本文主要是介绍【EMNLP 2023】面向Stable Diffusion的自动Prompt工程算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近日,阿里云人工智能平台PAI与华南理工大学朱金辉教授团队合作在自然语言处理顶级会议EMNLP2023上发表了BeautifulPrompt的深度生成模型,可以从简单的图片描述中生成高质量的提示词,从而使文生图模型能够生成更美观的图像。BeautifulPrompt通过对低质量和高质量的提示进行微调,并进一步提出了一种基于强化学习和视觉信号反馈的技术,以最大化生成提示的奖励值。
论文:
Tingfeng Cao, Chengyu Wang, Bingyan Liu, Ziheng Wu, Jinhui Zhu, Jun Huang. BeautifulPrompt: Towards Automatic Prompt Engineering for Text-to-Image Synthesis. EMNLP 2023 (Industry Track)
背景
文生图是AIGC中最引人注目和广泛应用的技术之一,旨在通过文本输入创建逼真的图像。最近,随着大型模型建模能力的提升,文生图模型得到快速的发展。大规模的TIS模型,如DALLE-2、Imagen和stable diffusion,显著提高了最先进的性能,并允许没有艺术专业知识的用户通过个人想象力创建前所未有的图像。
然而,文成图模型要求用户在模型推理之前编写文本提示(例如“一艘雄伟的帆船”)。编写满足设计师或艺术工作者需求的这些提示充满了不确定性,就像开盲盒一样。这是由于训练数据的质量问题,导致需要详细的描述才能生成高质量的图像。在现实场景中,非专家往往很难手工编写这些提示,并且需要通过试错的迭代修改来重新生成图像,从而导致时间和计算资源的严重浪费。
提示工程(prompt engineering)是一个新兴的研究领域,旨在探索如何为深度生成模型提供提示,并提高人与AI之间直接交互的效率。因此,我们关注于大语言模型(LLM)自动地生成高质量的提示词,下图展示了使用简单的图片描述和BeautifulPrompt之后生产的图片。

算法概述
数据收集
我们提出一个自动化收集prompt优化的数据集方案:

原始数据源是DiffusionDB,它只包含未配对的提示。启发式地,我们根据提示的长度、提示中包含的某些标签等将提示分为低质量提示和高质量提示。
接下来,我们
i)使用BLIP 对与高质量提示相关的图像进行caption,并将结果视为相应的低质量提示,因为说明文字较短且缺乏细节;
ii)使用ChatGPT对高质量的提示进行总结,并将总结视为低质量的提示;
iii)使用ChatGPT从低质量的提示生成更好的提示;结果被认为是高质量的提示。
通过以上三种方法,我们获得了大量的提示对;然而,这些提示对的质量无法保证。因此,我们需要进行进一步的数据清理和过滤。我们清洗了包含色情、政治敏感等不适合工作场景的数据,并对图片的美观值进行筛选。得到最终的数据集。与InstructGPT类似,我们采用了三阶段的训练,整体训练架构图如下:

Step 1. SFT
给定提示对的数据集,其中包含低质量提示对
和高质量提示对
,我们对仅解码器语言模型(BLOOM)进行微调,以输出具有给定指令和低质量提示的高质量令牌token
。
我们使用自回归语言建模目标来微调语言模型:
Step 2. RM
我们基于PickScore 和 Aesthetic Score来训练奖励模型。
简单地说,PickScore是一个基于文本到图像提示和真实用户偏好的大型数据集训练的偏好模型,它在预测人类对图像的偏好方面表现出超人的表现。我们计算低质量提示和相应高质量提示生成的图像的PickScore。为了减少随机种子对TIS模型生成的图像质量的影响,我们使用8种不同的随机种子生成图像并对结果进行平均。计算的平均PickScore 被用作训练奖励模型的基础真相。损失函数为:
其中是提示对
的奖励模型的标量输出。MSE是均方误差。N为样本总数。
类似地,奖励模型还被训练以将图像中的相应提示与美学分数匹配:
其中是奖励模型的标量输出。
最后,我们使用作为平衡因子,将两个奖励模型的得分组合为最终奖励:
Step 3. PPO(RL)
由于收集到的数据集不可避免地包含一些噪声,例如,低质量提示与相应的高质量提示之间的一致性相对较低,因此监督训练模型的性能可能不令人满意。为了进一步提高模型性能,我们初始化一个策略
,然后微调
来使用强化学习执行任务。我们利用近端策略优化(PPO) 算法直接优化预期奖励:
其中为Kullback-Leibler (KL)罚系数。它可以防止政策偏离
。我们在这里采用自适应KL惩罚。
算法评测
为了验证BeautifulPrompt的有效性,我们在一些基于模型打分的客观指标和人类主观评估上做了实验:
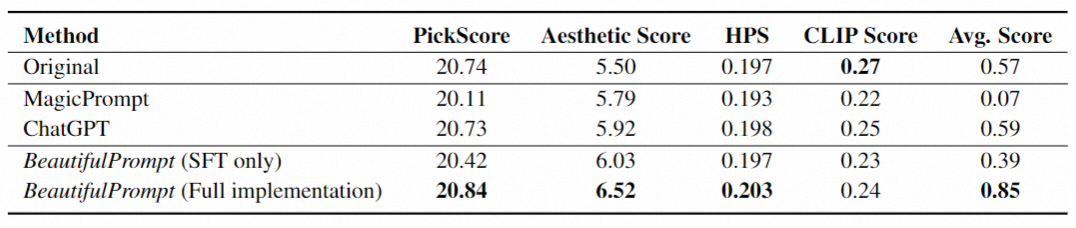

