本文主要是介绍文章解读与仿真程序复现思路——电网技术EI\CSCD\北大核心《考虑场间功率时移的海上风电场群联合储能优化调度方法》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这个标题涉及到海上风电场群(Offshore Wind Farm Cluster)的联合储能优化调度方法,并强调了对场间功率时移的考虑。以下是对标题各部分的解读:
-
海上风电场群: 指的是多个相邻或连接的海上风电场的集合体。通常,风电场群能够协同运行,以提高整体的电力生成效率、可靠性或经济性。
-
联合储能: 指的是在不同风电场之间或整个风电场群内共享储能资源。这可能包括电池储能系统、储水设施等,旨在平衡电力生产和消耗,提高系统的灵活性和可调度性。
-
优化调度方法: 指的是一种系统化的方法,用于在不同的操作和环境条件下制定风电场群和储能系统的调度计划。此过程可能涉及最大化发电效率、降低成本、提高系统可靠性等目标。
-
考虑场间功率时移: 指的是在优化调度方法中考虑不同风电场之间电力产生的时间差异。由于不同位置的风电场可能受到风速和气象条件的不同影响,它们的电力产生时间可能存在时滞,这需要在调度计划中进行合理考虑。
因此,整个标题表明研究的焦点是如何在海上风电场群中,通过联合利用储能资源并考虑场间功率时移,实现优化的电力调度。这样的研究有助于提高海上风电场群的整体效益和可持续性。
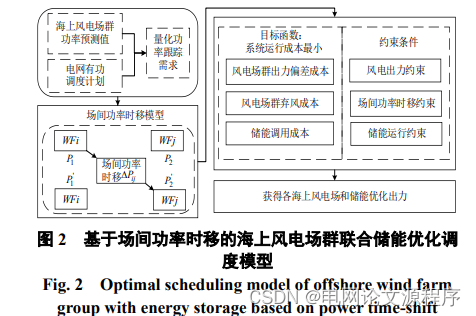
摘要:相邻海上风电场间因尾流效应产生功率时移能力,可为海上风电场群参与电网有功优化调度提供有效支撑。提出一种考虑场间功率时移的海上风电场群联合储能优化调度方法。首先,基于海上风电场群功率预测与电网有功调度计划量化风电场群功率跟踪需求;计及风速传播时间建立场间功率时移模型,利用风电场间功率时移能力参与电网调度;针对出力偏差协调储能进一步跟踪调度计划。然后,以系统运行成本最小为目标,构建考虑场间功率时移的海上风电场群储能优化调度模型。最后,以某实际海上风电场群储能系统为例进行仿真验证,结果表明本文所提方法能够利用相邻海上风电场间功率时移能力,有效降低储能调用成本,实现海上风电场群对电网有功调度计划的跟踪。
这个摘要指出了一种针对海上风电场群的新调度方法,其中考虑了相邻风电场间的功率时移现象以及联合储能的优化调度。
-
背景介绍:提到相邻海上风电场间的尾流效应导致功率时移,即不同风电场产生电力的时间存在差异。这种时移能力可以成为海上风电场群参与电网有功优化调度的支持基础。
-
方法概述:
- 量化需求和建模:首先,基于功率预测和电网调度计划,量化了风电场群对电网调度的需求。同时,考虑风速传播时间建立了功率时移模型,这有助于利用不同风电场间的功率时移能力参与电网调度。
- 储能协调:针对功率偏差,使用储能系统协调并进一步跟踪调度计划,以确保风电场群的电力输出符合预期。
-
建模和仿真验证:以最小化系统运行成本为目标,构建了一个优化模型,考虑了场间功率时移,并通过仿真验证了该方法的有效性。具体以某实际海上风电场群储能系统为例,结果表明这种方法能够降低储能调用成本,并实现风电场群对电网有功调度计划的跟踪。
总体来说,这个摘要提出了一种新的优化调度方法,旨在充分利用相邻风电场间的功率时移能力,结合储能系统来降低成本,并确保海上风电场群对电网调度计划的有效响应。
关键词:海上风电场群;场间功率时移;功率跟踪;储能;优化调度;
-
海上风电场群:指位于海上的多个风电场组成的集合体。通常,这些风电场群通过联合运行来提高效率、稳定性或降低整体成本。
-
场间功率时移:指相邻海上风电场之间由于尾流效应等因素导致的电力产生时间上的差异。这可能导致整个风电场群在时间上的功率波动。
-
功率跟踪:是指风电场群追踪电网有功调度计划的能力。在考虑场间功率时移的情况下,风电场群需要调整其输出,以确保其电力生产与电网的预期需求相一致。
-
储能:指利用储能技术,如电池等设备,将电力在产生时储存起来,以便在需要时释放。在这个上下文中,储能系统可能被用于协调风电场群的功率输出,以满足电网的需求。
-
优化调度:是指通过合理规划和管理风电场群的运行,以最小化系统运行成本或其他指定目标的过程。在这个情境下,优化调度涉及考虑功率时移和储能,以实现更高效、经济和可靠的运行。
综合来看,这些关键词指向一种优化海上风电场群运行的方法,其中考虑了相邻风电场之间的功率时移现象,利用储能技术来调整和优化风电场群的功率输出,以更好地满足电网的需求,并确保系统在经济和可靠性方面的最佳性能。
仿真算例:
为验证所提调度方法的有效性,本文以某实际 电网中三个海上风电场和一个集中式储能系统作 为研究算例,如图 3 所示。储能作为海上风电场群 的辅助设备,其配置比例为该实际电网给出的风电 场群总装机容量的 15%。风电上网单价[24]和弃风成本系数[25]都取 500 元/MWh;出力偏差成本系数取风电上网单价的 1.1 倍[26]即 550 元/MWh;储能充放电成本系数[25]取 50 元/MWh。海上风电场群主导风向为从风电场 1 吹 至风电场 2,最后到风电场 3。风电场 1 与风电场 2 相距 12.96km,风电场 2 与风电场 3 相距 6.5km。 风电场 1、风电场 2 和风电场 3 的装机容量分别为 200MW、142.2MW 和 102MW。 采用某实际电网不同典型日进行分析,其中一 典型日下海上风电场群出力预测值和电网调度计划如下图 4 所示,图中阴影部分表示海上风电场群 功率跟踪需求。另一典型日的算例分析见附录 A。
