本文主要是介绍DL Homework 9,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1 知识总结
1.1 给网络增加短期的记忆能力
1.2 有外部输入的非线性自回归模型
1.3 循环神经网络
2.1 简单循环神经网络
2.1.1 循环神经网络的通用近似定理
2.1.2 图灵完备
3.1 序列到类别
3.2 同步的序列到序列模式
3.3 异步的序列到序列模式
2.Homework
1. 实现SRN
(1)使用Numpy
(2)在1的基础上,增加激活函数tanh
(3)使用nn.RNNCell实现
(4)使用nn.RNN实现
2. 实现“序列到序列”
RNN Cell实现
RNN 实现
性能优化
3."编码器-解码器”的简单实现
4.简单总结nn.RNNCell、nn.RNN
torch.nn.RNNCell()
torch.nn.RNN()
总结
5.谈一谈对“序列”、“序列到序列”的理解
6.总结本周理论课和作业,写心得体会
参考博客
1 知识总结
首先对于前馈神经网络,在对数据处理时具有以下的问题:
- 连接在层与层之间,每层节点间无连接。
- 输入和输出的维数固定,不能任意改变。
- 无法处理时序数据。
展开来讲,对于前馈神经网络,每一次的输入都是独立的,并且每次输出只依赖于当前的输入,如下图所示
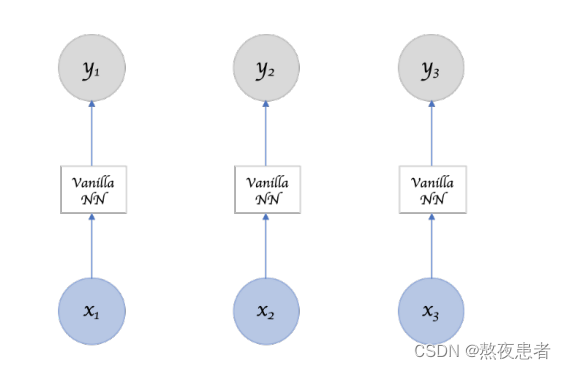
并且刚刚提到,前馈神经网络无法处理序列数据(sequence data),那什么是序列数据呢,有先后次序的一组(有限或无限多个)数据。例如:时间序列(按照不同时间收集到的数据,描述现象随时间变化的情况)、符号序列(由元素或事件的有序集组成,例如语言等)、生物序列(基因数据、蛋白质数据),由于前馈神经网络具有以上说明的不足,所以循环神经网络(Recurrent Neural Network, RNN)应时代诞生。
那么总结一下卷积神经网络和循环神经网络之间的区别,如下:

这样就对循环神经网络有了一个最基本的认识的,总结一下循环神经网络的基本特点:
- 具有短期记忆能力
- 神经元可接受其他神经元信息,也可接受自身信息,形成有环路的网络结构
- 和前馈神经网络相比,更加符合生物神经网络的结构
- 已广泛应用在语音识别、语言模型、自然语言生成等任务上
- 容易扩展到更广义的记忆网络模型:递归神经网络、图网络
