本文主要是介绍【数据平台】之Alluxio内存加速S3文件系统数据利器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Alluxio 是大数据领域数据内存加速利器,是世界上第一个面向基于云的数据分析和人工智能的开源的数据编排技术。 它为数据驱动型应用和存储系统构建提供了桥梁, 将数据从存储层移动到距离数据驱动型应用更近的位置,从而使得数据能够更容易被访问。 这还使得应用程序能够通过一个公共接口连接到许多存储系统。 Alluxio内存至上的层次化架构使得数据的访问速度能比现有方案快几个数量级。
在现有大数据生态系统中,Alluxio 位于数据驱动框架或应用(如 Apache Spark、Presto、Tensorflow、Apache HBase、Apache Hive 或 Apache Flink)和各种持久化存储系统(如 Amazon S3、Google Cloud Storage、OpenStack Swift、HDFS、GlusterFS、IBM Cleversafe、EMC ECS、Ceph、NFS 、Minio和 Alibaba OSS)之间。 Alluxio 统一了存储在这类不同存储系统中的数据,为其上层数据驱动型应用提供统一的客户端 API 和全局命名空间。
流程图
- 阐述了alluxio在整个商城体系中的角色
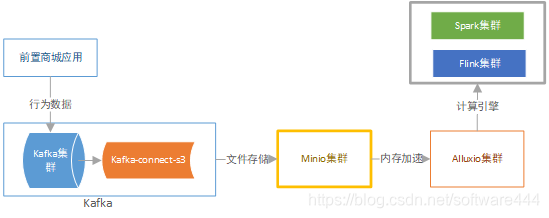
1、商城客户行为数据通过kafka存储到minio文件集群;
2、alluxio通过内存加速,将数据缓存到本机内存存储,提供快速数据访问桥梁;
3、计算引擎(Spark或Flink)直接操作Alluxio集群内存,实现数据快速计算;
Alluxio部署
其中alluxio 的版本为2.4,以下是5个服务器节点,每个节点内存32GB,挂载数据盘大小200GB,采用虚拟机部署,也可以采用K8s部署,安装用户为appuser,对其部署进行说明:
192.168.1.11 #master节点
192.168.1.12 #master节点
192.168.1.13 #master节点
192.168.1.14
192.168.1.15
1、系统配置
1.1、服务器间免密配置
- 生成公钥(秘钥对)
ssh-keygen -t rsa #默认一直执行下去,每个节点如此 - 查看秘钥
cat /appuser/.ssh/id_rsa.pub - 生成auth文件
cd .ssh/
touch authorized_keys - 文件拷贝
将第二步生成的key拷贝authorized_keys文件中保存,#每个节点的key都分别拷贝到其他节点authorized_keys文件保存。 - 授权
chmod 644 authorized_keys
1.2、服务器名映射配置
vim /etc/hosts
在每个服务器节点,如果存在服务器名称,需要做名称与IP的映射,例如:
192.168.1.11 ONE1181.main.local
192.168.1.12 ONE1182.main.local
192.168.1.13 ONE1183.main.local
192.168.1.14 ONE1184.main.local
192.168.1.15 ONE1185.main.local
1.3、系统参数调优
- vi /etc/sysctl.conf,增加如下配置项
vm.swappiness=5net.core.wmem_default=256960net.core.rmem_default=256960vm.max_map_count=262144
sysctl -p 重启使其生效;
- vi /etc/security/limits.conf
*soft nofile 204800*hard nofile 204800*soft nproc 204800*hard nproc 204800
- vi /proc/sys/kernel/pid_max
设置值为131072
1.4、为用户appuser授权
vi /etc/sudoers
增加如下一行信息后保存
appuser ALL=(ALL)NOPASSWORD:/bin/mount * /mnt/ramdisk,/bin/umount * /mnt/ramdisk,/bin/mkdir * /mnt/ramdisk,/bin/chmod * /mnt/ramdisk
2、Alluxio配置
2.1、配置文件
将alluxio-2.4.tar.gz压缩文件解压后,分别进行如下配置:
- 配置alluxio.properties
alluxio.master.hostname=hostIP
alluxio.worker.hostname=hostIP
alluxio.master.mount.table.root.ufs=s3a://s3-bucket #bucket
alluxio.underfs.s3.endpoint=http://minio-f5:9000/ #minio集群F5或者ng地址
alluxio.underfs.s3.disable.dns.buckets=true
alluxio.underfs.s3.inherit.acl=true
alluxio.underfs.s3.default.mode=0777
alluxio.user.file.metadata.sync.interval=0
aws.accessKeyId=minio #minio集群用户名
