本文主要是介绍NLP自然语言处理——关键词提取之 TF-IDF 算法(五分钟带你深刻领悟TF-IDF算法的精髓),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

🔥博客主页:真的睡不醒
🚀系列专栏:深度学习环境搭建、环境配置问题解决、自然语言处理、语音信号处理、项目开发
💘每日语录:要有最朴素的生活和最遥远🌏的梦想,即使明天天寒地冻,山高水远,路远马亡。
🎉感谢大家点赞👍收藏⭐指证✍️

前言
关键词提取是将文本中的关键信息、核心概念或重要主题抽取出来的过程。这些关键词可以帮助人们快速理解文本的主题,构建文本摘要,提高搜索引擎的效率,甚至用于文本分类和信息检索等应用领域。因此,关键词提取在文本分析和自然语言处理中具有广泛的应用前景。本文主要包括以下几个内容:
- 自然语言文本预处理
- TF-IDF算法详解(三个维度:原理、流程图、代码)
- 好玩的中文关键词词云生成(解决乱码问题)
本博客将深入探讨自然语言处理中常用的TF-IDF算法,以多种方式展现TF-IDF算法的核心思想。
准备工作
- 本文的代码是通过python实现的,建议安装一个pycharm,非常方便!
- 停用词表(提取码:peng):百度网盘 请输入提取码
- 文本文档(提取码:peng):百度网盘 请输入提取码
- 库函数 jieba、sklearn、matplotlib以及生词词云用到的wordcloud
以上的库函数都可以通过pip安装。
pip install 库函数名字自然语言文本预处理
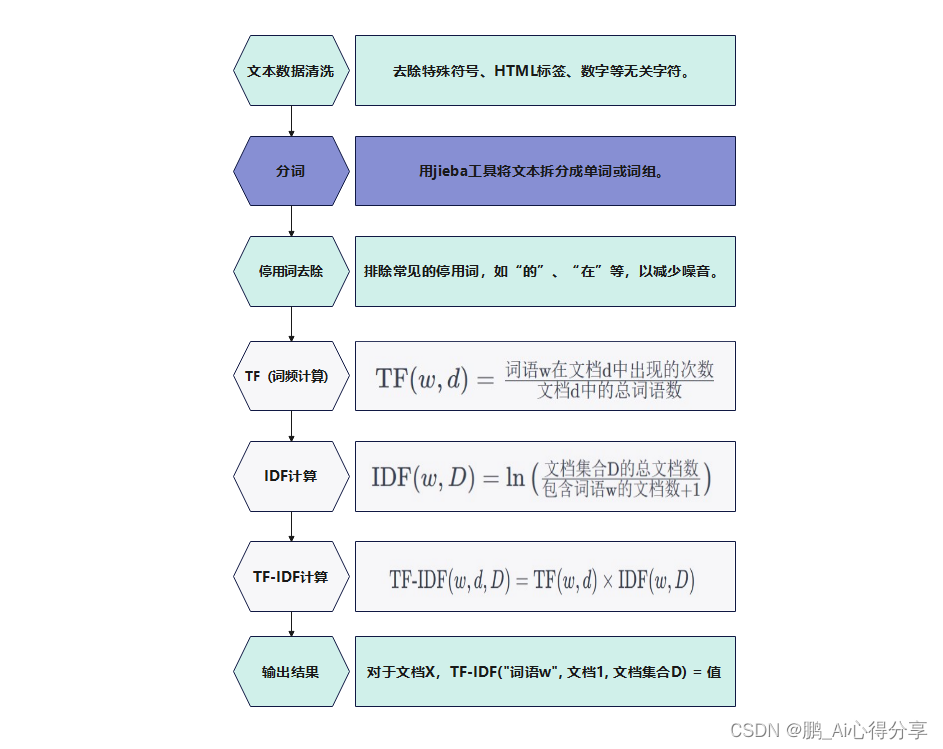
一般情况下我们拿到的文本是不规范的,需要我们进行一系列的预处理操作。
- 文本数据清洗:去除特殊符号、HTML标签、数字等无关字符。
- 分词:将文本拆分成单词或词组。
- 停用词去除:排除常见的停用词,如“的”、“在”等,以减少噪音。
停用词获取
在前边的准备工作中,你已经获得了停用词表,通过以下代码提取停用词。
# 获取停用词
def load_stopwords(stopwords_file):stopwords = set()with open(stopwords_file, 'r', encoding='utf-8') as f:for line in f:stopwords.add(line.strip())return stopwords 在这里提一嘴,在编程中,set 是一种数据结构,它类似于列表(list)或字符串(string),但具有一些不同的特点。
- 列表(list)是一种有序的数据结构,可以包含多个元素,每个元素可以是不同类型的数据(例如数字、字符串、其他列表等)。列表中的元素可以重复。
- 字符串(string)是一种有序的字符序列,通常用于表示文本。字符串的每个字符都有一个索引位置。
set是一种无序的集合数据结构,它用于存储不重复的元素。集合中的元素不按顺序排列,并且每个元素在集合中只能出现一次。集合通常用于存储一组唯一的值。
数据清洗
# 加载文档集,对文档集过滤词性和停用词
def filter_documents(data_path, stopwords):documents = []with open(data_path, 'r', encoding='utf-8') as f:for line in f:document = []words = pseg.cut(line.strip())for word, flag in words:if flag.startswith('n') and word not in stopwords and len(word) > 1:document.append(word)documents.append(document)return documents