这里有想法的同学就回想,为什么处理序列数据就一定需要循环神经网络么,难道没有别的方法么,当然有,处理序列数据可以理解为给网络增加短期的记忆能力
1.1 给网络增加短期的记忆能力
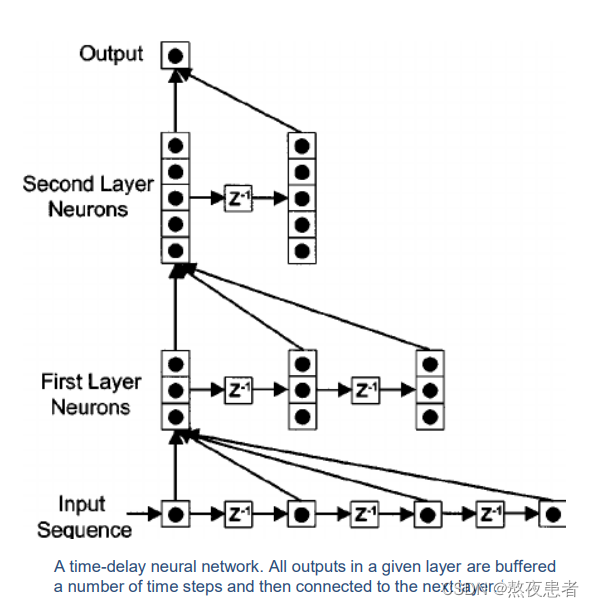
1.1.1 延时神经网络(Time Delay Neural Network,TDNN)
建立额外延时单元,存储网络历史信息。
在前馈网络中的非输出层都添加一个延时器, 记录神经元的最近几次活性值. 在第个时刻,第
层神经元的活性值 依赖于 第
层神经元的最近
个时刻的活性值, 即
,如下图所示,图片来源图片来源图片来源
1.2 有外部输入的非线性自回归模型
自回归模型:每一步都需要将前面的输出作为当前步的输入,是一种自回归的方式

时间序列模型,用变量的历史信息来预测自己
1.3 循环神经网络
RNN通过使用带自反馈的神经元,能够处理任意长度的时序数据。
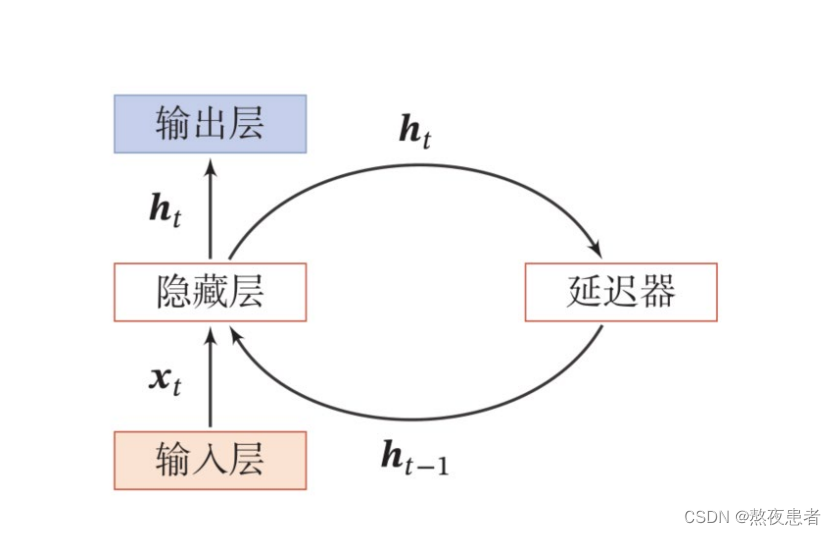
输入层输入的连同上一次的输出
一同传入隐藏层得到输出
,然后再将
传入延迟器
中。
2.1 简单循环神经网络
简称SRN,只有一个隐藏层的神经网络
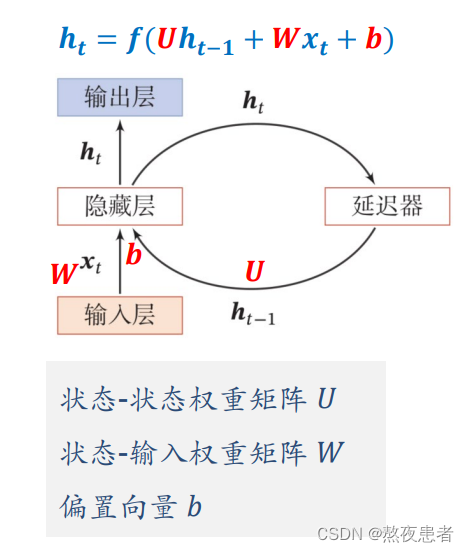

这里简单解释以下可以理解为对隐藏层的输入,通过激活函数变成了
,传入延迟器,并输出为
,这里的激活函数一般采用tanh函数,如果还不理解怎么办,看下方三维立体图,来自b站up主的讲解,up主讲的嘎嘎清晰
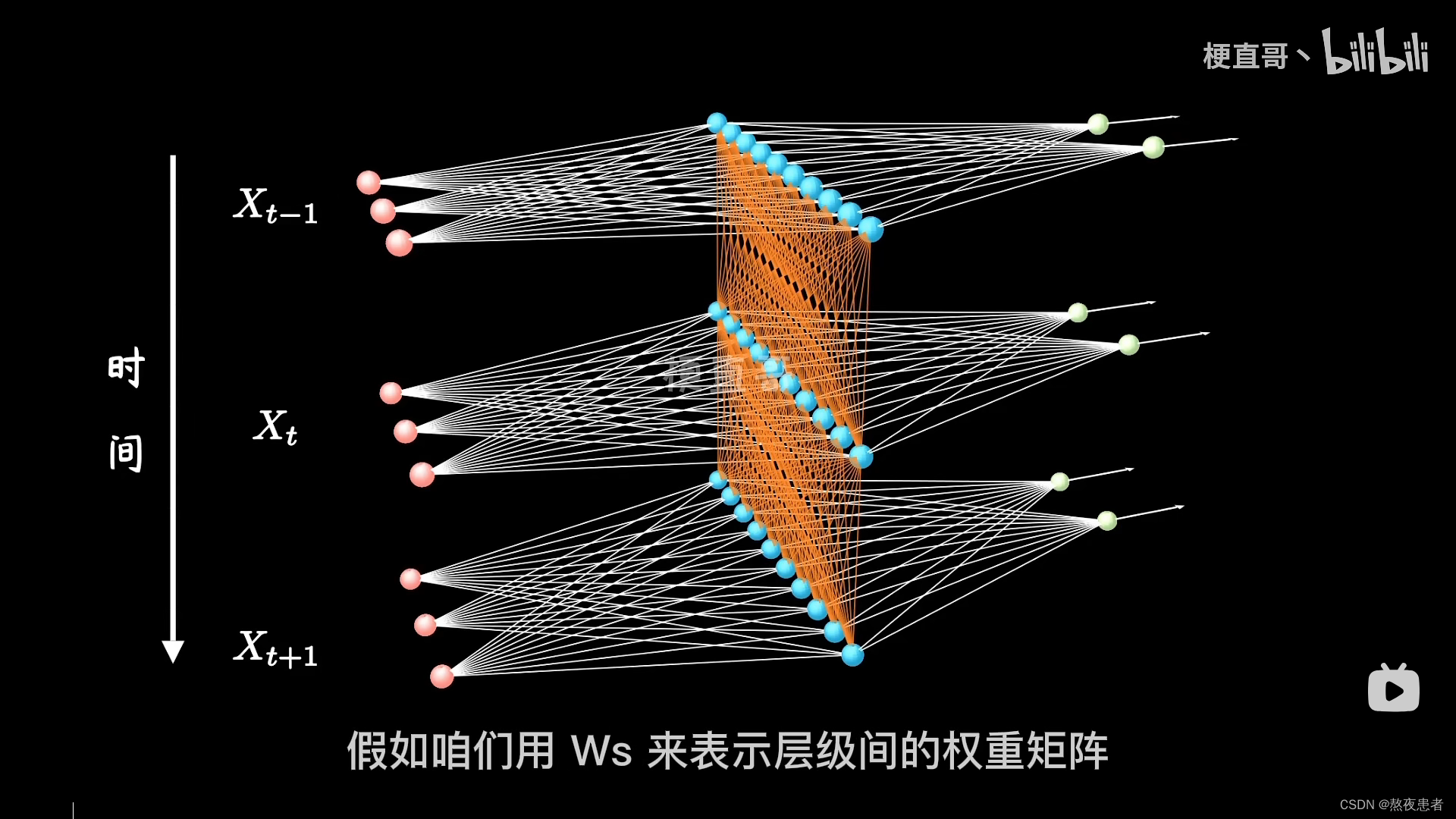
橙色的线把、
、
连接起来,体现了时间的相关性。
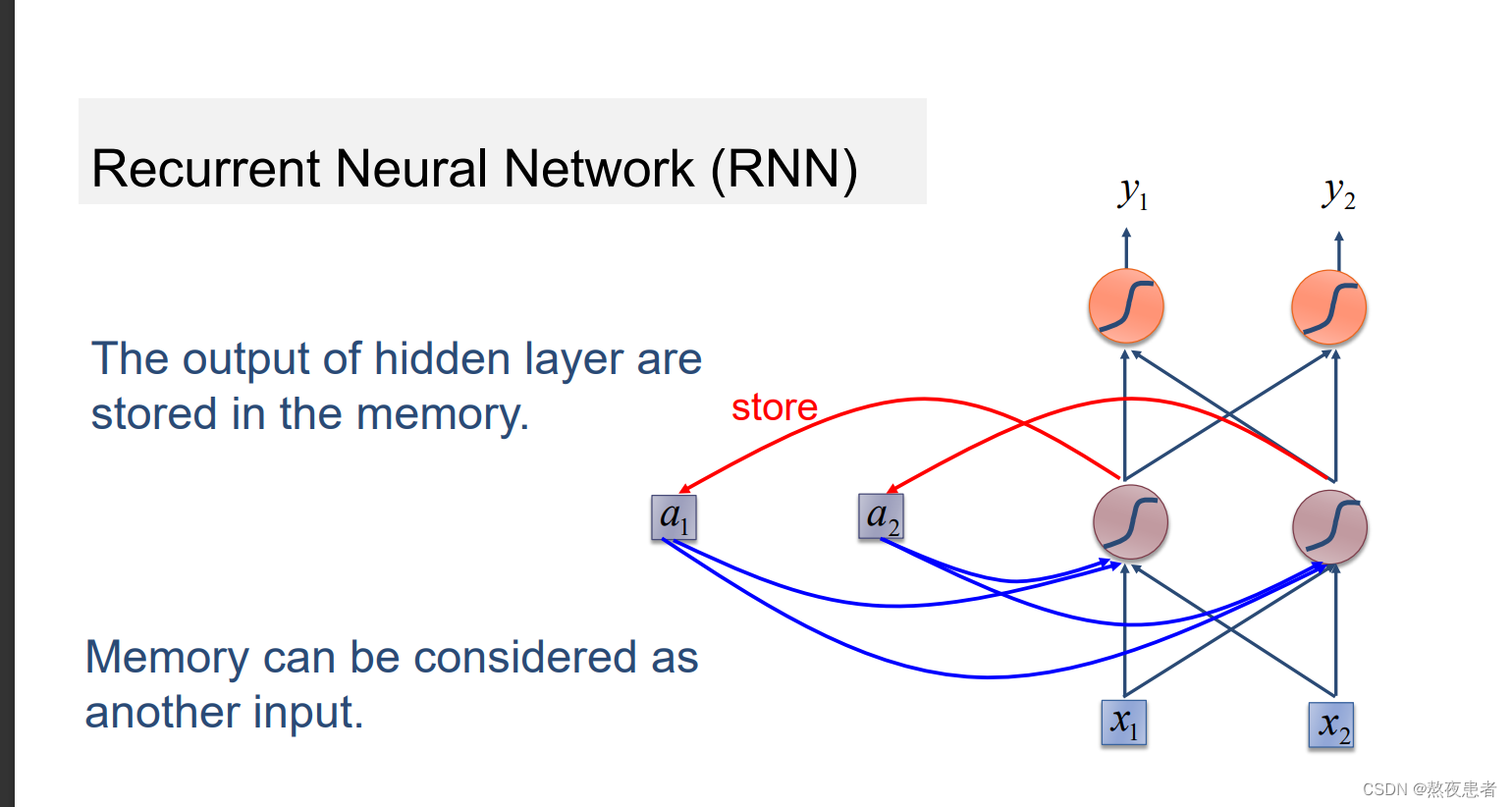
简单理解,隐藏层的输出会被存储,并且,再另外新的输出中调用。
2.1.1 循环神经网络的通用近似定理

直白的说具有足够多隐藏单元的循环神经网络可以以任意精度逼近任何连续函数,换个说法通过增加循环神经网络的隐藏单元数量,我们可以使其变得足够复杂,从而可以表示和学习各种复杂的函数关系。也就是说,循环神经网络在理论上能够处理和学习几乎任何连续数据的模式和关系。
2.1.2 图灵完备
图灵完备: 一种数据操作规则

通过资料搜索发现一个图灵完备的计算机系统或编程语言可以完成以下三方面的计算:
- 任何可计算的算法都可以在该系统中表示和执行;
- 该系统可以处理和操作任何有限大小的数据结构;
