本文主要是介绍AI助力智慧农业,基于YOLOv3开发构建农田场景下的庄稼作物、田间杂草智能检测识别系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
智慧农业随着数字化信息化浪潮的演变有了新的定义,在前面的系列博文中,我们从一些现实世界里面的所见所想所感进行了很多对应的实践,感兴趣的话可以自行移步阅读即可:
《自建数据集,基于YOLOv7开发构建农田场景下杂草检测识别系统》
《轻量级目标检测模型实战——杂草检测》
《激光除草距离我们实际的农业生活还有多远,结合近期所见所感基于yolov8开发构建田间作物杂草检测识别系统》
《基于yolov5的农作物田间杂草检测识别系统》
自动化的激光除草,是未来大面积农业规划化作物种植生产过程中非常有效的技术手段,本文的核心思想就是想从软件层面来开发构建智能检测识别模型,首先看下实例效果:
这里是基于实验性的想法做的实践项目,数据集由自主构建,主要包含:作物和杂草两类目标对象,在后续的实际开发中,可以根据实际的业务需求来不断地增加和细化对应类别下的数据规模。
简单看下数据集:

本文选择的是yolov3-tiny模型,如下:
# parameters
nc: 2 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# anchors
anchors:- [10,14, 23,27, 37,58] # P4/16- [81,82, 135,169, 344,319] # P5/32# YOLOv3-tiny backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [16, 3, 1]], # 0[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 1-P1/2[-1, 1, Conv, [32, 3, 1]],[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 3-P2/4[-1, 1, Conv, [64, 