本文主要是介绍三十三章:From Contexts to Locality ——从上下文到局部性:通过局部感知的上下文相关性进行超高分辨率图像分割,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
&原文信息
原文题目:《From Contexts to Locality: Ultra-high Resolution Image Segmentation via Locality-aware Contextual Correlation》
原文引用:Li Q, Yang W, Liu W, et al. From contexts to locality: Ultra-high resolution image segmentation via locality-aware contextual correlation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 7252-7261.
原文链接:https://openaccess.thecvf.com/content/ICCV2021/papers/Li_From_Contexts_to_Locality_Ultra-High_Resolution_Image_Segmentation_via_Locality-Aware_ICCV_2021_paper.pdf
0.摘要
近年来,超高分辨率图像分割因其逼真的应用而引起了越来越多的关注。在本文中,我们创新了广泛使用的高分辨率图像分割流程,其中超高分辨率图像被分割为常规补丁进行局部分割,然后将局部结果合并为高分辨率语义掩码。特别地,我们引入了一种基于局部感知的上下文相关性的分割模型来处理局部补丁,其中局部补丁与其各种上下文之间的相关性被联合和互补地利用来处理具有大变化的语义区域。此外,我们还提出了一种上下文语义细化网络,将局部分割结果与其上下文语义相关联,从而在生成最终高分辨率掩码的过程中具有减少边界伪影和优化掩码轮廓的能力。此外,在全面的实验中,我们证明了我们的模型在公共基准测试中优于其他最先进的方法。我们发布的代码可在https://github.com/liqiokkk/FCtL上获得。
1.引言
随着摄影和传感器技术的进步,对超高分辨率图像(即2K、4K甚至更高分辨率图像)的获取已经为计算机视觉社区打开了新的视野。这将有利于各种图像应用,例如基于高分辨率地理空间图像的城市规划和遥感,以及高分辨率医学图像分析,因此对于研究和分析这类图像的需求近年来迫切增加。
在本文中,我们旨在针对从空中视角捕获的超高分辨率地理空间图像的语义分割这一特定任务。深度卷积神经网络(CNN)的最近发展已经促使语义分割技术取得了显著进展。然而,大多数基于CNN的分割模型针对的是全分辨率图像,并进行像素级别的类别预测,这与图像分类和目标检测相比需要更多的计算资源。当图像分辨率增加到超高时,这个障碍变得显著,导致了内存效率(甚至可行性)与分割质量之间的紧迫困境。
