本文主要是介绍【阅读笔记】《ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文记录了博主阅读论文《ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks》的笔记,代码,更新于2019.05.23。
后续论文笔记:【阅读笔记】《ReSeg: A Recurrent Neural Network-based Model for Semantic Segmentation》
文章目录
- Abstract
- Introduction
- Model Description
- Differences between LeNet and ReNet
- Experiments
- Datasets
- Data Augmentation
- Model Architectures
- Training
- Results and Analysis
- Discussion
Abstract
本文提出了一个基于循环神经网络的用于目标识别的网络结构,称为ReNet。
Introduction
Model Description
用 X = { x i , j } X=\{x_{i,j}\} X={xi,j}表示输入图像或输入特征图,其中 X ∈ R w × h × c X\in\mathbb R^{w\times h\times c} X∈Rw×h×c, w w w、 h h h和 c c c分别代表宽、高和通道数。给定尺寸为 w p × h p w_p\times h_p wp×hp的感受野或图块 P = { p i , j } P=\{p_{i,j}\} P={pi,j},其中 I = w w p I=\frac{w}{w_p} I=wpw, J = h h p J=\frac{h}{h_p} J=hph, p i , j ∈ R w p × h p × c p_{i,j}\in\mathbb R^{w_p\times h_p\times c} pi,j∈Rwp×hp×c是图像的第 ( i , j ) (i,j) (i,j)个图块,第一个参数 i i i表示水平index,第二个参数 h h h表示竖直index。
用两个RNNs滑动扫过整张图像,一个RNN自下而上,另一个RNN自上而下。(这句没懂,到底这个方向什么意思,怎么进行的?)每个RNN都以一个展开的图块为输入,一次只处理一个图块,并更新其隐藏状态(hidden state),沿着输入图像 X X X的每个列 j j j进行;
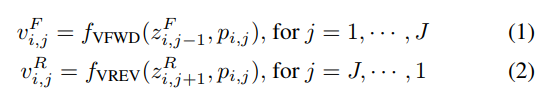
竖直的双向滑动结束后,开始水平方向的滑动。将两个中间状态 v i , j F v^F_{i,j} vi,jF和 v i , j R v^R_{i,j} vi,jR按照位置 ( i , j ) (i,j) (i,j)级联,得到整合的特征图 V = { v i , j } i = 1 , … , I j = 1 , … , J V=\{v_{i,j}\}^{j=1,\dots,J}_{i=1,\dots,I} V={vi,j}i=1,…,Ij=1,…,J,其中 v i , j ∈ R 2 d v_{i,j}\in\mathbb R^{2d} vi,j∈R2d, d d d是回归单元的个数。每个 v i , j v_{i,j} vi,j都是一个特征监测子在位置 ( i , j ) (i,j) (i,j)上的activation,对应所有在原始图像第 j j j列的图块(对所有 i i i的 p i , j p_{i,j} pi,j)。
接下来,对得到的特征图 V V V应用两个RNNs( f HFWD f_\text{HFWD} fHFWD和 f HREV f_\text{HREV} fHREV)。与竖直滑动相同,这些RNNs沿着 V V V的每行滑动,得到输出的特征图 H = { h i , j } H=\{h_{i,j}\} H={hi,j},其中 h = i , j ∈ R 2 d h_={i,j}\in\mathbb R^{2d} h=i,j∈R2d。现在,每个向量 h i , j h_{i,j} hi,j代表原始图像中图块 p i , j p_{i,j} pi,j对于整张图片的上下文信息。
用 ϕ \phi ϕ表示从输入图像 X X X到输出特征图 H H H的函数(如下图所示)。

显然,可以堆叠多个 ϕ \phi ϕ使得所提出的ReNet更深,从而能够获取输入图像更复杂的特征。经过若干层应用到输入图像的循环层以后,最后一层的Activation在展开(flattened)后,送入一个可微的分类器。在本文实验中,这里应用了全连接层和softmax作为分类器。如下图所示:

深度ReNet是一个平滑、连续的函数,其参数(从RNNs和全连接层来的)可以通过随机梯度下降法和反向传播算法估计得到(使得log-likelihood最大化)。
Differences between LeNet and ReNet
ReNet和卷积神经网络之间有诸多的相似和不同。这个部分,论文作者用LeNet代表经典卷积神经网络,分析比较几个关键点。
每层,这两个网络都对输入图像或输入特征图的图块用了相同的滤波器。但是,ReNet通过覆盖整图的横向连接(lateral connections)传递信息;而LeNet仅关注了局部特征。

LeNet用max-pool处理了所有小区域内的activations以得到局部平移不变性。相反,由于学习得到的横向连接,ReNet不用任何池化。ReNet中的横梁连接能够模仿(emulate)LeNet中max-pooling进行的特征局部计算。当然,这并不意味着ReNet没有办法应用max-pooling。在ReNet中应用最大池化可以帮助减少特征图的空间维度,从而降低计算量。


Experiments
Datasets
Data Augmentation
Model Architectures
Training
Results and Analysis
Discussion
更多内容,欢迎加入星球讨论。

这篇关于【阅读笔记】《ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