- 该系统具有分支和循环等控制流程结构,可以实现复杂的逻辑运算和条件判断;
通俗来讲,一个图灵完备的计算系统或编程语言可以通过一系列简单的计算步骤,模拟出复杂的计算过程和算法。但是通过资料搜索我发现,图灵完备并不意味着一个计算系统或编程语言是最好的或最高效的。只是表明该系统具有计算能力和普适性(某个系统或模型具有足够的灵活性和可塑性,能够模拟和表示各种不同类型的问题和现象),可以用于解决各种计算问题。
3.1 序列到类别
主要用于序列分类问题:输入为序列,输出为类别. 如:
- 输入一段文字判别所属的类别
- 输入一个句子判断其情感倾向
- 输入一段视频并判断它的类别
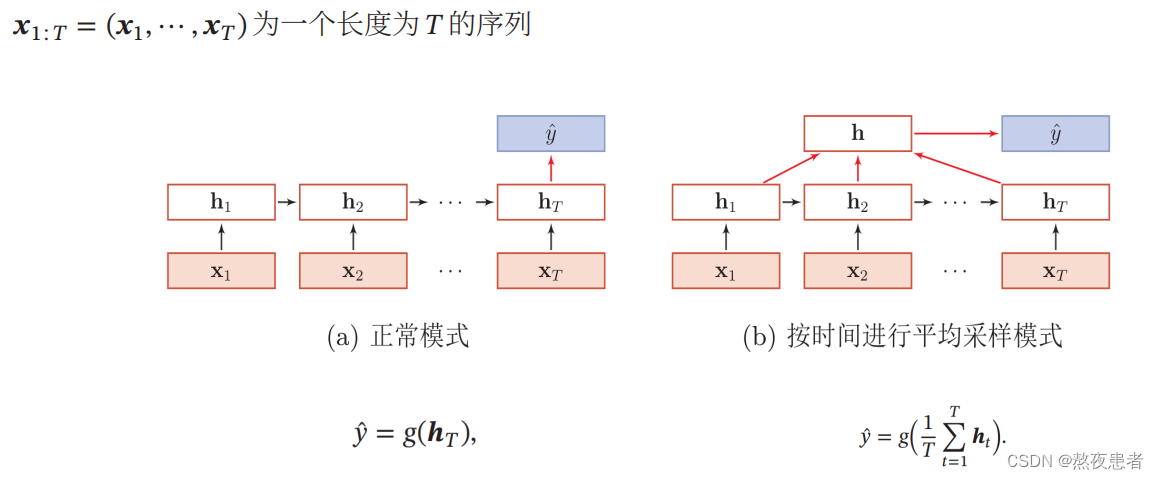
3.2 同步的序列到序列模式
同步的序列到序列模式主要用于序列标注任务
每一时刻都有输入和输出,输入序列和输出序列的长度相同
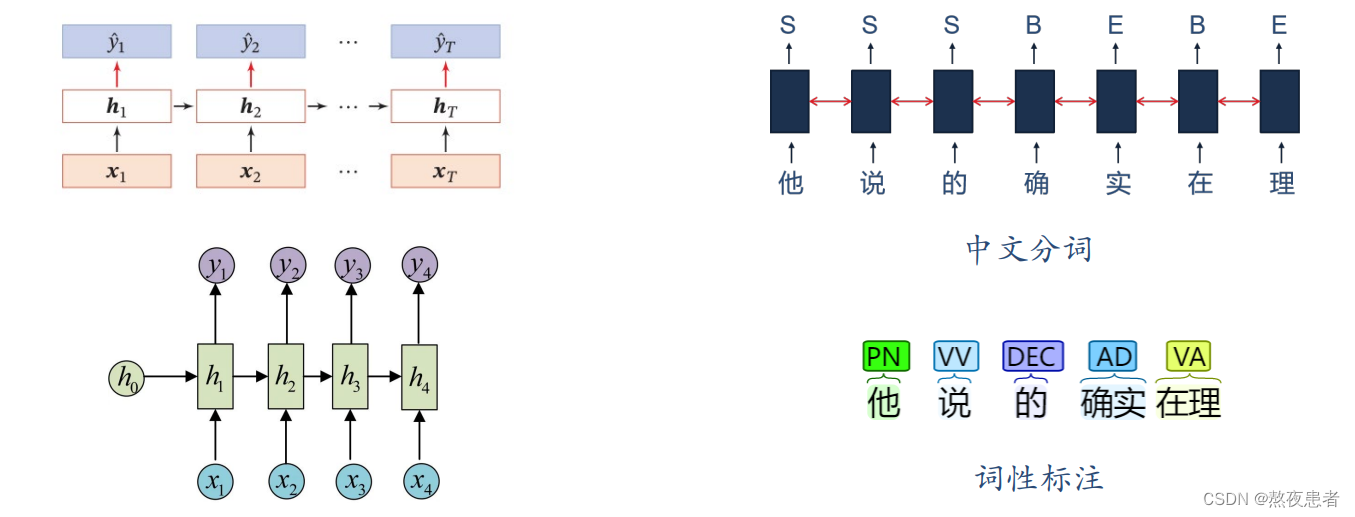
3.3 异步的序列到序列模式
编码器-解码器(Encoder-Decoder)模型
输入序列和输出序列:不需要严格对应关系,也不需要保持相同长度. 如: 机器翻译,输入为源语言的单词序列,输出为目标语言的单词序列
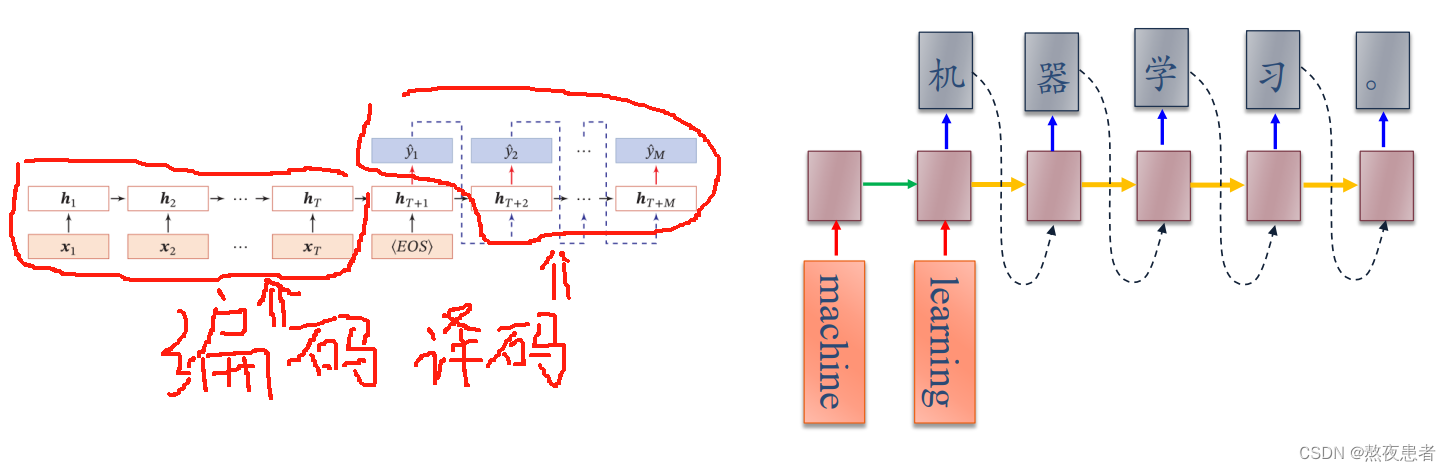
我们很轻易的发现,异步和同步的序列到序列的模型,不同之处只是在于二者一个是输入就有我们需要的输出,一个是需要先进行提前的编码,再输入我们的数据,得到相应的解码,具体详细会再后面进行讲解。
2 Homework
1. 实现SRN
(1)使用Numpy
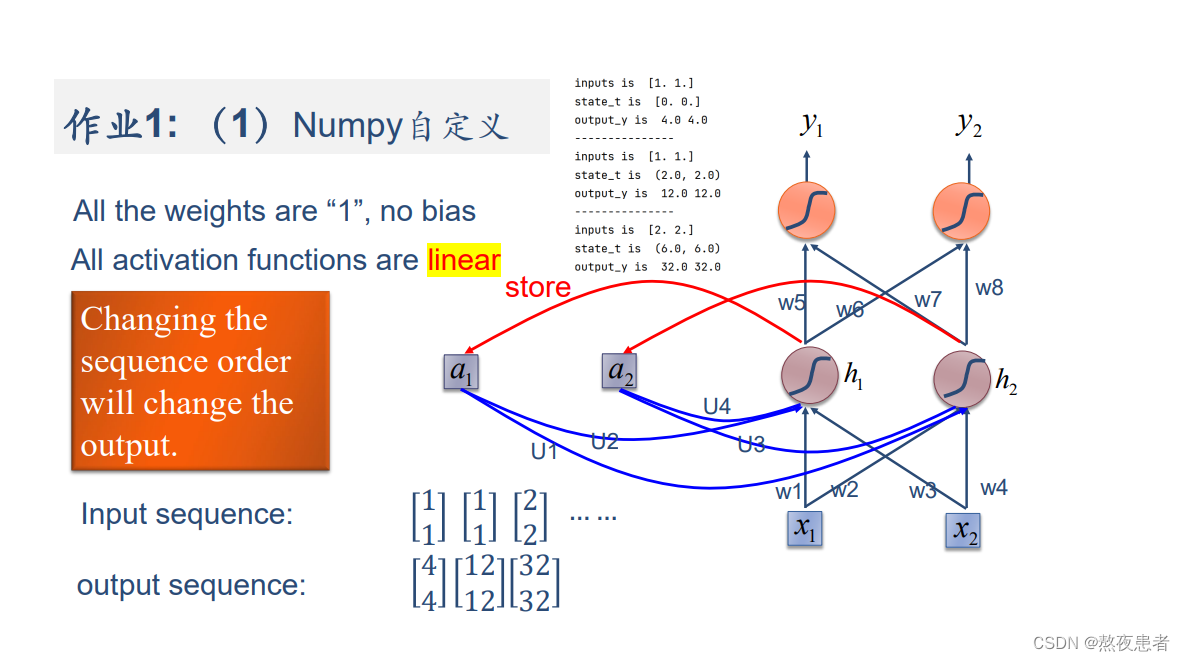 对于每次循环,因为没有激活函数,所以计算的过程如下:
对于每次循环,因为没有激活函数,所以计算的过程如下:
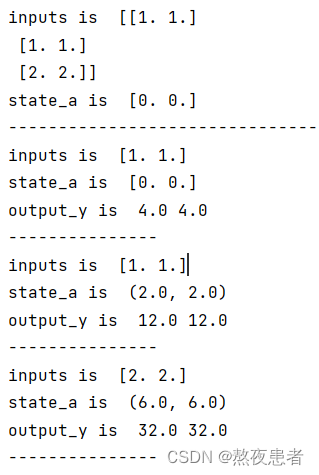
import numpy as npinputs = np.array([[1., 1.],[1., 1.],[2., 2.]]) # 初始化输入序列
print('inputs is ', inputs)state_a = np.zeros(2, ) # 初始化存储器
print('state_t is ', state_a)w1, w2, w3, w4, w5, w6, w7, w8 = 1., 1., 1., 1., 1., 1., 1., 1.
