本文主要是介绍导师男团来袭 | 开源之夏2022,与Alluxio一起探索数据编排的奇妙世界,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
 活动简介
活动简介
开源之夏(英文简称 OSPP)是由“开源软件供应链点亮计划”发起并长期支持的一项暑期开源活动,今年是第三届,由中国科学院软件研究所与 openEuler 社区共同举办,旨在鼓励在校学生积极参与开源软件的开发维护,促进优秀开源软件社区的蓬勃发展,培养和发掘更多优秀的开发者。

活动联合国内外各大开源社区,针对重要开源软件的开发与维护提供项目任务,并面向全球高校学生开放报名。
学生可在本活动中自主选择感兴趣的项目任务进行申请,并在中选后获得该开源项目资深维护者(社区导师)亲自指导的机会,完成项目并贡献给社区后,参与学生还将获得开源之夏活动奖金和结项证书。

社区介绍
Alluxio系统是全球首个分布式超大规模数据编排系统,孵化于加州大学伯克利分校AMP实验室。自项目开源以来,已有超过来自300多个组织机构的1200多位贡献者参与开发,包括全球最头部科技公司、最顶尖的计算机科研院所等,现已成为发展最快的开源大数据项目之一。目前,全球十大互联网公司中已有包括Facebook、Airbnb、Uber、阿里巴巴、腾讯和字节跳动在内的八家企业部署了Alluxio,还有更多大型企业在生产中运行 Alluxio。
社区GitHub:https://github.com/Alluxio
Slack:https://alluxio-community.slack.com/
网站:https://www.alluxio.io/
除了了解Alluxio系统背景之外,Alluxio为本次“开源之夏”配备的导师男团也不容错过:
下面有请 Alluxio导师男团(自带BGM)

如需入群与以上导师沟通,请添加Alluxio小助手(VX:Alluxio_Tianyu),请备注“开源之夏”
项目介绍
【项目一】:优化和完善Alluxio数据编排开源项目的单元测试功能
【项目导师】:刘嘉承(jiacheng@alluxio.com),Alluxio 核心开发工程师,硕士毕业于哥伦比亚大学,目前就职于Alluxio公司研发团队核心组。发布了Alluxio K8s Helm Chart。参与并主导了一些Alluxio的RPC和内核优化工作。

【难度】:基础
【项目描述】:众所周知,一套设计良好的单元测试保证了开源项目的质量和可维护性。本项目重点在于加强Alluxio应用客户端的测试覆盖率和关键功能的正确性保障。我们希望通过本项目的任务,使得Alluxio开源项目的单元测试(unit test)质量得到进一步补充、完善和加强,通过单元测试保障已有功能,为未来的优化和拓展铺平道路。
【产出要求】:
- 针对Alluxio数据编排开源项目的单元测试功能进行优化和完善
- 至少包含三个以上优化和完善点
【技术要求】:
熟悉Java编程,分布式系统以及单元测试
更多项目信息:https://summer-ospp.ac.cn/#/org/prodetail/226ea0337
【项目】二:Alluxio数据编排系统的分布式缓存管理机制优化
【项目导师】:范斌(binfan@alluxio.com),Alluxio公司创始成员&开源社区副总裁。本科毕业于中科大计算机系,随后取得卡内基梅隆大学计算机博士学位。博士期间在分布式系统算法和系统实现等方向发表多篇包括SIGCOMM, SOSP, NSDI等顶级国际会议论文以及多篇专利。加入Alluxio前, 范斌在Google从事下一代大规模分布式存储系统的研究与开发,曾获得谷歌年度技术奖。

