本文主要是介绍基于深度学习的钢铁缺陷检测系统(含UI界面,Python代码,数据集、yolov8),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

项目介绍
项目中所用到的算法模型和数据集等信息如下:
算法模型:
yolov8
yolov8主要包含以下几种创新:
1. 添加注意力机制(SE、CBAM等)
2. 修改可变形卷积(DySnake-主干c3替换、DySnake-所有c3替换)
数据集:
东北大学(NEU)表面缺陷数据集
以上是本套代码的整体算法架构和对目标检测模型的修改说明,这些模型修改可以为您的 毕设、作业等提供创新点和增强模型性能的功能 。
如果要是需要更换其他的检测模型,请私信。
注:本项目提供所用到的所有资源,包含 环境安装包、训练代码、测试代码、数据集、视频文件、 界面UI文件等。
如果需要yolov5版本的系统,见此链接:https://blog.csdn.net/qq_28949847/article/details/134492438
项目简介
本文将详细介绍如何使用深度学习中的YOLOv8算法实现对钢材表面缺陷的检测,并利用PyQt5设计了简约的系统UI界面。在界面中,您可以选择自己的视频文件、图片文件进行检测。此外,您还可以更换自己训练的yolov8模型,进行自己数据的检测。
该系统界面优美,检测精度高,功能强大。它具备多目标实时检测,同时可以自由选择感兴趣的检测目标。
本博文提供了完整的Python程序代码和使用教程,适合新入门的朋友参考。您可以在文末的下载链接中获取完整的代码资源文件。以下是本博文的目录:
目录
- 项目介绍
- 项目简介
- 效果展示:
- 🌟一、环境安装
- 🌟二、数据集介绍
- 🌟三、 目标检测介绍
- yolov8相关介绍
- 四、 yolov8训练步骤
- 五、 yolov8评估步骤
- 六、 训练结果
- 🌟下载链接
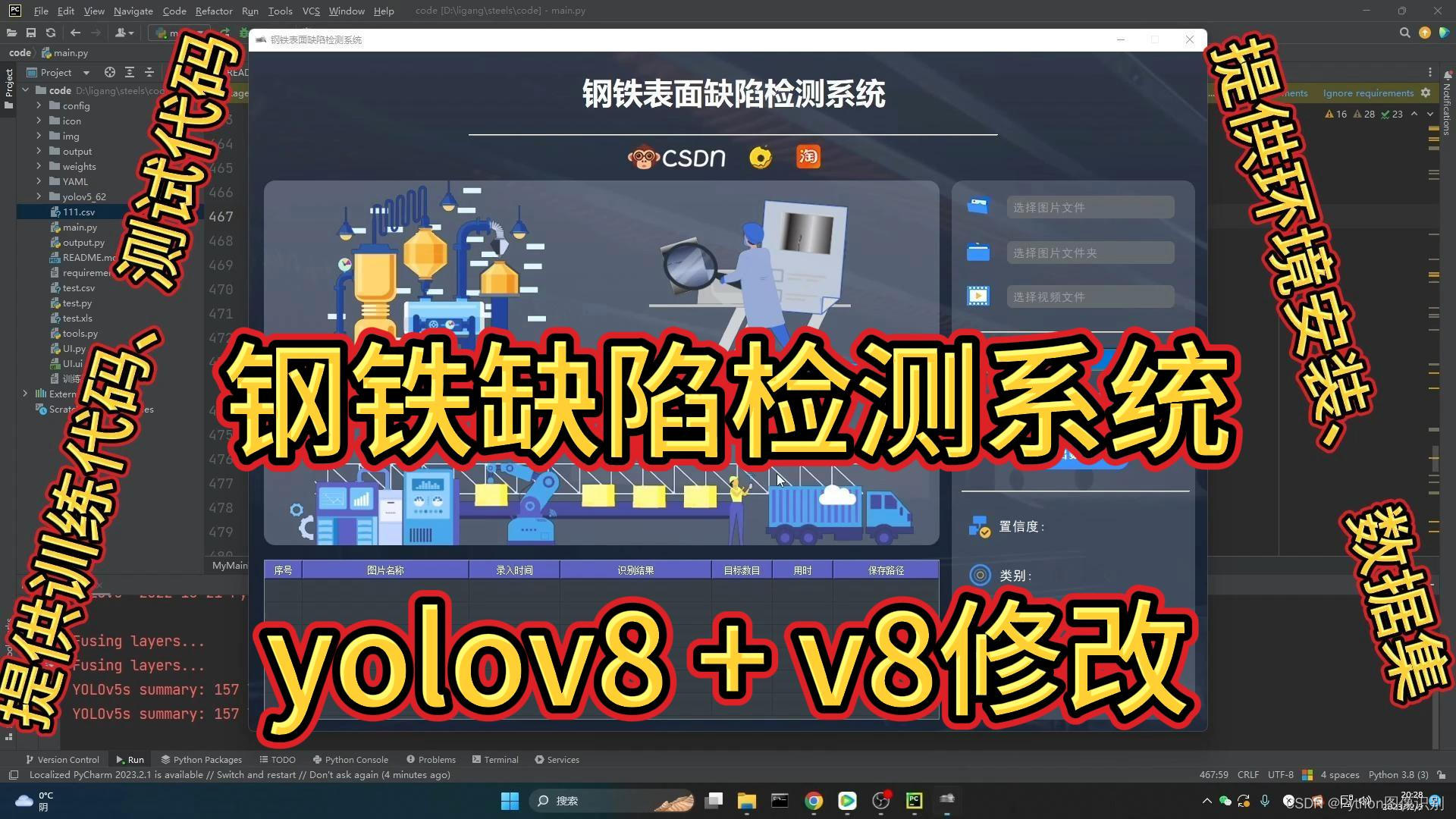
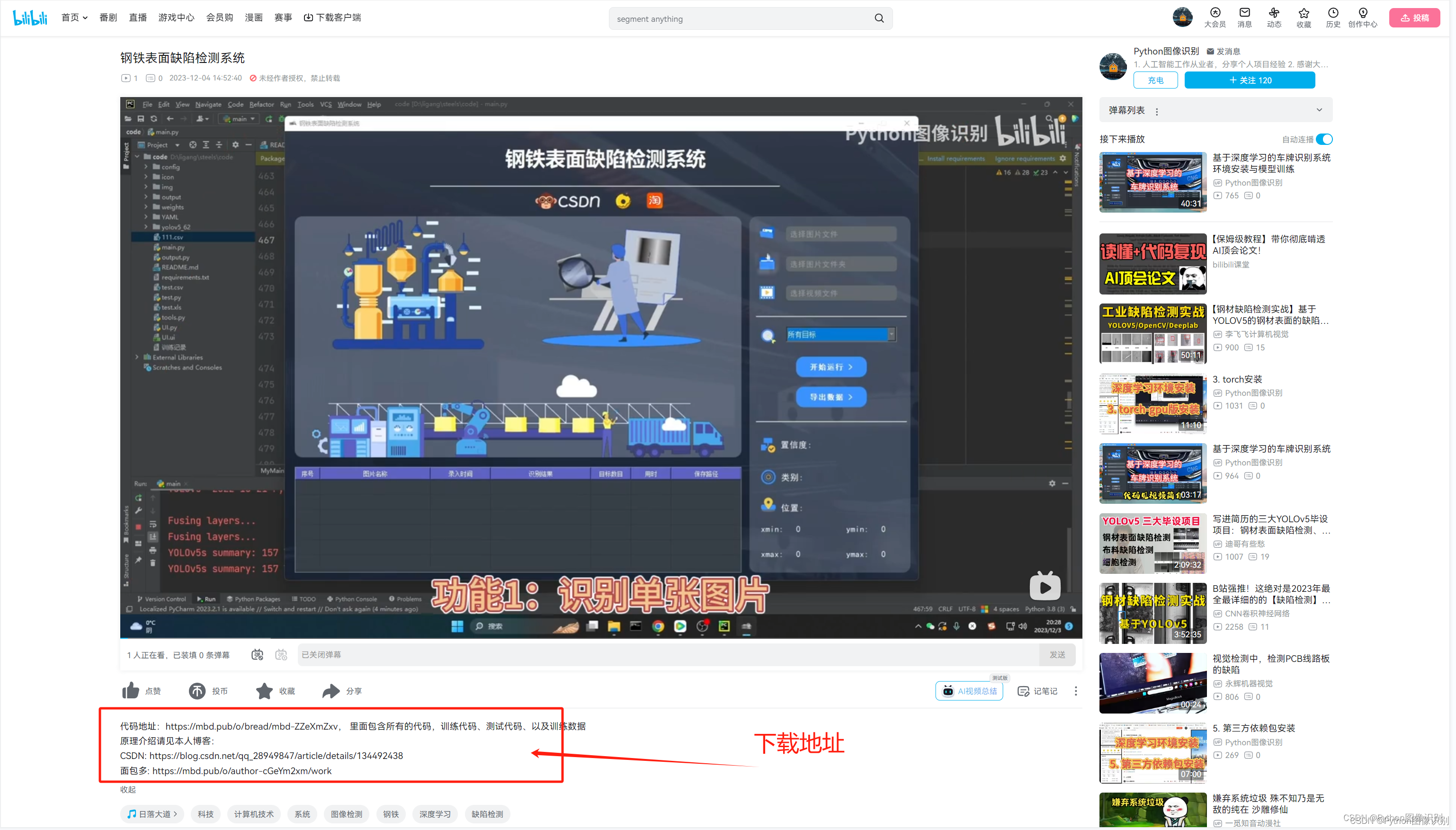
效果展示:
功能:
1. 支持单张图片识别
2. 支持遍历文件夹识别
3. 支持识别视频文件