U1, U2, U3, U4 = 1., 1., 1., 1.
print('--------------------------------------')
for input_t in inputs:print('inputs is ', input_t)print('state_a is ', state_a)in_h1 = np.dot([w1, w3], input_t) + np.dot([U2, U4], state_a)in_h2 = np.dot([w2, w4], input_t) + np.dot([U1, U3], state_a)state_t = in_h1, in_h2output_y1 = np.dot([w5, w7], [in_h1, in_h2])output_y2 = np.dot([w6, w8], [in_h1, in_h2])print('output_y is ', output_y1, output_y2)print('---------------')输出的结果如下:
(2)在1的基础上,增加激活函数tanh
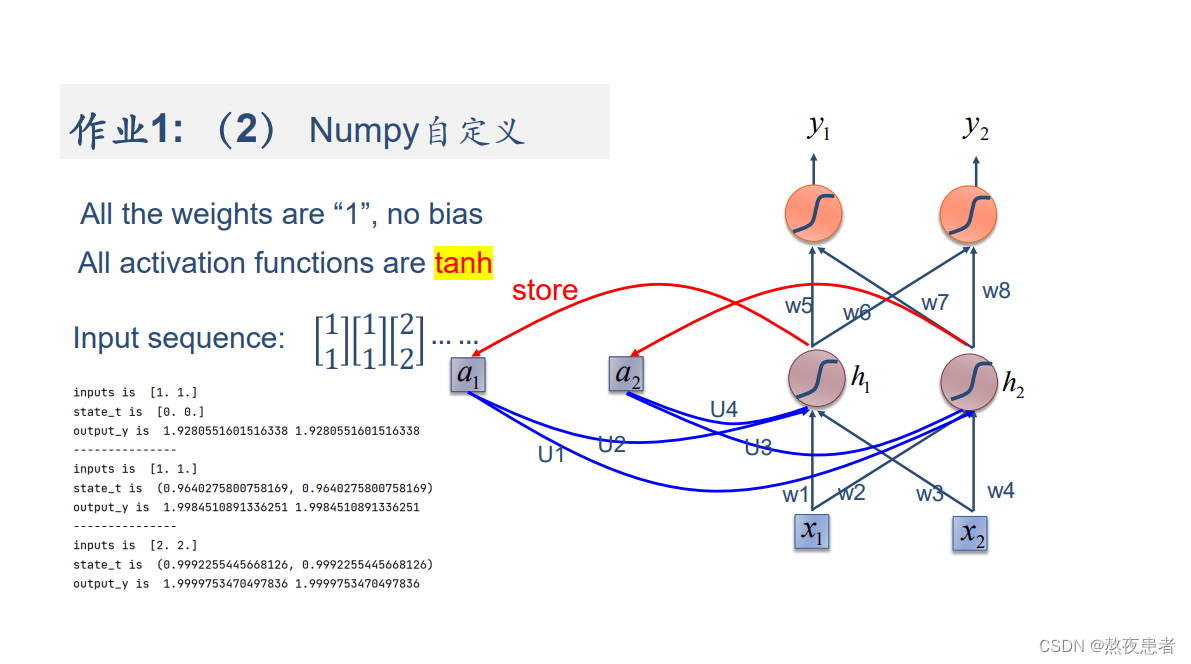
与(1)相比差异在于如下:
其中代表tanh函数
代码如下:
import numpy as npinputs = np.array([[1., 1.],[1., 1.],[2., 2.]]) # 初始化输入序列
print('inputs is ', inputs)state_a = np.zeros(2, ) # 初始化存储器
print('state_a is ', state_a)w1, w2, w3, w4, w5, w6, w7, w8 = 1., 1., 1., 1., 1., 1., 1., 1.
U1, U2, U3, U4 = 1., 1., 1., 1.
print('--------------------------------------')
for input_t in inputs:print('inputs is ', input_t)print('state_a is ', state_a)in_h1 = np.tanh(np.dot([w1, w3], input_t) + np.dot([U2, U4], state_a))in_h2 = np.tanh(np.dot([w2, w4], input_t) + np.dot([U1, U3], state_a))state_a = in_h1, in_h2output_y1 = np.dot([w5, w7], [in_h1, in_h2])output_y2 = np.dot([w6, w8], [in_h1, in_h2])print('output_y is ', output_y1, output_y2)print('---------------')结果如下:

(3)使用nn.RNNCell实现
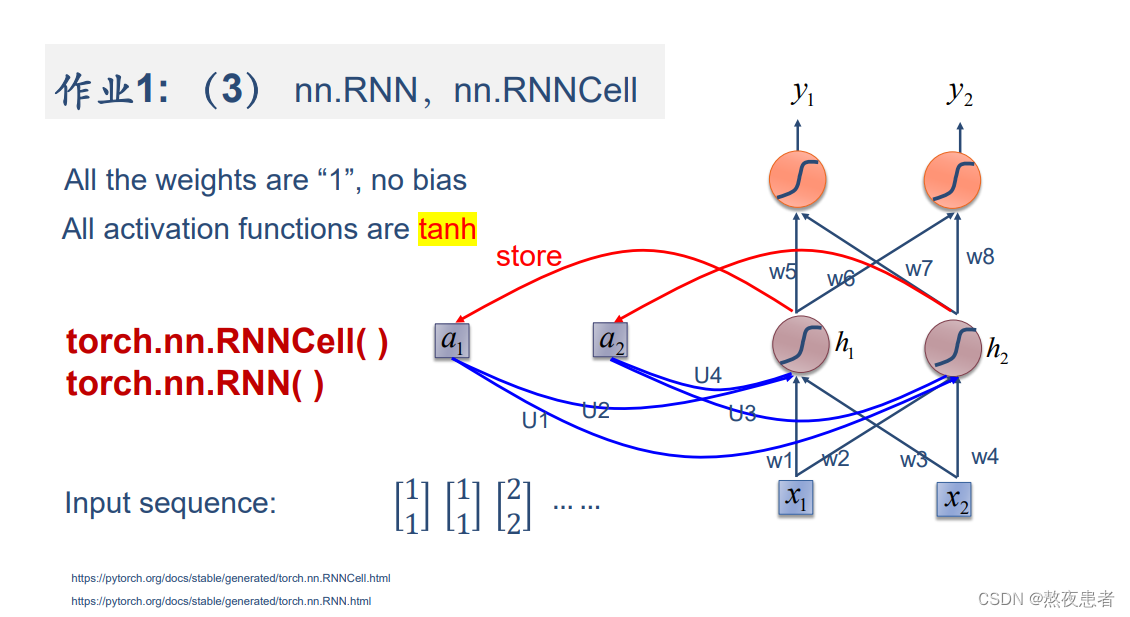
代码如下:
import torchbatch_size = 1
seq_len = 3 # 序列长度
input_size = 2 # 输入序列维度
hidden_size = 2 # 隐藏层维度
output_size = 2 # 输出层维度# RNNCell
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
# 初始化参数 https://zhuanlan.zhihu.com/p/342012463
for name, param in cell.named_parameters():if name.startswith("weight"):torch.nn.init.ones_(param)else:torch.nn.init.zeros_(param)
# 线性层
liner = torch.nn.Linear(hidden_size, output_size, bias=False)
liner.weight.data = torch.Tensor([[1, 1], [1, 1]])seq = torch.Tensor([[[1, 1]],[[1, 1]],[[2, 2]]])
hidden = torch.zeros(batch_size, hidden_size)
output = torch.zeros(batch_size, output_size)for idx, input in enumerate(seq):print('=' * 20, idx, '=' * 20)print('Input :', input)print('hidden :', hidden)hidden = cell(input, hidden)output = liner(hidden)print('output :', output)结果如下:

(4)使用nn.RNN实现
代码如下:
import torchbatch_size = 1
seq_len = 3
input_size = 2
hidden_size = 2
num_layers = 1
output_size = 2cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)
for name, param in cell.named_parameters(): # 初始化参数if name.startswith("weight"):torch.nn.init.ones_(param)else:torch.nn.init.zeros_(param)# 线性层
liner = torch.nn.Linear(hidden_size, output_size)
liner.weight.data = torch.Tensor([[1, 1], [1, 1]])
liner.bias.data = torch.Tensor([0.0])inputs = torch.Tensor([[[1, 1]],[[1, 1]],[[2, 2]]])
hidden = torch.zeros(num_layers, batch_size, hidden_size)
out, hidden = cell(inputs, hidden)print('Input :', inputs[0])
print('hidden:', 0, 0)
print('Output:', liner(out[0]))
print('--------------------------------------')
print('Input :', inputs[1])
print('hidden:', out[0])
print('Output:', liner(out[1]))
print('--------------------------------------')
print('Input :', inputs[2])
print('hidden:', out[1])
print('Output:', liner(out[2]))结果如下:

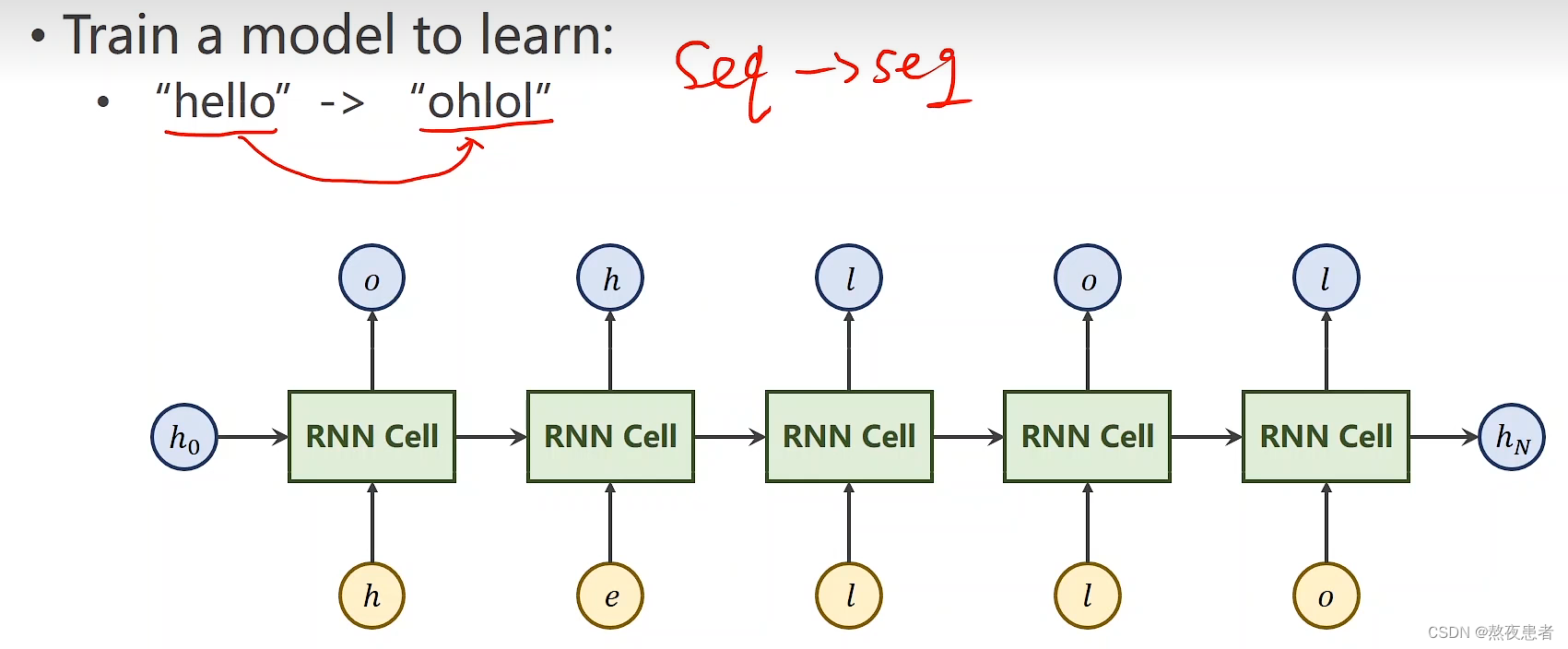
2. 实现“序列到序列”
观看视频,学习RNN原理,并实现视频P12中的教学案例
12.循环神经网络(基础篇)_哔哩哔哩_bilibili
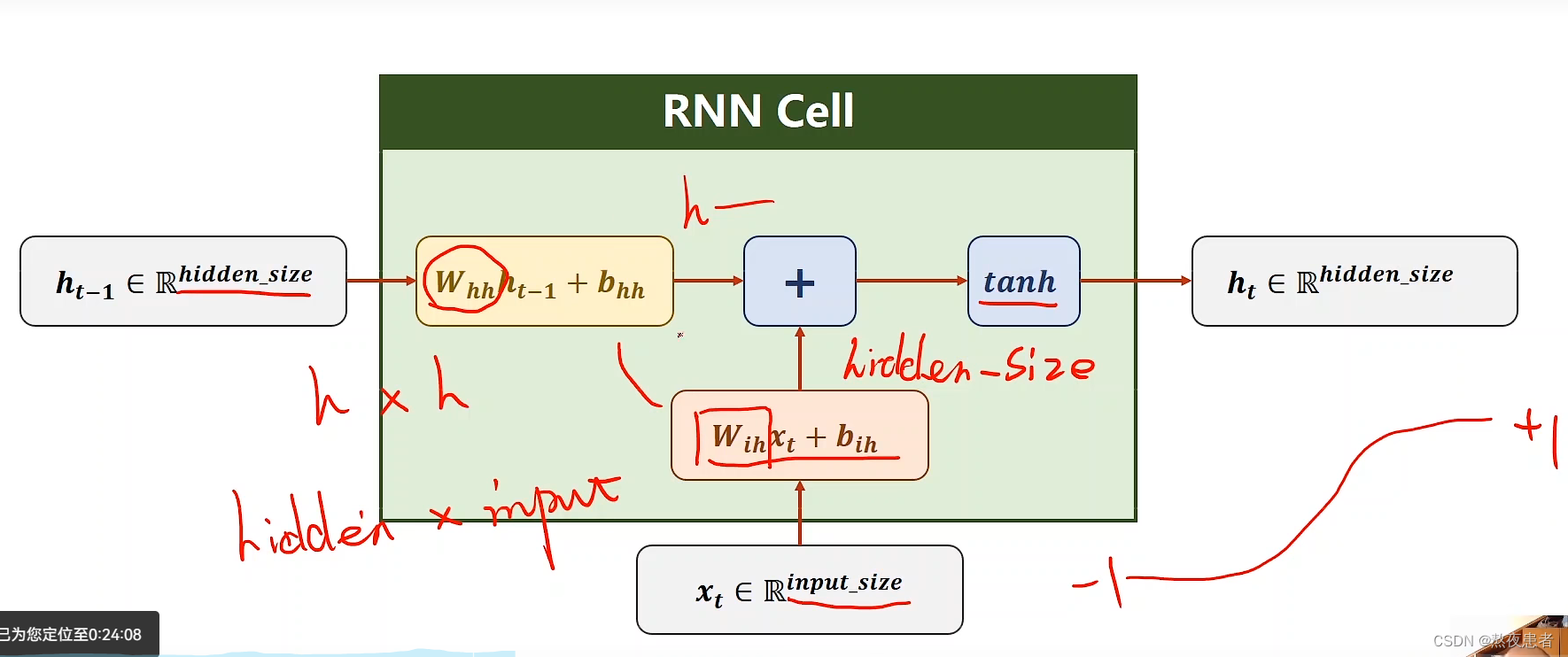
关于视频,视频首先详细的讲解了什么是RNN Cell,我感觉在这里换个写法更好
因为老师明确的告诉了,是一个hidden_size * input_size大小的矩阵,所以写成
更容易理解,并且这里得到最后矩阵大小为 hidden_size * 1的符合老师的讲解
