本文主要是介绍Presto+Alluxio数据平台实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数新网络,让每个人享受数据的价值 https://xie.infoq.cn/link?target=https%3A%2F%2Fwww.datacyber.com%2F
https://xie.infoq.cn/link?target=https%3A%2F%2Fwww.datacyber.com%2F
一、Presto & Alluxio简介
Presto
Presto是由Facebook开发的开源大数据分布式高性能 SQL查询引擎。
起初,Facebook使用Hive来进行交互式查询分析,但 Hive是基于MapReduce为批处理而设计的,延时很高,满足不了用户对于交互式查询想要快速出结果的场景。
为了解决Hive并不擅长的交互式查询领域,Facebook 开发了Presto,它专注于提供低延时、高性能的交互式查询服务。
与Hive等其他批处理的SQL引擎不同,Presto的查询速度非常快,可以在亚秒级或者分钟级内返回结果,让用户能够更加轻松地进行数据分析和查询。同时,Presto还支持多种数据源的查询,包Hive、MySQL、PostgreSQL、Kafka等,提供了丰富的函数库和强大的扩展性,使得它在企业数据分析、数据仓库构建等领域有着广泛的应用。
Alluxio
Alluxio是一个开源的分布式内存文件系统,由UC Berkeley AMPLab实验室开发。
Alluxio最初名为Tachyon,后更名为Alluxio。它主要解决大数据计算中数据访问速度瓶颈的问题。Alluxio将数据缓存在内存中,使大数据应用程序可以更快速地访问数据。
与传统的HDFS不同,Alluxio无需将数据预先写入磁盘,而是直接将数据缓存在内存,大大提升了数据访问速度。对于需要访问同一数据集的不同计算框架如Spark、MapReduce、Hive等,Alluxio只需将数据集缓存到内存一次,之后所有框架都可以共享这份缓存数据,避免了数据的重复加载。
此外,Alluxio支持混合存储架构,可以挂载多种底层存储系统如AWS S3、Azure Blob Store、HDFS等。数据会先被Cache到Alluxio中,如果Cache不足,Alluxio会暂时从底层储存系统中读取数据。
Alluxio作为内存级数据访问层,极大地提升了大数据应用的性能。它被广泛应用于数据分析、机器学习等需要高吞吐访问大数据集的场景。
二、应用Presto + Alluxio 的场景
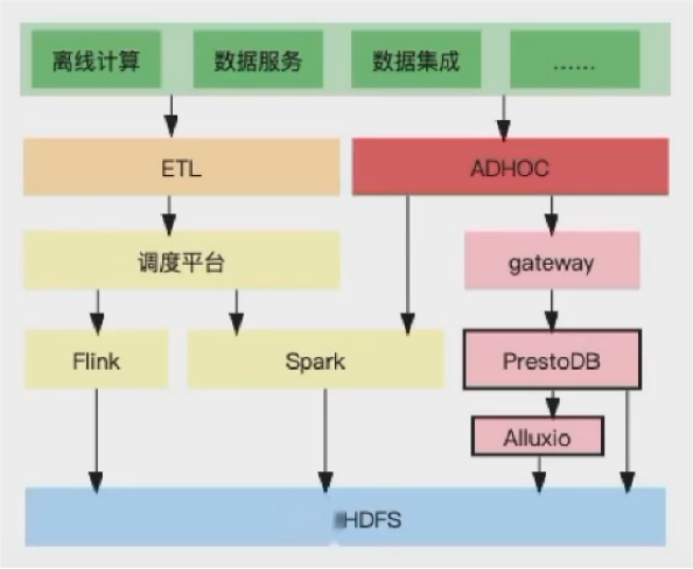
