alluxio专题

内存文件系统之Alluxio
Alluxio 是一个开源的分布式虚拟化文件系统,旨在为计算框架和存储系统之间提供一个高效的数据访问层。它最初由 UC Berkeley 的 AMPLab 开发,最早以 Tachyon 的名义推出,后来更名为 Alluxio。Alluxio 的目标是通过将存储资源抽象为一个统一的命名空间,简化数据管理和访问,并提升数据处理的性能。 官方地址:Alluxio - Data Orchestratio

Tachyon(现名:Alluxio):Spark生态系统中的分布式内存文件系统
原文: http://www.csdn.net/article/2015-06-25/2825056 Tachyon是Spark生态系统内快速崛起的一个新项目。 本质上, Tachyon是个分布式的内存文件系统, 它在减轻Spark内存压力的同时,也赋予了Spark内存快速大量数据读写的能力。Tachyon把内存存储的功能从Spark中分离出来, 使Spark可以更专注计算的本身, 以求通过更

Apache Zeppelin 中 Alluxio 解释器
概述 Alluxio是以内存为中心的分布式存储系统,能够以集群框架的速度实现可靠的数据共享。 配置 Name Class Description alluxio.master.hostname localhost Alluxio master 主机名 alluxio.master.port 19998 Alluxio master 端口

【Alluxio】文件系统锁模型之LockPool
Alluxio设计LockPool的主要目的是: 作为保存锁的一个资源池、不让任何正在使用的锁entries被evict掉、超过某个配置的高水位时后台线程evict那些没有使用的资源。 这个池子设计的很好,我们从这个LockPool的设计里也可以学习到如何自己设计一个资源池。 关键词: 存储Lock的池子(底层是个Map)、负载因子、evict线程、低水位、高水位。 定义LockPool里
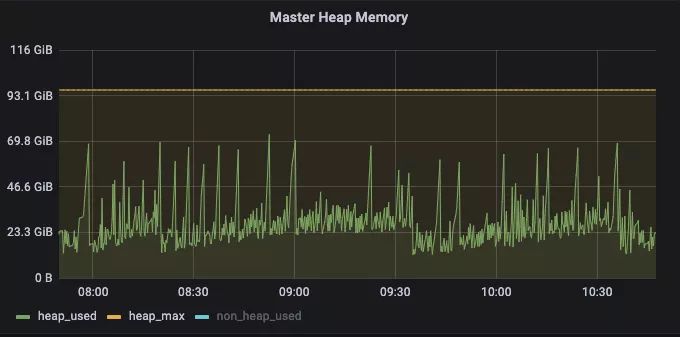
腾讯内部实践分享 | 千节点Alluxio 集群助力游戏 AI 业务
图片来源:Pexels 本文作者:郑兵、毛宝龙、潘致铮 Alluxio 是一个面向 AI 以及大数据应用,开源的分布式内存级数据编排系统。随着大数据和 AI 业务向 Kubernetes 等容器管理平台迁移,将 Alluxio 作为中间层,为数据查询及模型训练等场景加速,成为各厂商的首选方案。 Alluxio 在游戏 AI 离线对局业务中解决的问题可以抽象为:分布式计算场景下的数据依

你不知道的开源分布式存储系统 Alluxio 源码完整解析(上篇)
PART ONE 前言 目前数据湖已成为大数据领域的最新热门话题之一,而什么是数据湖,每家数据平台和云厂商都有自己的解读。整体来看,数据湖主要的能力优势是:集中式存储原始的、海量的、多来源的、多类型的数据,支持数据的快速加工及计算。相比于传统的数据仓库,数据湖对数据有更大的包容性,支持结构化/半结构化/非结构化数据,能快速进行数据的落地和数据价值发掘。数据湖的技术体系可以分为三个子领域:数据
Alluxio增强Spark和MapReduce存储能力
Alluxio的前身为Tachyon。Alluxio是一个基于内存的分布式文件系统;Alluxio以内存为中心设计,他处在诸如Amazon S3、 Apache HDFS 或 OpenStack Swift存储系统和计算框架应用Apache Spark 或Hadoop MapReduce中间,它是架构在底层分布式文件系统和上层分布式计算框架之间的一个中间件。 对上层应用来讲,Alluxio

