽末端,这与人工智能专家采用的工作流程一致。这些序列的AP和logP值分别使用MD模拟和疏水性尺度进行了评估。
AI-expert的前100个五肽(红色标记)和人类专家的29个序列(绿色标记)的结果如图3a(右面板)所示。根据光散射和显微镜测量,还得到了合成的候选物(黑色标记)和可聚集候选物(填充标记)。作者发现,AI-expert筛选的好序列比人类专家提出的序列的logP范围小。这是因为AI-expert筛选只根据评分功能来筛选候选物,而人类专家则依赖于许多因素,如模式、疏水性量表和个人过去的经验。其次,AI-expert选出的序列一般比人类专家具有更高的AP值。而这意味着,至少从计算模型的角度来看,AI-expert确实发现了具有更高聚集程度的五肽序列。第三,许多被计算发现具有高AP值的序列在实验合成中没有显示任何组装。这些案例突出了MD力场在捕获肽中准确聚集行为方面的局限性。同时也体现了本工作中使用的奖励功能的不足/简单性,因为它仅包括AP和logP值。
3.4自组装五肽的发现
本节涵盖了20个合成的五肽的细节和观察到的自组装结构。固相肽合成器(SPP)制备了人类专家推荐的29个序列中的11个肽以及AI-expert建议的100个序列中的9个肽,肽的末端不被修饰(即最终产物的胺基和羧基不受保护)作者注重的是是肽段聚集和/或组装的能力,在这里区分两个看似相似的术语是很重要的:聚集(aggregation)和组装(assembly)。聚集意味着缺乏明显的结构,而组装意味着存在纳米、中观和微尺度的特征,如胶束、囊泡、纤维和薄片,也就是结构性。因此,为了对聚合/组装结构进行详细分析,并找到与计算的logP和AP值类似的实验量,对每个合成的五肽进行了液相色谱(LC)、质谱、红外光谱、AFM和不透明度测量。其具体内容可参考图4。
人类专家设计的富含苯丙氨酸的肽,与人工智能专家鉴定的肽相似,具有形成纳米结构的高倾向。在KFAFD、FKFEF、VKVFF(球形束)和KFFFE(纳米板)中发现了纳米级纤维。许多来自人类专家的富含缬氨酸的多肽在干燥后形成纤维结构(VKVKV、KVKVK和RVSVD),但没有观察到溶液结构的证据。有趣的是,在相对疏水的(logP =−2.3)VVVVV中观察到25nm高度的大血小板。尽管VKVEV具有高度亲水性(logP = 5.05),但其凝胶作用是使pH增加到7。因此,人类专家提出的11个五肽中的6个形成了纳米结构,其中大多数形成了β-sheet构象。
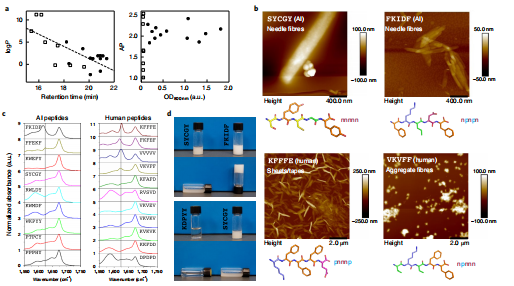
图4 五肽自组装的实验测量。a,由AI-expert和人类专家提出的20个合成的五肽的RT和不透明度(OD 800 nm)测量。被发现聚集的多肽显示为填充的圆圈。虽然发现RT与logP呈线性相关(用虚线拟合线表示),但在800 nm处的OD值与计算出的AP值相似。b,AFM图像(代表三个产生类似结果的试验),例如在本工作中合成的五肽,以及它们的混合极性(p)和非极性(n)氨基酸的分子表示和模式。可以看到纤维、薄片/磁带和其他不规则形状的聚集体。AA颜色编码:酸性AAs,红色;碱性AAs,蓝色;极性AAs,黄色;芳香的AAs,橙色。c,由AI-expert和人类专家建议的20个合成的五肽的红外光谱测量。在1600厘米−1附近的峰值突出了许多人类专家选择的系统中二级结构(β-shets)的形成,这在AI-expert是比较少见的。d,不同肽形成的凝胶、溶液和悬浮液的照片。
3.5 AI-expert与人类专家的性能比较
就预测五肽组装的整体能力而言,AI-expert的表现与我们的人类专家相当或者说是略好一些。如图5a所示,人工智能专家(使用r penta)的成功率为66.67%,而人类专家的成功率为54.5%。然而,我们认为,聚合成功率本身并不足以作为评估性能的充分指标。AI-expert和人工合理设计方法之间的另一个差异在于氨基酸缬氨酸和脯氨酸。AI-expert选择的多肽很少含有缬氨酸,但人类专家展现了对它的倾向(例如,KVKVK、RVSVD和VKVEK)。一般来说,使用缬氨酸是由于其较高的β-sheet倾向,这往往导致自组装的排序。脯氨酸的情况则相反;虽然一些AI-expert的序列是由这种氨基酸主导的,但没有一个人类专家认为它有助于任何类型的组装。补充实验表明,没有一个含脯氨酸的五肽聚集,这表明了AI-expert的局限性。

