本文主要是介绍Deep Learning(wu--84)调参、正则化、优化--改进深度神经网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 2
- 偏差和方差
- 正则化
- 梯度消失\爆炸
- 权重初始化
- 导数计算
- 梯度检验
- Optimization
- Mini-Batch 梯度下降法
- 指数加权平均
- 偏差修正
- RMSprop
- Adam
- 学习率衰减
- 局部最优问题
- 调参
- BN
- softmax
- framework

2
偏差和方差
唔,这部分在机器学习里讲的更好点

训练集误差大(欠拟合)—高偏差,验证集误差大—高方差(前提 :训练集和验证集来自相同分布)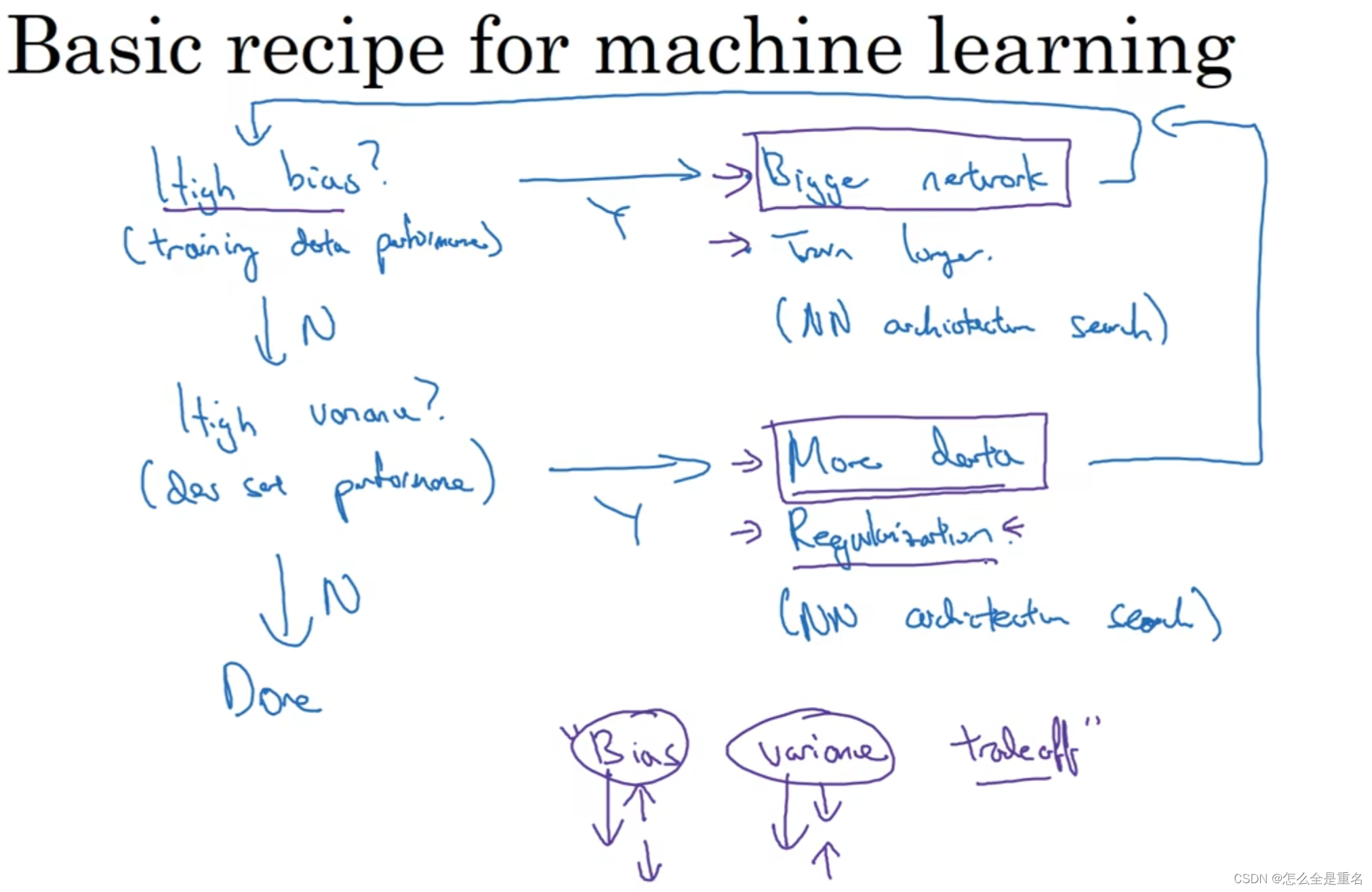
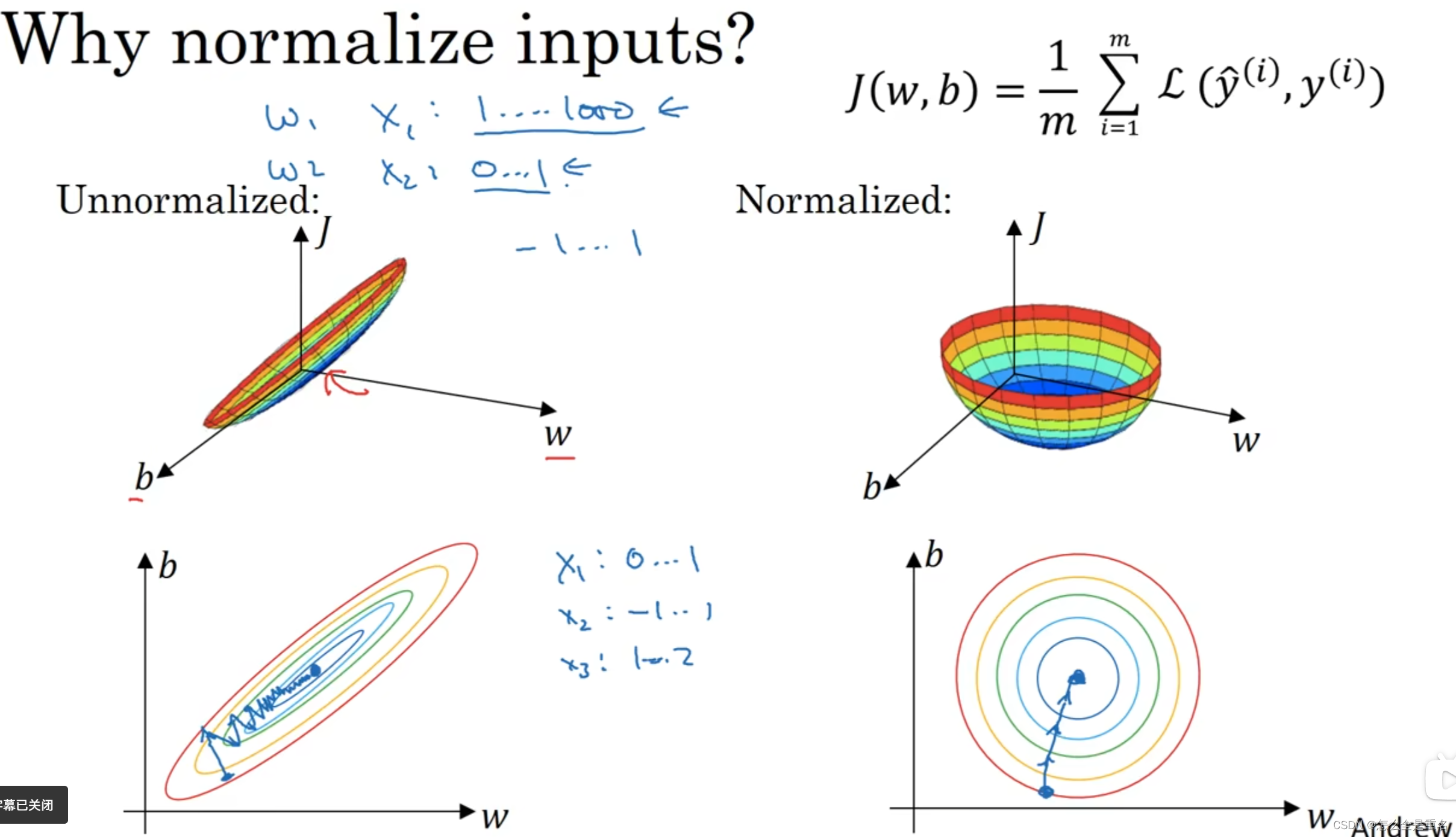
正则化


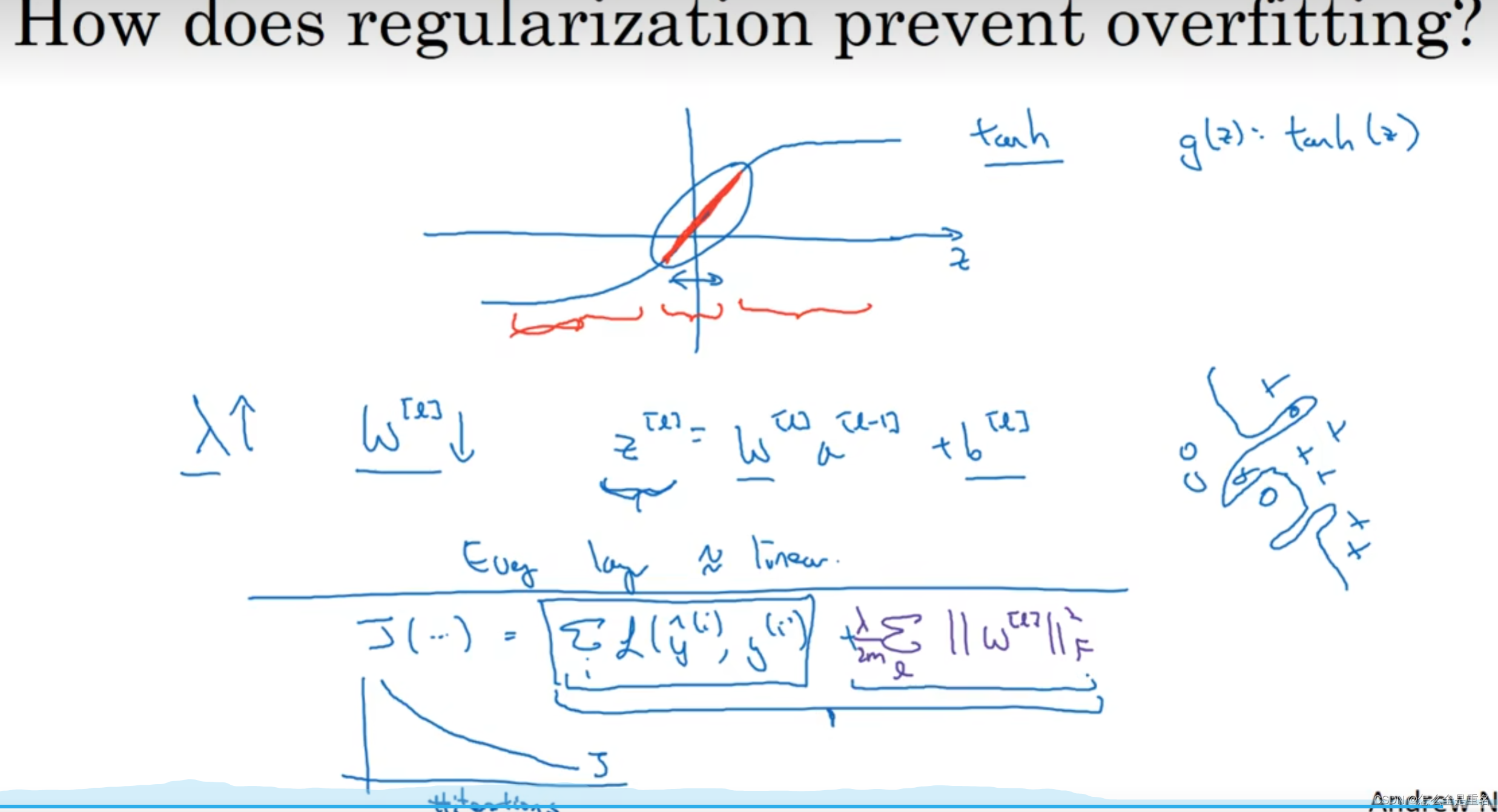

dropout随机失活,消除一些节点的影响,但为了不影响整体得 / keep-prob,补偿归零带来的损失,确保a3期望值不变
dropout仅在训练过程中进行
为了保证神经元输出激活值的期望值与不使用dropout时一致
我们结合概率论的知识来具体看一下:假设一个神经元的输出激活值为a,在不使用dropout的情况下,其输出期望值为a,如果使用了dropout,神经元就可能有保留和关闭两种状态,把它看作一个离散型随机变量,它就符合概率论中的0-1分布,其输出激活值的期望变为 p*a+(1-p)*0=pa,此时若要保持期望和不使用dropout时一致,就要除以 p