特别是为了分割超高分辨率图像,目前的做法要么是在进行分割之前将其降采样到较小的空间尺寸,要么是分别对划分的补丁进行分割,并将它们的结果合并成高分辨率的结果。这些简单的做法牺牲了模型效率以换取分割质量。此外,最近的尝试提出利用预训练的分割模型获取粗糙的分割掩码,并使用另一个模型来优化掩码的轮廓。然而,这些方法主要集中在高分辨率自然图像或涉及大型对象的日常照片上,而高分辨率地理空间图像是从空中视角拍摄的,涵盖了大范围的视野,可能包含许多具有不同尺度和形状对比的对象/区域。因此,需要分割模型能够捕捉到不仅是大范围图像区域的语义信息,还能捕捉到不同粒度的图像细节。最近的工作GLNet [4]提出了通过一个双流网络来结合局部和全局信息,分别处理降采样的全局图像和裁剪的局部补丁,以及一个特征共享模块,对两个流中的局部和全局特征进行连接共享。他们的方法可以明显改善现有方法,这体现了上下文信息对于分割性能的重要性。然而,他们的特征共享方案没有将局部特征与全局特征进行空间关联,因此无法很好地利用它们的相关性,这使得他们的模型过于复杂难以优化,性能也不够优化。
为了充分利用超高分辨率地理空间图像中的丰富信息,我们提出了一种具有局部感知上下文相关性方案的超高分辨率地理空间图像分割模型。类似于[4,25],我们的框架基于广泛使用的高分辨率图像分割实践,其中图像补丁从原始图像中定期裁剪出来,然后分别进行分割,最后将它们的局部结果叠加合并。然而,超高分辨率地理空间图像的每个局部补丁通常包含尺寸差异很大的语义区域(例如房屋和森林),这给局部分割模型带来了挑战。受之前的实践(例如[4])的启发,上下文信息被证明可以有效解决这个问题。但是,与先前的方法不同,我们提出局部补丁内的语义可以通过其不同尺度的上下文区域进行结构化和互补关联和推断。例如,在图1中,不同覆盖范围的上下文引导模型关注与图像中不同粒度对象相关的区域(例如小型或大型建筑物)。因此,我们提出了一种基于局部感知上下文相关性的深度网络模型来利用局部补丁与其上下文区域之间的相关性。具体而言,我们首先提出了一个局部感知上下文相关性模块,以捕捉局部补丁和上下文的位置相关性,从而能够集中增强局部补丁的相关特征,即局部感知特征。然后,我们提出了一种自适应上下文融合方案,以平衡和组合由不同上下文关联的局部感知特征。如图1所示,上下文可以导致不同但互补的局部感知特征,从而允许对单个上下文中的误导信息具有容忍性。为此,不同局部感知特征的相应空间权重图是即时预测的,以完成互补融合。
此外,为了获得超高分辨率图像的最终分割结果,局部补丁的结果将被重新组合。直接拼接局部分割掩码可能会导致相邻补丁之间边界消失的伪影,因此先前的做法是部分重叠相邻补丁,并计算重叠区域的平均结果。在一定程度上,这种简单的方法可以减少伪影,但无法达到最佳结果。因此,我们提出了一种有效的上下文语义细化网络,利用局部掩码和上下文掩码的相关性来增强相关的语义区域,从而自适应地改善局部结果,而不引入边界消失的伪影。此外,我们提出的模型还可以利用上下文语义来优化分割掩码的轮廓。
为了评估我们的模型,我们进行了全面的实验,并证明我们提出的模型在公共的超高分辨率航空图像数据集DeepGlobe和Inria Aerial上优于最先进的方法。本文的主要贡献总结如下:
- 我们提出了一种基于新型局部分割模型的超高分辨率图像分割框架。它利用了局部感知上下文相关性和自适应特征融合方案,将局部-上下文信息相互关联和组合,以加强局部分割效果。
- 我们提出了一种上下文语义细化网络,利用局部分割和上下文掩码的相关性,避免边界消失的伪影,并优化局部语义掩码。
- 我们的方法在几个公共的超高分辨率地理空间图像数据集上实现了最先进的语义分割性能。
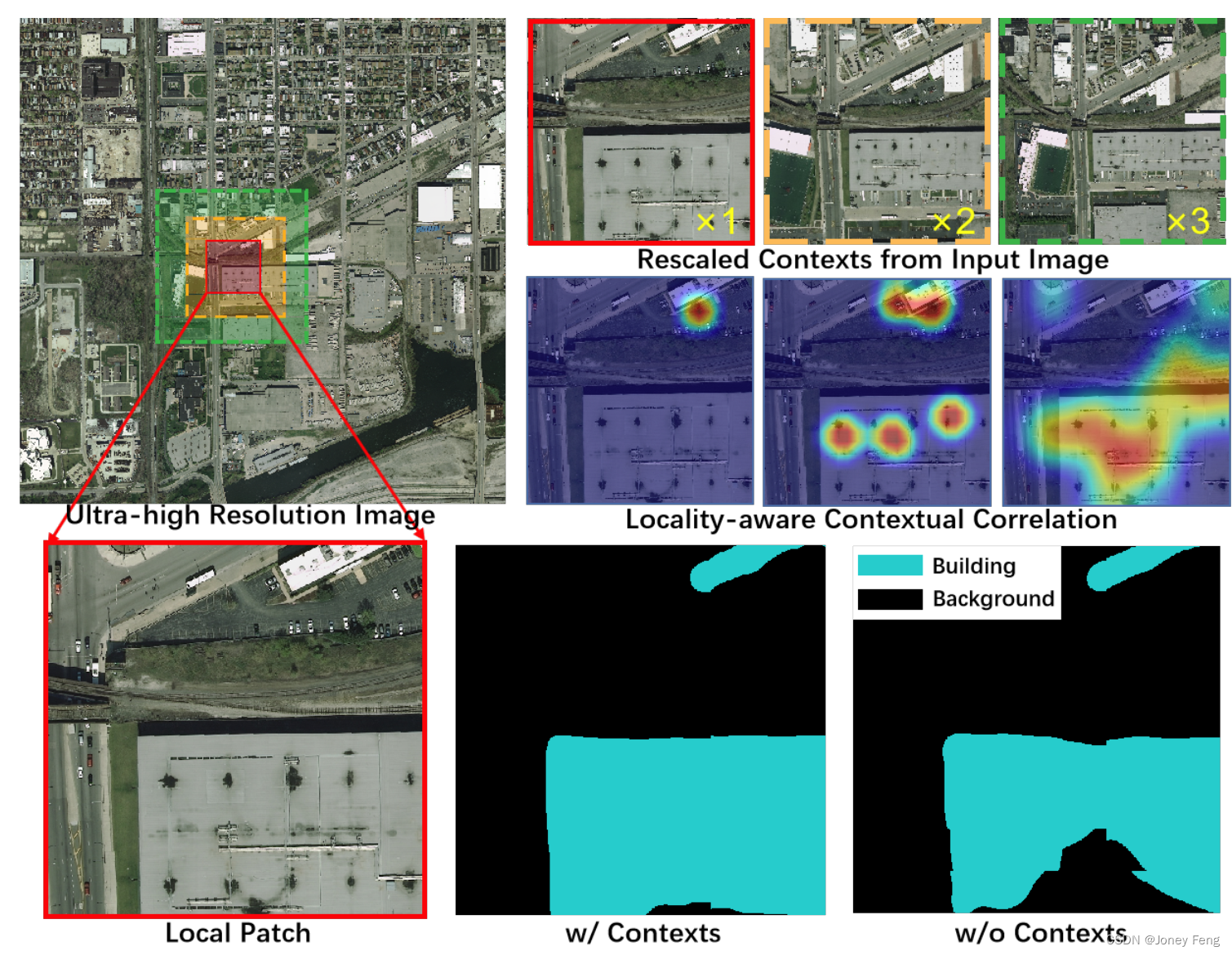 图1。对于超高分辨率图像分割任务,最常见的方法是对裁剪的局部补丁进行分割,然后将它们组合成高分辨率的掩码。为了解决局部分割质量的核心问题,我们提出了一种基于局部感知上下文相关性的模型,利用重新缩放的各种上下文(×1、×2、×3大于原始图像中的局部补丁)来产生精细化的结果。