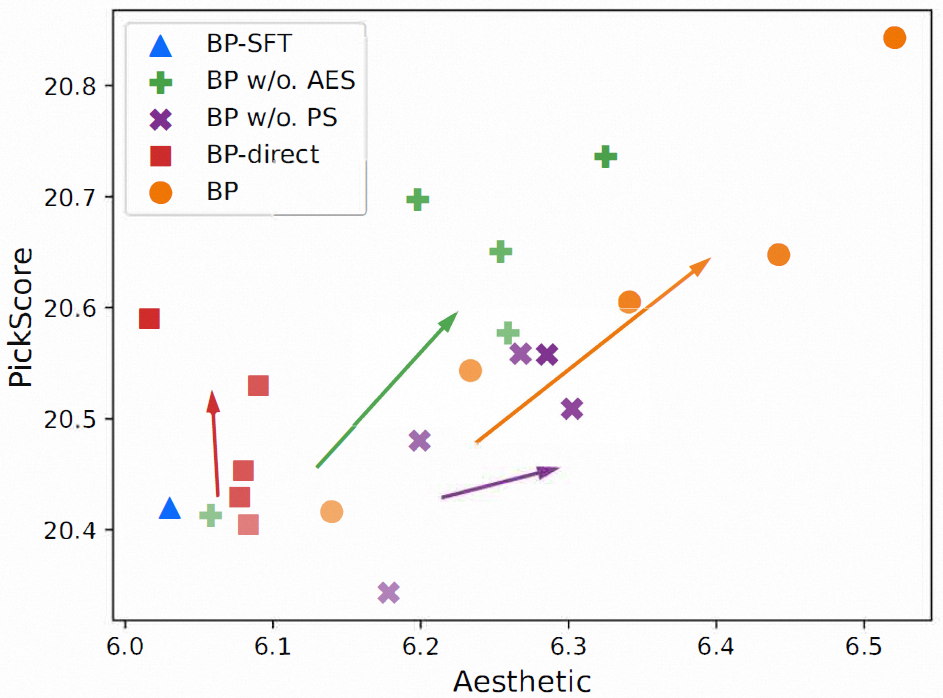
我们也对算法的模块进行了详细有效性分析,我们可以算法的各个流程都是有效的。
为了更好地服务开源社区,BeautifulPrompt算法的源代码即将贡献在自然语言处理算法框架EasyNLP中,欢迎NLP从业人员和研究者使用。
EasyNLP开源框架:GitHub - alibaba/EasyNLP: EasyNLP: A Comprehensive and Easy-to-use NLP Toolkit
参考文献
- Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. EMNLP 2022
- Stiennon, Nisan, et al. "Learning to summarize with human feedback." Advances in Neural Information Processing Systems 33 (2020): 3008-3021
- Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022
- Kirstain, Yuval, et al. "Pick-a-pic: An open dataset of user preferences for text-to-image generation." arXiv preprint arXiv:2305.01569 (2023)
论文信息
论文标题:BeautifulPrompt: Towards Automatic Prompt Engineering for Text-to-Image Synthesis
论文作者:曹庭锋、汪诚愚、刘冰雁、吴梓恒、朱金辉、黄俊
论文pdf链接:https://arxiv.org/abs/2311.06752
这篇关于【EMNLP 2023】面向Stable Diffusion的自动Prompt工程算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