此时最后求解结果为
我们发现这个式子的括号里的内容可以处理以下,可以处理为 这里可能又不理解了,老师把w和输入都合并了,为啥
和
合并的这么奇怪,大小为hidden_size * hidden_size 和 hidden_size * input_size,这个问题我也想了好久,所以我看了好几遍终于理解这里
和
的下标代表的不完全是维度,就像
,代表的不是input_size * hidden_size的维度,我们发现老师b的下标都是按照跟w相同的下标志,下标只是为了区分,并且,不论是
还是
最后的乘积的结果都是 hidden_size * 1大小的,所以我觉得最后这个式子正确写法为
真么一看两个
确实如果没看懂真的挺迷糊的,好像理解老师了,那么针对这个式子
,我们其实还可以进行下一步的变化变为
,
为hidden_size * 1,
为input_size * 1
序列到序列的举例实践
RNN Cell实现
首先采用RNN Cell实现,采用向量方式改变,按照老师的思路输入是一个字符串,按照字符串编写对应的字典,然后输出字典对应的下标,采用独热码编码,生成独热码向量(将文本转化为向量的最简单的方式)。input_size = 4,如下图所示:

代码流程如下:
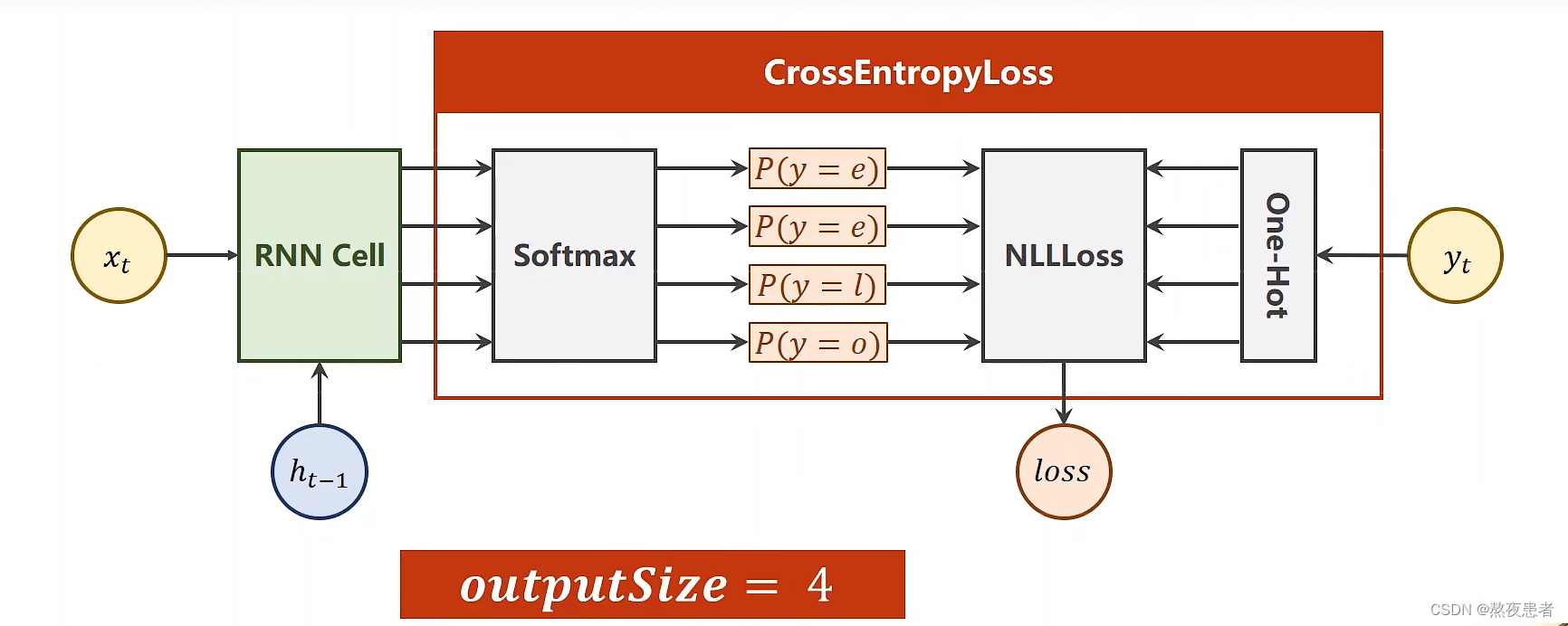
代码如下:
import torchinput_size = 4
hidden_size = 4
batch_size = 1idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]one_hot_lookup = [[1, 0, 0, 0],[0, 1, 0, 0],[0, 0, 1, 0],[0, 0, 0, 1]]x_one_hot = [one_hot_lookup[x] for x in x_data]inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
labels = torch.LongTensor(y_data).view(-1, 1)class Model(torch.nn.Module):def __init__(self, input_size, hidden_size, batch_size):super(Model, self).__init__()self.batch_size = batch_sizeself.input_size = input_sizeself.hidden_size = hidden_sizeself.rnncell = torch.nn.RNNCell(input_size=self.input_size,hidden_size=self.hidden_size)def forward(self, input, hidden):hidden = self.rnncell(input, hidden)return hiddendef init_hidden(self):return torch.zeros(self.batch_size, self.hidden_size)net = Model(input_size, hidden_size, batch_size)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr = 0.1)for epoch in range(15): # 循环15轮loss = 0optimizer.zero_grad() # 每一次计算前先把梯度归零hidden = net.init_hidden() # 初始化 h_0print('Predicted string:', end = '')for input, label in zip(inputs, labels): # 输入seq_length, batch_size, input_sizehidden = net(input, hidden)loss += criterion(hidden, label) # 所有的损失要用累加,不能用item_, idx = hidden.max(dim = 1) # 找到hidden 里面最大的值,认为是最有可能的print(idx2char[idx.item()], end='')loss.backward() # 反向传播optimizer.step() # 更新参数print(', Epoch [%d/15] loss=%.4f' % (epoch+1, loss.item()))输出结果如下:

RNN 实现
老师同样通过torch.nn.RNN实现了序列到序列,代码如下:
import torchinput_size = 4
hidden_size = 4
batch_size = 1
num_layers = 1
seq_length = 5idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]one_hot_lookup = [[1, 0, 0, 0],[0, 1, 0, 0],[0, 0, 1, 0],[0, 0, 0, 1]]x_one_hot = [one_hot_lookup[x] for x in x_data]inputs = torch.Tensor(x_one_hot).view(seq_length, batch_size, input_size)
labels = torch.LongTensor(y_data) # shape:(1, seq_length)class Model(torch.nn.Module):def __init__(self, input_size, hidden_size, batch_size, num_layers=1):super(Model, self).__init__()self.batch_size = batch_sizeself.input_size = input_sizeself.hidden_size = hidden_sizeself.num_layers = num_layersself.rnn = torch.nn.RNN(input_size=self.input_size,hidden_size=self.hidden_size,num_layers=self.num_layers)def forward(self, input):hidden = torch.zeros(self.num_layers,self.batch_size,self.hidden_size)out, _ = self.rnn(input, hidden)return out.view(-1, self.hidden_size) # shape(seq_length * batch_size, hidden_size)net = Model(input_size, hidden_size, batch_size, num_layers)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)for epoch in range(15):optimizer.zero_grad()outputs = net(inputs) # 这里可以理解为 一共seq_length行数据, 每一行对应hidden_size维度loss = criterion(outputs, labels) # 一行数据为 seq_length列loss.backward()optimizer.step()_, idx = outputs.max(dim=1)idx = idx.data.numpy()print('Predicted:', ''.join([idx2char[x] for x in idx]), end='')print(', Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))