图1。对于超高分辨率图像分割任务,最常见的方法是对裁剪的局部补丁进行分割,然后将它们组合成高分辨率的掩码。为了解决局部分割质量的核心问题,我们提出了一种基于局部感知上下文相关性的模型,利用重新缩放的各种上下文(×1、×2、×3大于原始图像中的局部补丁)来产生精细化的结果。
2.相关工作
语义分割。近年来,语义分割取得了显著进展[2,7,10-12,18,19,27,30]。全卷积网络(FCN)[18]是第一个用于高质量分割的CNN架构。U-Net [25]通过跳跃连接将低层特征与高层特征进行拼接。类似的结构也被[1,22]采用。不幸的是,这些模型对于超高分辨率图像的GPU内存需求过高。ENet [23]和ICNet [34]通过模型压缩来减少GPU内存的使用。然而,这些模型在超高分辨率图像上效果不佳。最近,提出了CascadePSP [5]来从预训练模型中优化粗糙的分割结果,生成高质量的结果。GLNet [4]通过深度共享层保留了全局和局部信息,并通过相互交互来平衡其性能和GPU内存的使用。与GLNet相比,我们提出的多上下文局部分割模型是关键的区别,而GLNet仅依赖整体图像作为唯一的上下文,并简单地将局部和裁剪的全局特征进行拼接以进行分割。此外,我们还提出了一种新的上下文细化模型,用于将局部结果合并成高清图像,这方面尚未进行研究。
多尺度和上下文聚合。多尺度信息[2,3,9,16,31,36,38]已经证明对于分割是有效的,通过整合高级和低级特征来捕捉不同粒度的模式。RefineNet [13]引入了多路径细化块,通过上采样低分辨率特征来结合多尺度特征。[8]采用Laplacian金字塔来利用更高级的特征来细化从低分辨率地图中重建的边界。特征金字塔网络(FPN)[14]逐步上采样不同尺度的特征图并以自顶向下的方式进行聚合。另一方面,上下文聚合也在编码局部空间邻域甚至非局部信息方面发挥着关键作用[2,4,17,28,29,32,35]。ParseNet [17]通过全局池化来聚合不同级别的上下文。DeepLab [2]提出了扩张卷积和孔洞空间金字塔池化模块,将全局上下文聚合到局部信息中。在最近的工作[4,21,24,33]中,深/浅分支被组合起来以聚合全局上下文和高分辨率细节。与之前的工作不同,我们提出局部分割可以与各种上下文空间相关,并提出一种自适应融合方案来结合不同的局部感知特征。
3.方法论
我们提出的超高分辨率图像分割框架遵循图2所示的三步骤过程,这与之前的工作(如[4,25])中的常见做法一致。首先,给定一个宽度为W、高度为H的超高分辨率图像I,我们将其均匀分割成N个局部补丁fIkg(k =[1;···;N],Ik ⊂I_),每个补丁的宽度为w,高度为h(w <W且h <H)。接下来,局部语义分割模型对每个补丁计算局部结果。最后,我们将局部结果合并成一张作为最终的高分辨率分割掩码。我们的主要贡献在于如何生成精细的局部分割(第二步)和可以无缝合并成高分辨率掩码的细化结果(第三步)。接下来,我们将详细阐述技术细节。
3.1.我们提出的局部分割模型