通过这一步,我们就得到一个包含精确分词、词性过滤和停用词去除的文本数据。
预处理完成,接下来就是算法详解和实现。
TF-IDF算法
TF-IDF(词频-逆文档频率)是一种用于衡量文本中词语重要性的方法,特别适用于信息检索和文本挖掘任务。下面我将深入讲解TF-IDF的计算过程,以便更好地理解。
TF-IDF的计算过程可以分为两个主要部分:词频(TF)和逆文档频率(IDF)。
1. 词频(TF - Term Frequency):
词频是指某个词语在文档中出现的频率。TF表示了一个词语在文档中的重要性,通常通过以下公式计算:

标准公式:
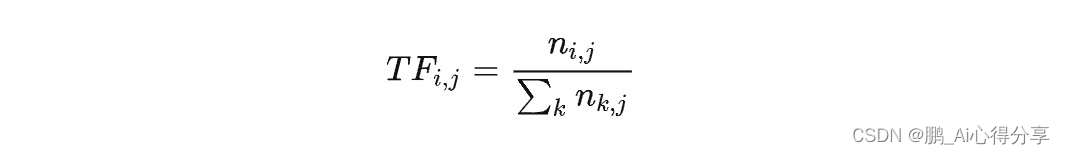
其中:
- w 是要计算TF的词语。
- d 是包含词语的文档。
- 分子是词语在文档中的出现次数。
- 分母是文档中的总词语数。
计算出的TF值表示了词语在单个文档中的相对重要性,值越大表示词语在文档中越重要。
2. 逆文档频率(IDF - Inverse Document Frequency):
逆文档频率度量了一个词语在整个文档集合中的重要性。IDF值越大,表示词语在整个文档集合中越不常见,因此在文档中的重要性越高。IDF通常通过以下公式计算:
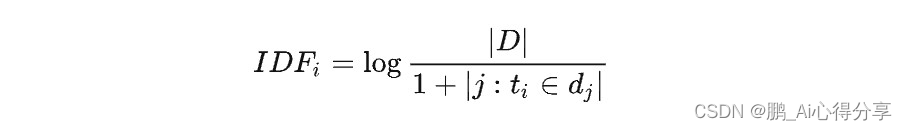
可理解为

其中:
- w 是要计算IDF的词语。
- D 是文档集合。
- 分子是文档集合中的总文档数。
- 分母是包含词语 w 的文档数,+1 是为了避免分母为零的情况。
计算出的IDF值反映了词语的全局重要性,较不常见的词语具有较高的IDF值。
3. TF-IDF的计算:
TF-IDF的计算是将词频(TF)和逆文档频率(IDF)相结合,以确定词语在文档中的整体重要性。计算公式如下:
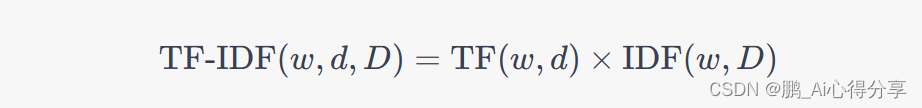
其中:
- w 是要计算TF-IDF的词语。
- d 是包含词语的文档。
- D 是文档集合。
计算出的TF-IDF值表示了词语在文档 d 中的重要性,同时考虑了在整个文档集合 D 中的全局重要性。
TF-IDF算法实例讲解
假设我们有一个包含多篇文档的文本集合,其中包括以下两篇文档:
文档1:
自然语言处理(NLP)是一门研究人与计算机之间用自然语言进行有效通信的领域。NLP的目标是使计算机能够理解、解释和生成自然语言文本。
文档2:
TF-IDF是一种常用于文本挖掘和信息检索的算法。它用于衡量文档中词语的重要性,通过词频(TF)和逆文档频率(IDF)的计算来实现。
计算步骤:
-
词频(TF)计算:
- 对于文档1,词语 "自然语言处理" 在文档中出现的次数是1,文档1的总词语数为16。因此,TF("自然语言处理", 文档1) = 1/16 = 0.0625。
- 对于文档2,词语 "自然语言处理" 在文档中没有出现,因此,TF("自然语言处理", 文档2) = 0。
-
逆文档频率(IDF)计算:
- 假设文档集合中总共有100篇文档,其中包含词语 "自然语言处理" 的文档数为10篇。那么,IDF("自然语言处理", 文档集合) = ln(100 / (10 + 1)) ≈ 2.1972。
-
TF-IDF计算:
- 对于文档1,TF-IDF("自然语言处理", 文档1, 文档集合) = 0.0625 * 2.1972 ≈ 0.1373。
- 对于文档2,TF-IDF("自然语言处理", 文档2, 文档集合) = 0 * 2.1972 = 0。
通过这个例子,我们可以看到词语 "自然语言处理" 在文档1中的TF-IDF值较高,因为它在文档1中出现,并且相对较少地出现在整个文档集合中。在文档2中,由于该词语未出现,其TF-IDF值为零。这样,我们可以使用TF-IDF值来衡量词语在文档集合中的重要性。