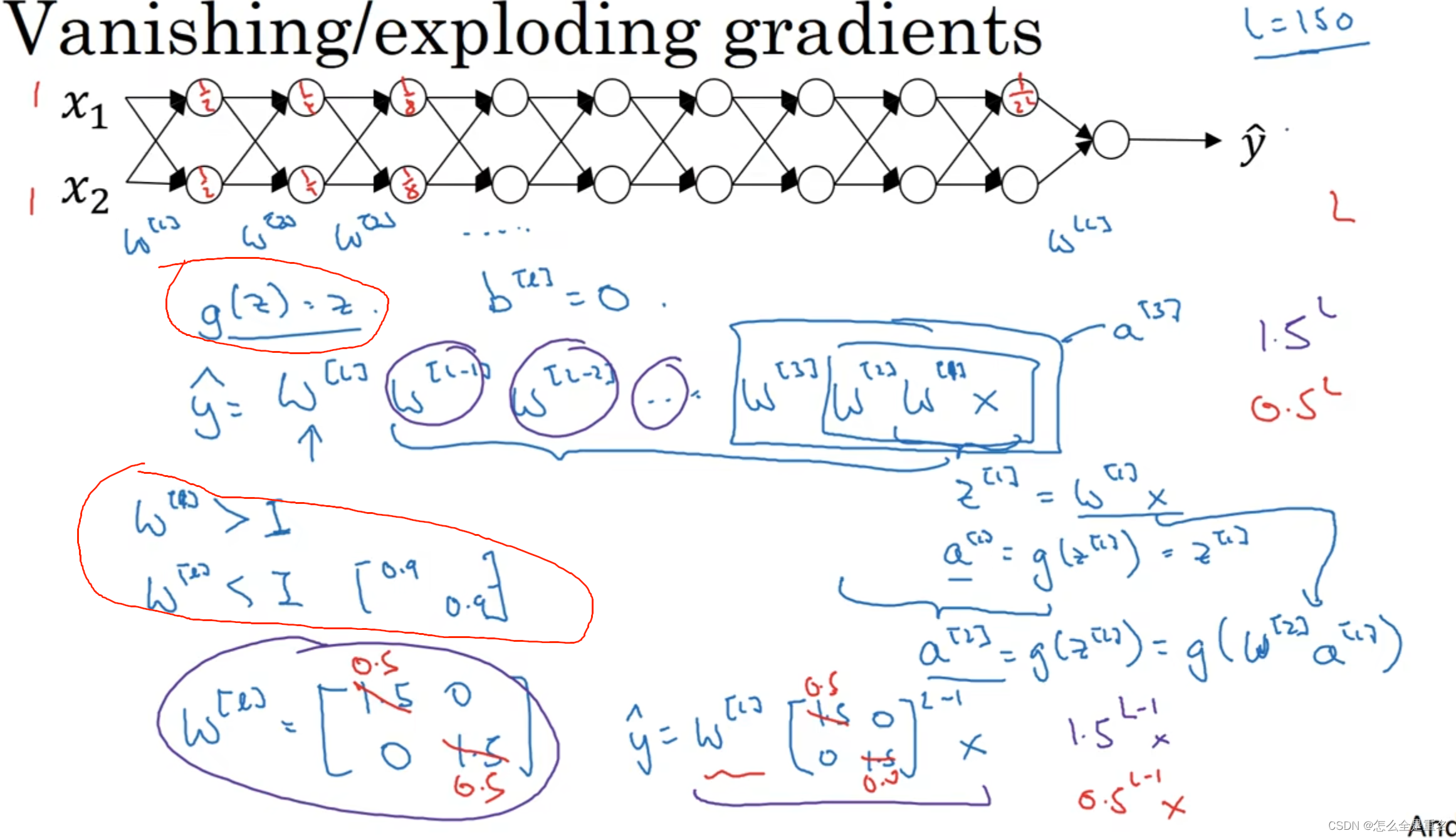
梯度消失\爆炸
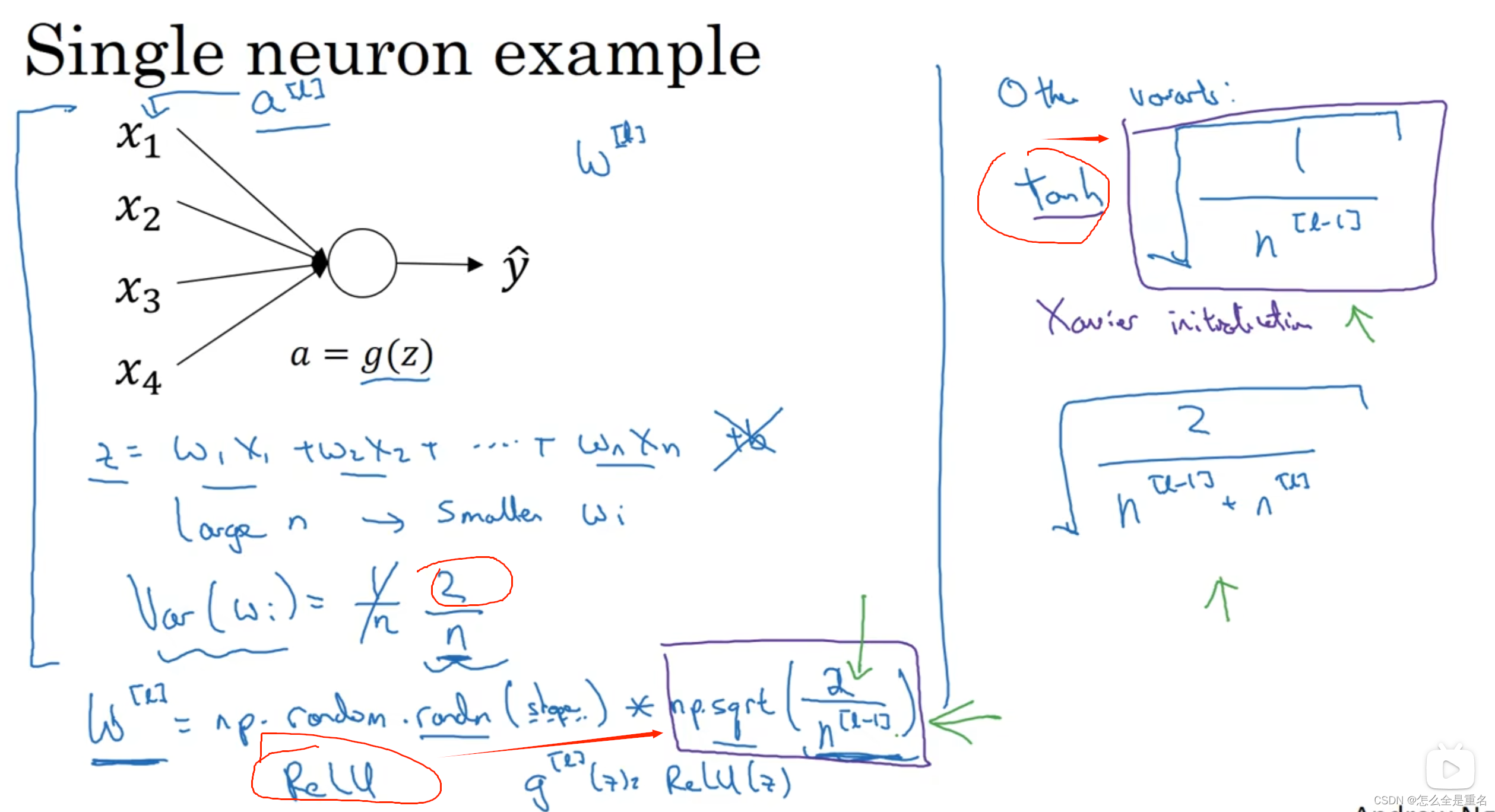
权重初始化
导数计算