Presto+Alluxio的使用场景主要在交互式查询的场景中:
1、实时数据分析
Presto可以查询各种实时数据源如Kafka,配合Alluxio内存级缓存,可以实现对实时数据流的秒级交互分析。
2、交叉数据源查询
Presto可以查询多源异构数据,Alluxio提供数据访问统一层,两者配合可以轻松实现交叉数据源的交互查询。
3、数据仓库查询分析
典型的数据仓库查询对交互性要求较高,Presto + Alluxio可实现对云数据仓库中数据的高速查询。
4、海量小文件查询
Alluxio可将海量小文件缓存到内存中,Presto基于内存数据查询速度很快。
5、分布式环境复杂查询
在分布式环境下,复杂查询需要访问全局数据,Presto+Alluxio可通过内存加速解决网络IO问题。
6、多租户环境查询隔离
Alluxio通过缓存空间隔离提供查询隔离,Presto按租户查询,可实现多租户安全可靠查询。
7、持久化短查询结果
对于重复查询,可以将Presto结果持久化到Alluxio,避免重复计算。
8、跨云查询
Presto可查询多云数据,Alluxio统一数据访问层,实现跨云数据高效查询。
Presto和Alluxio在交互查询领域可以良好覆盖各种典型场景,共同解决交互查询面临的关键痛点,为用户提供高性能、灵活、稳定的交互式查询服务。
Presto + Alluxio 部署方式
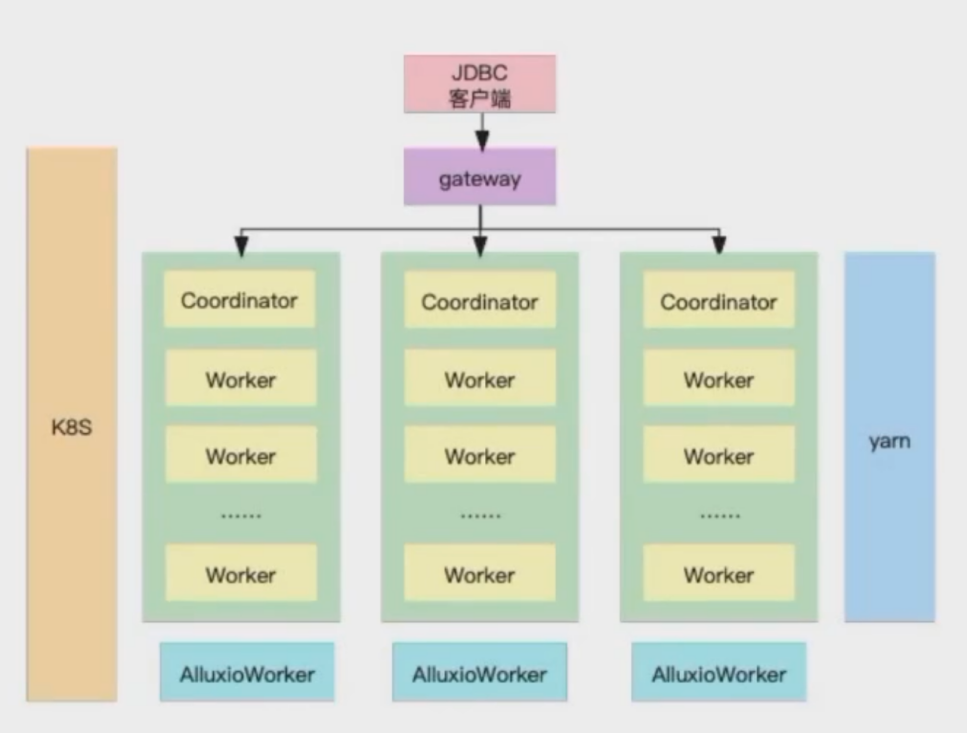
在生产环境中,Presto+Alluxio可通过两种方式部署,分别是基于K8s和Yarn部署:
Presto + Alluxio on K8s部署
在本部署方案中,将Presto的Coordinator和worker包括Alluxio的master worker和Presto 的网关Gateway都部署在K8s上,由K8s完成负载和高可用的功能;
Presto on Yarn 部署
在Yarn部署方式中,即由Yarn完成原来由K8s完成的工作,在Yarn部署中,需要使用开源组件Apache Slider;在Yarn部署中,将Presto的coordinator和worker部署在Yarn上;在部署中,需要使用混合部署的模式,需要在每一台部署的nodeManager或者宿主机上部署一个AlluxioWorker,使PrestoWorker可以短路读取本地的缓存,其中缓存存储介质建议使用SSD,可实现较好的加速效果。
三、使用Alluxio遇到的问题
问题一:其他业务系统不能识别Alluxio
问题描述: (以访问Hive表为例)