【项目描述】:分布式缓存是Alluxio数据编排开源项目的重要特性之一。而如何有效利用和管理各个worker上的缓存空间则成为了影响分布式缓存性能的关键因素。我们在本项目中希望针对现有的缓存清空机制进行功能上的拓展,分两个维度:(1)在现有默认的异步清空操作的基础上,增加支持“同步”清空操作的功能可选项;(2)在现有默认针对所有worker统一执行清空操作的基础上,增加“可指定”若干特定worker实施清空操作。
【难度】:进阶
【产出要求】:
针对Alluxio数据编排系统现有的缓存清空机制从两个维度进行功能上的拓展:
- 增加支持“同步”清空操作的功能;
- 增加“可指定”若干特定worker实施清空操作。
【技术要求】:
熟悉Java编程,分布式缓存
更多项目信息:https://summer-ospp.ac.cn/#/org/prodetail/226ea0340
针对以上2个学生项目,我们除了配备专门导师,还会有男团其他成员全程助力,同时社区的其他专家也会给予项目辅导与支持。
参与方式
学生自由选择项目,与社区导师沟通实现方案并撰写项目计划书。被选中的学生将在社区导师指导下,按计划完成开发工作,并将成果贡献给社区。社区评估学生的完成度,主办方根据评估结果发放活动奖金给学生。
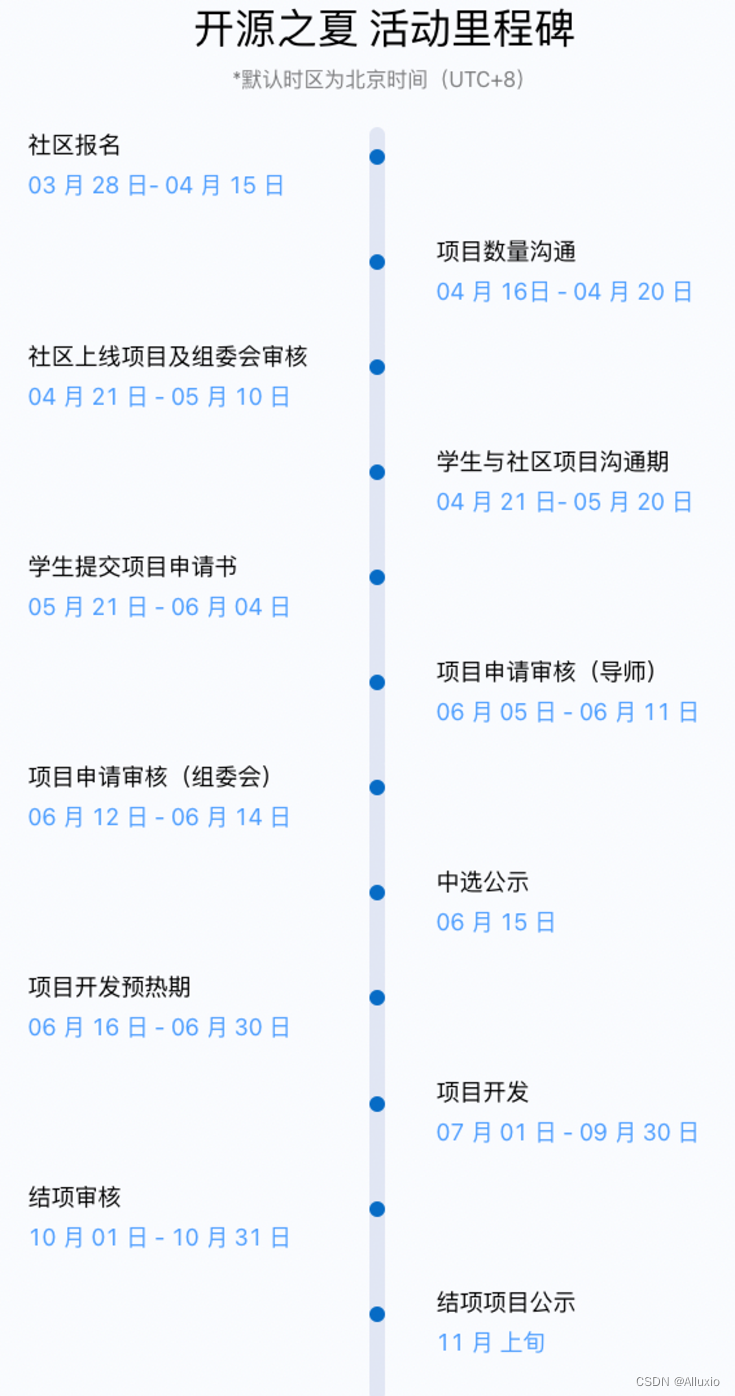
活动日程
课题项目将于 5 月 21 日开始正式接受学生申请,当前正处于「学生与社区项目沟通期」,欢迎大家进群咨询相关事宜,与项目导师线上交流沟通。
与导师沟通
目前Alluxio的2个项目已经成功发布,正式进入学生与导师沟通阶段,各位学生如果对上述项目感兴趣,欢迎你加入Alluxio开源社区的开源之夏项目交流群,与对应导师及社区专家进行沟通交流。
【群聊加入方式】:
方式一:扫描下方二维码(如二维码失效,请采用第二种方式)
方式二:请添加Alluxio小助手(VX:Alluxio_Tianyu),请备注“开源之夏”

这篇关于导师男团来袭 | 开源之夏2022,与Alluxio一起探索数据编排的奇妙世界的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