作为我们超高分辨率分割框架的核心,我们提出了一种新颖的局部分割模型来处理每个裁剪的补丁(图3)。然而,每个局部补丁仅涵盖超高分辨率图像的一个受限领域,这通常包含不同尺度或被截断的对象区域,因此往往会提供不完整的信息,可能会导致错误的语义分割。为了解决这个问题,我们提出了一种基于局部感知上下文相关的分割模型来处理每个局部补丁。如图3所示,我们的局部分割模型基于多流编码器-解码器架构,包括特征提取模块(即编码器)、局部感知上下文相关模块、多上下文融合模块和解码器。具体而言,为了减少计算开销,将每个局部补丁与不同尺度的上下文一起调整大小后输入网络进行特征提取。然后,通过局部感知上下文相关模块,将上下文的特征与局部补丁的特征分别关联起来,并进行自适应融合。最后,特征将被上采样以获得局部分割掩码。接下来,我们首先介绍如何选择局部补丁的上下文,然后描述局部感知上下文相关模块和多上下文融合方案。
3.1.1.局部补丁的上下文
对于第k个补丁Ik,Uk表示输入图像I_中另一个不小于Ik且覆盖Ik的图像区域。Uk的宽度为wu,高度为hu,满足w ≤ wu ≤ W和h ≤ hu ≤ H。给定一个局部补丁,有许多候选的上下文区域。在实践中,我们设计了以下三种类型的上下文区域。
(1)我们将候选上下文的大小设定为wu = λw和hu = λh;(λ≥1;wu ≤ W;hu ≤ H),并使其中心与局部补丁的中心对齐(参见图1和图3中的示例)。
(2)我们可以利用的最大上下文正好是整个图像,即Uk ≡ I_,称为全局上下文。
(3)最小的上下文是补丁本身,称为局部上下文,即wu ≡ w和hu ≡ h。
一般来说,较大的上下文提供了更多可能与大区域或对象相关的上下文线索,而较小的上下文提供了更多可能与小区域或对象相关的细节。在输入网络之前,上下文将被归一化为与局部补丁相同的尺寸。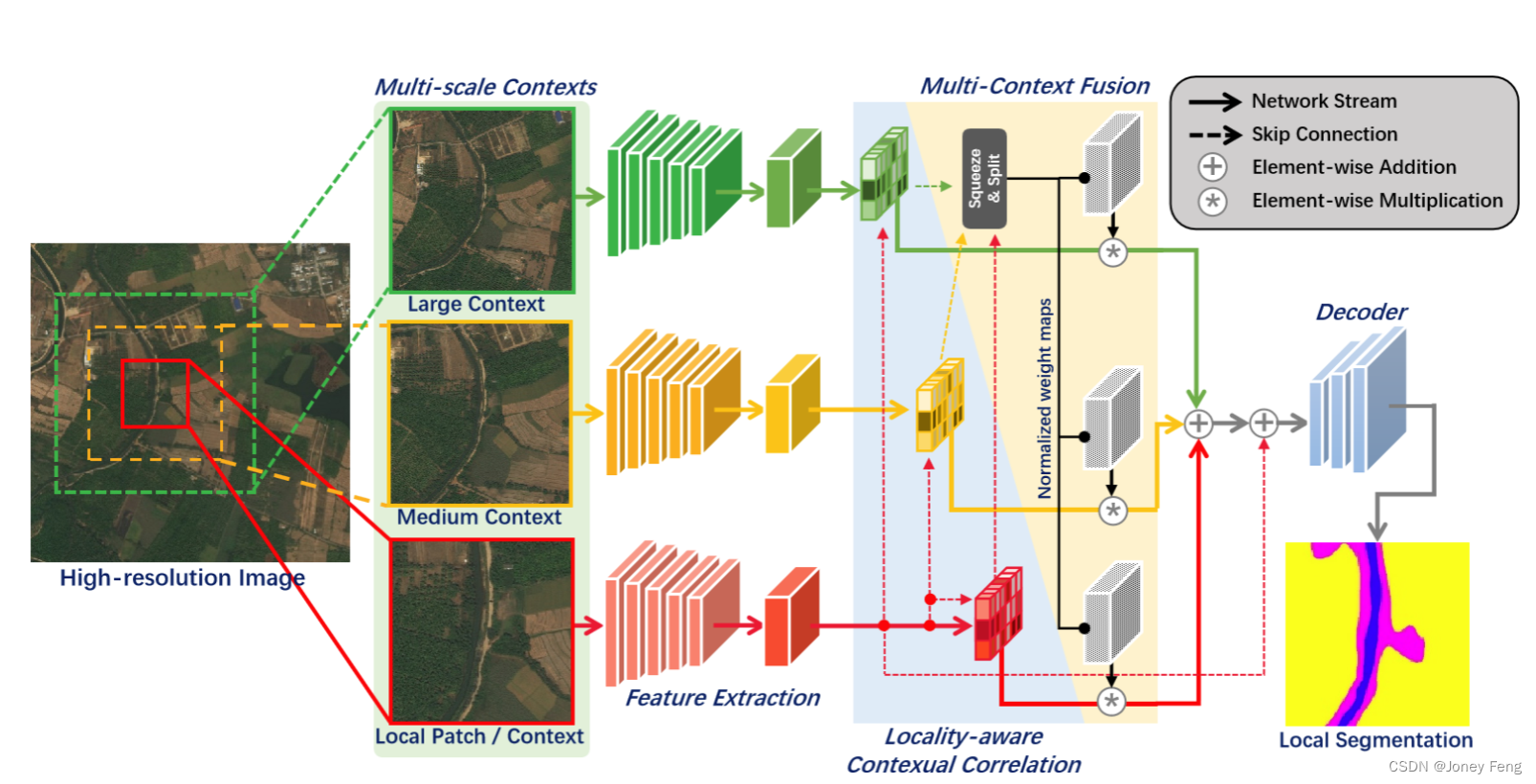
图3.我们局部分割模型的示意图。具体来说,从高分辨率图像中裁剪出的某个局部补丁及其上下文被分别传入网络分支,以提取特征并测量它们与局部补丁的相关性,从而获得具有局部感知的特征。最后,这些特征被自适应地融合,产生高质量的局部分割结果。
3.1.2.局部感知的上下文相关性
为了加强局部补丁的分割效果,我们希望将上下文信息与局部信息关联起来。因此,我们提出了一个局部感知上下文相关模块Flcc,用于评估Ik和Uk的特征之间的相关性,并利用它获取具有局部感知性的特征。我们所提出的模块的结构在图3中给出。首先,通过相同的网络结构(即预训练的VGG16的Conv1到Conv3),分别提取Ik和Uk的特征,分别表示为Xik和Xuk(Xik;Xuk ∈ R^c×h×w)。接下来,通过计算局部特征Xik和上下文特征Xuk的内积,计算Ik和Uk之间的相关性,即Rk = hXik;Xuki,该值通过建立像素级别的成对关系来衡量非局部相关性。因此,相关性可以进一步应用作为注意力图,增强局部特征Xik,使其关注与局部相关性更高的语义区域。具体而言,Rk经过softmax层得到注意力图,然后与Xik进行内积计算,即Xk = hSoftmax(Rk);Xiki。为了清晰起见,我们将这个过程表示为Xk = Flcc(Ik;Uk)。
3.1.3.多上下文融合模块
对于通常包含大量具有不同尺寸变化的对象的超高分辨率地理空间图像,不同尺度的上下文可能对具有不同粒度的对象分割起作用。因此,适当地组合不同的上下文信息可以互补地提取语义信息并去除伪影。具体而言,我们假设存在T个相关的上下文区域,可能影响局部分割。形式化地,给定补丁Ik,我们有T个对应的上下文区域Ukt(t = [1;···;T]),并将它们分别传入我们局部分割模型的每个分支,以获取具有局部感知的特征Xt k(Xt k = Flcc(Ik;Ukt))。为了有效地利用和组合来自不同上下文的局部感知特征,如图3所示,我们将多上下文融合方案集成到我们的局部分割模型中。在这里,我们提出了一个新的网络模块Fest,分别估计与特征fXt kg相对应的权重图fHtg。