aws.secretKey=minio #minio集群密码
#HA
alluxio.master.embedded.journal.addres=192.168.1.11:19200,192.168.1.12:19200,192.168.1.13:19200 #master节点的地址列表
alluxio.zookeeper.enabled=true
alluxio.zookeeper.address=zk1:2181,zk2:2181,zk3:2181 #zookeeper集群地址
alluxio.master.journal.type=UFS
alluxio.master.journal.folder=/ods/data #或hdfs://, 存储master journal日志的路径, 必须所有节点能访问到的地址
alluxio.zookeeper.session.timeout=90 #需要保证Zookeeper部署设置maxSessionTimeout=90000
#Security
alluxio.underfs.s3.inherit.acl=false
alluxio.security.login.username=root
alluxio.security.authorization.permission.enabled=false
alluxio.security.authorization.permission.umask=000
alluxio.security.authorization.permission.supergroup=root
alluxio.user.file.delete.unchecked=true
alluxio.master.security.impersonation.root.users=*
alluxio.master.security.impersonation.root.groups=*
alluxio.master.security.impersonation.client.users=*
alluxio.master.security.impersonation.client.groups=*
#Memory
alluxio.worker.memory.size=20GB
alluxio.worker.tieredstore.levels=2
alluxio.worker.tieredstore.level0.alias=MEM
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk
alluxio.worker.tieredstore.level1.alias=SSD
alluxio.worker.tieredstore.level1.dirs.mediumtype=SSD
alluxio.worker.tieredstore.level1.dirs.path=/network/data #本地数据盘地址
alluxio.worker.tieredstore.level1.dirs.quota=150GB
#Network
alluxio.worker.block.heartbeat.interval=25sec
#Performance
alluxio.user.file.passive.cache.enabled=false
alluxio.user.block.master.client.pool.size.max=256
alluxio.user.file.master.client.pool.size.max=256
alluxio.user.file.replication.max=3
#Machine Learning
alluxio.user.metadata.cache.enabled=true
- 配置masters文件
vi masters 配置如下信息
192.168.1.11 192.168.1.12 192.168.1.13
- 配置workers
vi workers配置如下信息
192.168.1.11 192.168.1.12 192.168.1.13 192.168.1.14192.168.1.15
- 配置alluxio-env.sh
执行命令 cp alluxio-env-template.sh alluxio-env.sh
ALLUXIO_LOGS_DIR=/ALLUXIO_USER_LOGS_DIR=/ALLUXIO_MASTER_JAVA_OPTS="-Xms2G -Xmx2G"ALLUXIO_WORKER_JAVA_OPTS="-Xms4G -Xmx4G -XX:+UseG1GC -XX:InitiatingHeapOccupancyPercent=70 - XX:G1RSetUpdatingPauseTimePercent=5 -XX:MAXGCPauseMillis=500 -XX:ParallelGCThreads=16 -XX:ConcGCThreads=16"ALLUXIO_JOB_WORKER_JAVA_OPTS="-Xms2G -Xmx2G"
其他可选参数:
-XX: +PrintGCDetails-XX: +PrintGCDatestampsXX: +PrintHeapAtGC-XX: +PrintTenuringDistribution-XX: +PrintGCApplicationStoppedTime-XX: +PrintPromotionFailure#-XX: PrintFLSStatistics=1#-Xloggc: /applog/gc.log#-XX:HeapDumpPath:/heapdump-XX: +UseGCLogFileRotation-XX: NumberOfGCLogFiles=10-XX: GCLogFileSize=10M