仿真程序复现思路:
复现这篇文章的仿真涉及以下步骤:
-
建立模型:根据文章描述,建立海上风电场群和储能系统的数学模型。包括风电场的发电模型、储能系统的充放电模型、功率跟踪需求模型等。确保模型能够准确地反映实际情况。
-
设定参数:根据文章提供的参数,设定模型中的各项参数,如风电场的装机容量、风向、距离等,以及储能系统的配置比例和成本系数。
-
实现算法:根据文章中提到的调度方法,实现相应的算法。这可能涉及到功率预测、优化调度等方面的算法。可以使用现有的优化库或自行实现算法。
-
采用实际数据:文章提到采用某实际电网不同典型日进行分析,因此需要获取这些实际数据。这包括典型日下海上风电场群出力预测值、电网调度计划等数据。
-
运行仿真:将模型和算法结合,使用实际数据运行仿真。可以采用循环的方式,模拟多个时刻的系统运行,以全面评估提出的调度方法的性能。
-
结果分析:分析仿真结果,包括功率跟踪的效果、成本变化等。与文章中的结果进行对比,以验证所提调度方法的有效性。

以下是一个简化的示例,使用Python的SciPy库进行仿真。请注意,这只是一个示例,实际的仿真可能需要更复杂的模型和算法:
import numpy as np
from scipy.optimize import minimize# 模拟电网系统
class PowerSystem:def __init__(self, wind_farm_capacities, storage_ratio, wind_prices, deviation_cost_factor, storage_cost):self.wind_farm_capacities = wind_farm_capacitiesself.storage_ratio = storage_ratioself.wind_prices = wind_pricesself.deviation_cost_factor = deviation_cost_factorself.storage_cost = storage_costdef objective_function(self, x):# 目标函数,即总成本wind_power = np.sum(x[:3]) # 风电场功率总和storage_power = x[3] # 储能系统功率# 计算风电场成本wind_cost = wind_power * self.wind_prices# 计算偏差成本deviation_cost = np.abs(wind_power - np.mean(wind_power)) * self.deviation_cost_factor# 计算储能充放电成本storage_cost = np.abs(storage_power) * self.storage_cost# 总成本total_cost = wind_cost + deviation_cost + storage_costreturn total_cost# 设定参数
wind_farm_capacities = np.array([200, 142.2, 102]) # 风电场容量
storage_ratio = 0.15 # 储能系统容量占比
wind_prices = 500 # 风电上网单价
deviation_cost_factor = 1.1 # 偏差成本系数
storage_cost = 50 # 储能充放电成本# 创建电网系统实例
power_system = PowerSystem(wind_farm_capacities, storage_ratio, wind_prices, deviation_cost_factor, storage_cost)# 设置优化问题
constraints = ({'type': 'eq', 'fun': lambda x: np.sum(x[:3]) - x[3]}) # 功率平衡约束
initial_guess = np.zeros(4) # 初始猜测# 运行优化算法
result = minimize(power_system.objective_function, initial_guess, method='SLSQP', constraints=constraints)# 输出结果
optimized_power_profile = result.x[:3] # 优化后的风电场功率
optimized_storage_power = result.x[3] # 优化后的储能系统功率
total_cost = result.fun # 优化后的总成本print("Optimized Wind Power Profile:", optimized_power_profile)
print("Optimized Storage Power:", optimized_storage_power)
print("Total Cost:", total_cost)
请注意,这只是一个简化的例子,实际的仿真可能涉及更多的复杂性和实际数据。在实际应用中,你可能需要进一步细化模型、考虑更多的约束条件和变量,并使用更为复杂的优化算法。此外,确保模型的参数和算法与实际研究保持一致。
这篇关于文章解读与仿真程序复现思路——电网技术EI\CSCD\北大核心《考虑场间功率时移的海上风电场群联合储能优化调度方法》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