TF-IDF算法流程图展示
TF-IDF 算法代码
这里是直接调用了TfidfVectorizer(),简单方便。
# 使用TF-IDF提取关键词
def extract_keywords_tfidf(documents, top_n=20):# 将过滤后的文档集转化为文本列表documents_text = [' '.join(document) for document in documents]# 创建TF-IDF向量化器tfidf_vectorizer = TfidfVectorizer()# 计算TF-IDF权重tfidf_matrix = tfidf_vectorizer.fit_transform(documents_text)# 获取特征词列表features = tfidf_vectorizer.get_feature_names_out()# 计算每个文档中的关键词top_keywords_per_document = []for doc_id in range(len(documents)):document_tfidf_weights = tfidf_matrix[doc_id].toarray()[0]top_keyword_indices = document_tfidf_weights.argsort()[-top_n:][::-1]top_keywords = [features[idx] for idx in top_keyword_indices]top_keywords_per_document.append(top_keywords)return top_keywords_per_document词云生成
当我们获得了文本关键词后,总不能还是打印输出吧?为了更加直观地展示它们,这里选择使用词云(Word Cloud)的形式进行展示。
首先确保我们已经安装了wordcloud。
pip install wordcloud为了避免乱码这里建议下载中文字体,这里我直接分享给大家。
(提取码:peng)百度网盘 请输入提取码
附上代码:
def generate_wordcloud(keywords, title):"""生成词云图并显示参数:keywords (list): 包含关键词的列表。title (str): 词云图的标题。返回:None"""# 将关键词列表转化为字符串keywords_str = ' '.join(keywords)# 指定中文字体文件路径(根据实际情况替换为合适的路径)font_path = r'D:\my_homework\NLP_homework\NLP_test1\SimHei.ttf' # 替换为包含中文字符的字体文件路径# 创建词云对象并指定字体wordcloud = WordCloud(width=800, height=400, background_color='white', font_path=font_path).generate(keywords_str)# 显示词云图plt.figure(figsize=(10, 5))plt.imshow(wordcloud, interpolation='bilinear')plt.axis('off')plt.title(f'wordcloud - {title}')plt.show()
效果展示:

结语
总的来说,关键词提取是自然语言处理中的一项核心任务,它为我们处理文本数据、挖掘文本信息提供了有力的工具和方法。希望本篇博客能够帮助读者更好地理解关键词提取的基本原理和应用,从而在实际项目中更加灵活和高效地处理文本数据。如果你对关键词提取有更深入的兴趣,也可以进一步研究更多高级的关键词提取算法和技术。感谢阅读!