双边差分误差要小于单边
梯度检验
通过双边差分检验dθ是否准确


Optimization
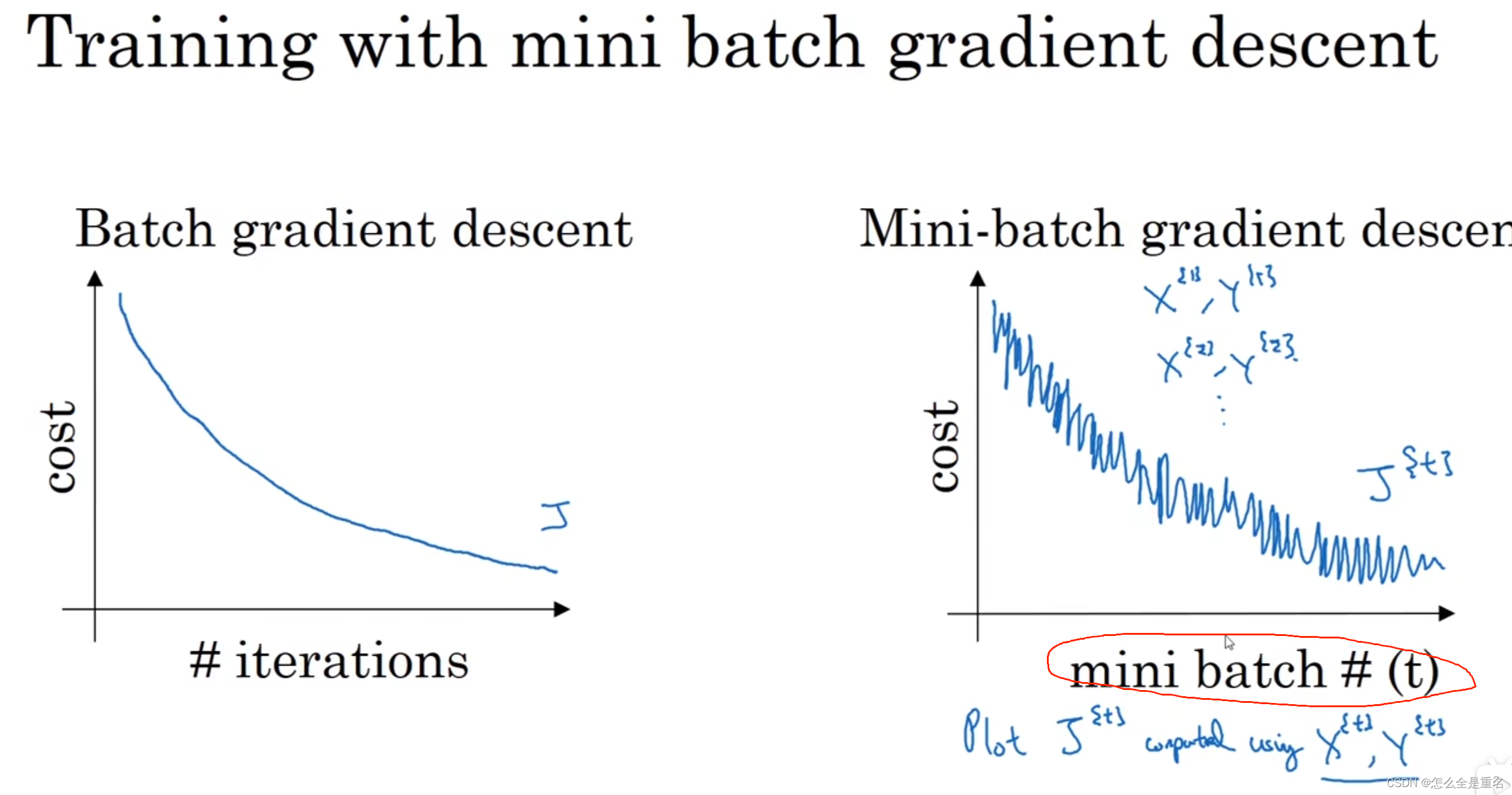
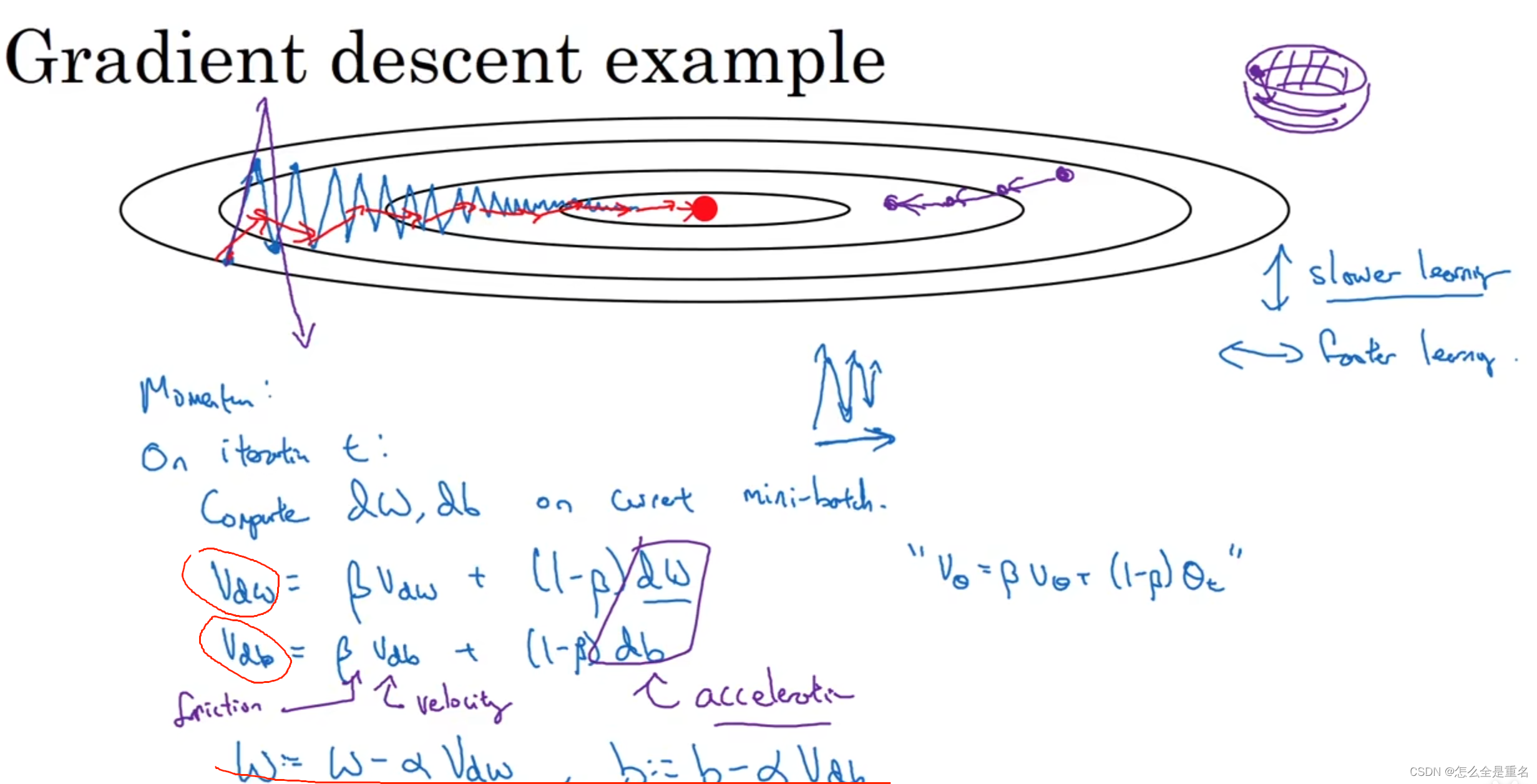
Mini-Batch 梯度下降法