3, 1]],[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 5-P3/8[-1, 1, Conv, [128, 3, 1]],[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 7-P4/16[-1, 1, Conv, [256, 3, 1]],[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 9-P5/32[-1, 1, Conv, [512, 3, 1]],[-1, 1, nn.ZeroPad2d, [0, 1, 0, 1]], # 11[-1, 1, nn.MaxPool2d, [2, 1, 0]], # 12]# YOLOv3-tiny head
head:[[-1, 1, Conv, [1024, 3, 1]],[-1, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [512, 3, 1]], # 15 (P5/32-large)[-2, 1, Conv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 8], 1, Concat, [1]], # cat backbone P4[-1, 1, Conv, [256, 3, 1]], # 19 (P4/16-medium)[[19, 15], 1, Detect, [nc, anchors]], # Detect(P4, P5)]
train.py对应参数配置如下:
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='./weights/yolov3-tiny.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='./models/yolov3-tiny.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/self.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[416, 416], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--log-imgs', type=int, default=16, help='number of images for W&B logging, max 100')
parser.add_argument('--workers', type=int, default=1, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--name', default='yolov3-tiny', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()终端执行:
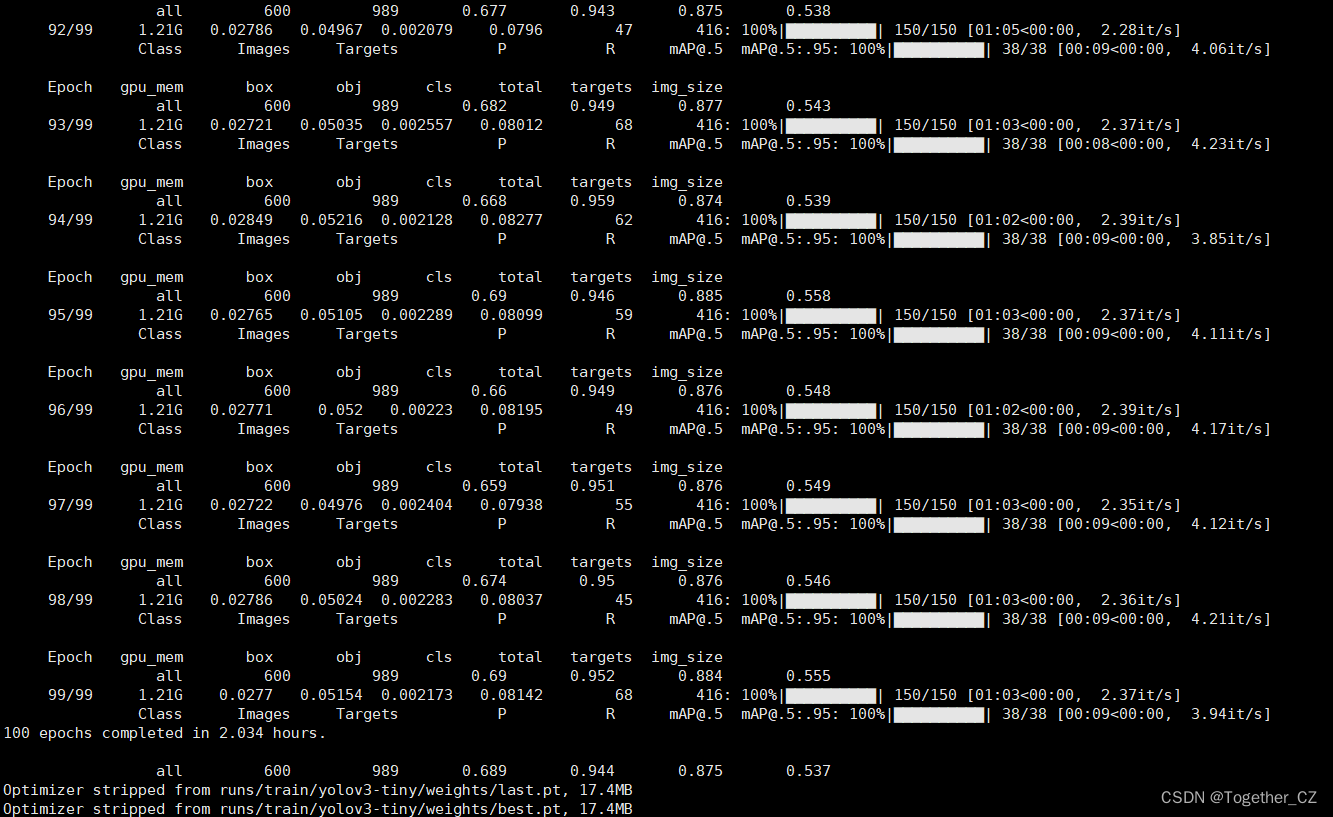