4. 支持结果导出(xls、csv两种格式)
5. 支持切换检测到的目标
钢铁表面缺陷检测系统
🌟一、环境安装
本项目提供所有需要的环境安装包(python、pycharm、cuda、torch等),可以直接按照视频讲解进行安装。具体的安装流程见此视频:视频链接
环境安装视频是以车牌项目为例进行讲解的,但是可以适用于任何项目。
视频快进到 3:18 - 21:17,这段时间讲解的是环境安装,可直接快进到此处观看。
环境安装包可通过百度网盘下载:
链接:https://pan.baidu.com/s/17SZHeVZrpXsi513D-6KmQw?pwd=a0gi
提取码:a0gi
–来自百度网盘超级会员V6的分享
🌟二、数据集介绍
东北大学(NEU)表面缺陷数据集,收集了热轧带钢6种典型的表面缺陷,即轧内垢(RS)、斑块(Pa)、裂纹(Cr)、点蚀面(PS)、夹杂物(In)和划痕(Sc)。该数据库包括1800张灰度图像:6种不同类型的典型表面缺陷各300个样本。
下图为6种典型表面缺陷的样本图像,每张图像的原始分辨率为200×200像素。从图中,我们可以清楚地观察到类内缺陷在外观上存在较大差异,例如划痕(最后一列)可能是水平划痕、垂直划痕和倾斜划痕等。与此同时,类间缺陷也具有相似的特征,如滚积垢、裂纹和坑状表面。此外,由于光照和材料变化的影响,类内缺陷图像的灰度会发生变化。总之,NEU表面缺陷数据库包含两个难题,即类内缺陷存在较大外观差异,类间缺陷具有相似方面,缺陷图像受到光照和材料变化的影响。

🌟三、 目标检测介绍
yolov8相关介绍
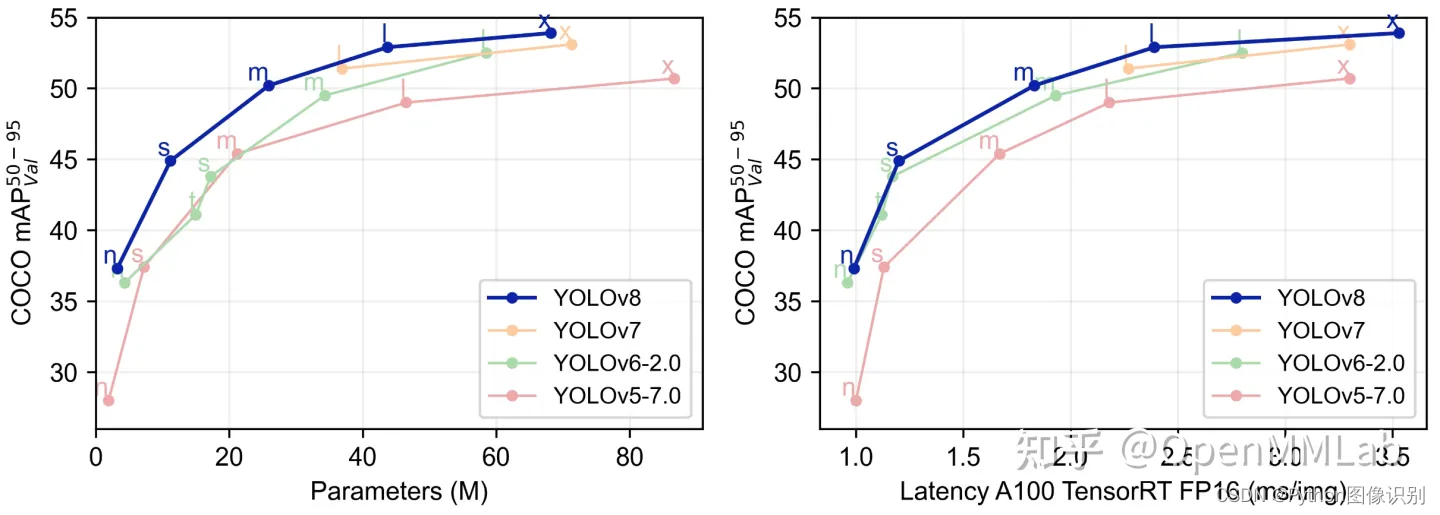
YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。具体创新包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
不过 ultralytics 并没有直接将开源库命名为 YOLOv8,而是直接使用 ultralytics 这个词,原因是 ultralytics 将这个库定位为算法框架,而非某一个特定算法,一个主要特点是可扩展性。其希望这个库不仅仅能够用于 YOLO 系列模型,而是能够支持非 YOLO 模型以及分类分割姿态估计等各类任务。