指数加权平均
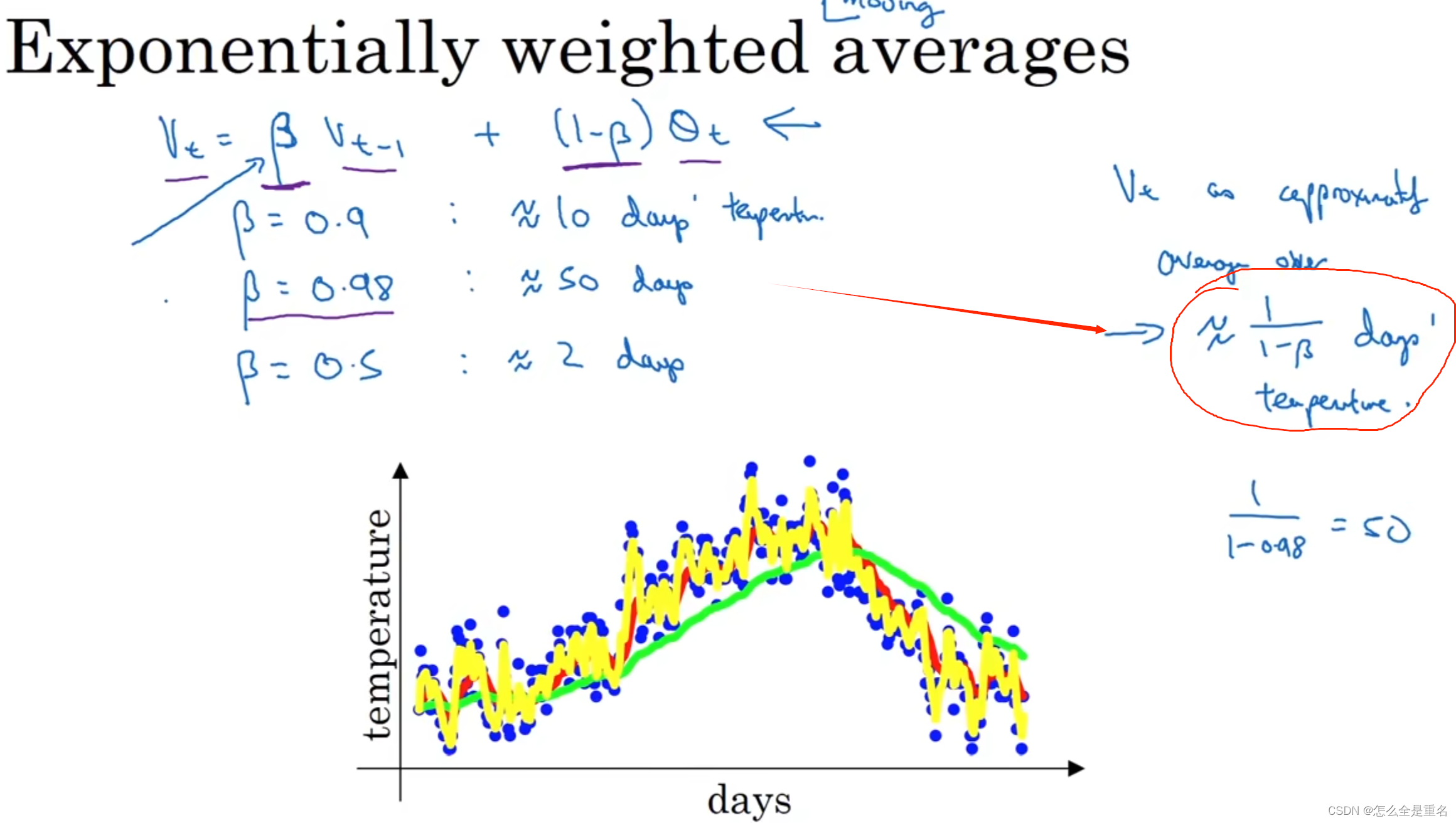


偏差修正
可以在早期获得更好的估测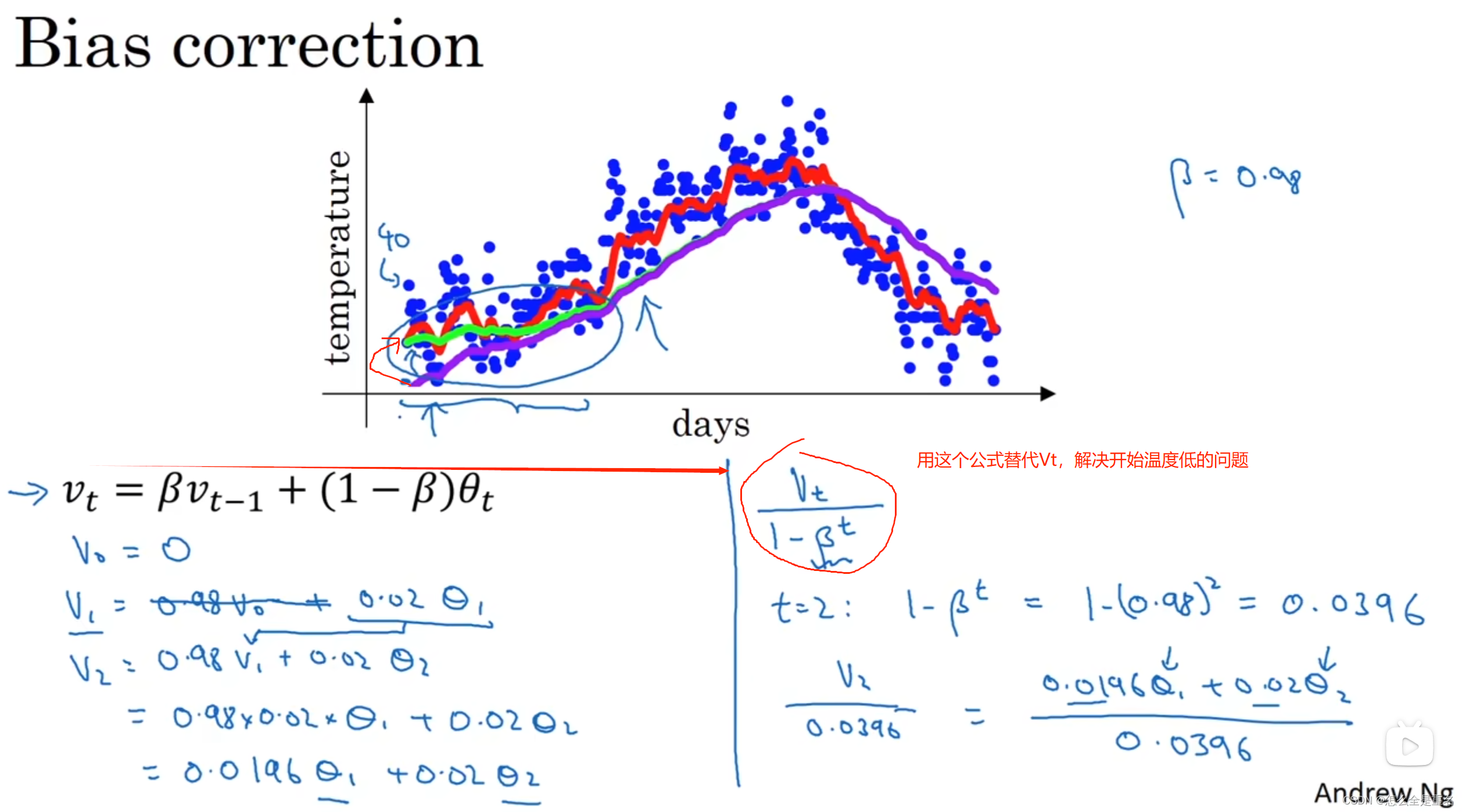

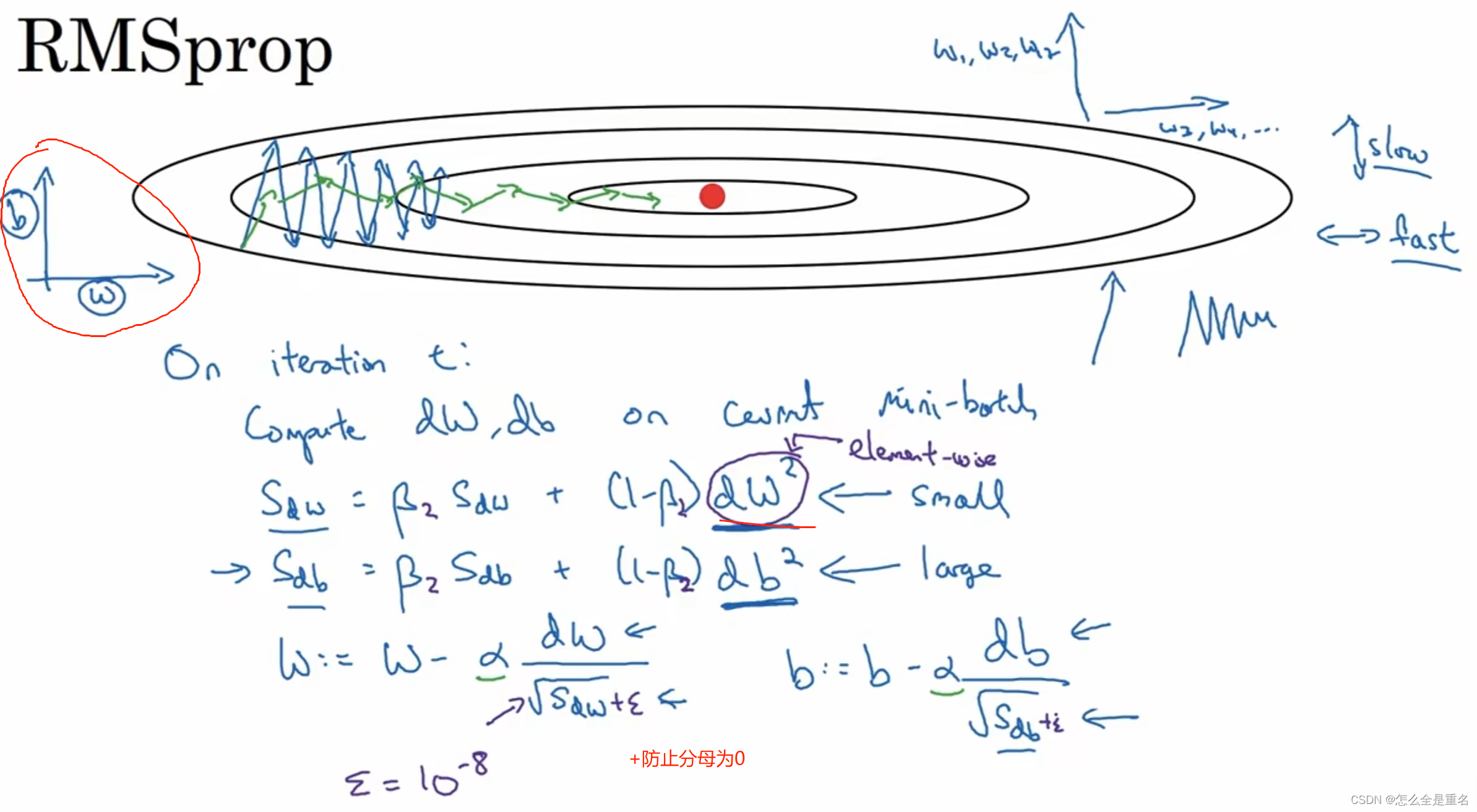
RMSprop
Adam


学习率衰减


