本文主要是介绍【LSSVM时间序列预测】蒲公英算法优化最小二乘支持向量机DO-LSSVM时序预测未来数据【含Matlab源码 2482期】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

⛄一、蒲公英算法DO简介
DOA 算法主要是模拟蒲公英在繁殖过程中飘落生长的植物特性,以弥漫式并行搜索方式对解空间进行搜索,直到找到满足最优解的条件为止.
1 蒲公英算法的主要思想
每值春夏之际,大地上长满了成片的蒲公英,每片的蒲公英群都会由一定范围内星星点点
的蒲公英繁殖而来,受蒲公英飘落繁殖现象的启发,本人在导师高岳林的指导下提出模拟蒲公英繁衍方式的蒲公英优化算法( DOA ),将蒲公英繁殖生长的空间比作成优化问题的搜索空间, 将生长在此区域内的母代和子代蒲公英个体看作是问题的候选解,通过目标函数评估蒲公英子代的适应度值,算法越接近目标函数的最优解,对应的适应度值就会越高,以此来比较算法的优劣性.根据蒲公英植物的生长繁殖规律,实时对蒲公英子代的飘落位置进行更新,同时对蒲公英子代进行增肥和灌溉,提高幼苗的生长质量.幼苗作为下一阶段蒲公英繁衍的位置,且生长的蒲公英个体将保留在原来的位置上.通过对挑选出的优质蒲公英个体进行不停的繁殖, 这样的操作不停地进行,繁殖的后代也会不停的接近最适合蒲公英种子生长的位置附近,最终在算法满足终止条件时,蒲公英种群中适应度值最优的位置就当作目标函数在解空间的最优值. 蒲公英算法通过实数编码的方式,随机地初始化种群,种群的迭代过程是受 3 个分量(风速、风向、种群密度)的共同作用,在整个迭代过程中,为了保持种群多样性,对蒲公英种子落地生根时的位置进行更新移植,并通过施肥和灌溉等操作,直到满足终止条件.
2 蒲公英算法的步骤和流程
2.1 蒲公英优化算法的流程图
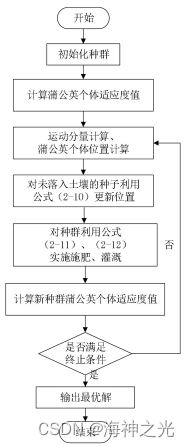
图 2.2 蒲公英算法流程图
这篇关于【LSSVM时间序列预测】蒲公英算法优化最小二乘支持向量机DO-LSSVM时序预测未来数据【含Matlab源码 2482期】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