总而言之,ultralytics 开源库的两个主要优点是:
-
融合众多当前 SOTA 技术于一体
-
未来将支持其他 YOLO 系列以及 YOLO 之外的更多算法
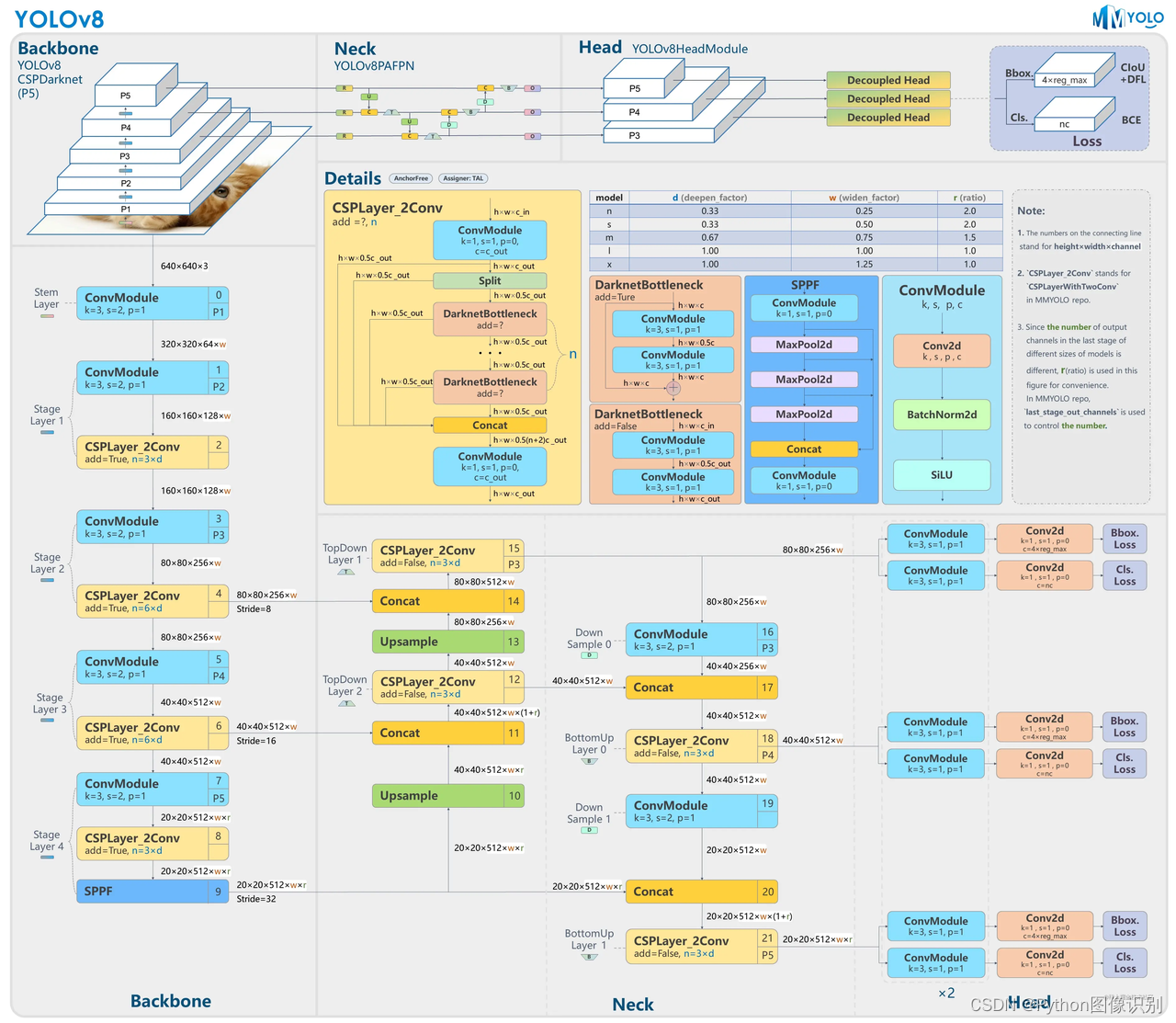
网络结构如下:
四、 yolov8训练步骤
此代码的训练步骤极其简单,不需要修改代码,直接通过cmd就可以命令运行,命令都已写好,直接复制即可,命令如下图:
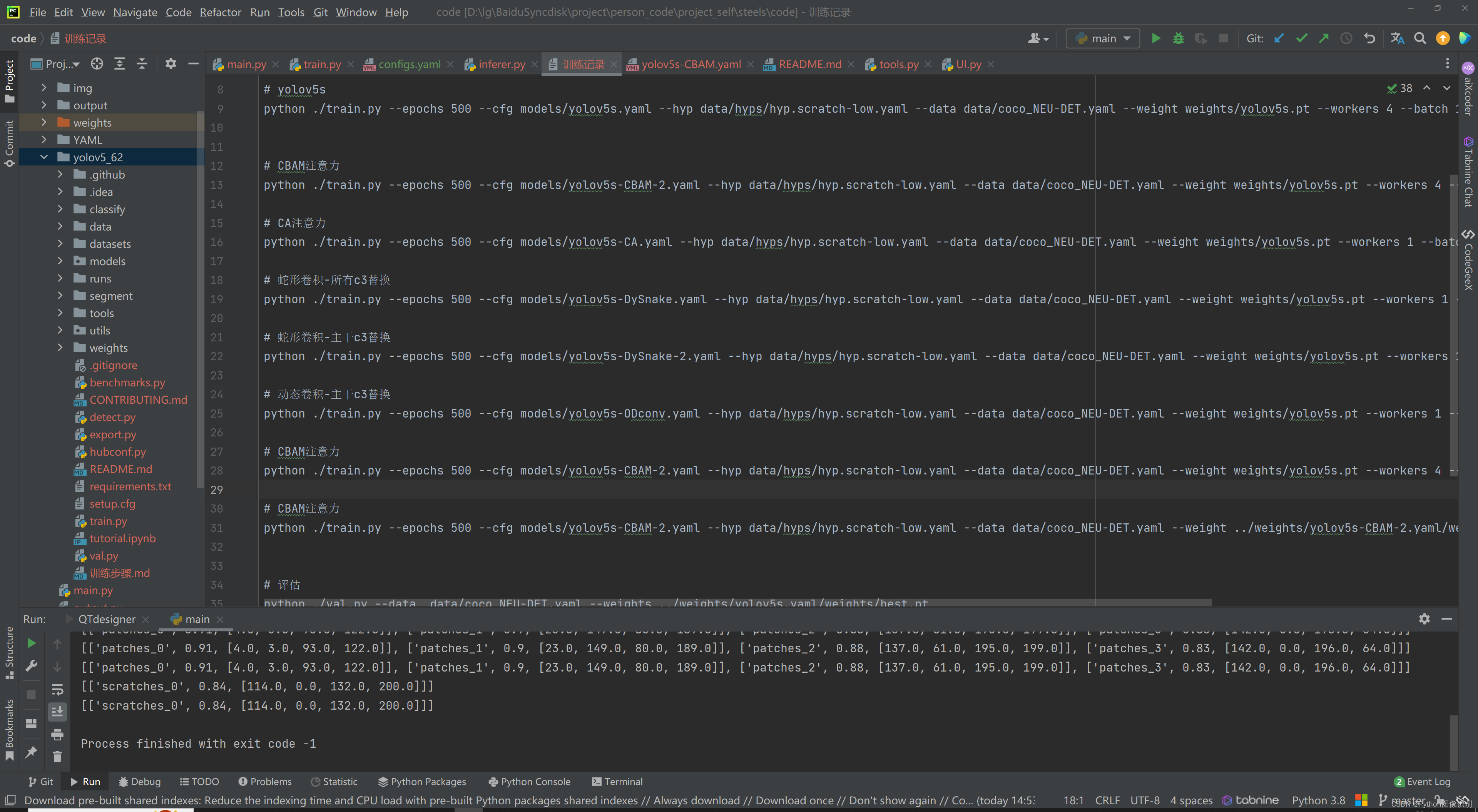
下面这条命令是 训练 添加 CBAM 注意力机制的命令,复制下来,直接就可以运行,看到训练效果。
python ./train.py --epochs 500 --cfg models/yolov5s-CBAM-2.yaml --hyp data/hyps/hyp.scratch-low.yaml --data data/coco_NEU-DET.yaml --weight weights/yolov5s.pt --workers 4 --batch 16