Presto查询前先访问HMS拿到表和分区的location,locationUrl的schema必须是alluxio:/,Presto才会使用alluxio.hadoop.FileSystem去访问Alluxio Master (由core-site.xml中的fsalluxioimpl配置)。
如果拿到的locationUrl的schema是hdfs://,Presto默认使用org.apache.hadoop.hdfs.DistributedFileSystem去访问NameNode(fs.hdfsimpl的默认值)。
但是如果HMS中存的location是alluxio://,其他业务系统无法识别这个schema。
解决方案:
重写一个hadoop兼容的文件系统客户端,配置到core-site.xml中的fs.hdfsimpl,替换掉默认的实现DistributedFileSystem;Presto在拿到hdfs://的location时,就会使用自实现的客户端来处理,直接访问Alluxio,相当于把schema转换成alluxio://。
问题二:如何提高缓存空间的利用效率?
解决方案:
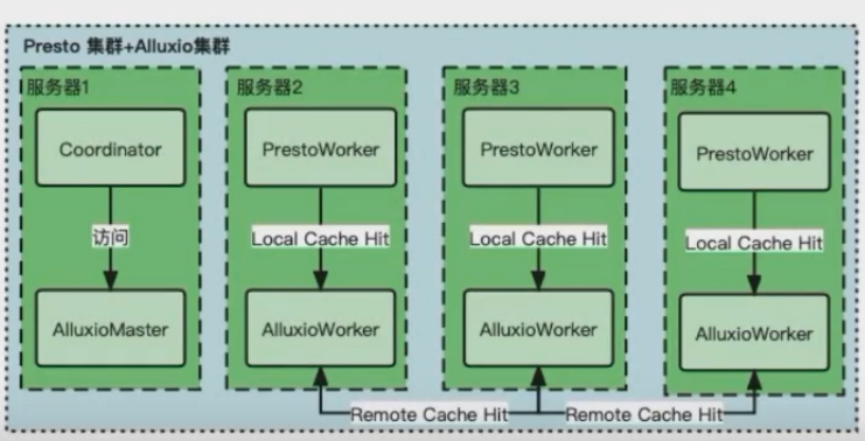
默认配置下,会造成多次远程命中和缓存数据大量几余,数据更容易被淘汰,降低命中率,可通过开启Presto软亲和性,并采用一致性hash算法来分配Split,实现在保持数据本地性的前提下,降低缓存冗余。
其中:集群整体都进入繁忙的时候,软亲和性等于失效,进而降低数据本地性引发缓存冗余、数据淘汰、命中率下降。
四、适合Alluxio的场景
场景一:UFS的文件不宜太小
读取的小文件越小,Alluxio加速收益越低。
同样大小的数据,小文件越多,读取的元数据、创建的split和driver数越多,还要调度更多的driver执行,这些操作都无法被加速。
例如在数仓中采集到ODS层的数据,如果存在大量小文件,进而导致DWDDWS层也有大量小文件这种场景下,使用Alluxio加速交互式查询数仓的效果会比较差。
优化建议:合并掉Hive表的小文件。
场景二:UFS的文件不宜太小
执行的sql查询越复杂,加速收益越低在整体耗时中,IO耗时的占比就会下降,而Alluxio只能加速IO的耗时,所复杂sql的计算耗时较长以在整体耗时的加速上收益会降低。
ETL中的那些复杂sql,使用Alluxio来加速意义不大。
优化建议:过于复杂的sql执行时不要走Alluxio访问数据。
这篇关于Presto+Alluxio数据平台实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






