本文主要是介绍论文解读--Robust lane detection and tracking with Ransac and Kalman filter,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用随机采样一致性和卡尔曼滤波的鲁棒的车道线跟踪
摘要
在之前的一篇论文中,我们描述了一种使用霍夫变换和迭代匹配滤波器的简单的车道检测方法[1]。本文扩展了这项工作,通过结合逆透视映射来创建道路的鸟瞰视图,应用随机样本共识来帮助消除由于道路噪声和伪影造成的异常值,以及一个卡尔曼滤波器来帮助平滑车道跟踪器的输出。
1.介绍
多年来,高速公路上的司机安全一直是人们关注的一个领域。随着快速、廉价、低功耗和精密的电子产品的发展,带有传感器、电子产品和预警系统的汽车开始出现在市场上。
研究和开发的感兴趣的一个领域是避免碰撞。车道检测是有效避免碰撞的一个重要组成部分。当司机正在进入的车道上有故障时,检测突然或意外的车道变化的能力可以帮助司机避免碰撞。有效地监测汽车在车道内的位置,可以帮助避免因司机干扰、疲劳或在受控物质的影响下驾驶而造成的碰撞。避碰系统的设计存在明显的困难和挑战,其中一些挑战超出了工程领域,涉及与法律和责任相关的复杂问题。
在本文中,我们解决了设计一个车道检测系统。它的组织方式如下。在简要回顾了一些以前的研究之后,我们接着描述了该系统的各个组成部分。这些方法包括使用时间模糊的图像预处理,逆投影映射来创建道路的鸟瞰图,一个用于检测候选车道标记的霍夫变换,一个用来帮助处理图像中的异常值的随机样本共识算法,以及使用卡尔曼滤波器跟踪车道参数。然后,我们简要描述了用于收集数据的硬件,然后展示了车道跟踪系统的性能。结果表明,与仅使用霍夫变换和匹配滤波的[1]系统相比,该系统在性能上有了相当大的改进。
2.以前的研究
许多基于视觉的车道检测技术已经被开发出来,试图稳健地检测车道。在车道检测特征的提取中,最常用的方法之一是将边缘检测器应用于数据[2,3]。使用这种方法,Canny边缘检测器通常用于生成二进制边缘映射。从二进制边缘映射中,利用经典的霍夫变换提取一组线作为车道标记的候选线。虽然这种方法通常显示出良好的结果,但检测到的车道往往由于表面不规则或道路上的导航文本标记而倾斜。通过颜色分割来提取车道标记是[4,5]常用的另一种方法。不幸的是,颜色分割对环境光很敏感,需要额外的处理,以避免不良的影响。
大多数用于车道检测的方法直接操作相机捕获的图像,没有任何几何校正或改变相机透视[1,2,4,6]。虽然从相机的角度处理图像允许访问原始数据值,但定义感兴趣的特征的属性可能会很复杂。例如,一个前瞻性相机将捕捉到的图像中没有平行的车道标记,其线宽随着距离相机的距离的变化而变化。这些变化通常需要以不同的方式处理捕获图像的每一行。
上面描述的许多系统在某些驾驶条件下表现良好,通常要求一个特定的假设是有效的。其中一些假设包括存在强烈的车道标记对比,以及道路上没有人工痕迹,如裂缝、箭头或类似的标记。不幸的是,这些假设并不适用于许多高交通流量的城市街道和高速公路。
3.方法
本文将[1]中的分层车道检测方法进行了扩展,(1)使用逆透视映射,(2)应用随机样本共识来帮助消除异常值,(3)使用卡尔曼滤波器进行预测和平滑。在下面的章节中,将描述车道检测系统的各个组件。
3.1.图像增强
捕获的彩色图像经过灰度变换和时间模糊,平均N=连续3帧。这种平滑有助于连接虚线车道标记,形成一个接近连续的线[1]。
3.2.反向透视映射
下一步是对图像执行反向透视映射(IPM)。这种转换用于将捕获的图像从相机视角改变为鸟瞰图,如图1所示。[7, 8, 9].通过这种转换,车道检测现在变成了检测一对平行线的问题,这些平行线通常被一个给定的固定距离分开。此外,这种转换使图像平面中的像素之间能够映射到世界坐标(脚),如图1b所示。保证转换的精度,相机的内参和外参是必须的。

图1:反向透视映射将相机透视图像转换为鸟瞰图像。
3.3.车道候选位置检测
接下来,对IPM图像应用自适应阈值来生成二值图像[1]。然后每个二值图像被分成两部分,每部分可能包含一个车道标记。然后在二值图像上计算低分辨率的霍夫变换,为每半图像[1]找到10条得分最高的线。然后沿着每条线的长度进行采样,如图2中的红色加号所示。为了找到每条线的近似中心,在每条线的每个样本点上应用一个一维匹配滤波器。如[1]所述,匹配滤波器是一个高斯方差,其方差是线宽的函数。由于用IPM创建的鸟瞰视图产生的线的宽度近似恒定,所以一个固定的方差高斯核可以用于匹配的滤波器。经过匹配滤波后,选择每个样本点处相关系数最大的超过预定阈值的像素作为车道标记中心的最佳估计值,如图3中的绿色加号所示。最小阈值有助于忽略假阳性,如裂缝、焦油斑块或车道标记不存在的情况。
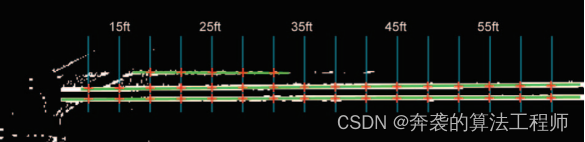
图2:绿线表示从Hough变换中得到的高得分线,加号表示每条线都要被采样的点
3.4.消除异常值和数据建模
一旦每个样本点上的每个候选线的中心被估计出来,随机采样一致性(RANSAC)就被应用于数据点。通用的RANSAC算法通过最可能的数据集或嵌入器稳健地适合一个模型,同时拒绝异常值[10,11]。然后使用线性最小二乘估计(LSE)来拟合到整数上的一条直线。图3用ρ和θ表示拟合线的参数化,其中ρ是从原点(左上角像素)到直线的距离,θ是如图3所示的角度(一般接近90◦)。