执行完上述命令后,即可完成训练,训练过程如下:
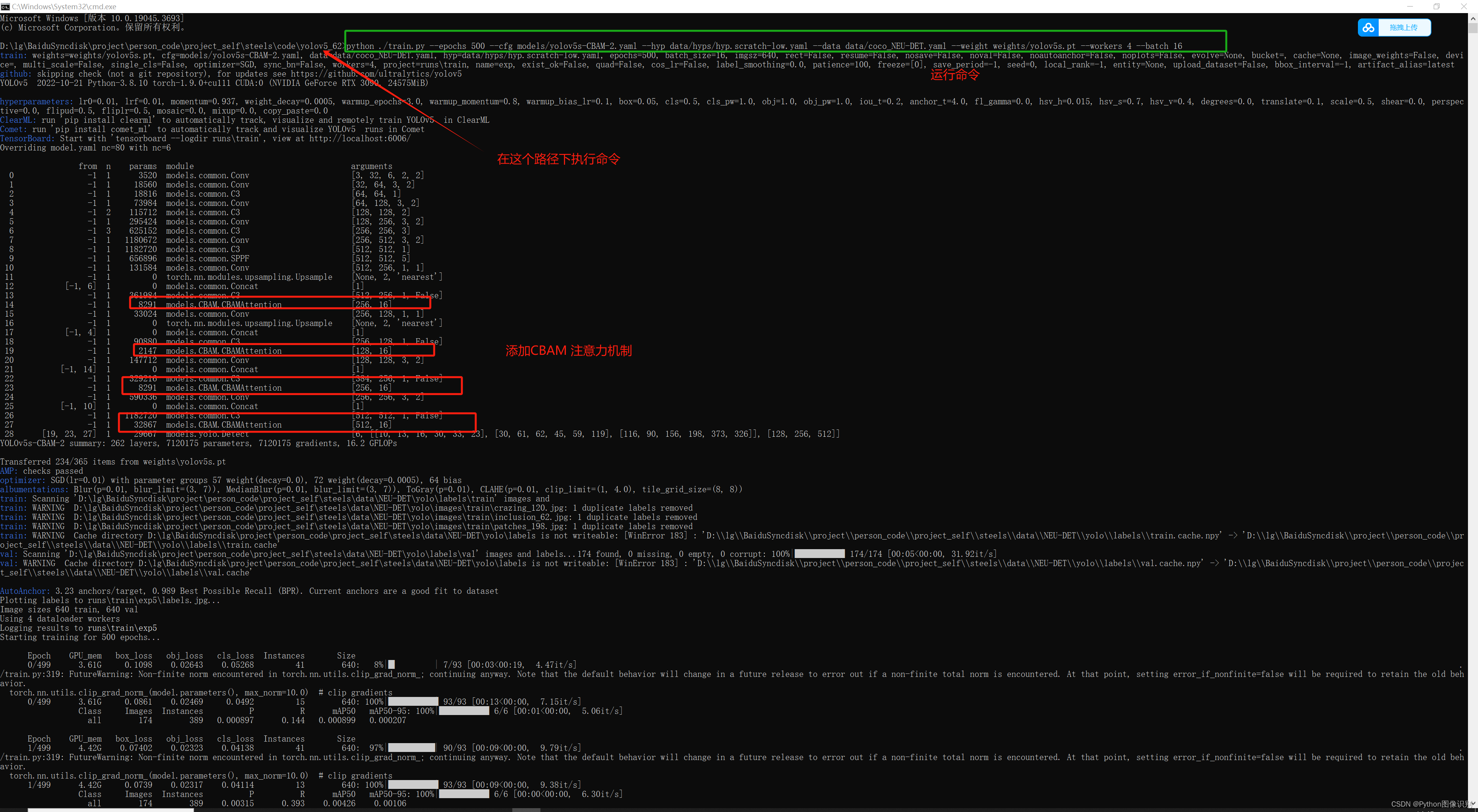
下面是对命令中各个参数的详细解释说明:
-
python: 这是Python解释器的命令行执行器,用于执行后续的Python脚本。 -
./train.py: 这是要执行的Python脚本文件的路径和名称,它是用于训练目标检测模型的脚本。 -
--epochs 500: 这是训练的总轮数(epochs),指定为500,表示训练将运行500个轮次。 -
--cfg models/yolov5s-CBAM-2.yaml: 这是YOLOv5模型的配置文件的路径和名称,它指定了模型的结构和参数设置。 -
--hyp data/hyps/hyp.scratch-low.yaml: 这是超参数文件的路径和名称,它包含了训练过程中的各种超参数设置,如学习率、权重衰减等。 -
--data data/coco_NEU-DET.yaml: 这是数据集的配置文件的路径和名称,它指定了训练数据集的相关信息,如类别标签、图像路径等。 -