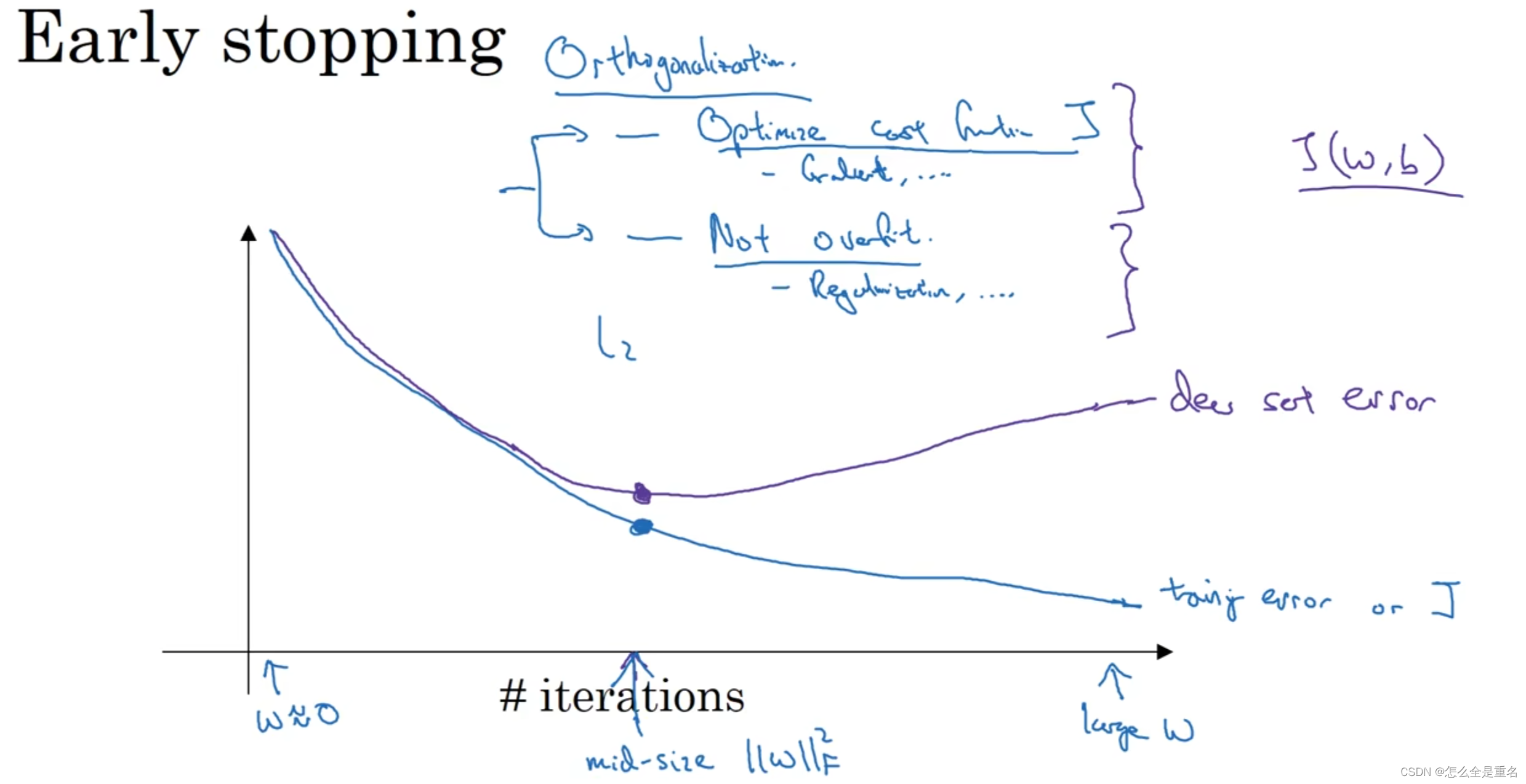
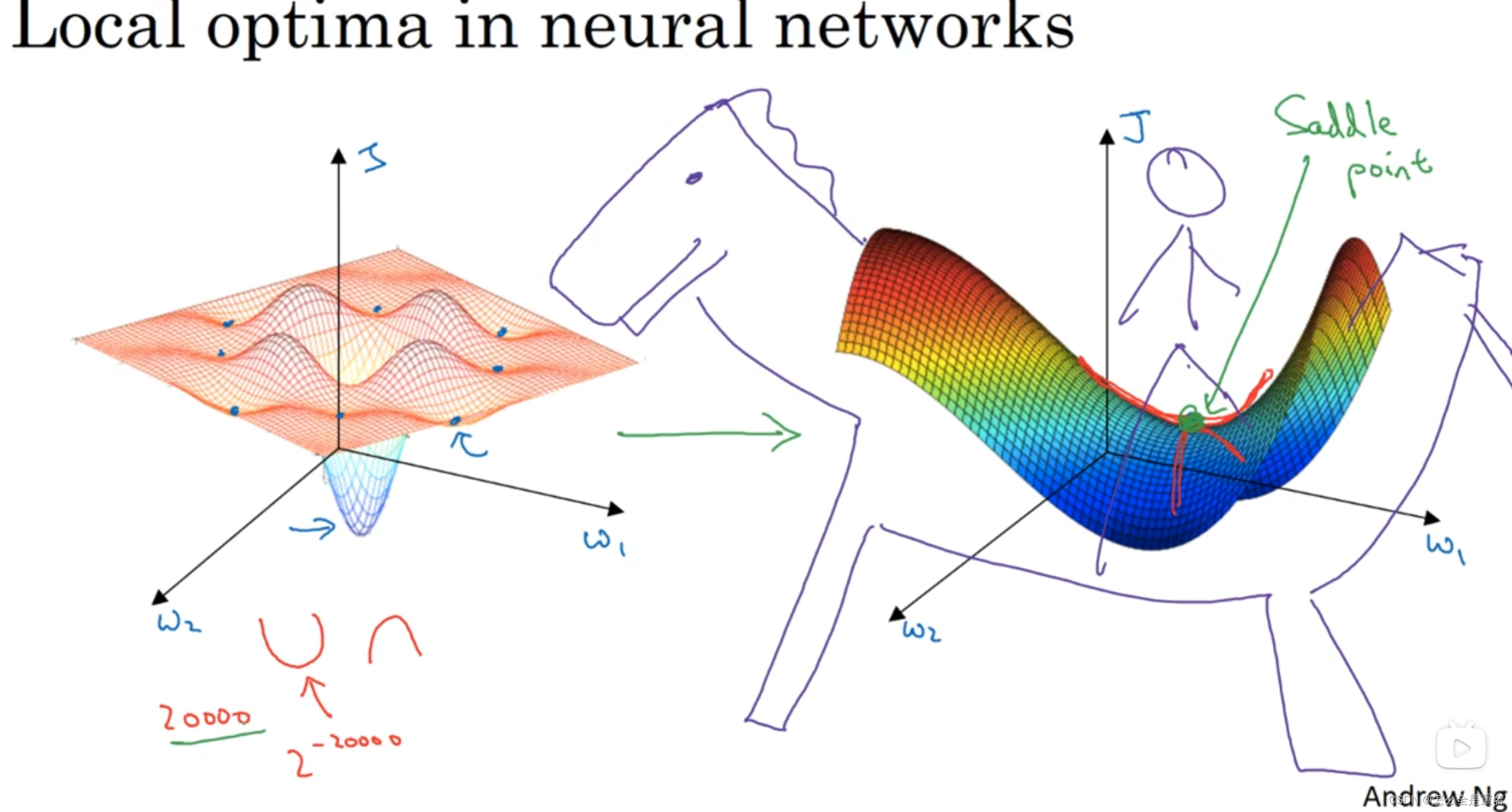
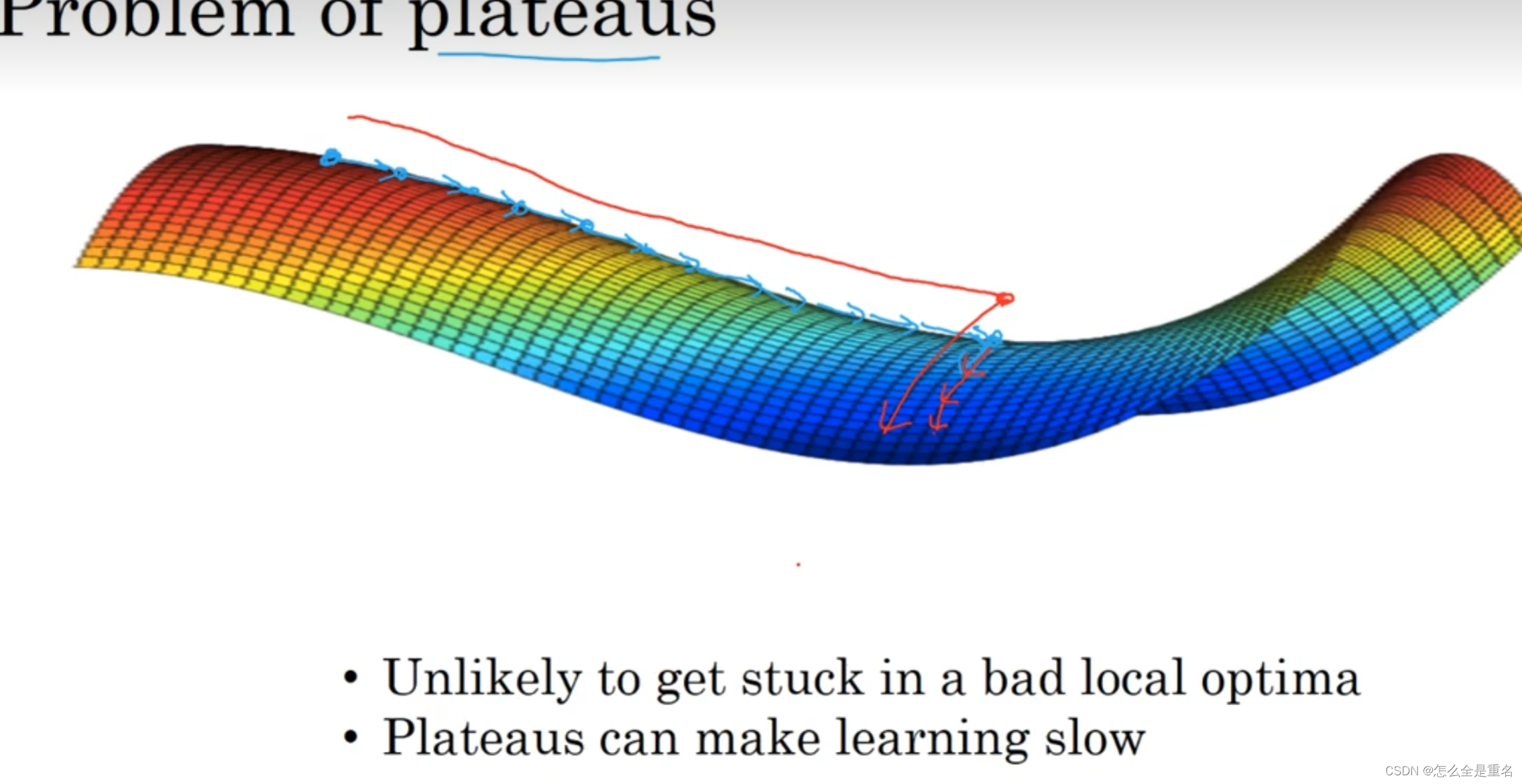
局部最优问题
通常来说不会困在极差的局部最优中,当你训练较大的神经网络,存在大量参数。