python train.py即可启动训练计算,日志如下所示:
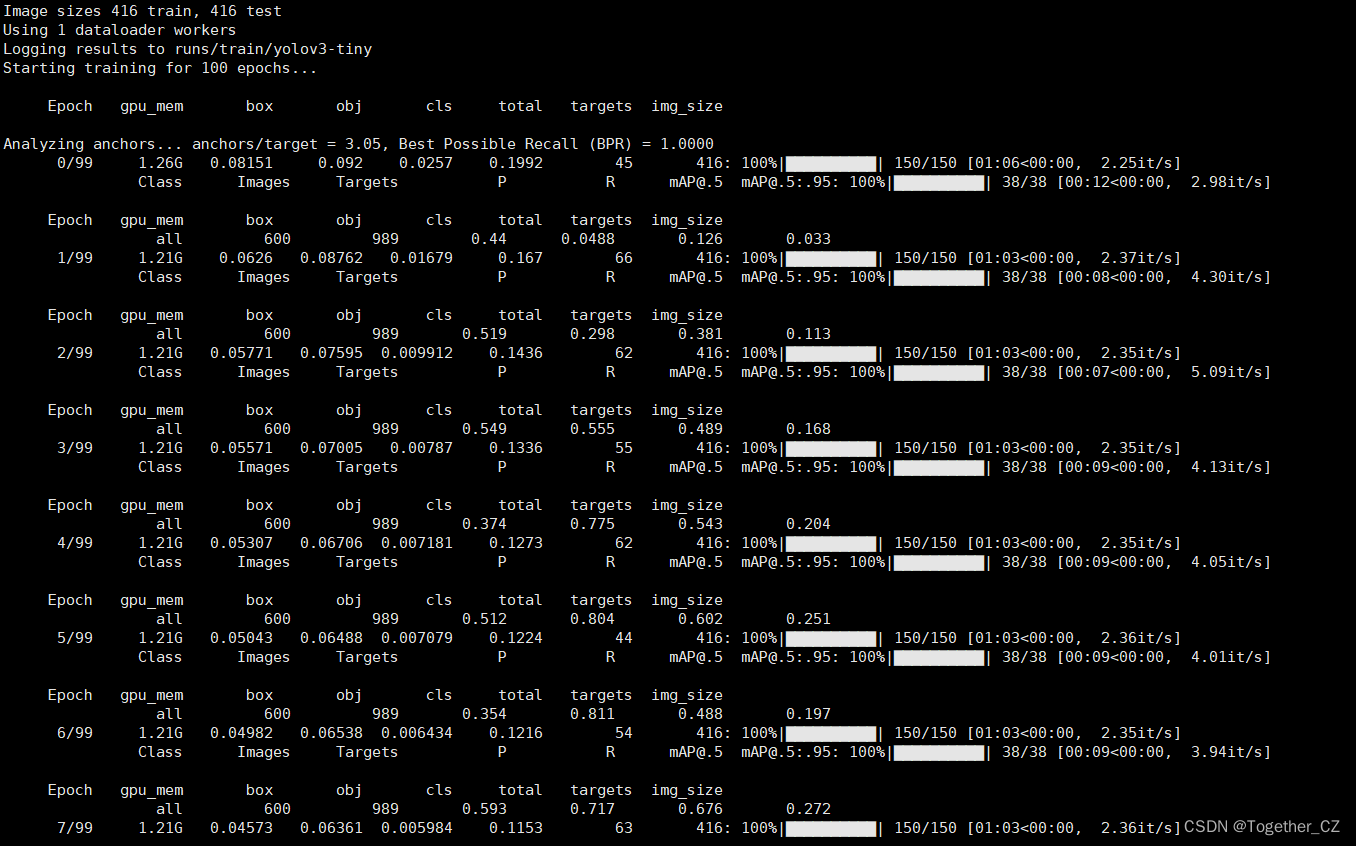
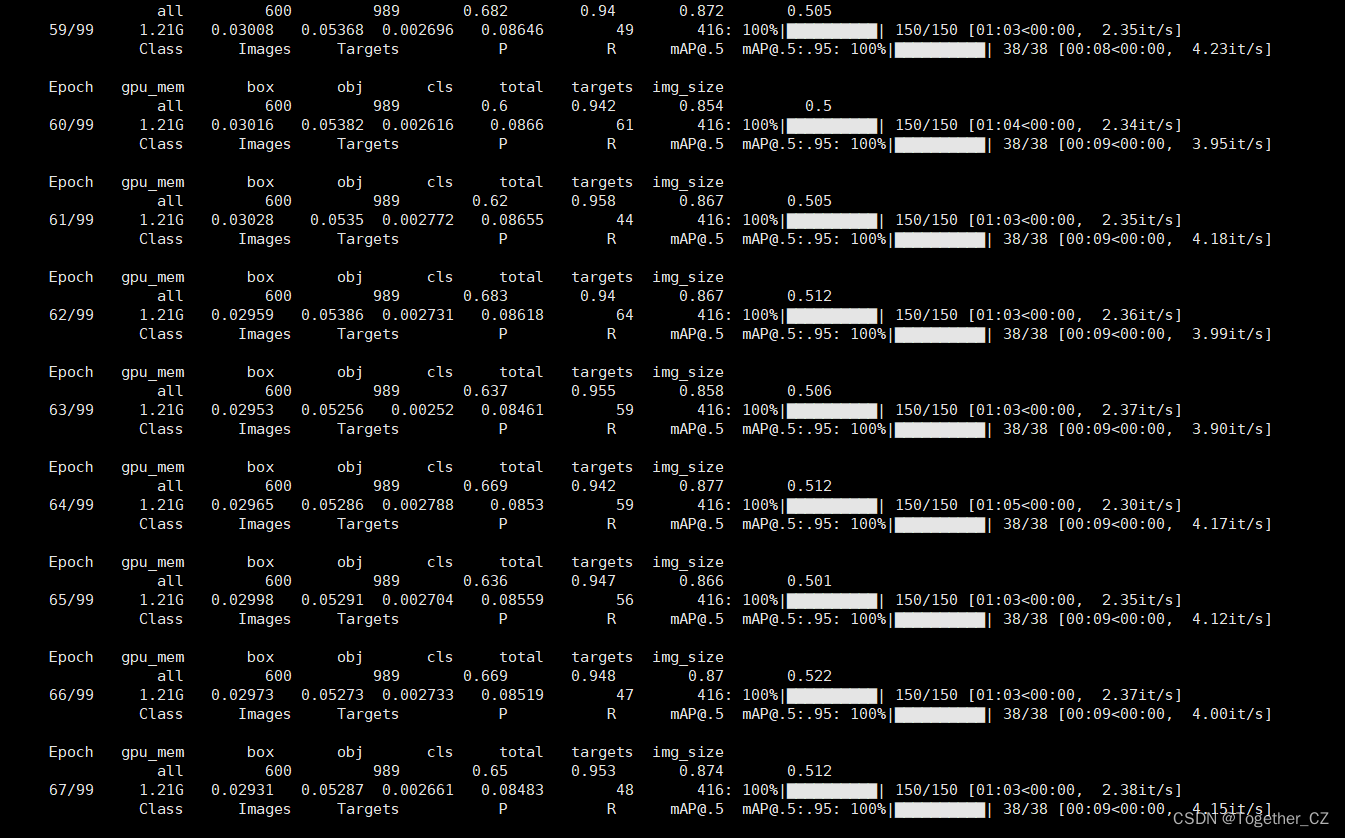
训练完成如下所示:
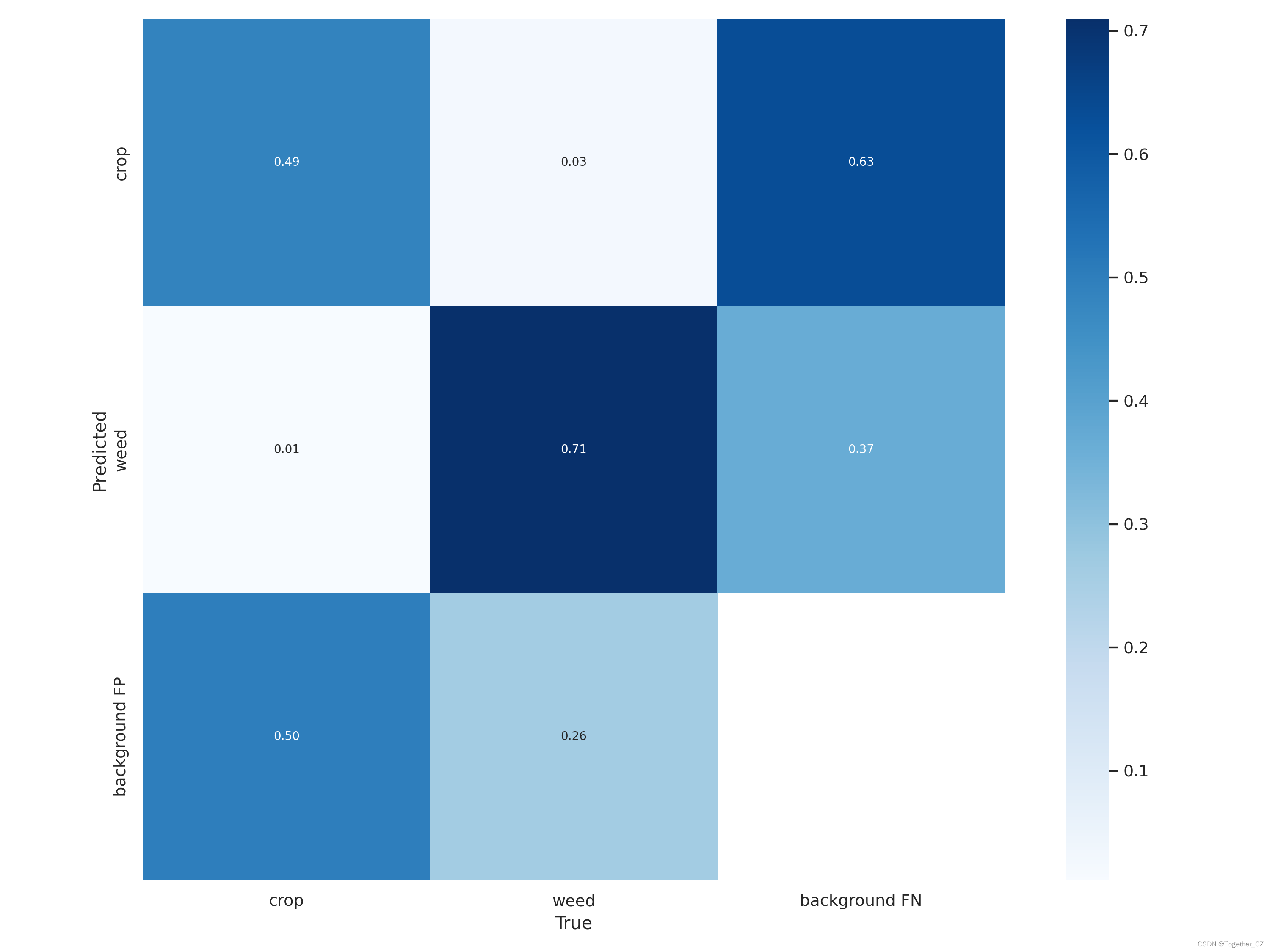
混淆矩阵如下:
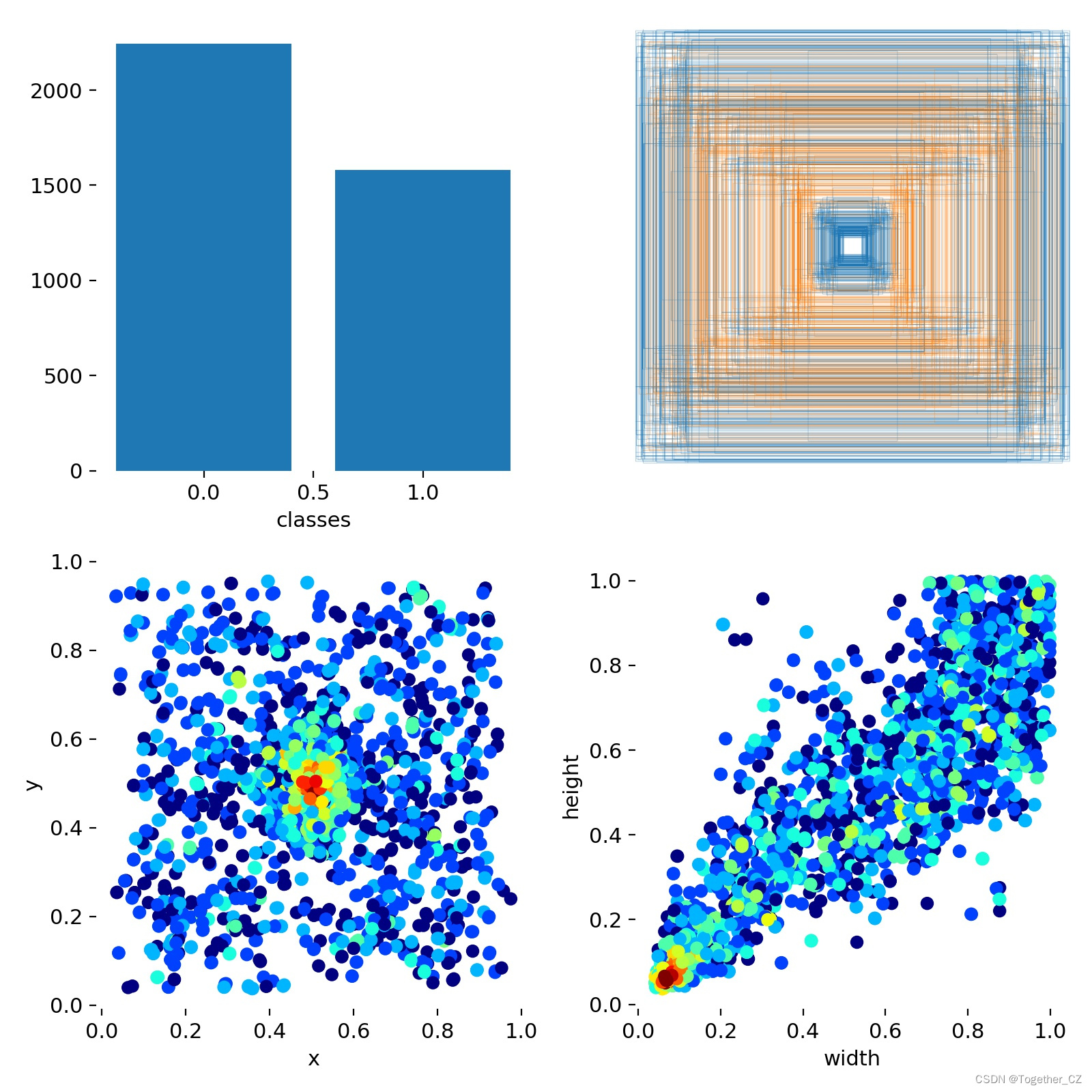
Label数据可视化如下所示:
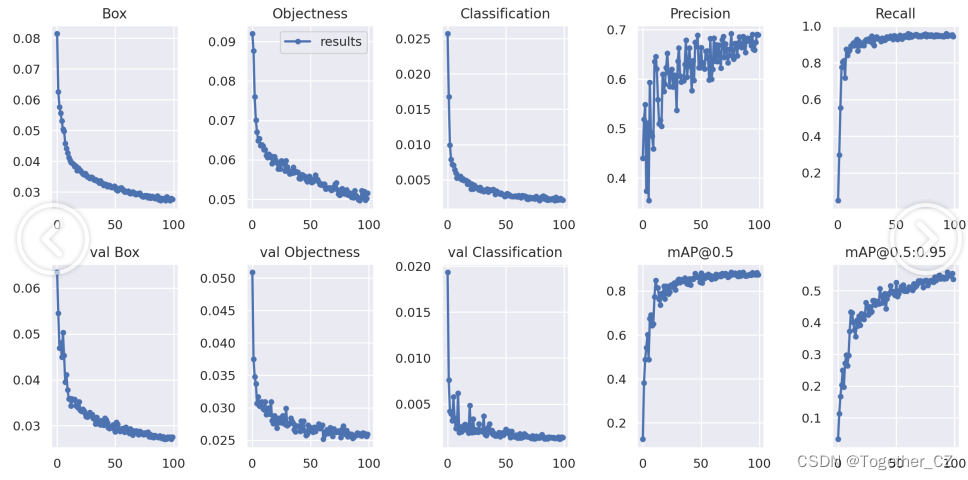
训练过程可视化如下所示:
Batch计算实例如下所示:


PR曲线如下所示:
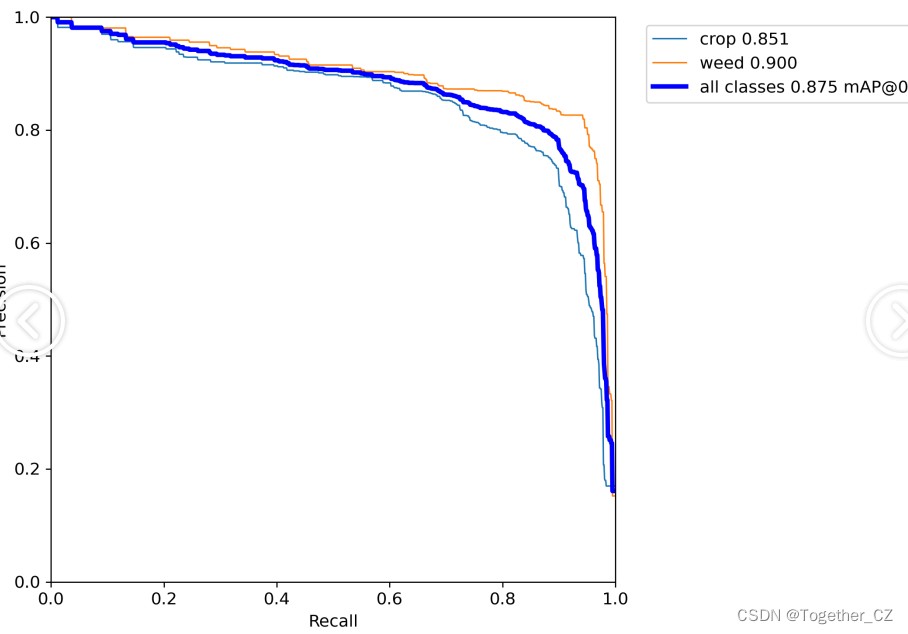
感兴趣的话也都可以自行动手尝试下!
这篇关于AI助力智慧农业,基于YOLOv3开发构建农田场景下的庄稼作物、田间杂草智能检测识别系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