输出的结果如下:

性能优化
独热向量编码的缺点是:
- 具有较高的维度
- 向量集过于稀疏,因为基本都在坐标轴上
- 属于硬编码,一对一的
为了学习的数据具有更低维,更密集,能学习得到对应的关系等等的特点,可以采用Embedding方法,将独热编码得到的高维数据映射到低维,也就是我们俗称的降维,通过调用torch.nn.Embedding()函数,但是因为这样隐层很多时候输出的数量和分类的数量不一致,所以要加一个线形层。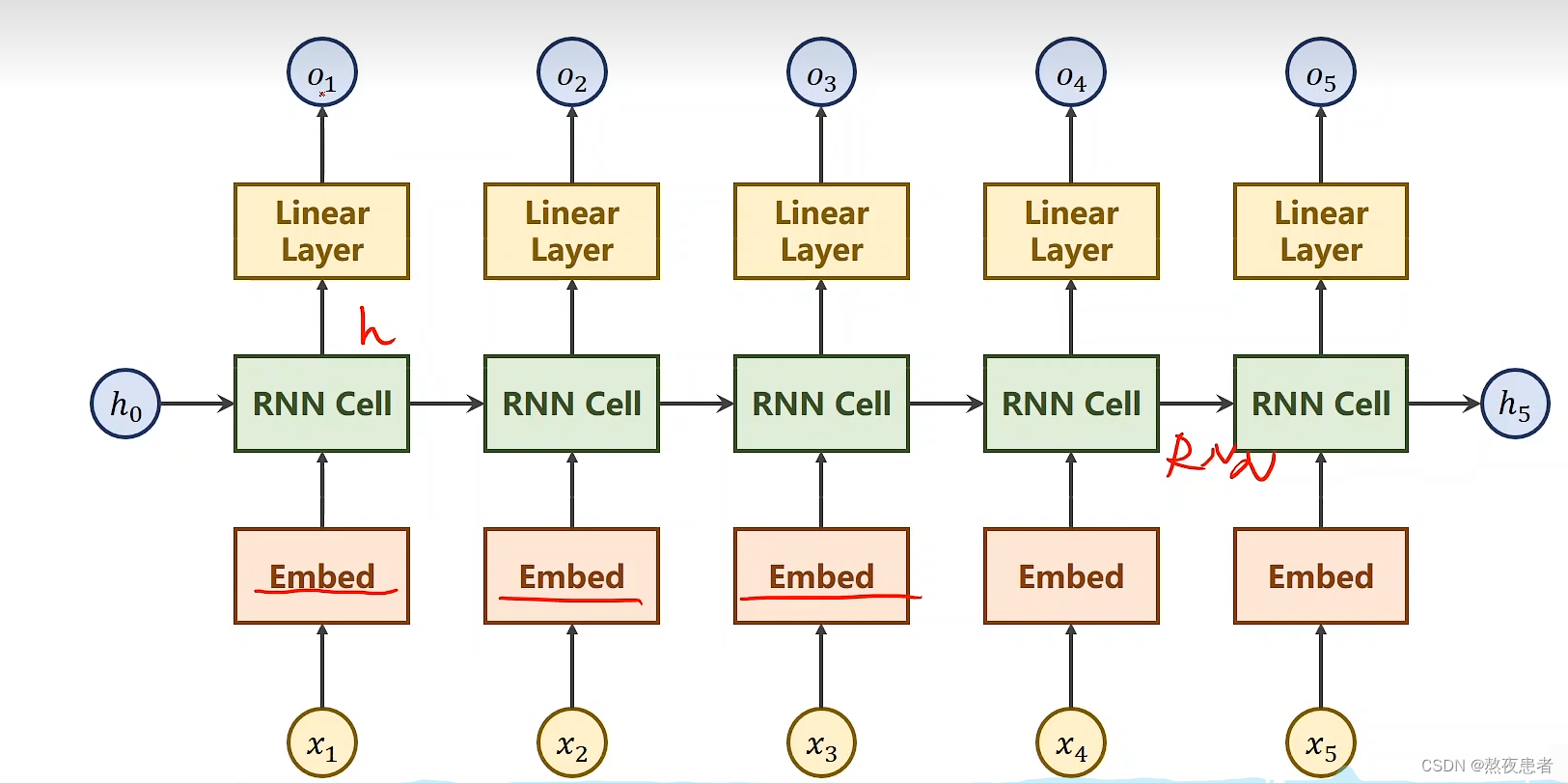
代码如下:
import torchnum_class = 4
input_size = 4
hidden_size = 8
embedding_size = 10
batch_size = 1
num_layers = 2
seq_length = 5idx2char = ['e', 'h', 'l', 'o']
x_data = [[1, 0, 2, 2, 3]]
y_data = [3, 1, 2, 3, 2]inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)class Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()self.emb = torch.nn.Embedding(input_size, embedding_size)self.rnn = torch.nn.RNN(input_size=embedding_size,hidden_size=hidden_size,num_layers=num_layers,batch_first=True)self.fc = torch.nn.Linear(hidden_size, num_class)def forward(self, x):hidden = torch.zeros(num_layers, x.size(0), hidden_size)x = self.emb(x)x, _ = self.rnn(x, hidden)x = self.fc(x)return x.view(-1, num_class)net = Model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)for epoch in range(15):optimizer.zero_grad()outputs = net(inputs) # seq_length * batch_size * hidden_sizeloss = criterion(outputs, labels) # seq_length * batch_size * 1loss.backward()optimizer.step()_, idx = outputs.max(dim=1)idx = idx.data.numpy()print('Predicted:', ''.join([idx2char[x] for x in idx]), end='')print(', Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))
结果如下:

我们发现准确率真的有很大的提升,但是由于可能看的课最近比较多,身体才好了没几天还吃不消,有点看不进去了,看了好几遍这块还是不太理解,等过段时间一定的要回来在看一遍。
3."编码器-解码器”的简单实现
首先根据上面的知识总结我们知道,这是一部分异步的序列到序列的模式,老师在b站推荐了一个很好很好的视频,放在这里
# code by Tae Hwan Jung(Jeff Jung) @graykode, modify by wmathor
import torch
import numpy as np
import torch.nn as nn
import torch.utils.data as Datadevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# S: Symbol that shows starting of decoding input
# E: Symbol that shows starting of decoding output
# ?: Symbol that will fill in blank sequence if current batch data size is short than n_stepletter = [c for c in 'SE?abcdefghijklmnopqrstuvwxyz']
letter2idx = {n: i for i, n in enumerate(letter)}seq_data = [['man', 'women'], ['black', 'white'], ['king', 'queen'], ['girl', 'boy'], ['up', 'down'], ['high', 'low']]# Seq2Seq Parameter
n_step = max([max(len(i), len(j)) for i, j in seq_data]) # max_len(=5)
n_hidden = 128
n_class = len(letter2idx) # classfication problem
batch_size = 3def make_data(seq_data):enc_input_all, dec_input_all, dec_output_all = [], [], []for seq in seq_data:for i in range(2):seq[i] = seq[i] + '?' * (n_step - len(seq[i])) # 'man??', 'women'enc_input = [letter2idx[n] for n in (seq[0] + 'E')] # ['m', 'a', 'n', '?', '?', 'E']dec_input = [letter2idx[n] for n in ('S' + seq[1])] # ['S', 'w', 'o', 'm', 'e', 'n']dec_output = [letter2idx[n] for n in (seq[1] + 'E')] # ['w', 'o', 'm', 'e', 'n', 'E']enc_input_all.append(np.eye(n_class)[enc_input])dec_input_all.append(np.eye(n_class)[dec_input])dec_output_all.append(dec_output) # not one-hot# make tensorreturn torch.Tensor(enc_input_all), torch.Tensor(dec_input_all), torch.LongTensor(dec_output_all)'''
enc_input_all: [6, n_step+1 (because of 'E'), n_class]
dec_input_all: [6, n_step+1 (because of 'S'), n_class]
dec_output_all: [6, n_step+1 (because of 'E')]
'''
enc_input_all, dec_input_all, dec_output_all = make_data(seq_data)
