本文主要是介绍Flink Window中典型的增量聚合函数(ReduceFunction / AggregateFunction),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、什么是增量聚合函数
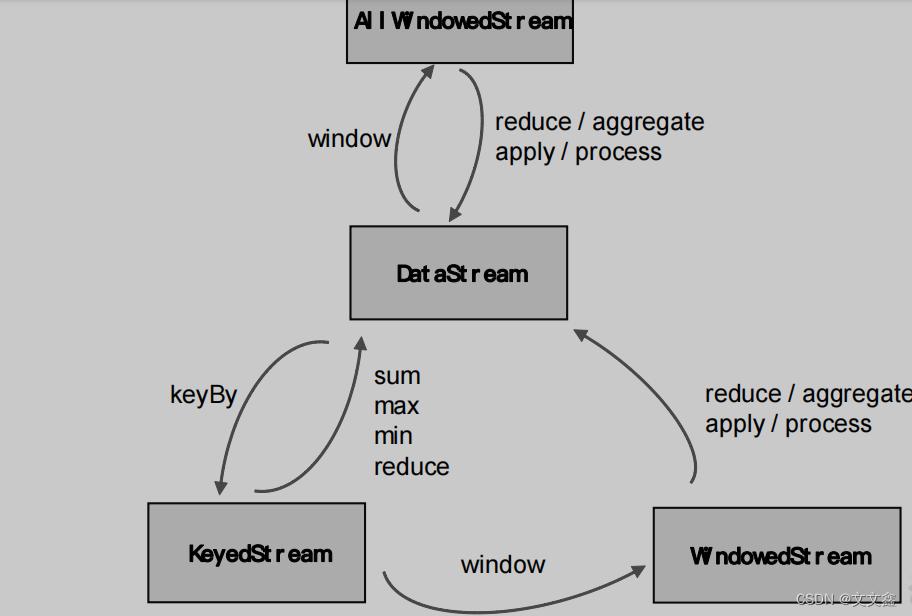
在Flink Window中定义了窗口分配器,我们只是知道了数据属于哪个窗口,可以将数据收集起来了;至于收集起来到底要做什么,其实还完全没有头绪,这也就是窗口函数所需要做的事情。所以在窗口分配器之后,我们还要再接上一个定义窗口如何进行计算的操作,这就是所谓的“窗口函数”(window functions)。
窗口可以将数据收集起来,最基本的处理操作当然就是基于窗口内的数据进行聚合。
我们可以每来一个数据就在之前结果上聚合一次,这就是“增量聚合”。
典型的增量聚合函数有两个:ReduceFunction 和 AggregateFunction。
二、归约函数ReduceFunction
源码解析
@FunctionalInterface
@Public
public interface ReduceFunction<T> extends Function, Serializable {T reduce(T var1, T var2) throws Exception;
}
实际案例
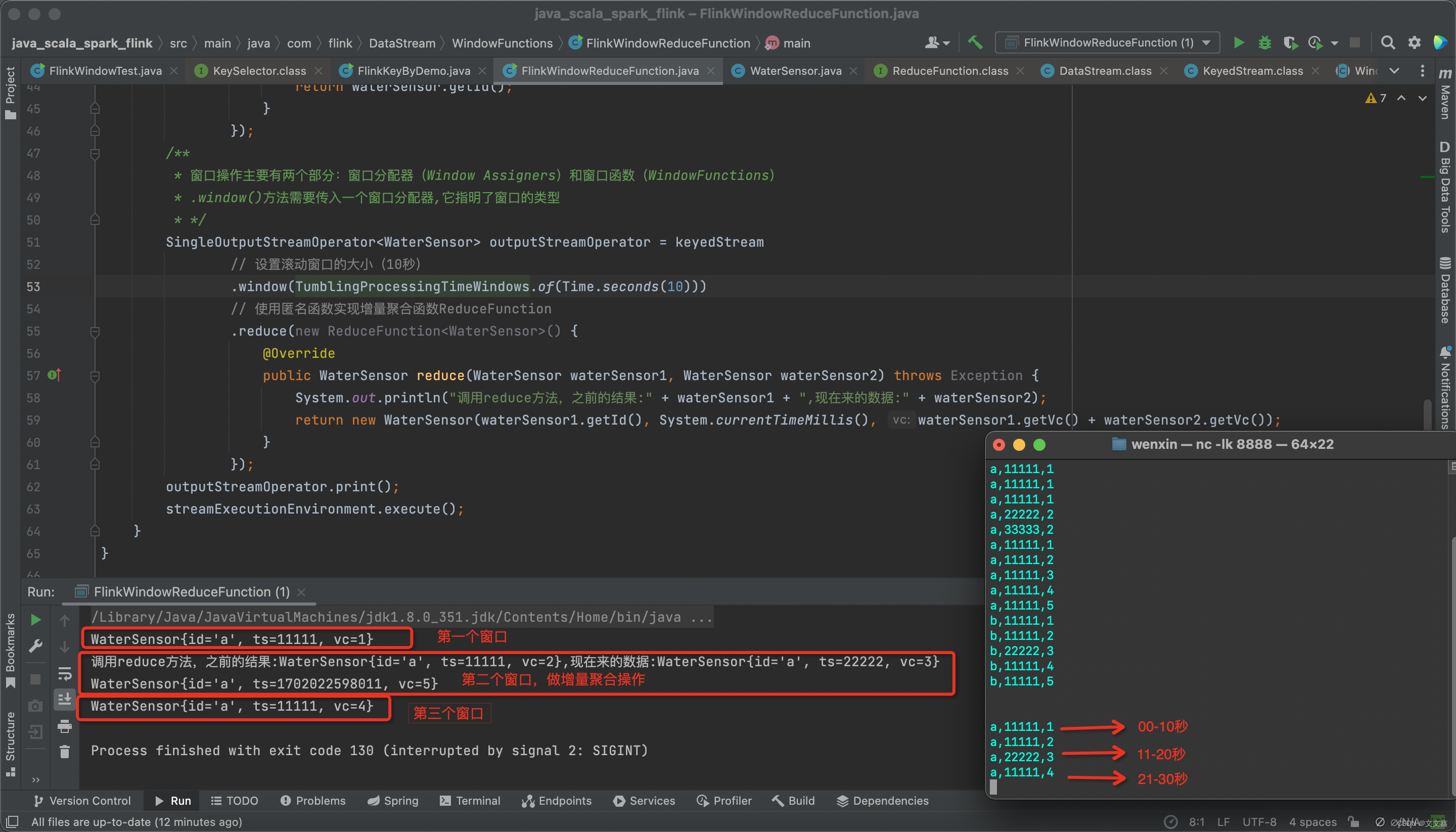
在Flink中,使用socket模拟实时的数据流DataStream,通过定义一个滚动窗口,窗口的大小为10s,按照id分区,使用reduce聚合函数实现value的累加统计
package com.flink.DataStream.WindowFunctions;import com.flink.POJOs.WaterSensor;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;public class FlinkWindowReduceFunction {public static void main(String[] args) throws Exception {StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();streamExecutionEnvironment.setParallelism(1);DataStreamSource<String> streamSource = streamExecutionEnvironment.socketTextStream("localhost", 8888);// 注意这里为什么返回的是KeyedStream(建控流/分区流),而不是DataStreamKeyedStream<WaterSensor, String> keyedStream = streamSource// 使用map函数将输入的string转为一个WaterSensor类.map(new MapFunction<String, WaterSensor>() {@Overridepublic WaterSensor map(String s) throws Exception {// 这里写的很详细,如何把string转为的WaterSensor类String[] strings = s.split(",");String id = strings[0];Long ts = Long.valueOf(strings[1]);Integer vc = Integer.valueOf(strings[2]);WaterSensor waterSensor = new WaterSensor();waterSensor.setId(id);waterSensor.setTs(ts);waterSensor.setVc(vc);return waterSensor;//return new WaterSensor(strings[0],Long.valueOf(strings[1]),Integer.valueOf(strings[2])}})// 按照id做keyBy分区(提问:KeyBy是如何实现分区的?).keyBy(new KeySelector<WaterSensor, String>() {// 也可以直接使用lamda表达式更简单@Overridepublic String getKey(WaterSensor waterSensor) throws Exception {// getId()方法就是return的waterSensor.idreturn waterSensor.getId();}});/*** 窗口操作主要有两个部分:窗口分配器(Window Assigners)和窗口函数(WindowFunctions)* .window()方法需要传入一个窗口分配器,它指明了窗口的类型* */SingleOutputStreamOperator<WaterSensor> outputStreamOperator = keyedStream// 设置滚动窗口的大小(10秒).window(TumblingProcessingTimeWindows.of(Time.seconds(10)))// 使用匿名函数实现增量聚合函数ReduceFunction.reduce(new ReduceFunction<WaterSensor>() {@Overridepublic WaterSensor reduce(WaterSensor waterSensor1, WaterSensor waterSensor2) throws Exception {System.out.println("调用reduce方法,之前的结果:" + waterSensor1 + ",现在来的数据:" + waterSensor2);return new WaterSensor(waterSensor1.getId(), System.currentTimeMillis(), waterSensor1.getVc() + waterSensor2.getVc());}});outputStreamOperator.print();streamExecutionEnvironment.execute();}
}
启动Flink程序,启动nc,模拟输入
nc -lk 8888
# 00-10秒输入
a,11111,1
# 11-20秒输入
a,11111,2
a,22222,3
# 21-30秒输入
a,11111,4
查看控制台打印结果
WaterSensor{id='a', ts=11111, vc=1}
调用reduce方法,之前的结果:WaterSensor{id='a', ts=11111, vc=2},现在来的数据:WaterSensor{id='a', ts=22222, vc=3}
WaterSensor{id='a', ts=1702022598011, vc=5}
WaterSensor{id='a', ts=11111, vc=4}