cost function J会被定义在较高的空间(容易出现鞍点,即右图中的saddle point)
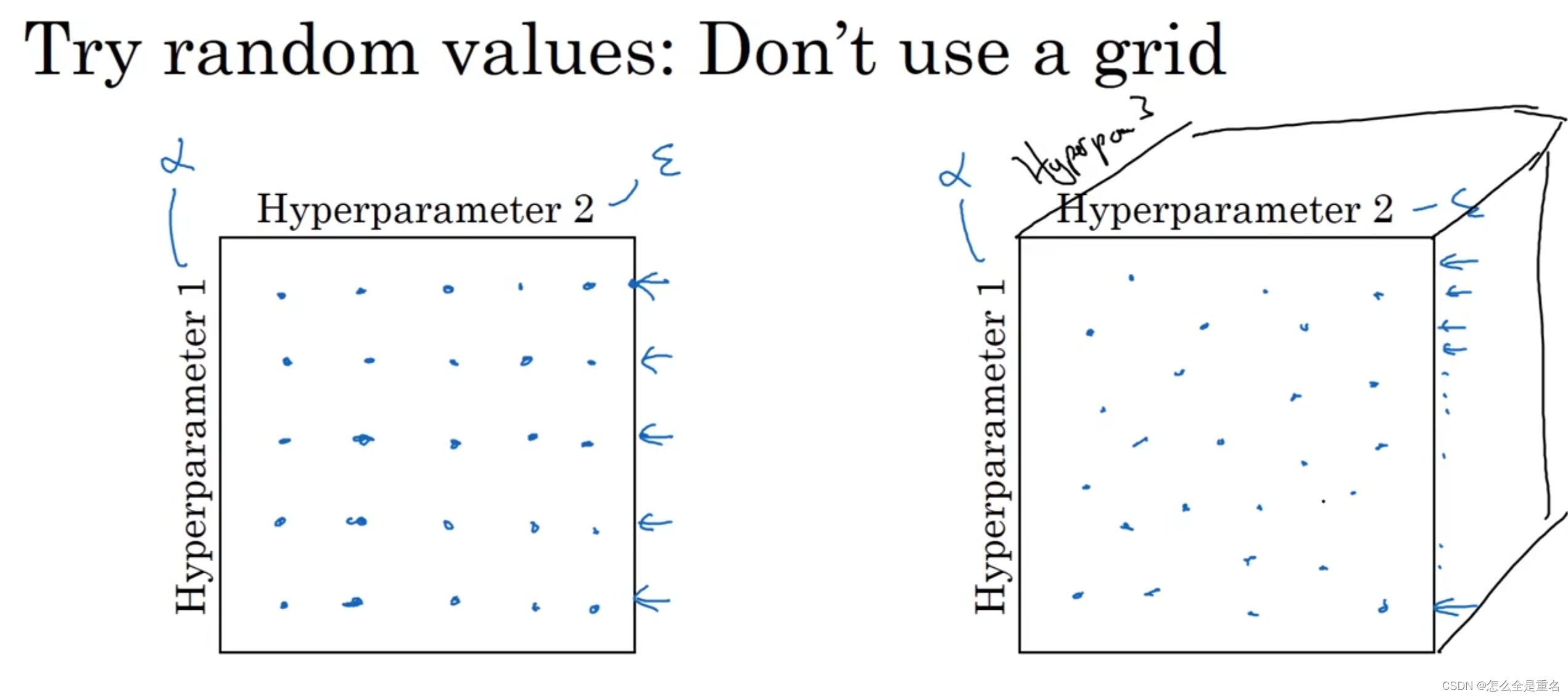
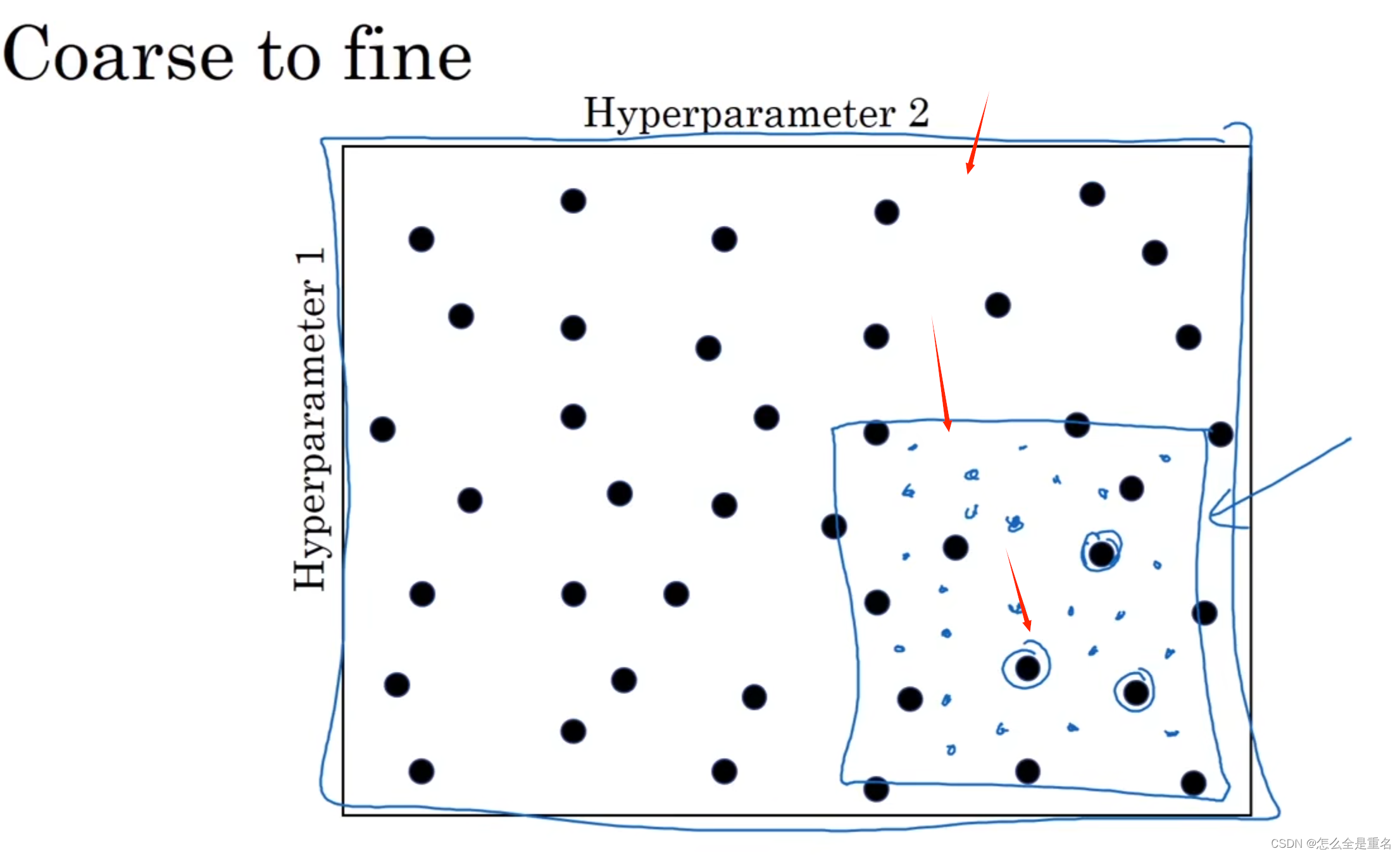
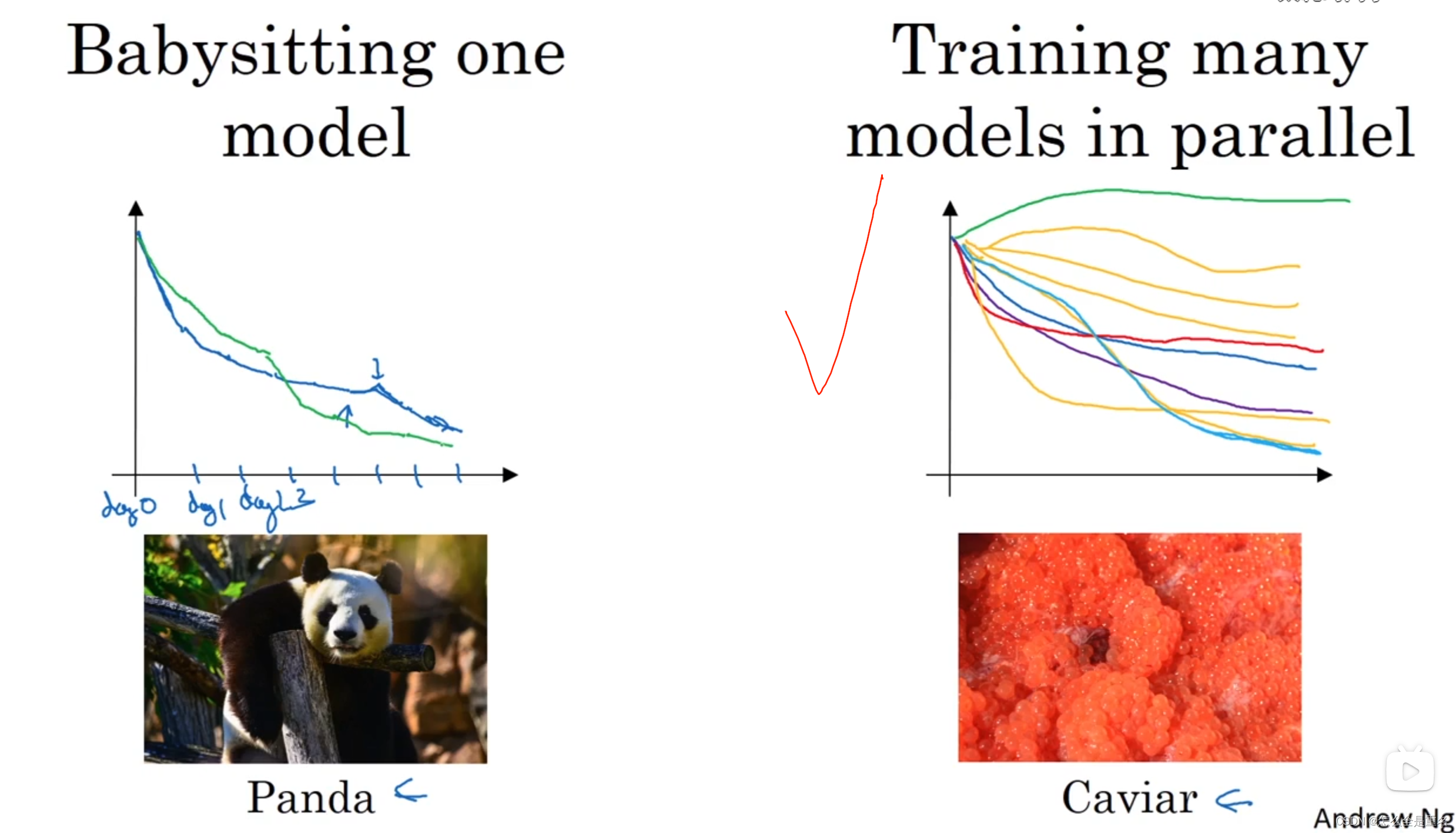
调参