make_data制作数据集,enc_input存储的是每一次编码部分输入的序列,如果不足五个则需要补为5位,并且增加一个E作为输入的结束标志,dec_input存储的是译码部分的输入序列,依旧按照不满5位用?填充的原则进行填充,并且在输入序列的最前端加一个S作为输入开始的标志,dec_output存储的和dec_input一样但这里存储的为结束标志E而非开始标志
并且enc_input和dec_input需要获取独热码编码向量,而dec_output只需要获取索引即可
class TranslateDataSet(Data.Dataset):def __init__(self, enc_input_all, dec_input_all, dec_output_all):self.enc_input_all = enc_input_allself.dec_input_all = dec_input_allself.dec_output_all = dec_output_alldef __len__(self): # return dataset sizereturn len(self.enc_input_all)def __getitem__(self, idx):return self.enc_input_all[idx], self.dec_input_all[idx], self.dec_output_all[idx]loader = Data.DataLoader(TranslateDataSet(enc_input_all, dec_input_all, dec_output_all), batch_size, True)由于这里有三个数据要返回,所以需要自定义 DataSet,具体来说就是继承
torch.utils.data.Dataset类,然后实现里面的__len__以及__getitem__方法
# Model
class Seq2Seq(nn.Module):def __init__(self):super(Seq2Seq, self).__init__()self.encoder = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5) # encoderself.decoder = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5) # decoderself.fc = nn.Linear(n_hidden, n_class)def forward(self, enc_input, enc_hidden, dec_input):# enc_input(=input_batch): [batch_size, n_step+1, n_class]# dec_inpu(=output_batch): [batch_size, n_step+1, n_class]enc_input = enc_input.transpose(0, 1) # enc_input: [n_step+1, batch_size, n_class]dec_input = dec_input.transpose(0, 1) # dec_input: [n_step+1, batch_size, n_class]# h_t : [num_layers(=1) * num_directions(=1), batch_size, n_hidden]_, h_t = self.encoder(enc_input, enc_hidden)# outputs : [n_step+1, batch_size, num_directions(=1) * n_hidden(=128)]outputs, _ = self.decoder(dec_input, h_t)model = self.fc(outputs) # model : [n_step+1, batch_size, n_class]return modelmodel = Seq2Seq().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)模型的构建部分,因为需要贴合pytorch官方文档,所以调用transpose调换第一第二维,简单的 RNN 作为编码器和解码器,所以也可以修改batch_first=True,进行修改
for epoch in range(5000):for enc_input_batch, dec_input_batch, dec_output_batch in loader:# make hidden shape [num_layers * num_directions, batch_size, n_hidden]h_0 = torch.zeros(1, batch_size, n_hidden).to(device)(enc_input_batch, dec_intput_batch, dec_output_batch) = (enc_input_batch.to(device), dec_input_batch.to(device), dec_output_batch.to(device))# enc_input_batch : [batch_size, n_step+1, n_class]# dec_intput_batch : [batch_size, n_step+1, n_class]# dec_output_batch : [batch_size, n_step+1], not one-hotpred = model(enc_input_batch, h_0, dec_intput_batch)# pred : [n_step+1, batch_size, n_class]pred = pred.transpose(0, 1) # [batch_size, n_step+1(=6), n_class]loss = 0for i in range(len(dec_output_batch)):# pred[i] : [n_step+1, n_class]# dec_output_batch[i] : [n_step+1]loss += criterion(pred[i], dec_output_batch[i])if (epoch + 1) % 1000 == 0:print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))optimizer.zero_grad()loss.backward()optimizer.step()首先要准备
,然后调整对应的输入维度,并且由于输出的 pred 是个三维的数据,所以计算 loss 需要每个样本单独计算。
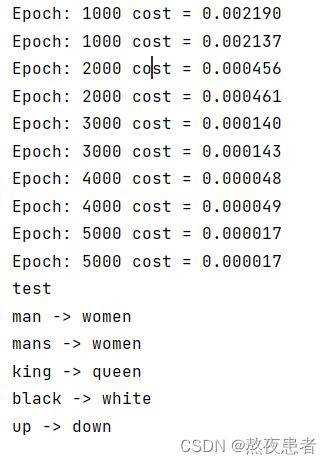
测试模块:
def translate(word):enc_input, dec_input, _ = make_data([[word, '?' * n_step]])enc_input, dec_input = enc_input.to(device), dec_input.to(device)# make hidden shape [num_layers * num_directions, batch_size, n_hidden]hidden = torch.zeros(1, 1, n_hidden).to(device)output = model(enc_input, hidden, dec_input)# output : [n_step+1, batch_size, n_class]predict = output.data.max(2, keepdim=True)[1] # select n_class dimensiondecoded = [letter[i] for i in predict]translated = ''.join(decoded[:decoded.index('E')])return translated.replace('?', '')print('test')