2.2、格式化
首次启动alluxio前,必须先格式化所有master节点,执行命令为:
bin/alluxio formatMaster
2.3、启动
- 启动所有的masters和workers节点
bin/alluxio-start.sh all #不推荐 - 分别启动master或者worker(
推荐)
./alluxio-start.sh masters #启动所有masters节点,前提必须免密设置./alluxio-start.sh master #或单独启动master节点(未设置免密登录时)./alluxio-start.sh worker SudoMount #挂载woker,每台服务器(可根据具体需求)启动单个worker节点./allxio-start.sh job_master #job_worker依赖job_master,可以根据需要配置job_master节点个数,一般在所有master节点启动;./allxio-start.sh job_worker #一般在所有worker节点(可根据具体需求)启动job worker,用于文件服务(例如:内存文件持久化到文件服务器)
2.4、集群检查
浏览器正常访问:http://host:19999,注意host是masters三个节点中的某一个节点IP
配置完整性检查:bin/alluxio fsadmin doctor configuration

3、常用运维
3.1、停止Alluxio
要停止Alluxio服务,运行:
$ ./bin/alluxio-stop.sh all
这将停止conf/workers和conf/masters中列出的所有节点上的所有进程。
可以使用以下命令仅停止master和worker:
$ ./bin/alluxio-stop.sh masters # 停止所有conf/masters 的 masters
$ ./bin/alluxio-stop.sh workers # 停止所有conf/workers 的 workers
如果不想使用ssh登录所有节点来停止所有进程,可以在每个节点上运行命令以停止每个组件。 对于任何节点,可以使用以下命令停止master节点或worker节点:
$ ./bin/alluxio-stop.sh master # 停止 local master
$ ./bin/alluxio-stop.sh worker # 停止 local worker
一般建议如下:
$./bin/alluxio-stop.sh job_worker #停止job_worker
$./bin/alluxio-stop.sh job_master #停止job_master
$ ./bin/alluxio-stop.sh workers #停止所有workers
$ ./bin/alluxio-stop.sh master #待所有workers停止后,再分别停止master
3.2、重新启动Alluxio
与启动Alluxio类似,建议先清除alluxio.master.journal.folder目录下文件,如果已经配置了conf/workers和conf/masters,可以使用以下命令启动集群:
$ ./bin/alluxio-start.sh all
可以使用以下命令仅启动masters和workers:
$ ./bin/alluxio-start.sh masters # starts all masters in conf/masters
$ ./bin/alluxio-start.sh workers # starts all workers in conf/workers
如果不想使用ssh登录所有节点来启动所有进程,可以在每个节点上运行命令以启动每个组件。 对于任何节点,可以使用以下命令启动master节点或worker节点:
$ ./bin/alluxio-start.sh master # 开始 local master
$ ./bin/alluxio-start.sh worker # 开始 local worker一般建议如下:
清除alluxio.master.journal.folder目录下文件
$./bin/alluxio-start.sh masters #启动所有masters
$./bin/alluxio-start.sh worker #验证master启动成功后,再分别启动各个worker
有时出现文件访问异常,需要删除alluxio.master.journal.folder目录下文件,重新启动。
3.3、常用命令
- mkdir
./alluxio fs mkdir /tmp - chmod
./alluxio fs chmod 755 /tmp - ls
./alluxio fs ls /tmp - help
./alluxio fs help - upload file
./alluxio fs copyFromLocal /filePath/tmp.txt /tmp - persist
./alluxio fs persist /tmp
这篇关于【数据平台】之Alluxio内存加速S3文件系统数据利器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