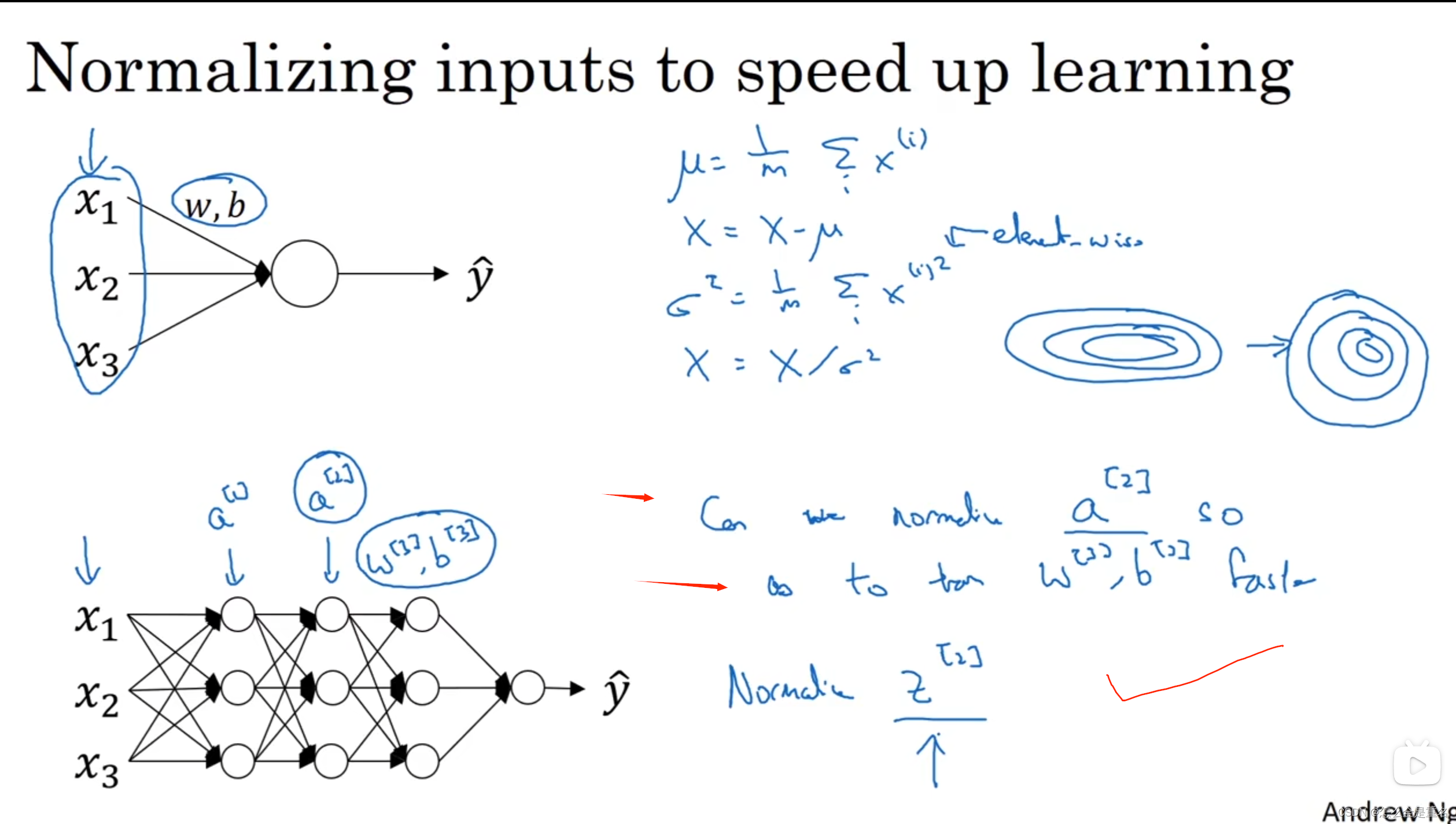
BN
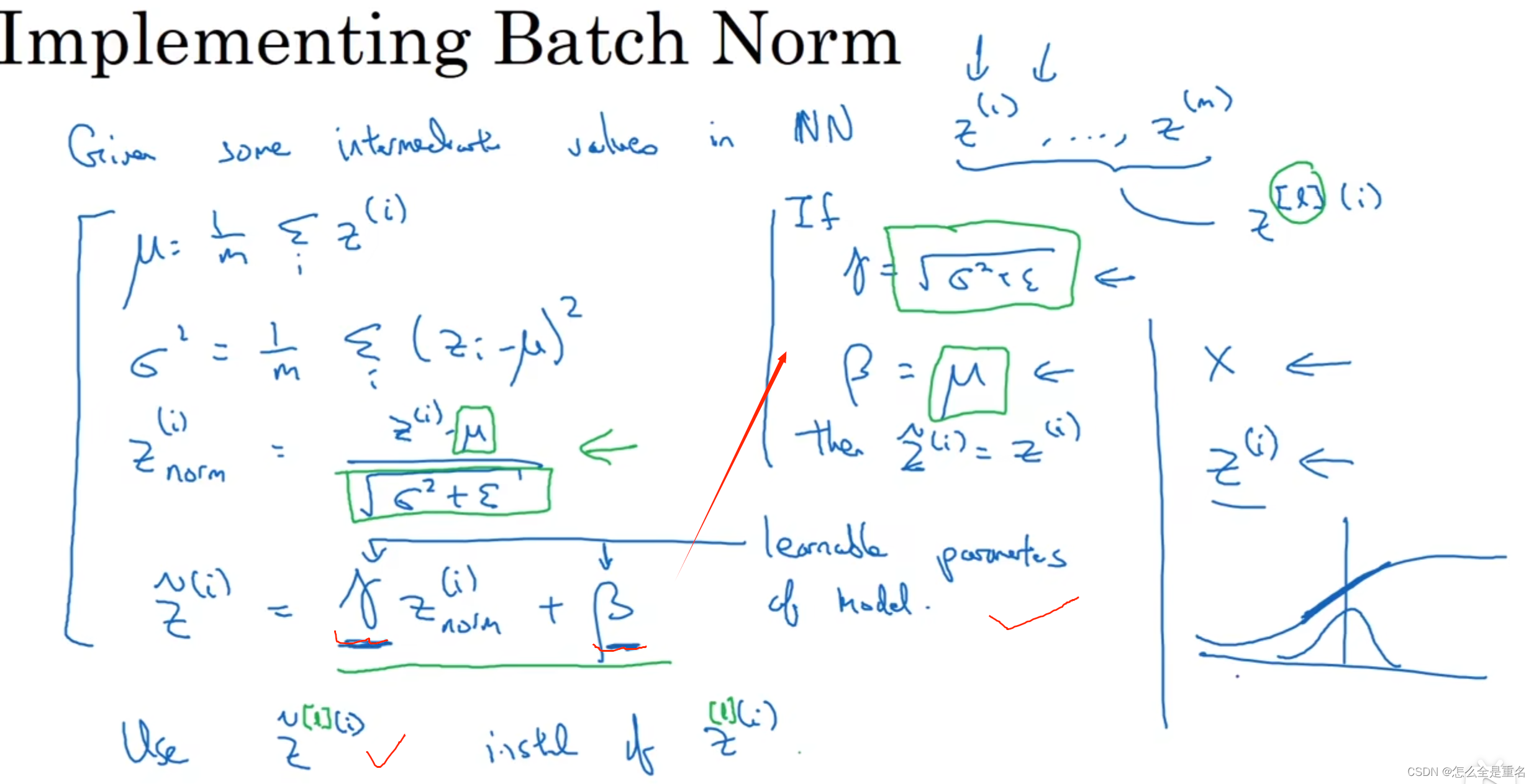
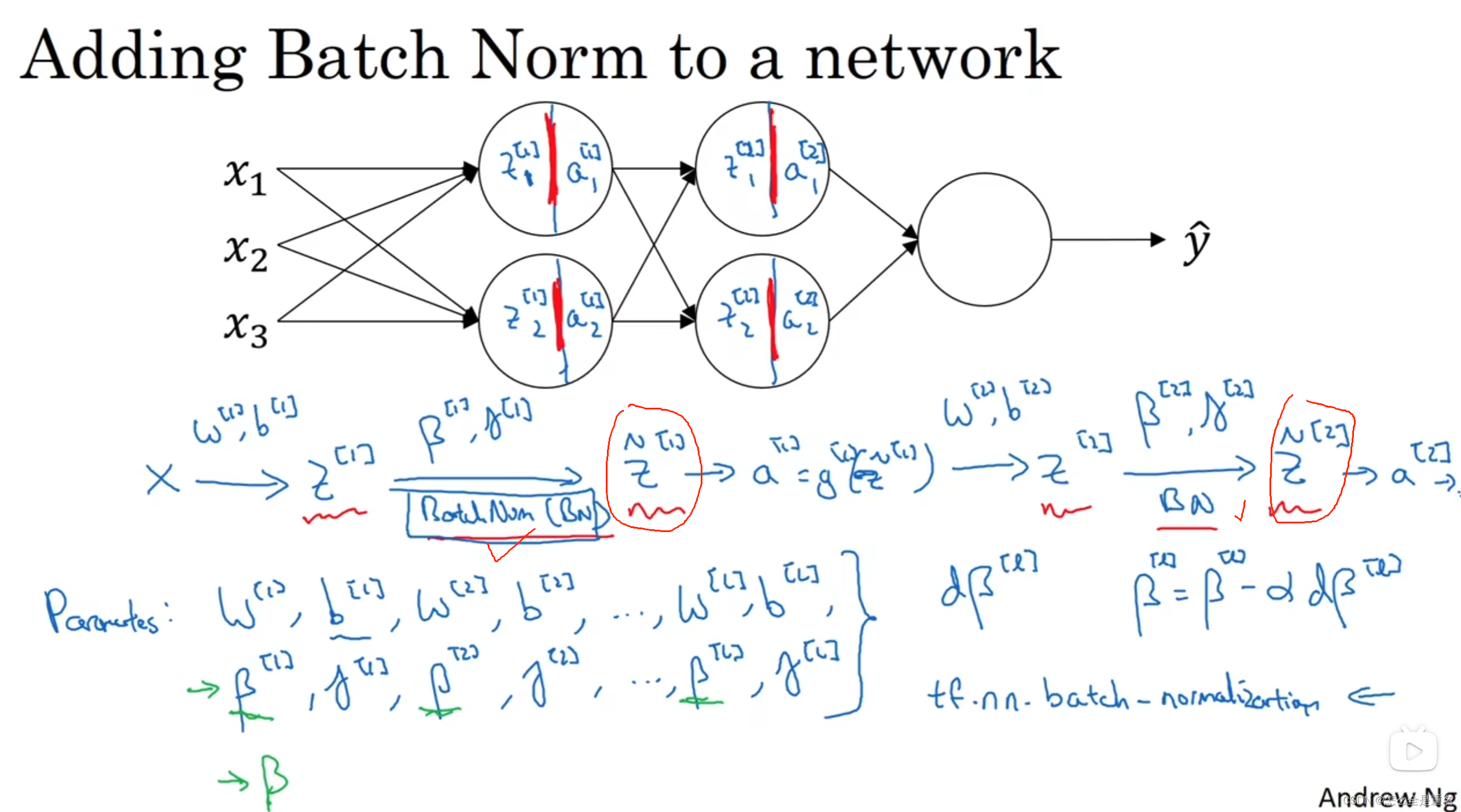
BN不用加b(bias),因为归一化的过程中(均值)会将b给抵消
ex:x - μ —> (x+b) - (μ+b)
BN能起码保证均值为0方差为1,减弱了前层参数和后层参数作用之间的联系
可以避免前面层的参数变化导致激活函数变化过大,进而导致后面层不好学习的情况