具体而言,局部感知特征首先被连接起来,然后通过一个压缩和分割结构传递。该结构通过一个卷积层(卷积核大小为1×1)压缩和混合多尺度特征,然后预测来自不同源的特征的归一化权重,即fHtg = Fest(fXt kg)。具体而言,压缩和分割结构通过卷积层将连接的特征进行压缩,将局部感知特征混合在一起。然后,通过另一个1×1的卷积层将压缩后的特征重构到原始维度,并通过softmax函数进行归一化,得到T个归一化权重图fHtg(Ht ∈ R^hx×wx,t = [1;···;T]),用于平衡每个项的贡献。因此,我们可以得到融合后的特征Xk,如下所示:
其中 ⊙ 表示逐元素相乘,1 表示所有元素都为1的矩阵。需要注意的是,每个通道上的 T 个权重图的元素求和为1。最后,融合的特征将与局部补丁的特征通过跳跃连接连接在一起,形成残差结构,然后通过解码器中的几个上采样层计算补丁的分割掩码。通过这种方式,我们的特征融合方案能够利用来自不同上下文的互补信息。最后,我们将焦点损失[15]作为目标函数,其中 γ 设置为3。
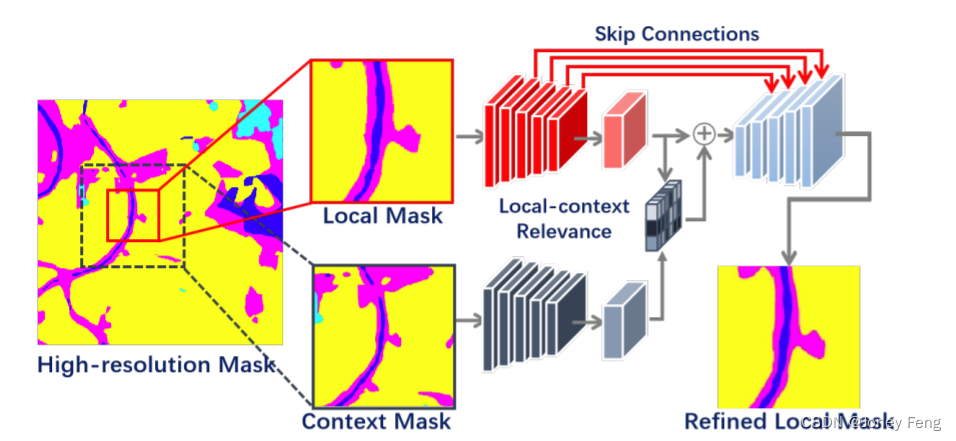
图4.上下文语义细化网络的示意图。给定一个粗糙的高分辨率语义掩码,我们将局部掩码和其上下文掩码输入到一个双分支网络中,以细化局部掩码。
3.2.上下文语义细化网络
在先前的实践中,将所有裁剪的补丁的计算分割掩码进行拼接很容易引起边界伪影,因此局部掩码以重叠的方式堆叠在一起(参见图2中的第三步),并且在重叠区域上计算平均值,这在一定程度上减少了伪影。以这种方式合并所有局部掩码最终得到最终的高分辨率结果。然而,这种简单的方法很难在不自适应地考虑局部补丁与其上下文的语义相关性的情况下获得最佳结果。为了解决这个问题,我们提出了一种上下文语义细化网络,利用上下文语义掩码来细化局部掩码。
给定计算得到的局部分割掩码,我们可以通过简单地拼接局部补丁或以重叠的方式合并掩码来生成粗糙的高分辨率掩码。尽管这个粗糙的结果可能包含伪影,但上下文的语义在体现相邻区域的地理空间布局方面起着重要作用,从而促进了局部掩码的细化。具体而言,如图4所示,我们的细化网络基于U-Net架构的两个流变体,其中包含了一个局部上下文相关模块,用于关联上下文和局部掩码。局部-上下文相关模块类似于我们的局部分割模型中的局部感知相关模块,它衡量了被缩放到与局部掩码相同维度的局部掩码和上下文掩码的特征之间的相关性,然后通过注意力机制增强局部掩码。因此,上下文语义可以被利用来不仅去除边界消失的伪影,还可以改善局部掩码的轮廓。此外,与标准的U-Net结构相同,我们的网络通过跳跃连接连接了下采样和上采样层的特征,将低层次的细节传递给深层,以实现细化的结果。此外,我们也采用了焦点损失作为目标函数。所有细化的局部结果可以进一步应用于拼接出更高质量的高分辨率语义掩码。
4.实验结果
在本节中,我们展示了在公共基准测试中的全面实验结果。我们与最先进的方法进行了全面比较,以展示分割质量,并进行了剔除研究,以评估我们模型的能力。
4.1.数据集
