本文主要是介绍【论文阅读】ICRA: An Intelligent Clustering Routing Approach for UAV Ad Hoc Networks,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 论文基本信息
- 摘要
- 1.引言
- 2.相关工作
- 3.PROPOSED SCHEME
- 4.实验和讨论
- 5.总结
- 补充
论文基本信息
《ICRA: An Intelligent Clustering Routing Approach for UAV Ad Hoc Networks》
《ICRA:无人机自组织网络的智能聚类路由方法》
Published in: IEEE Transactions on Intelligent Transportation Systems ( Volume: 24, Issue: 2, February 2023)

摘要
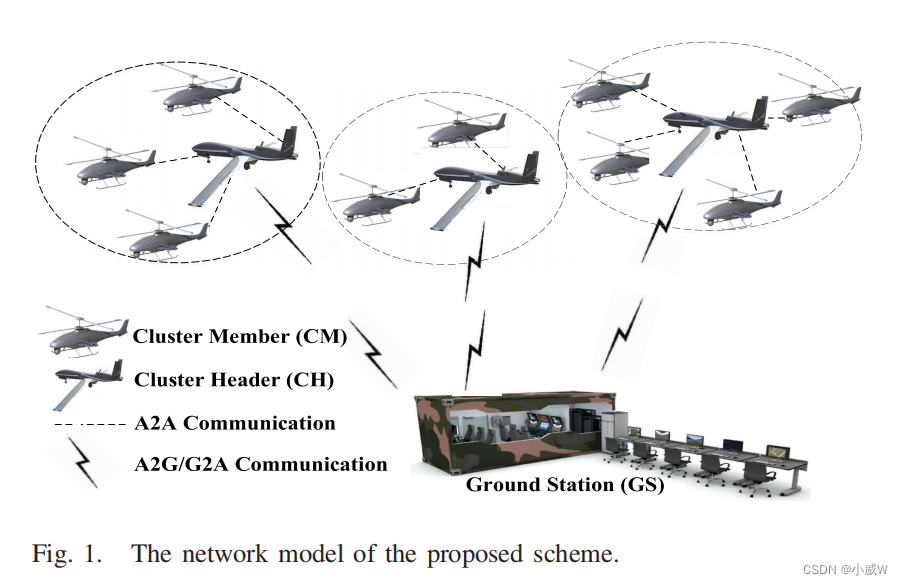
依赖无人机的海洋监测系统作为获取海洋形势信息的重要手段,越来越受到世界各国的关注,对任务的需求不断增长。在无人机自组网中,由于复杂和快速变化的环境情况和应用需求,具有缺乏灵活性的具有不可变路由策略的路由协议通常无法保持有效的性能。在本文中,我们提出了一种针对uanet的智能聚类路由方法(ICRA)。ICRA由集群模块、集群策略调整模块和路由模块三个组成部分组成。在集群过程中,每个节点都需要计算其效用。为了在不同的网络状态下保持高拓扑稳定性和长网络寿命,基于强化学习的聚类策略调整模块需要持续学习采用不同策略计算节点效用带来的好处。利用学习到的知识,聚类策略调整模块可以根据当前的网络状态确定最优的聚类策略。在路由阶段,该方案通过引入集群间转发节点在不同集群之间转发消息,可以减少端到端延迟,提高数据包传递率。大量的实验验证了ICRA的鲁棒性和优越性。结果表明,ICRA在聚类效率、拓扑稳定性、能源效率和服务质量等方面都具有比现有的同类产品更好的性能。
1.引言
2.相关工作
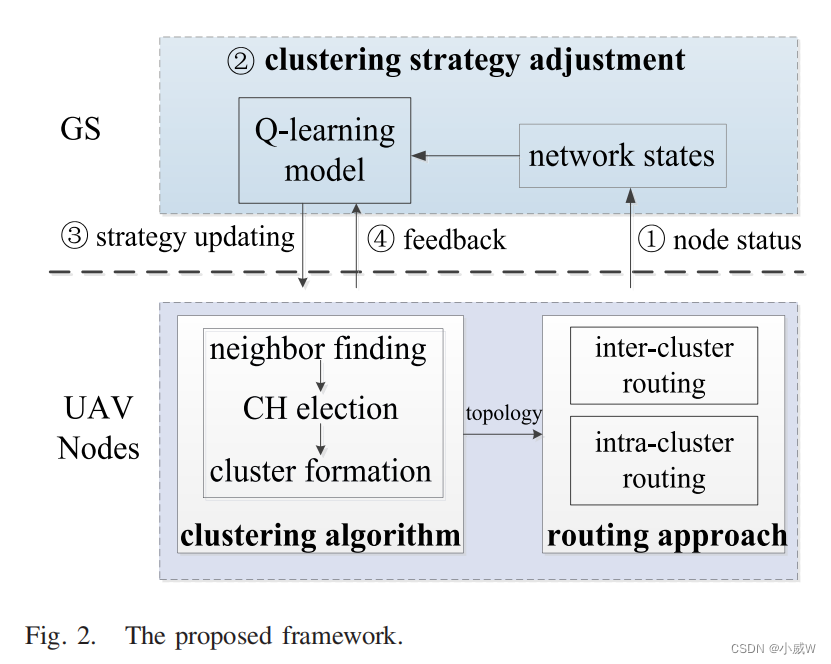
3.PROPOSED SCHEME
4.实验和讨论
5.总结
在本文中,我们提出了一种使用强化学习模型的uanet智能路由协议。整个协议由一个聚类过程和一个路由过程组成。在聚类过程中,我们测量每个节点选择CH的效用,这是四个效用因子的加权和。通过使用强化学习模型,可以随着网络状态的变化而调整四个效用因子的权重,从而保持稳定的网络拓扑结构。对于路由过程,我们给出了基于网络拓扑结构的簇内路由和簇间路由方法。为了验证我们的方法的性能,我们将我们的方法与其他两种现有方案在聚类效率、拓扑稳定性、能源效率和服务质量方面进行了比较。结果表明,该方案完成聚类过程所花费的时间较少。对于其他措施,我们的方案也取得了更好的性能相比,它的最先进的同行。
在未来,我们将考虑在集群过程中传输的消息的安全性。由于路由安全的工作主要是路由过程的安全性,而如果集群数据包被对手篡改,网络拓扑可能会遭受严重的正面偏差,这将导致不稳定和低效的路由过程。
补充
这篇关于【论文阅读】ICRA: An Intelligent Clustering Routing Approach for UAV Ad Hoc Networks的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