本人目前正在学习自然语言处理(NLP)、语音信号识别、计算机视觉等相关知识,关注我,后续,我将分享更多人工智能tips!最后附上整段代码!
import jieba
import jieba.posseg as pseg
from sklearn.feature_extraction.text import TfidfVectorizer
from textrank4zh import TextRank4Keywordimport matplotlib.pyplot as plt
from wordcloud import WordCloud# 获取停用词
def load_stopwords(stopwords_file):stopwords = set()with open(stopwords_file, 'r', encoding='utf-8') as f:for line in f:stopwords.add(line.strip())return stopwords# 加载文档集,对文档集过滤词性和停用词
def filter_documents(data_path, stopwords):documents = []with open(data_path, 'r', encoding='utf-8') as f:for line in f:document = []words = pseg.cut(line.strip())for word, flag in words:if flag.startswith('n') and word not in stopwords and len(word) > 1:document.append(word)documents.append(document)return documents# 使用TF-IDF提取关键词
def extract_keywords_tfidf(documents, top_n=20):# 将过滤后的文档集转化为文本列表documents_text = [' '.join(document) for document in documents]# 创建TF-IDF向量化器tfidf_vectorizer = TfidfVectorizer()# 计算TF-IDF权重tfidf_matrix = tfidf_vectorizer.fit_transform(documents_text)# 获取特征词列表features = tfidf_vectorizer.get_feature_names_out()# 计算每个文档中的关键词top_keywords_per_document = []for doc_id in range(len(documents)):document_tfidf_weights = tfidf_matrix[doc_id].toarray()[0]top_keyword_indices = document_tfidf_weights.argsort()[-top_n:][::-1]top_keywords = [features[idx] for idx in top_keyword_indices]top_keywords_per_document.append(top_keywords)return top_keywords_per_documentdef generate_wordcloud(keywords, title):"""生成词云图并显示参数:keywords (list): 包含关键词的列表。title (str): 词云图的标题。返回:None"""# 将关键词列表转化为字符串keywords_str = ' '.join(keywords)# 指定中文字体文件路径(根据实际情况替换为合适的路径)font_path = r'D:\my_homework\NLP_homework\NLP_test1\SimHei.ttf' # 替换为包含中文字符的字体文件路径# 创建词云对象并指定字体wordcloud = WordCloud(width=800, height=400, background_color='white', font_path=font_path).generate(keywords_str)# 显示词云图plt.figure(figsize=(10, 5))plt.imshow(wordcloud, interpolation='bilinear')plt.axis('off')plt.title(f'wordcloud - {title}')plt.show()if __name__ == "__main__":stopwords_file = r'D:\my_homework\NLP_homework\NLP_test1\stopword.txt' # 停用词文件路径data_path = r'D:\my_homework\NLP_homework\NLP_test1\corpus4keyword.txt' # 文档集文件路径stopwords = load_stopwords(stopwords_file)documents = filter_documents(data_path, stopwords)print('停用词表的大小为:', len(stopwords))print('文档的数量为', len(documents))# 提取关键词top_keywords = extract_keywords_tfidf(documents)# 打印每个文档的前10个关键词for doc_id, keywords in enumerate(top_keywords):print(f'文档 {doc_id + 1} 的前10个关键词: {", ".join(keywords)}')document_keywords = top_keywords[19] # 假设第20个文档的索引是19generate_wordcloud(document_keywords, 'wordcloud')这篇关于NLP自然语言处理——关键词提取之 TF-IDF 算法(五分钟带你深刻领悟TF-IDF算法的精髓)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





