本文主要是介绍成为AI产品经理——模型稳定性评估(PSI),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、PSI作用
稳定性是指模型性能的稳定程度。
上线前需要进行模型的稳定性评估,是否达到上线标准。
上线后需要进行模型的稳定性的观测,判断模型是否需要迭代。
稳定度指标(population stability index ,PSI)。通过PSI指标,我们可以获得不同样本或者不同时间下同一样本在分数段上的分布的稳定性。
PSI的计算公式为:SUM(实际占比-预期占比)*ln(实际占比/预期占比)。
PSI至少有两组分布结果,一组是预期分布结果,一组是实际分布结果。我们期望的是分布情况不要发生很大的变化。
在一个信用评估的业务中,我们将用户的信用等级分为0-100,分数越高,信用越好,我们让分数60以上的人可以进行贷款,60以下的不能进行贷款业务。
我们将上线前的OOT测试结果的分布情况作为预期,将上线后最近抽取的样本结果作为实际分布,下图是预期分布和实际分布在不同分数段的占比情况。
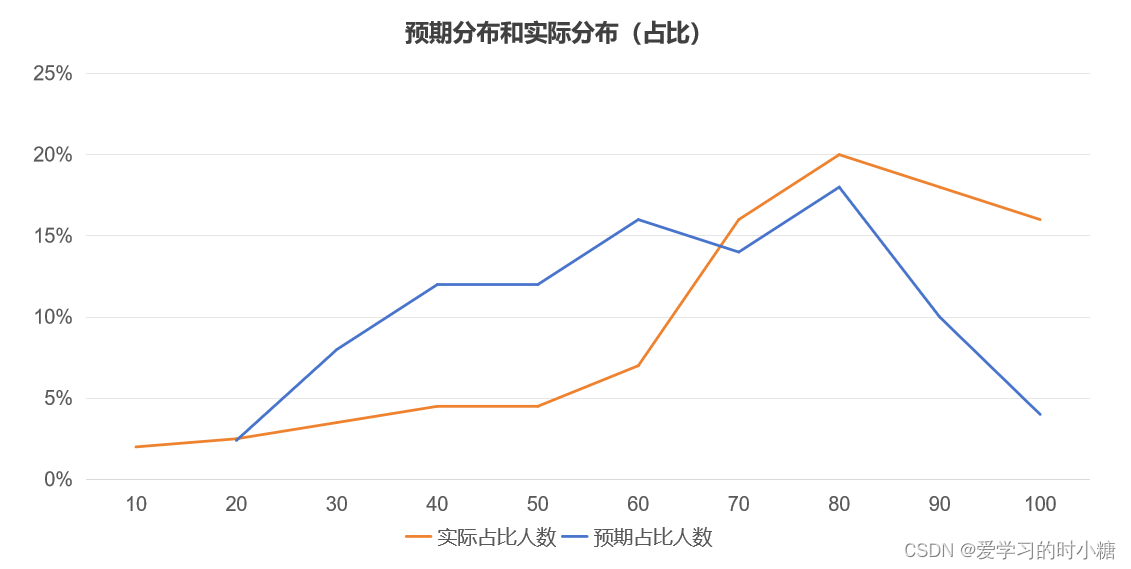
我们可以看出分布占比情况发生了巨大的变化,这对于业务的使用无疑是致命的, 我们可能会使得不能贷款的人员办理了业务,他们有逾期还款的风险,银行会损失很多金钱。
二、PSI的计算
PSI的计算公式为:SUM(实际占比-预期占比)*ln(实际占比/预期占比)。
PSI的计算主要分为三步:
①分箱:等频分箱或等距分箱
②计算实际分布
③计算PSI数值
下面将具体说明这三步:
1.分箱
分箱分为等频分箱和等距分箱。
等频分箱就是令每一个分箱中的样本数量相同。
等距分箱是指每两个区间之间的距离一样多。
数据分箱2——等频、等距分箱_等频分箱法_呆萌的代Ma的博客-CSDN博客
因为我们信用评分模型的稳定性需要看人数分布的波动情况,我们上面案例使用的是等距分箱。
2.计算实际分布
我们已经设置好预期样本,所以只需要计算实际分布。上述案例中我们通过获得近期的用户数据传入模型得到实际的测试结果。然后将测试的结果等距分箱。
3.计算PSI
PSI的计算公式为:SUM(实际占比-预期占比)*ln(实际占比/预期占比)。
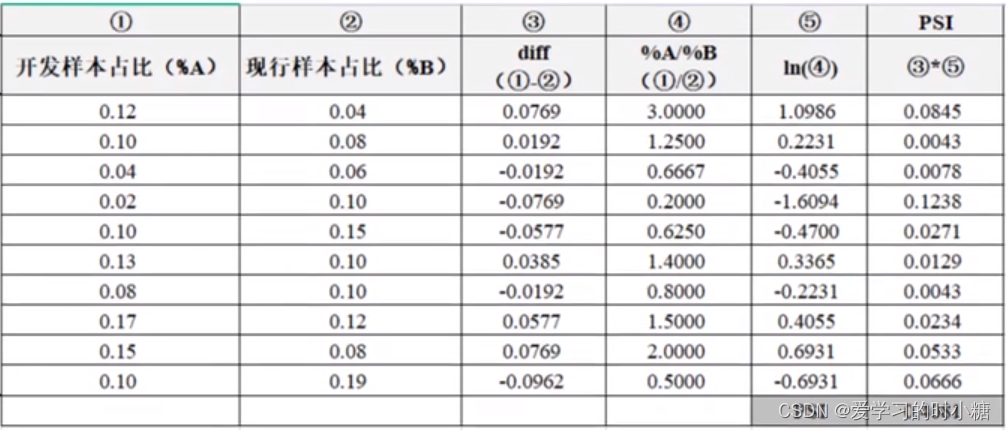
这里有一个例子:我们把开发样本占比看成实际占比,把现行样本占比看作预期样本,具体的计算就是下面这个图。
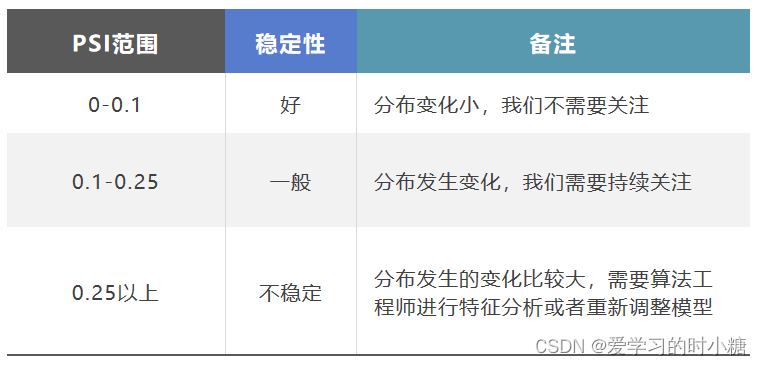
三、PSI范围标准
四、Python计算PSI
import pandas as pd
import numpy as npdef calculate_psi(expected, actual, bins=10):# 离散化数据expected_discrete = pd.cut(expected, bins=bins, labels=False)actual_discrete = pd.cut(actual, bins=bins, labels=False)# 计算每个分箱中的样本数expected_counts = pd.value_counts(expected_discrete)actual_counts = pd.value_counts(actual_discrete)# 