--weight weights/yolov5s.pt: 这是预训练权重文件的路径和名称,用于加载已经训练好的模型权重以便继续训练或进行迁移学习。 -
--workers 4: 这是用于数据加载的工作进程数,指定为4,表示使用4个工作进程来加速数据加载。 -
--batch 16: 这是每个批次的样本数,指定为16,表示每个训练批次将包含16个样本。
通过运行上面这个命令,您将使用YOLOv5模型对目标检测任务进行训练,训练500个轮次,使用指定的配置文件、超参数文件、数据集配置文件和预训练权重。同时,使用4个工作进程来加速数据加载,并且每个训练批次包含16个样本。
五、 yolov8评估步骤
评估步骤同训练步骤一样,执行1行语句即可,注意--weights需要变为自己想要测试的模型路径。
python ./val.py --data data/coco_NEU-DET.yaml --weights ../weights/yolov5s.yaml/weights/best.pt
评估结果如下:
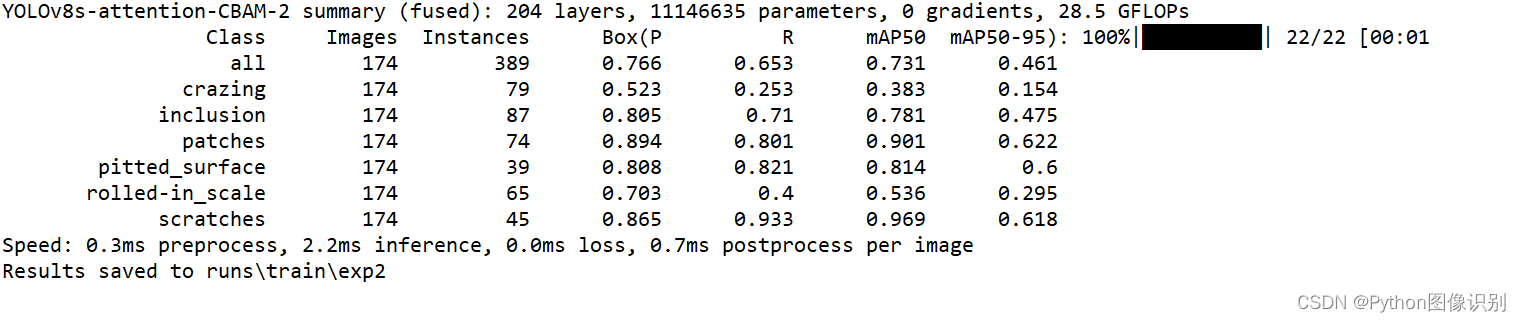