【数据平台】之Alluxio内存加速S3文件系统数据利器
Alluxio 是大数据领域数据内存加速利器,是世界上第一个面向基于云的数据分析和人工智能的开源的数据编排技术。 它为数据驱动型应用和存储系统构建提供了桥梁, 将数据从存储层移动到距离数据驱动型应用更近的位置,从而使得数据能够更容易被访问。 这还使得应用程序能够通过一个公共接口连接到许多存储系统。 Alluxio内存至上的层次化架构使得数据的访问速度能比现有方案快几个数量级。 在现有大数据生态系

导师男团来袭 | 开源之夏2022,与Alluxio一起探索数据编排的奇妙世界
活动简介 开源之夏(英文简称 OSPP)是由“开源软件供应链点亮计划”发起并长期支持的一项暑期开源活动,今年是第三届,由中国科学院软件研究所与 openEuler 社区共同举办,旨在鼓励在校学生积极参与开源软件的开发维护,促进优秀开源软件社区的蓬勃发展,培养和发掘更多优秀的开发者。 活动联合国内外各大开源社区,针对重要开源软件的开发与维护提供项目任务,并面向全球高校学生开放报名。 学
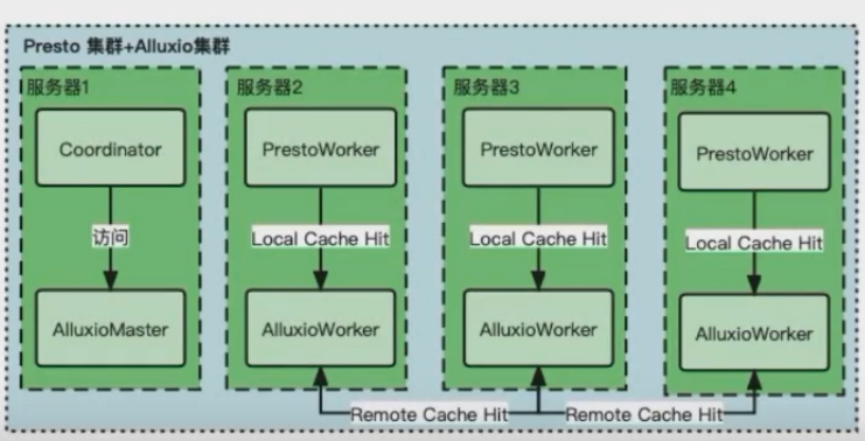
Presto+Alluxio数据平台实战
数新网络,让每个人享受数据的价值https://xie.infoq.cn/link?target=https%3A%2F%2Fwww.datacyber.com%2F 一、Presto & Alluxio简介 Presto Presto是由Facebook开发的开源大数据分布式高性能 SQL查询引擎。 起初,Facebook使用Hive来进行交互式查询分析,但 Hive是基于M
Alluxio CEO李浩源:构筑数据流动的高速公路
Robin.ly 是一个全新的视频内容平台,旨在为广大工程师和研究人员提高对商业、创业、投资和领导力的理解。本期是Robin.ly创始人Alex Ren采访Alluxio 创始人,李浩源博士。 以下为采访实录摘要: 完整视频请在文末扫二维码关注 Alex: 大家好,我是Alex Ren,是Robin.ly和TalentSeer的创始人。今天是我们Robin.ly Entrepreneur

百度案例:使用Alluxio提速数据查询30倍
作为全球最大的中文互联网搜索提供商,百度在其产品数据服务系统方面经验丰富。在本案例研究中,百度的高级架构师刘少山分享了他们在生产环境中使用Alluxio的经验,以及为什么Alluxio能够带来显著的性能提升。使用Alluxio将原先的批处理查询将转换为交互式查询,这使百度能够以交互方式分析数据,从而提升了生产力,并改善了用户体验。 业务挑战 百度作为中国最大的搜索引擎,这意味着我们有很多的数据