DeepGlobe [6]数据集。该数据集包含803张超高分辨率图像(2448×2448像素)。按照[4]的方法,我们将图像分为训练集、验证集和测试集,分别包含455、207和142张图像。密集注释包含七个类别的景观区域,包括青色表示“城市”,黄色表示“农业”,紫色表示“牧场”,绿色表示“森林”,蓝色表示“水域”,白色表示“贫瘠地区”,其中七个类别中的一个称为“未知”区域在挑战中不予考虑。
Inria Aerial [20]数据集。该数据集涵盖了各种城市景观,从密集的都市区到高山度假村。它提供了180张图像(来自五个城市),每张图像都用二值掩码注释了建筑/非建筑区域。与DeepGlobe不同,它将训练集和测试集按城市进行了划分。我们按照[4]的协议,将图像分为训练集、验证集和测试集,分别包含126、27和27张图像。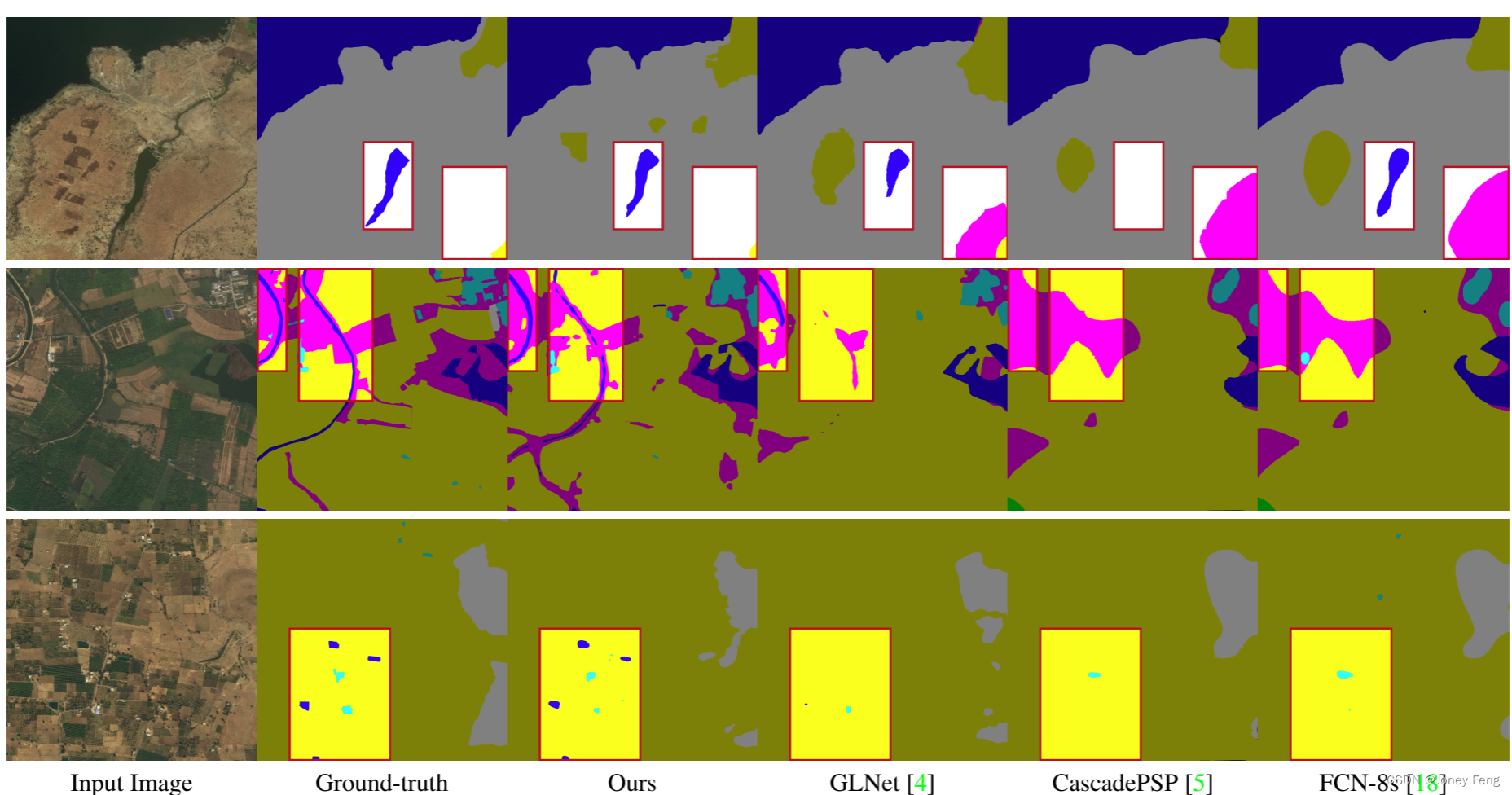
图5。我们展示了超高分辨率图像中语义分割的几个示例,并与最先进的方法进行了比较。在这些图中,不同颜色的掩码表示不同的语义区域。特别是,青色表示“城市”,黄色表示“农业”,紫色表示“牧场”,绿色表示“森林”,蓝色表示“水域”,白色表示“贫瘠地区”。
4.2.实验细节
上下文设置。在实践中,我们在模型中应用了三个上下文,分别称为局部、中等和大型上下文。对于两个基准测试,上下文的大小是不同的。我们在第4.4节中评估了不同上下文设置的性能。
训练细节。我们在一台配有单个NVIDIA GTX 1080Ti GPU的计算机上使用Pytorch实现了我们的框架。特别地,我们采用VGG16 [26]作为我们的主干网络,我们的基线模型类似于FCN-8s [18]。所有输入图像(即局部补丁)被归一化为508×508,并且输出大小也是508×508,这遵循[4]的设置,以在性能和效率之间进行权衡。在将局部结果合并为高分辨率结果时,我们让相邻的补丁有一个120×508的重叠区域,以避免边界消失。在训练局部分割模型时,我们采用Adam优化器和梯度累积的小批量大小为6。初始学习率设置为5×10−5,并且按照多项式学习率策略进行衰减,其中初始学习率在每次迭代后乘以(1−total iter/iter)的0.9次方。在实践中,我们需要50个epochs来使模型收敛。此外,作为我们的基线和比较方法,FCN-8s [18]也遵循以上的训练策略。
关于上下文语义细化网络的独立训练,我们采用了与局部分割模型类似的训练设置。需要注意的是,上下文细化网络的输入(即局部和上下文掩码)来源于我们训练过的分割模型。一旦细化网络与局部分割模型共享相同的训练数据集,就容易导致细化网络过拟合并降低其推理性能。为了解决这个问题,我们采用了一种简单的策略。我们不完全训练局部分割模型,而是在20个epochs后提前停止其训练,并利用未收敛的分割模型生成样本来训练细化网络,这证明效果很好。
4.3.与当今主流方法的比较
在评估方面,我们将我们的方法与U Net [25]、ICNet [34]、PSPNet [35]、SegNet [1]、DeepLab v3+ [2]、FCN-8s [18]、CascadePSP [5]和GLNet [4]在DeepGlobe和Inria Aerial这两个基准数据集上进行了比较,评估指标包括mIOU(%)、F1(%)和准确率(%)。它们的结果在表1和表2中展示,其中我们遵循[4]提供的大部分定量结果。这些方法大多数都不是针对超高分辨率图像设计的(在表1中标注为通用模型),因此有两种训练这些模型的方式:1)从局部补丁训练并合并局部结果;2)从降采样的全局图像训练。因此,我们在表1中提供了它们在DeepGlobe上的局部推理和全局推理的相应指标。