图3:通过一组候选点拟合的直线,用ρ和θ参数化
3.5.跟踪
利用卡尔曼滤波器预测了每条线的参数。状态向量x (n)和观测向量y (n)定义为
![]() (1)
(1)
其中,ρ和θ定义了线的方向,˙ρ和θ˙是ρ和θ的导数,它们是利用当前帧和前一帧之间的ρ和θ的差值来估计的。状态转移矩阵A为
 (2)
(2)
而测量方程中的矩阵C是单位矩阵。假设状态和测量方程中的噪声为白色,并假设每个过程与其他过程不相关。因此,这些向量随机过程的协方差矩阵是常数和对角线的。每个噪声过程的方差是离线估计使用的帧,其中准确的车道估计正在产生。在车道标记未被检测到的情况下,矩阵C被设置为零,迫使卡尔曼滤波器纯粹依赖于预测。最后,将估计的线映射回相机的视角,以描绘车道检测结果。
4.实验分析
4.1.硬件
用于测试和评估这种新的车道检测系统的硬件是围绕一个基于英特尔的计算机构建的。在后视镜下方安装了一个面向前方的火线彩色摄像头,这样它就可以清晰地看到前方的道路。视频以VGA分辨率以30帧每秒的速度拍摄。
4.2.结果
车道检测算法是在Matlab中实现的,每帧大约需要0.8秒。表1和表2说明了当前和以前的车道检测系统在应用于超过10小时的捕获视频时的性能。表1中的结果显示,在使用类似的数据集进行测试时,它比[1]中描述的系统的准确性有所提高。由于缺乏对其他车道检测算法和交钥匙软件系统,使得比较结果极其困难。此外,为数据定义基本真相是极其乏味的;因此,通常避免它。因此,检测是定性的,纯粹基于单个用户的视觉检查。我们使用以下规则将结果量化为不同的类别:1)正确的检测发生在超过50%的车道标记估计覆盖在车道标记在现场,2)一个不正确的检测发生在估计覆盖在车道以外的其他标记,和3)错过检测发生时没有估计尽管相关车道标记可见。取左右标记的检出率平均值,得到表中的数字。图4显示了一些正确的车道检测的实例。结果以每分钟的检出率来表示。当使用不同帧率的相机捕获数据时,这个度量允许将结果标准化。
表1 当前车道检测系统的准确性
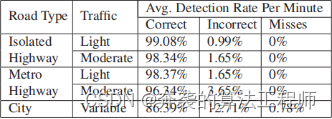
表2 之前的车道检测系统[1]的准确性
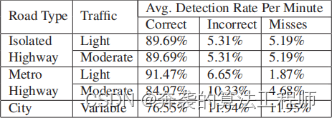

图4:精确车道线检测示例
尽管测量有噪声,卡尔曼滤波器递归地估计状态向量的动态。图5为ρ的观测值与预测值的比较。
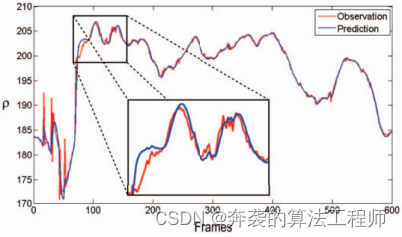
图5:多帧范围内,ρ的观测值和预测值之间的比较。一个爆炸图显示了卡尔曼滤波器平滑噪声测量值。

图6:错误的车道线检测示例
图6中还显示了一些不正确的车道检测的实例。幸运的是,在图6a中,卡尔曼滤波器能够在通过道路上的碰撞后的几毫秒内结束。然而,在图6b中,由于道路老化和磨损而缺少车道标记,导致了对裂缝等虚假信号的检测和跟踪。
5.结论
本文提出的工作是对[1]中提出的分层车道检测系统的一个重大改进。诸如(1)反向透视映射(IPM)、(2)随机采样一致性(RANSAC)和(3)卡尔曼滤波等特征的加入,增加了对以往系统的新颖性和扩展性。IPM有助于简化寻找候选车道标记的过程,而RANSAC有助于排除估计中的异常值。最后,卡尔曼滤波器忽略了较小的扰动,并用跟踪保持车道标记序列。
用于测试拟议系统准确性的数据集被记录在佐治亚州亚特兰大市及其周边地区的高速公路和街道上。尽管遇到的交通条件和道路质量存在变化,但推荐的系统仍具有良好的性能,如表1所示。
6.将来工作
未来将实施车道偏离警告(LDW)。它将利用车道检测系统的能力来准确地确定到车道标记的距离,如图4所示。此外,所实现的算法将被移植到c#和C++中,以方便建立一个实时系统。未来的数据集还将包括地面真实信息,以允许精确的误差计算。其他用户还将进行目视检查。最后,通过计算N作为车辆速度的函数,使图像增强阶段自适应。
这篇关于论文解读--Robust lane detection and tracking with Ransac and Kalman filter的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