图5 AI-expert与人类专家的性能比较。a,b,根据AI-expert和人类专家的聚合成功率(a)和计算和实验分数(b)来评估性能。c,计算分数和实验分数之间的相关关系,有(底部)和没有(顶部)β-sheet因子。虽然较高的计算分数并不一定表明聚集,但超过0.01(虚线)的实验分数可以很好地捕获肽聚集。
3.6 AI-expert可以改进的地方
AI-expert成功的关键原因是它的评分功能,但这需要非常仔细地设计。为了显示它对AI-expert的性能的显著影响,作者再次使用AI-expert来设计五肽,但这次的奖励是rtri。这主要产生了高度亲水性的候选物,logP值在2到6之间,如图1所示。尽管得分很高(基于rtri),这些候选物可能溶于水但具有任何组装性。采用了类似的筛选程序,基于较长的MD模拟(200 ns),从前100个候选物中合成了10个分子。10个分子中只有2个,KFFFDY和FFEKF,产生了聚集物,成功率仅为20%。因此,选择一个具有指导性的评分功能是人工智能专家的关键,加权参数α和β需要根据肽的序列长度n仔细调整。
作者也注意到,AI-expert没有从实际实验中得到任何反馈,并且在计算量(rpenta)和实验分数之间只存在适度的相关性,如图所示5c所示。
作者未来的愿景是开发一个完全自主的肽设计平台,在该平台中,AI-expert与一个能够合成和表征新序列的机器人平台进行交互,其反馈由AI-expert直接消化,提出新的序列,然后以迭代的方式进行搜索。为了加速这一过程,来自模拟的输入也可以用来避免低评分的肽段。目前的方案的另一个局限性是,AI-expert不能预测自组装纳米结构的形态(纤维、β-薄片、磁带等)。因此仍需要改进奖励函数,包括来自模拟的额外信息,如肽簇的数量和纵横比,它们的形态和惯性矩等,以提高AI-expert的能力。在未来,引入β-sheet因子或结合来自(高通量)实验的直接反馈,有望提高AI-expert的性能。
4.结论
识别新的短自组装肽是合成和分子设计的未来。因为搜索大型的化学空间(20n,其中n是肽的长度)是非常棘手的,所以有必要发展ai为基础的肽研究。在这里,作者开发了人工智能专家,利用MD模拟和疏水性(logP)尺度来评估320万个可能的五肽中的6600个的聚集倾向。此外,专业的肽设计者也提供了具有潜在性的序列。作者对人工智能专家的前9个序列和人类专家的11个候选序列进行了合成和表征。一个实验性评分系统(样本不透明度与HPLC RT),反映了AI评分系统(聚合倾向与疏水性相比)在识别人工智能专家和人类专家的方法中的失败和成功方面至关重要。总的来说,AI-expert的表现(66.7%)优于我们的人类专家(54.5%)。AI-expert不仅理解已知的设计策略,如识别电荷平衡的富含苯丙氨酸的多肽(AI,FKIDF和FFEKF;人类,KFFFE和FKFEF),它还可以发现了明显不同于传统方法的新序列(例如,SYCGY)。
人类偏倚被证明倾向于具有高β-sheet倾向评分的五肽,并被用作改进人工智能评分指标的机会。将β-sheet因子纳入AI得分,使排名趋向正确的方向,虽然这不完全等同于实验中的排名。作者未来的努力将集中于高通量肽合成与已开发的实验评分系统的应用,为人工智能专家提供一个实验反馈回路,超出了目前实现的理论指标(AP和logP)。类似的人工智能策略可以扩展到筛选小的肽库以获得更具体的应用。虽然这项研究证明了人工智能专家在发现自组装肽方面的成功,但它可以扩展到发现功能肽组装,用于光捕获、催化、机械稳定性和电导率。
-------------------------------------------
欢迎点赞收藏转发!
下次见!
这篇关于Nature chemistry|机器学习可以克服自组装肽发现中的人类偏见的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