CascadePSP和GLNet是专门为超高分辨率图像语义分割任务设计的(在表1中标注为高分辨率模型)。特别地,CascadePSP主要处理自然图像,而GLNet适用于地理空间图像。需要注意的是,在表1中,GLNet*指的是没有全局局部特征共享模块的模型。所有结果都是按照相同的训练和测试协议获得的。此外,由于CascadePSP的原始论文没有报告这两个数据集上的结果,我们在实验中按照相同的协议训练了他们的模型。CascadePSP需要一个预训练模型来提供粗略的全局结果。在我们的实验中,他们预训练的全局模型在DeepGlobe和Inria Aerial数据集上的表现分别为66.9%和69.0%。从表1和表2可以看出,在所有比较方法中,我们的模型在各个数据集上与竞争方法相比取得了最先进的性能。我们的任务存在严重的类别不平衡问题,例如,“农业”类别的面积(即像素数)比“水域”类别要大得多。像素级的F1和准确率指标很难反映出模型如何处理这个问题。相反,mIOU衡量了每个类别的平均分割质量。因此,mIOU的主要改进(超过2%)表明了我们模型的有效性。此外,我们在图5中展示了几个定性比较结果。从观察到,我们的模型能够识别条状区域(如河流)和小区域(如农业),这得益于局部和上下文之间的相关性。
表1. 在DeepGlobe上与最先进方法的比较。
表2. 在Inria Aerial上与最先进方法的比较。
4.4.消融研究
在本节中,我们深入研究了我们提出的模型的模块和设置,并展示了它们的有效性。
上下文的有效性。我们的基准模型是基于FCN-8s [18]的,没有引入上下文。如表3所示,总体上,整合上下文明显提高了分割性能,在DeepGlobe数据集中,性能从71.84%提升到73.22%,在Inria Aerial数据集中,性能从69.08%提升到73.53%。特别是,最小的上下文(即局部上下文或局部补丁本身)提供了非局部自相关线索。然而,局部补丁的自相关特征很难提供足够的信息来进一步推断出补丁的语义。另一方面,中等和大型上下文引入了缩放后的上下文信息,从而促进了分割。但是,仅依靠中等上下文或大型上下文可能并不总是产生更好的结果。例如,在Inria Aerial数据集中,中等或大型上下文的结果甚至略差于局部上下文的结果。因此,利用不同尺度上下文的互补信息可以获得更好的结果。在图6中,我们展示了带有或不带有上下文的模型产生的几个示例。
局部感知的上下文相关性。为了验证,我们将其替换为朴素的局部全局特征拼接进行比较,在这种比较中,我们提出的方案优于特征拼接(在DeepGlobe上的mIOU为73.5%对比72.2%,在Inria Aerial上的mIOU为73.7%对比72.8%)。
上下文的尺度。我们研究了上下文尺度对分割性能的影响。在表4中,我们评估了在两个基准测试中使用不同上下文尺度的模型。直观地,如果上下文尺度接近局部补丁的尺度,局部补丁和上下文高度重叠,并且它们共享太多冗余信息,可能不会带来太大的性能提升。因此,对于候选上下文的尺度,我们选择局部补丁尺寸(508×508)的倍数作为三个上下文(即小、中、大)的尺度。对于DeepGlobe数据集,最佳的上下文尺度分别为508×508、1524×1524和2448×2448,其中大尺度上下文恰好是整个图像(即全局上下文)。对于Inria Aerial数据集,最佳的上下文尺度为508×508、1016×1016和1524×1524。这两个数据集的不同配置是由于它们的图像特点不同。DeepGlobe包含具有不同地形(例如水域和森林)的地理空间图像,而Inria Aerial包含俯视城市景观,其中可以观察到大量建筑物。因此,对于DeepGlobe,将整个图像作为大尺度上下文可以更好地理解语义。相反,对于Inria Aerial,在缩小尺寸后过大的上下文将丢失城市细节,使模型难以分辨图像中的建筑物,从而导致性能下降。