print('man ->', translate('man'))
print('mans ->', translate('mans'))
print('king ->', translate('king'))
print('black ->', translate('black'))
print('up ->', translate('up'))最后输出的结果如下:
4.简单总结nn.RNNCell、nn.RNN
torch.nn.RNNCell()

- input_size:输入特征的数量
- hidden_size:隐藏层特征的数量
- bias:是否具有偏置,bool类型
- nonlinearity:激活函数采用非线性,tanh/relu
关于RNNCell的调用
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
hidden = cell(input, hidden) 对于输入input的形状为 (batch, input_size)
对于输入hidden的形状为(batch, hidden_size)
对于输出hidden的形状为(batch, hidden_size)
- batch:一次输入样本的数量
- input_size:输入样本的维度
- hidden_size:隐藏层的维度
这里数据集的形状为(seq_length,batch, input_size)
- seq_length:序列长度
torch.nn.RNN()

- input_size:即
;
- hidden_size:即
;
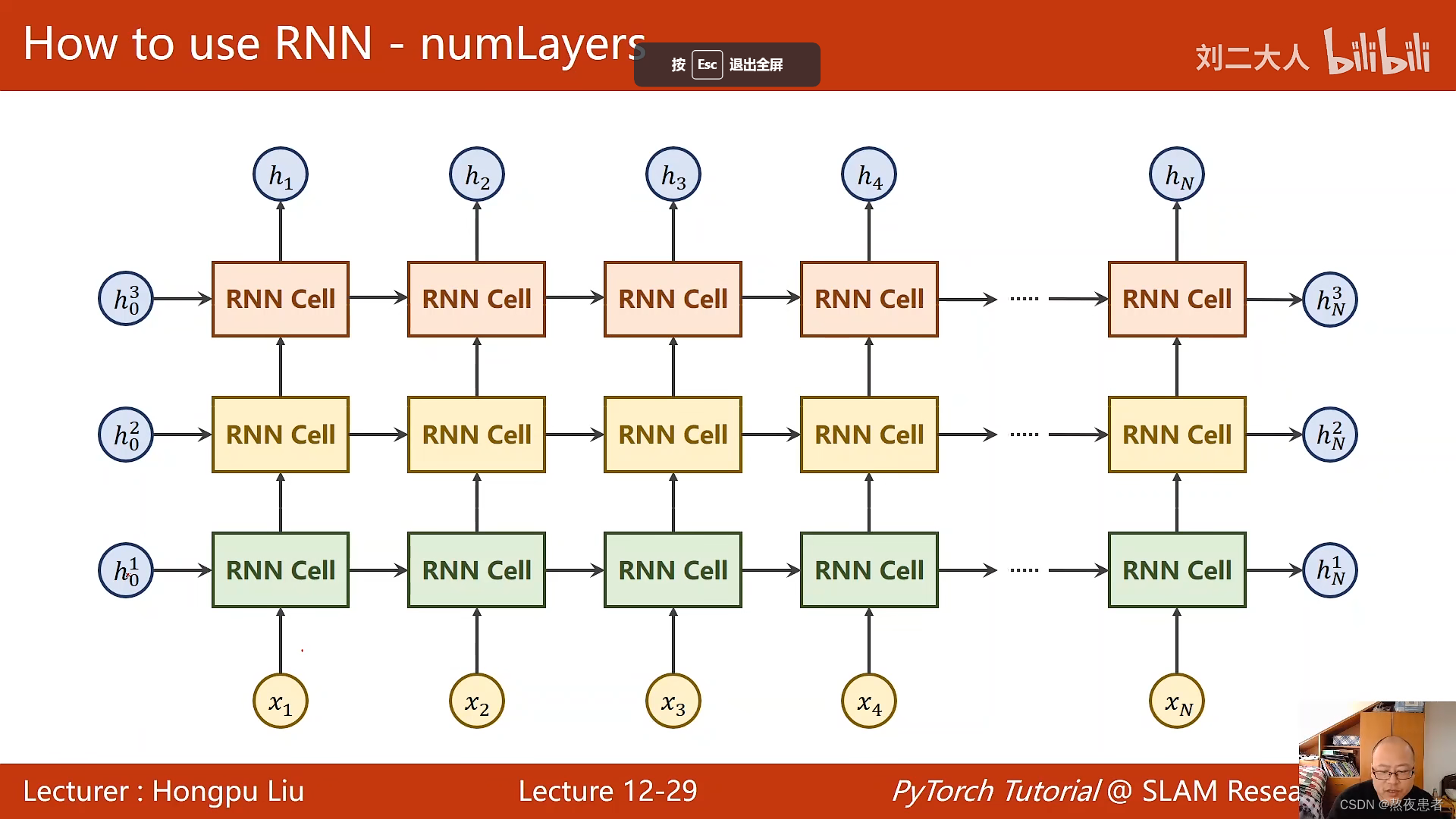
- num_layers:即RNN的层数。默认是
层。该参数大于
- nonlinearity:即非线性激活函数。可以选择
tanh或relu,默认是tanh; - bias:即偏置。默认启用,可以选择关闭;
- batch_first:即是否选择让 batch_size 作为输入的形状中的第一个参数。当 batch_first=True 时,输入应具有
这样的形状,否则应具有
这样的形状。默认是 False;
- dropout:即是否启用 dropout。如要启用,则应设置 dropout 的概率,此时除最后一层外,RNN的每一层后面都会加上一个dropout层。默认是
,即不启用;
- bidrectional:即是否启用双向RNN,默认关闭。
关于num_layers不太理解的同学看一下这个~博客
而且之前在b站中得视频中老师对num_Layers就已经有了较为清晰得解释,如下图,为num_Layers=3时得图像:
关于RNN的调用
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size,num_layers=num_layers)
out, hidden = cell(inputs, hidden)
对于输入inputs的形状为(seqSize, batch, input_size)
对于输入hidden的形状为(numLayers, batch, hidden_size)
对于输出out的形状为(seqSize, batch, hidden_size)
对于输出hidden的形状为(numLayers, batch, hidden_size)
- batch:一次输入样本的数量
- input_size:输入样本的维度
- hidden_size:隐藏层的维度
- seqSize:序列的总长度
- numLayers:RNN的总层数
RNN函数的输出为什么是两个究竟代表什么呢,看下图
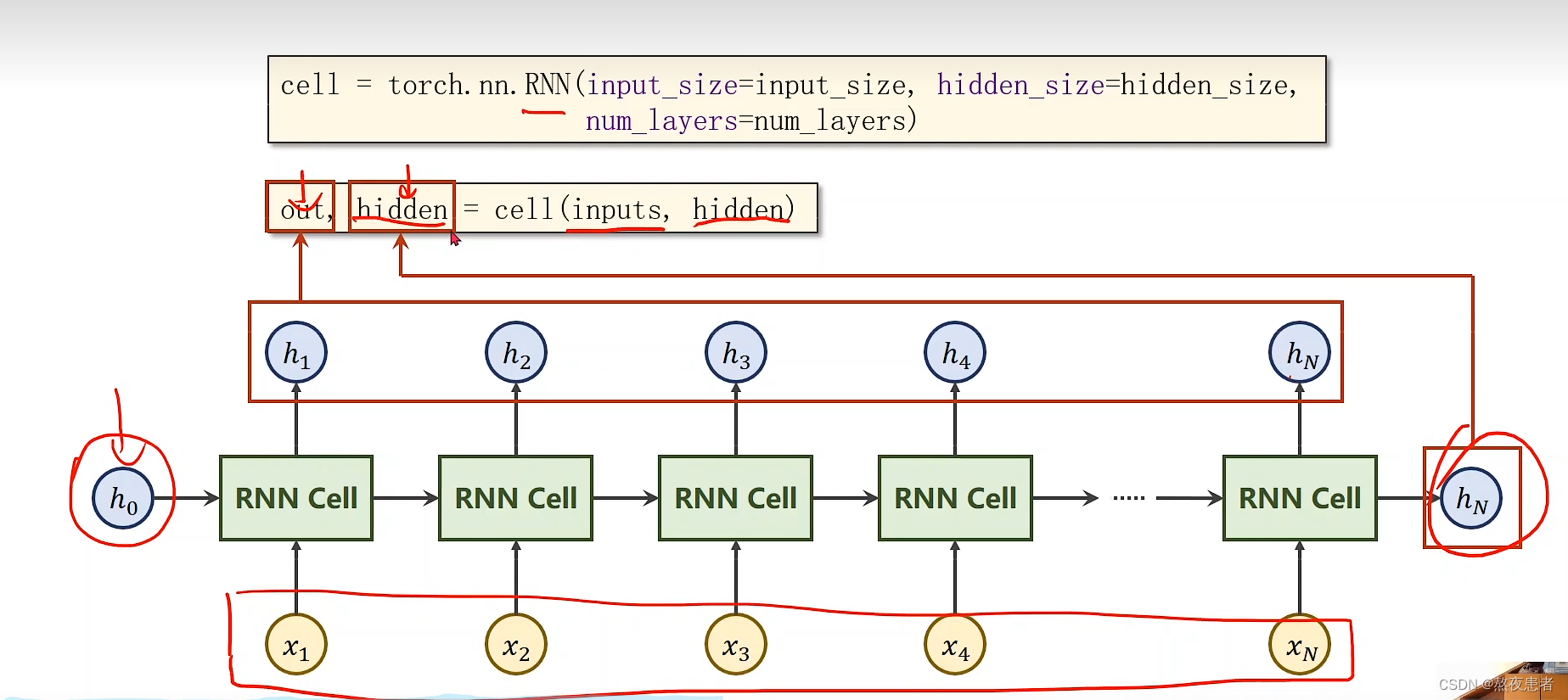
out:代表的是每一次循环神经网络的输出
输出的hidden:代表的是循环神经网络最后的输出
输入的hidden:代表的是循环神经网络最开始
inputs:输入的序列
总结
nn.RNNCell是PyTorch中的一个类,它表示循环神经网络(RNN)的一个单元。它可以独立地使用,用于在每个时间步处理序列数据。nn.RNN则是基于nn.RNNCell的封装,体现了循环神经网络的整个流程。
更简单更直接的说,nn.RNNCell是RNN的一个基本单元,用于处理单个时间步的输入;而nn.RNN是对nn.RNNCell的封装,提供更方便的接口,可以处理整个序列的数据。
5.谈一谈对“序列”、“序列到序列”的理解
序列可以理解为,有时间关系的数据,如果调整输入的顺序会影响到最后输出的结果,这就是序列。
序列到序列:序列到序列分为同步序列到序列和异步序列到序列。
- 同步序列到序列为每一时刻都有输入和输出,输入序列和输出序列的长度相同。
- 异步序列到序列为输入序列和输出序列不需要严格对应关系,也不需要保持相同长度。
对于序列到序列,我们可以理解为所给的时间序列,通过RNN得到另外有一条相关序列的过程,就是序列到序列。
6.总结本周理论课和作业,写心得体会
因为在每一部分我都有一定程度的总结,所以在这里的对上述总结的点这里不加以概述。
首先对于batch_size,对于CNN,batch_size很好理解,可以理解为一次传入多少的照片,很直观,但是在RNN中,我发现batch_size让我很头疼,我不理解有了时间的因素怎么产生的batch_size,但是黄天不负有心人,通过资料我发现最简单的理解就是同时有batch_size个RNN在处理数据,每个RNN处理一个字,那么如果比如说五句话(天气真好)(你是谁啊)(我是小明)(明天打球)(武汉加油)那么for循环第一段时间时,进入网络的数据就是(天,你,我,明, 武)每句话的第一个字进入网络,然后依次往后,这样突然就顺畅了有没有。
其次,虽然说了不加以赘述,对于模型的参数问题,还是需要重点重复一遍,因为b站两个老师的讲解,我几乎一直是边翻自己博客记得东西边看的,不太好理解,真的觉得很难很重要,我发现了一个真的很好的博客关于输入的维度这一块讲的真的很不错,萌萌推荐。维度在目前我看来是循环神经网络的一大难点,因为搞不清维度的关系,代码真的无从下手。超参数我们发现相比于CNN真的增加了很多,所以一定要需要很用心的去记。给自己提个醒。
最后,对于RNN的自我的理解,因为上周生病,其实对上周的理论课基本忘得都差不多了,这也是我为什么开头一定要对知识进行总结,因为如果不总结,我感觉可能这次的博客真的就是纯纯依靠别人的,复制粘贴,可能会一无所获,但是!为了学好深度学习,就不差这点时间了,言归正传,RNN可以分为N*N, 1*N, N*1, N*M,而对于每一种不同的RNN所应用的环境不同,循环神经网络 (RNN) 的原理可以用一个类比来形象地解释:假设你有一个记事本,你写下了一些文字,然后回到之前写过的文字上继续写,这样你就可以在之前写过的文字基础上进行更新。类似地,RNN 中的隐藏层就像是一个记事本,能够记录之前的信息并在之后的时间步骤中进行更新。也可以想象成你正在学习一门新语言,你会将之前学过的单词记录下来,在学习新单词时使用这些单词来帮助理解。类似地,RNN 中的隐藏层就像是你的脑海中的“单词本”,能够记录之前学过的单词并在之后的学习过程中进行更新。
参考博客
如何理解RNN中的Batch_size?_rnn神经网络模型batchsize-CSDN博客
Seq2Seq的PyTorch实现 - mathor (wmathor.com)
【23-24 秋学期】NNDL 作业9 RNN - SRN-CSDN博客
这篇关于DL Homework 9的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