三、聚合函数AggregateFunction
虽然ReduceFunction 可以解决大多数归约聚合的问题,但是我们通过上述案例可以发现:这个接口有一个限制,就是聚合状态的类型、输出结果的类型都必须和输入数据类型一样。
Flink Window API 中的 aggregate 就突破了这个限制,可以定义更加灵活的窗口聚合操作。这个方法需要传入一个 AggregateFunction 的实现类作为参数。AggregateFunction 可以看作是 ReduceFunction 的通用版本,这里有三种类型:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。输入类型 IN 就是输入流中元素的数据类型;累加器类型 ACC 则是我们进行聚合的中间状态类型;而输出类型当然就是最终计算结果的类型了。
源码解析
@PublicEvolving
public interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable {ACC createAccumulator();ACC add(IN var1, ACC var2);OUT getResult(ACC var1);ACC merge(ACC var1, ACC var2);
}
接口中有四个方法:
1.createAccumulator()
创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次。
2.add()
将输入的元素添加到累加器中。
3.getResult()
从累加器中提取聚合的输出结果。
4.merge()
合并两个累加器,并将合并后的状态作为一个累加器返回。
所以可以看到,AggregateFunction 的工作原理是:首先调用 createAccumulator()为任务初始化一个状态(累加器);而后每来一个数据就调用一次 add()方法,对数据进行聚合,得到的结果保存在状态中;等到了窗口需要输出时,再调用 getResult()方法得到计算结果。很明显,与 ReduceFunction 相同,AggregateFunction 也是增量式的聚合;而由于输入、中间状态、输出的类型可以不同,使得应用更加灵活方便。
案例解析
package com.flink.DataStream.WindowFunctions;import com.flink.POJOs.WaterSensor;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;public class FlinkWindowAggregateFunction {public static void main(String[] args) throws Exception {StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();streamExecutionEnvironment.setParallelism(1);DataStreamSource<String> streamSource = streamExecutionEnvironment.socketTextStream("localhost", 8888);KeyedStream<WaterSensor, String> keyedStream = streamSource.map(new MapFunction<String, WaterSensor>() {@Overridepublic