多上下文融合。为了展示我们融合方案的优势,我们将我们的模块与两种简单的融合方法进行了比较:1)简单地对局部感知特征取平均(即T1 PT t=1 Xt);2)离线估计局部感知特征的最优权重(即估计的权重在每个数据集上保持不变)。在表5中,我们展示了以mIOU衡量的比较分析结果。观察到,我们的自适应融合方案在简单融合方法上实现了最佳性能。在图7中,我们展示了我们的融合方案与没有融合的结果的示例。需要注意的是,我们的融合方案本质上是平均融合和加权融合的通用版本,因此在表5中显示的优势可能不是显著的,但表明了其有效性。
上下文语义细化网络。我们评估了上下文语义细化网络的有效性。我们将我们的方法与使用非重叠拼接和重叠合并(即取平均)的简单方法进行了比较。如表6所示,我们的语义细化网络在mIOU方面超过了简单方法。此外,我们研究了该网络的上下文尺度对细化网络的影响。具体而言,我们评估了上下文尺度为762×762、1016×1016和1270×1270的结果,其中1016×1016的上下文掩码导致了最佳结果。在图8中,我们展示了我们的模型能够减少边界伪影并细化语义掩码的轮廓。我们的网络可以与先前的模型合作。例如,与GLNet [4]一起使用,它还可以将其在DeepGlobe上的mIOU从71.6提升到72.6。
内存开销和计时性能。在推断阶段,我们的局部分割模型对DeepGlobe和Inria Aerial图像中的每个补丁大约需要3167MB的内存,这与FCN-8s(2477MB)相比,并没有增加太多的计算开销。作为一个独立于分割模型的模型,我们的细化网络需要1165MB的内存。因此,我们的模型的内存使用与现有的语义分割模型相当。对于计时性能,我们的分割模型每个补丁处理时间为0.15秒,我们的细化模型在推断过程中每个补丁需要0.06秒。总体而言,对于每个DeepGlobe和Inria Aerial的实例,相比于FCN-8s(3秒和9秒)、GLNet(6秒和19秒)和CascadePSP(9秒和37秒),我们的模型需要耗时8秒和26秒。
图6。示例展示了上下文的有效性。
表4。局部分割的上下文尺度。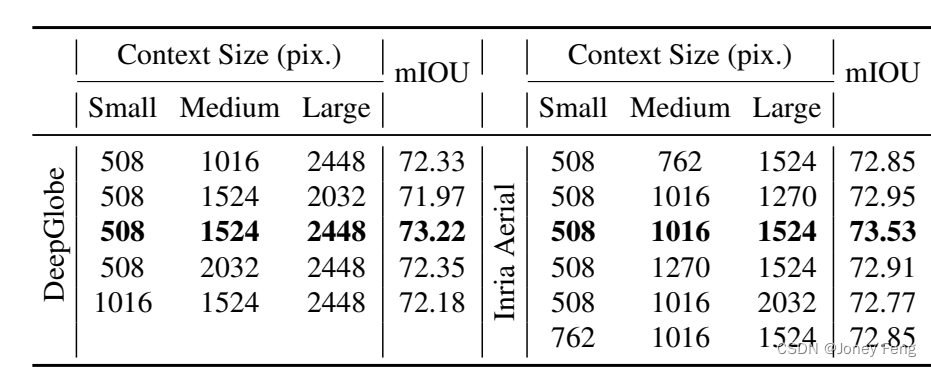
表6。公共数据集上的掩码细化的上下文尺度。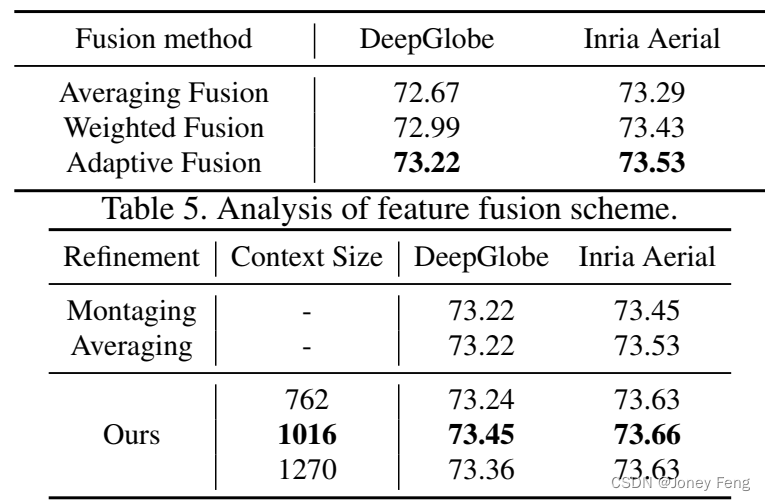
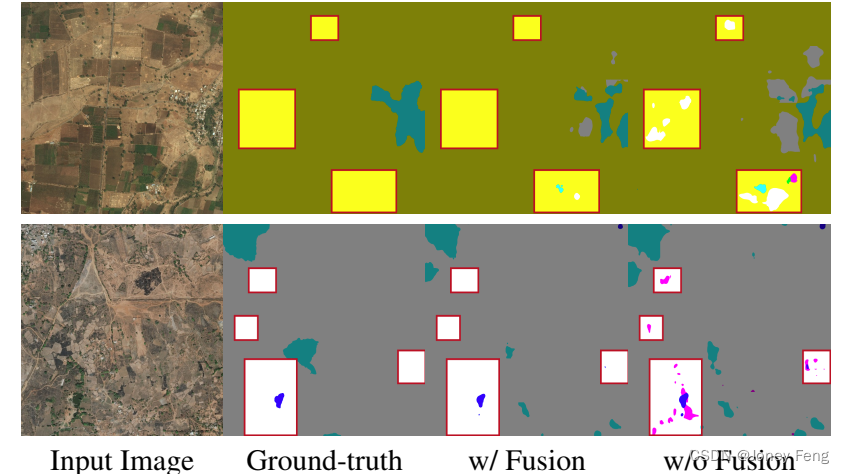
图7。示例展示了我们自适应融合的有效性。
图8。该示例显示了相邻补丁上的边界伪影,其中边界以虚线表示。
5.总结
我们引入了一种基于局部感知上下文相关性的分割模型来处理局部图像补丁。此外,我们还提出了一种上下文语义细化网络,能够在创建最终高分辨率掩码的过程中减少边界伪影并优化掩码轮廓。
这篇关于三十三章:From Contexts to Locality ——从上下文到局部性:通过局部感知的上下文相关性进行超高分辨率图像分割的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