六、 训练结果
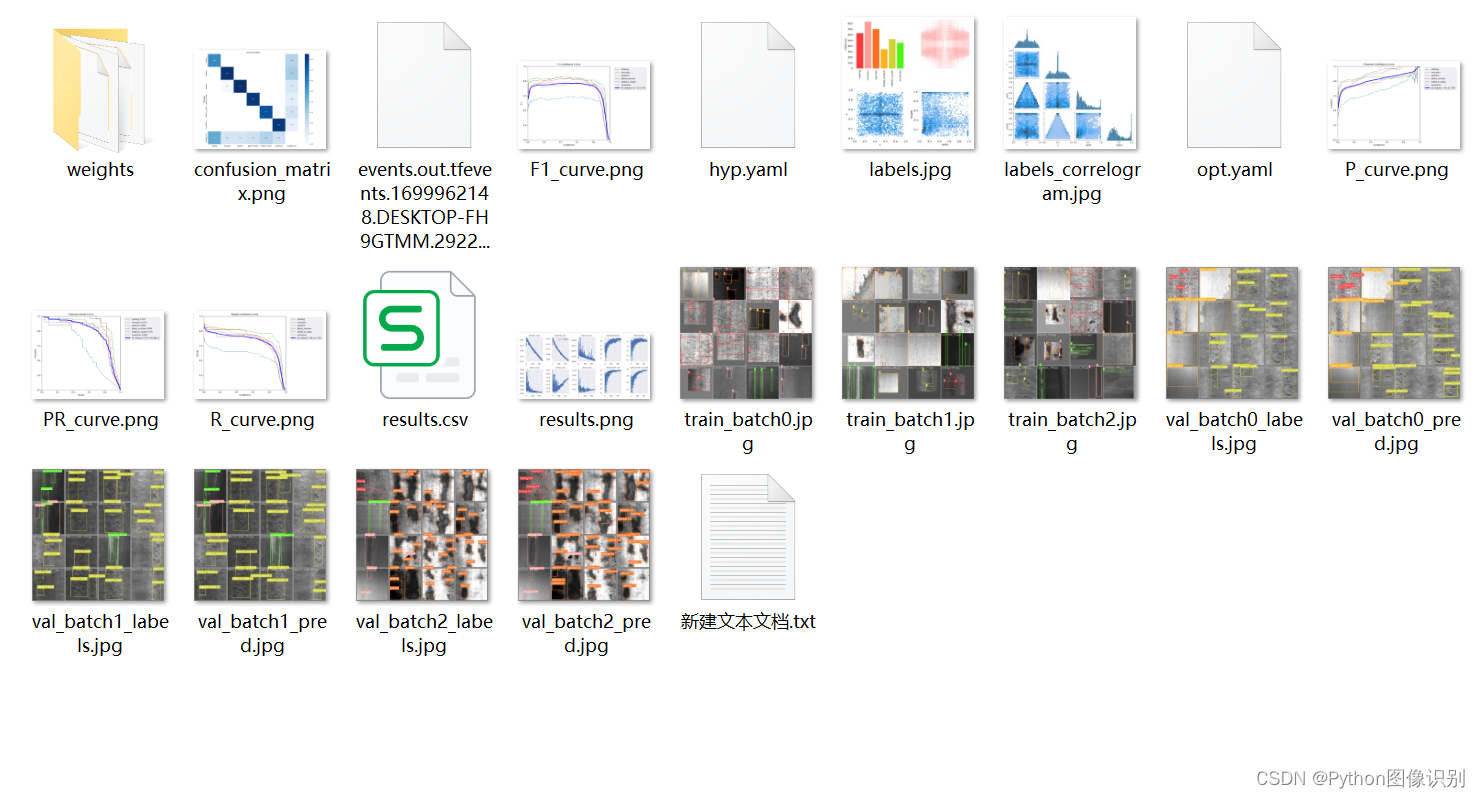
我们每次训练后,会在 run/train 文件夹下出现一系列的文件,如下图所示:
🌟下载链接
该代码采用Pycharm+Python3.8开发,经过测试能成功运行,运行界面的主程序为main.py,提供用到的所有程序。为确保程序顺利运行,请按照requirements.txt配置Python依赖包的版本。Python版本:3.8,为避免出现运行报错,请勿使用其他版本,详见requirements.txt文件;
若您想获得博文中涉及的实现完整全部程序文件(包括训练代码、测试代码、训练数据、测试数据、视频,py、 UI文件等,如下图),这里已打包上传至博主的面包多平台,可通过下方项目讲解链接中的视频简介部分下载,完整文件截图如下:
项目演示讲解链接:B站
这篇关于基于深度学习的钢铁缺陷检测系统(含UI界面,Python代码,数据集、yolov8)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