计算每个分箱中的占比expected_percentages = expected_counts / len(expected)actual_percentages = actual_counts / len(actual)# 计算 PSIpsi = np.sum((expected_percentages - actual_percentages) * np.log(expected_percentages / actual_percentages))return psi# 示例数据
train_data = np.random.normal(loc=0, scale=1, size=1000)
test_data = np.random.normal(loc=0.2, scale=1, size=1000)# 计算 PSI
psi_value = calculate_psi(train_data, test_data)
print("PSI:", psi_value)
在这个示例中,train_data 和 test_data 是两个数据集,calculate_psi 函数用于计算 PSI。该函数首先将数据进行离散化,然后计算每个分箱的样本占比,最后计算 PSI。
请注意,这只是一个简单的示例,实际应用中可能需要根据数据的特点进行适当的调整。
将数据集导入到 Python 代码中通常使用 Pandas 库,Pandas 提供了灵活且高效的数据结构,特别适用于处理和分析数据。以下是一个简单的示例,演示如何将数据集导入到 Python 代码中:
import pandas as pd# 从CSV文件导入数据集
file_path = 'path/to/your/dataset.csv'
dataset = pd.read_csv(file_path)# 打印数据集的前几行
print(dataset.head())
上述代码假设你的数据集以 CSV 格式存储。如果数据集是以其他格式(例如 Excel、JSON、SQLite 等)存储,Pandas 提供了相应的读取函数,可以根据数据集的格式进行选择。
如果你没有一个实际的数据集,你可以创建一个示例数据集。以下是一个使用 Pandas 创建示例数据集的例子:
import pandas as pd
import numpy as np# 创建一个示例数据集
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],'Age': [25, 30, 35, 40],'Salary': [50000, 60000, 75000, 90000]}dataset = pd.DataFrame(data)# 打印数据集
print(dataset)
五、备注
1.PSI不仅在上线前需要关注,还需要在上线后进行监测,因为有些模型可能会随着时间的推移稳定性变差。
2.影响PSI的因素很多,常见的有数据源变化、用户群体变化等等,后期都需要考虑。
参考文献:刘海丰——《成为AI产品经理》 自用,请勿传播
【评分卡入门教程12】模型评估2-PSI值_哔哩哔哩_bilibili
这篇关于成为AI产品经理——模型稳定性评估(PSI)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