WaterSensor map(String s) throws Exception {String[] split = s.split(",");return new WaterSensor(split[0], Long.valueOf(split[1]), Integer.valueOf(split[2]));}}).keyBy((KeySelector<WaterSensor, String>) waterSensor -> waterSensor.getId());// 窗口分配器WindowedStream<WaterSensor, String, TimeWindow> windowAssigner = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(20)));SingleOutputStreamOperator<String> aggregate = windowAssigner.aggregate(new AggregateFunction<WaterSensor, Integer, String>() {@Overridepublic Integer createAccumulator() {System.out.println("创建累加器");return 0;}@Overridepublic Integer add(WaterSensor value, Integer accumulator) {System.out.println("调用add方法,value=" + value);return accumulator + value.getVc();}@Overridepublic String getResult(Integer accumulator) {System.out.println("调用getResult方法");return accumulator.toString();}@Overridepublic Integer merge(Integer integer, Integer acc1) {System.out.println("调用merge方法");return null;}});aggregate.print();streamExecutionEnvironment.execute();}}
启动Flink程序,启动nc,模拟数据流输入

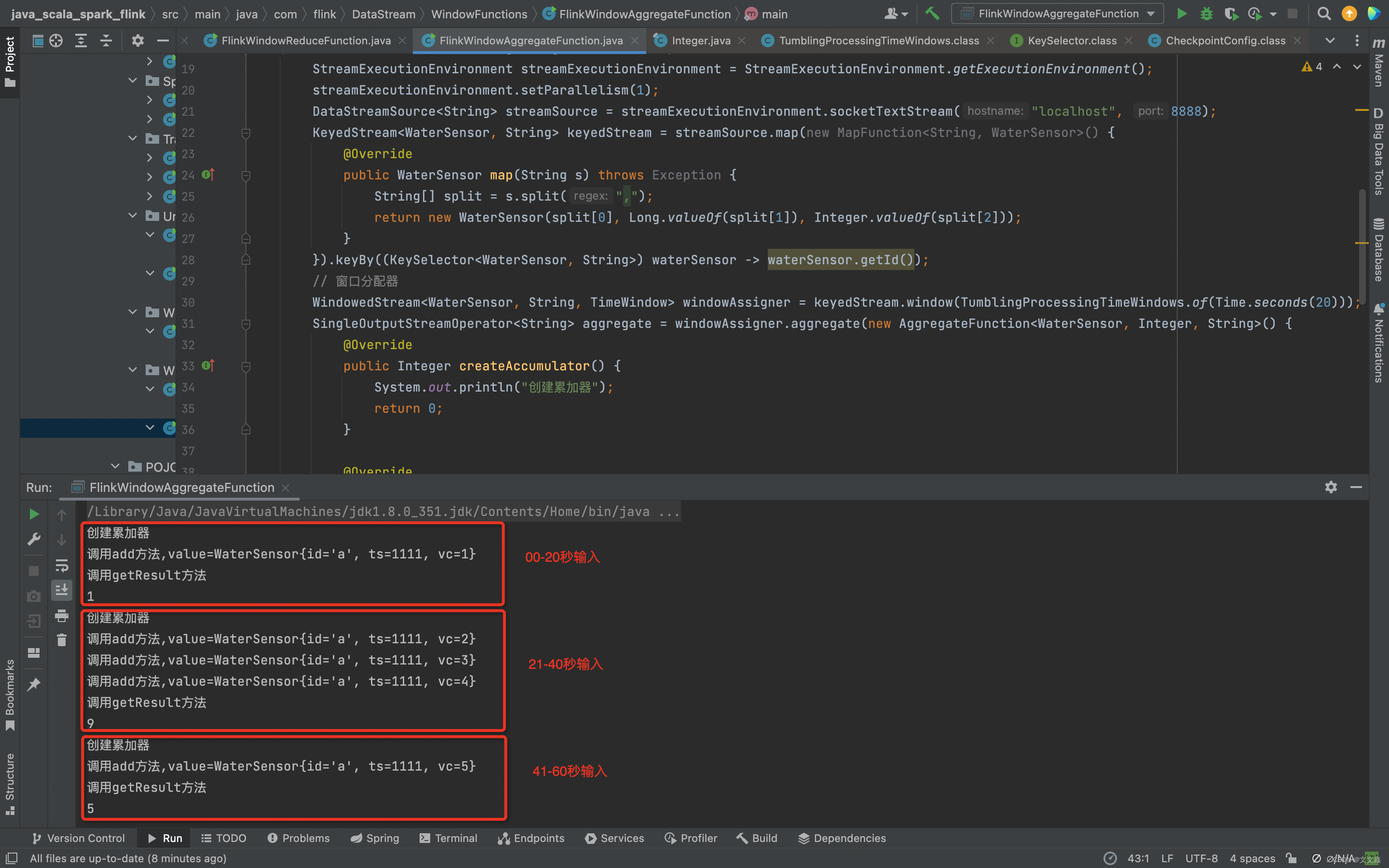
创建累加器
调用add方法,value=WaterSensor{id='a', ts=1111, vc=1}
调用getResult方法
1
创建累加器
调用add方法,value=WaterSensor{id='a', ts=1111, vc=2}
调用add方法,value=WaterSensor{id='a', ts=1111, vc=3}
调用add方法,value=WaterSensor{id='a', ts=1111, vc=4}
调用getResult方法
9
创建累加器
调用add方法,value=WaterSensor{id='a', ts=1111, vc=5}
调用getResult方法
5
这篇关于Flink Window中典型的增量聚合函数(ReduceFunction / AggregateFunction)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