BN一次只能处理一个mini-batch数据
BN还有轻微的正则化功能:正则化通过增加噪声防止过拟合,norm通过调整input的分布来降低训练集改变对后面层的影响,但会带来噪音,所以也有轻微正则化作用


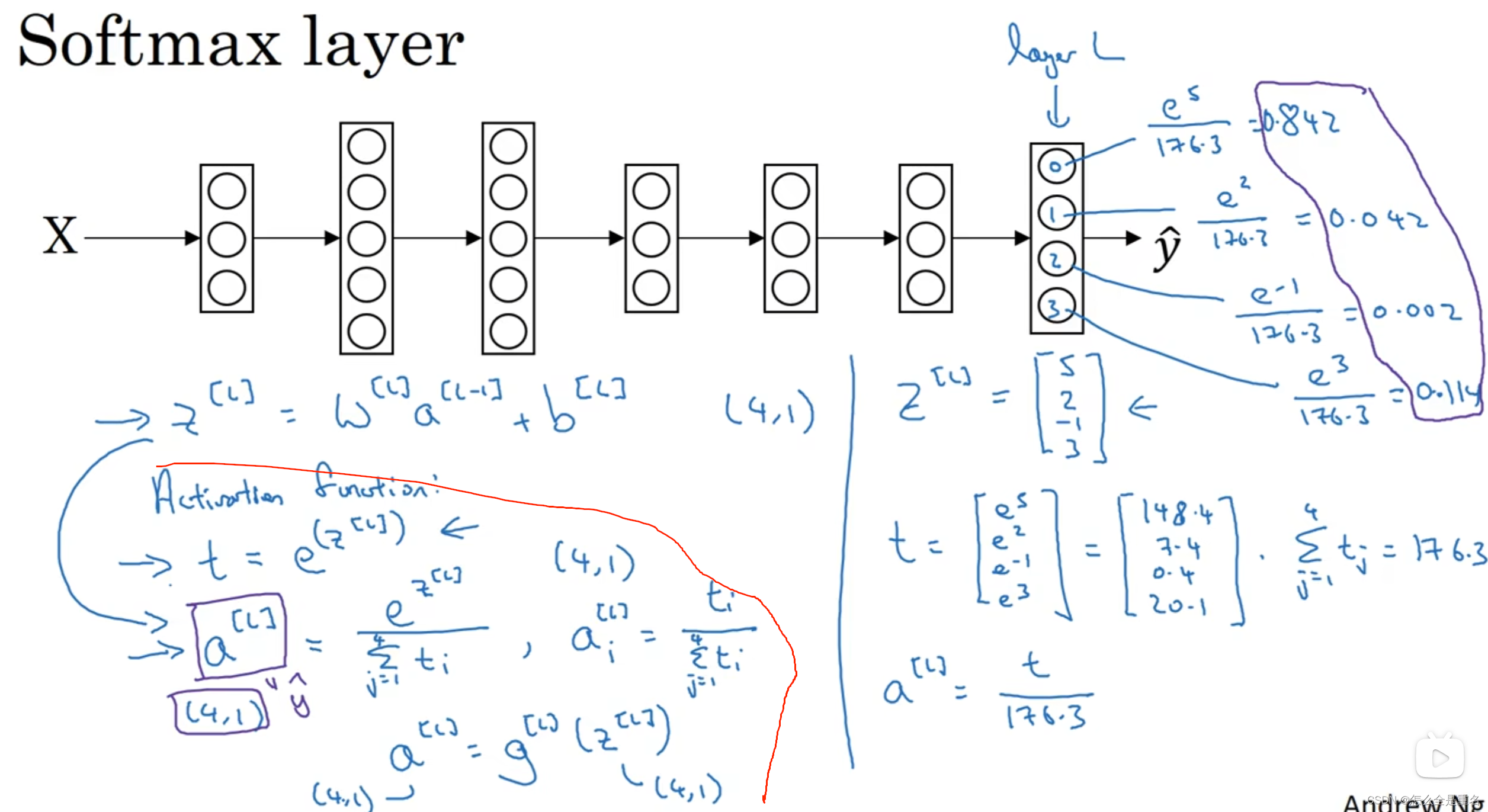
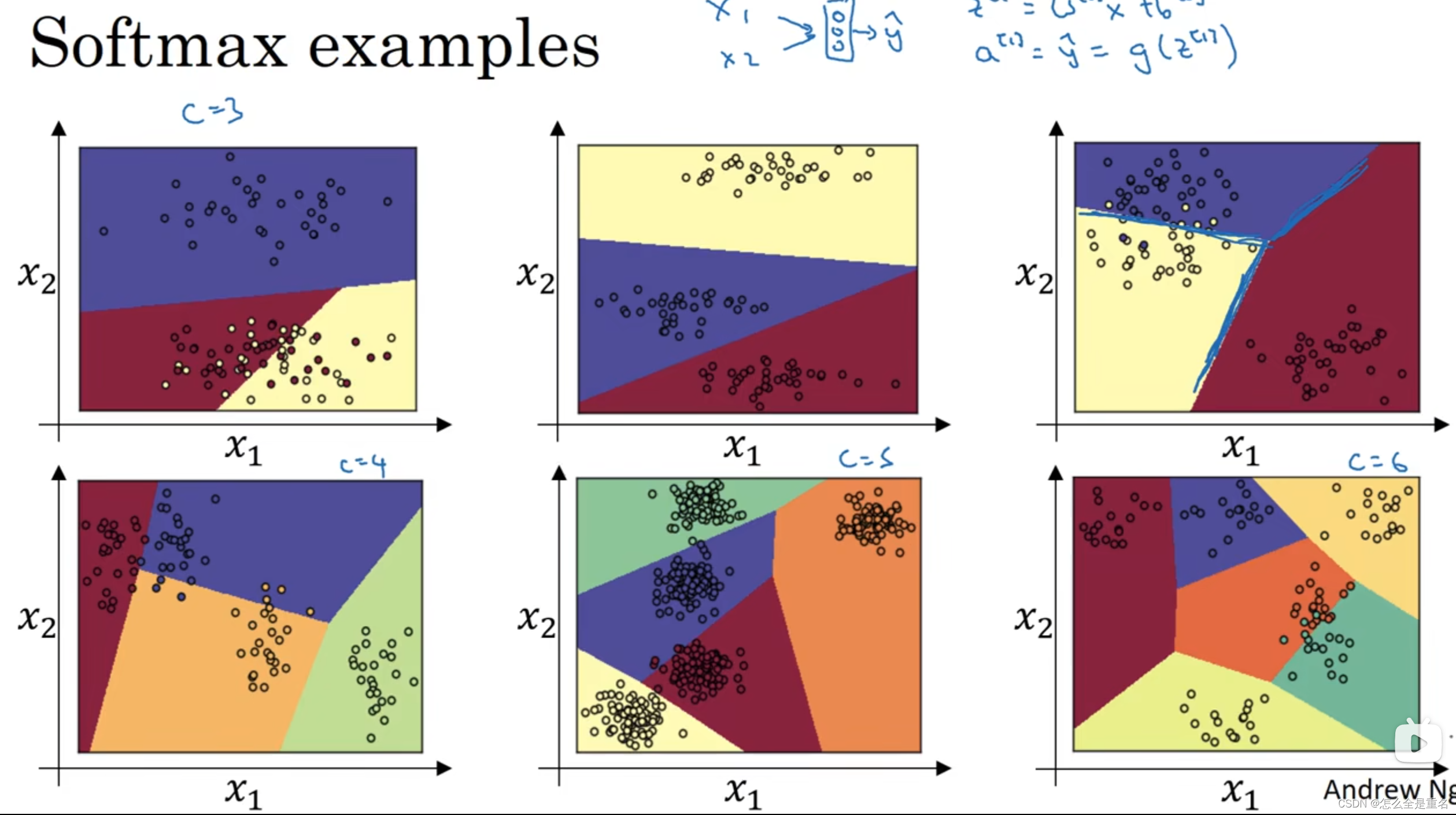
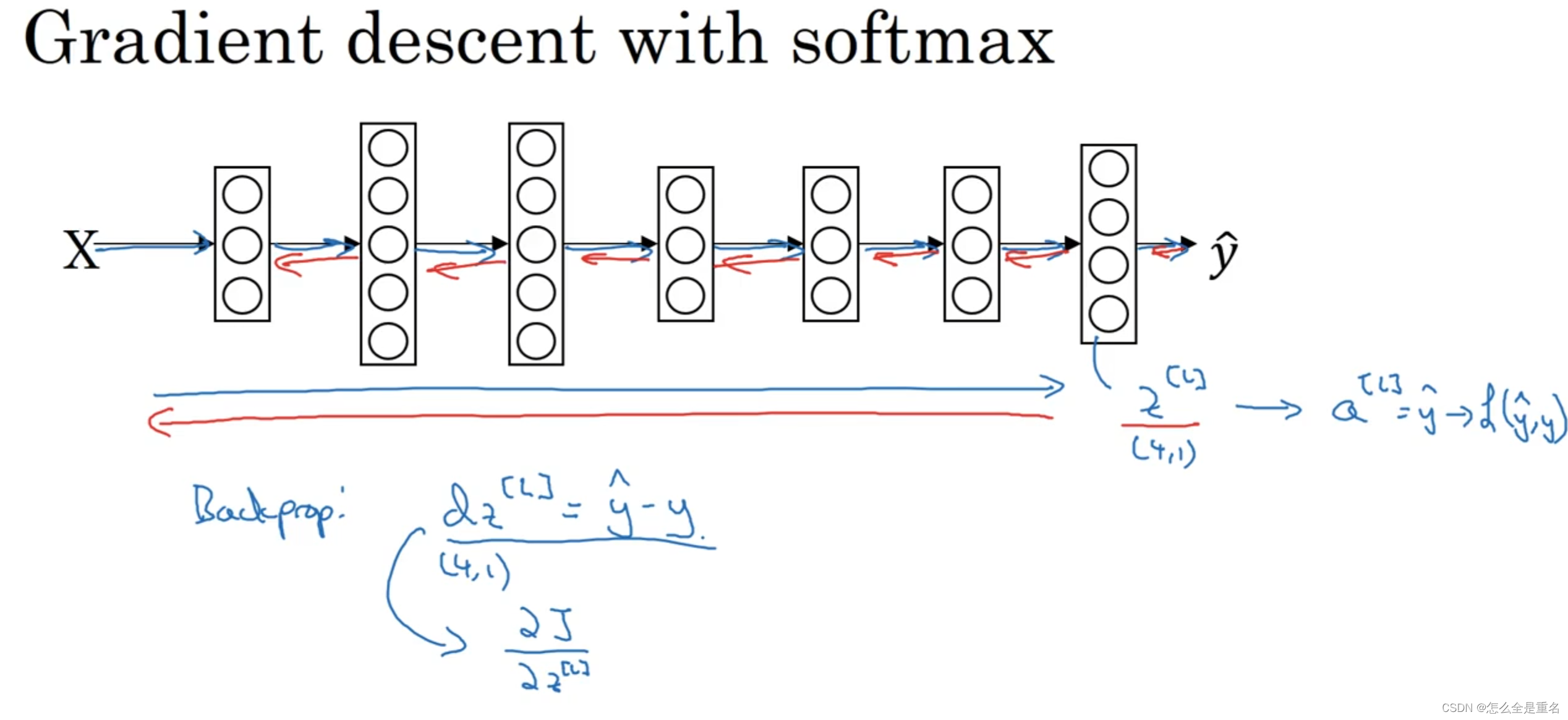
softmax

首先用softmax将logits转换成一个概率分布,然后取概率值最大的作为样本的分类 。softmax的主要作用其实是在计算交叉熵上,将logits转换成一个概率分布后再来计算,然后取概率分布中最大的作为最终的分类结果,这就是将softmax激活函数应用于多分类中
一个输出结果(概率最大)


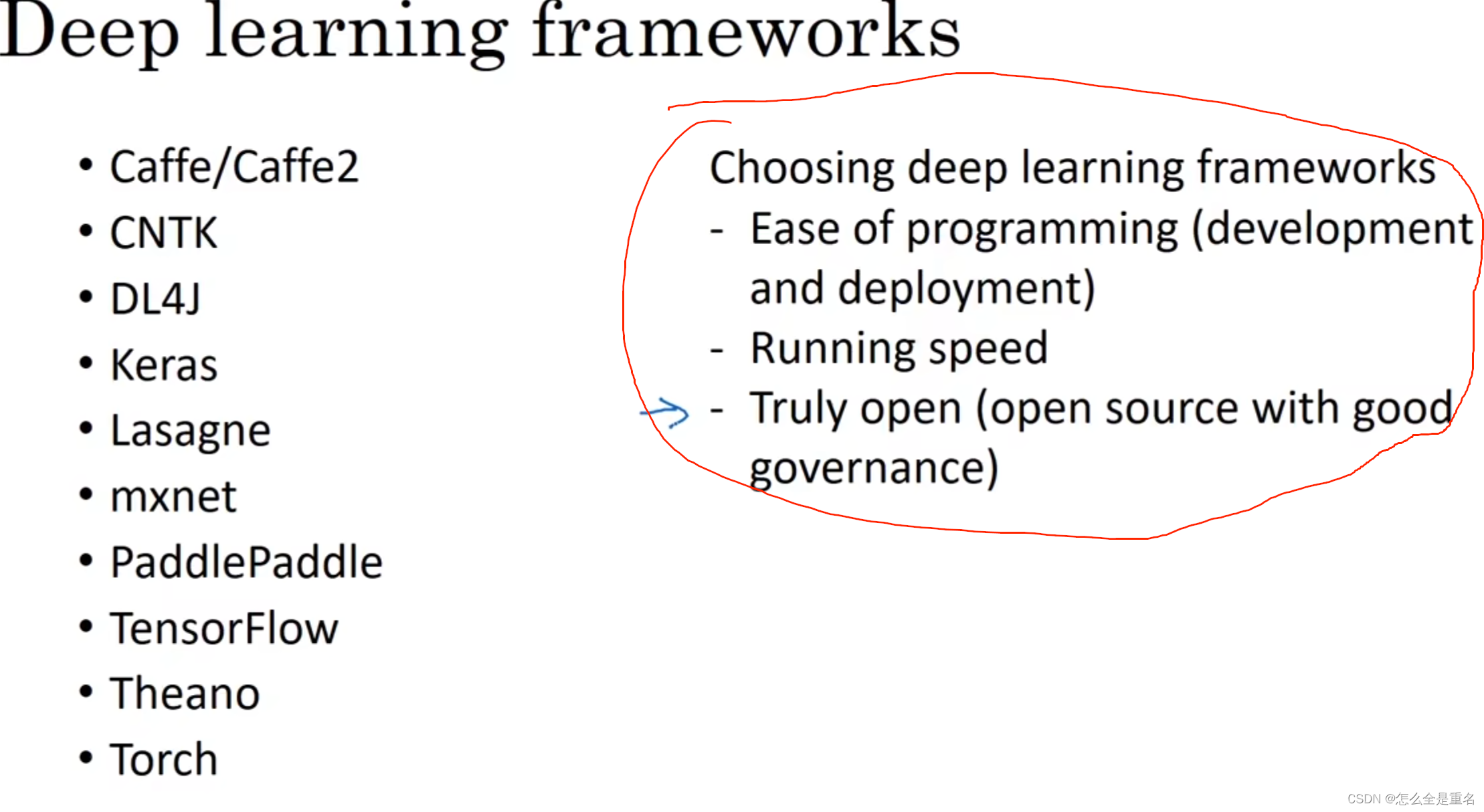
framework

这篇关于Deep Learning(wu--84)调参、正则化、优化--改进深度神经网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






