本文主要是介绍PPYOLO垃圾检测+地平线旭日X3派部署(上),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.项目介绍
不管在城市场景还是家庭场景中,都会存在一些不规则垃圾。如何帮助机器人识别这些垃圾,成了计算机视觉一个重要问题。基于PPYOLO算法,本项目针对这些垃圾设计了一个目标检测模型,只检测单一类别的垃圾。并且利用地平线旭日X3派5TPOS的算力,和地平线机器人开发平台的快捷部署能力进行部署。后续可以配合机器人用于垃圾寻找、垃圾捡取(配合机械臂)的APP设计。
最终部署效果:

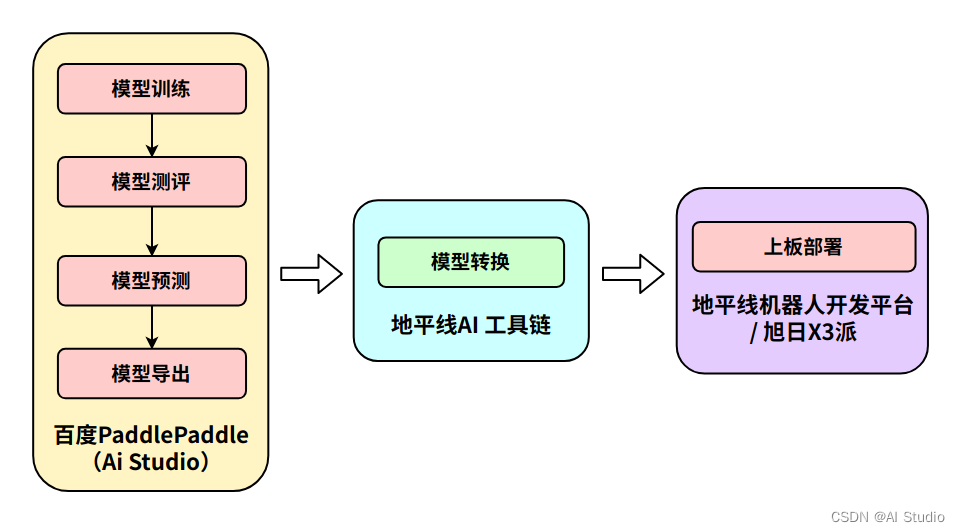
整体开发部署流程图:
PPYOLO算法:https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.5/configs/ppyolo
本文所用配置:https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.5/configs/ppyolo/ppyolo_r18vd_coco.yml
本文参考项目:https://aistudio.baidu.com/aistudio/projectdetail/3846170
2. 模型训练
2.1 数据集设置
项目采用TACO数据集中150张城市场景的垃圾数据集
部分数据预览

数据集将配置为COCO格式,将数据集放到 PaddleDetection/datasets/MiniTACO 目录下。
修改配置文件 PaddleDetection/configs/datasets/coco_detection.yml 如下:
metric: COCO
num_classes: 1TrainDataset:!COCODataSetimage_dir: Imagesanno_path: Annotations/train.jsondataset_dir: dataset/MiniTACOdata_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']EvalDataset:!COCODataSetimage_dir: Imagesanno_path: Annotations/val.jsondataset_dir: dataset/MiniTACOTestDataset:!ImageFolderimage_dir: Imagesanno_path: Annotations/test.jsondataset_dir: dataset/MiniTACO 2.2 环境配置
# 1) 环境配置
cd work/PaddleDetection
pip install -r requirements.txt
python setup.py install
2.3 模型训练
直接基于ppyolo_r18vd_coco.yml默认配置选项进行模型训练,在终端运行:
# 2) 模型训练
python tools/train.py -c configs/ppyolo/ppyolo_r18vd_coco.yml --eval
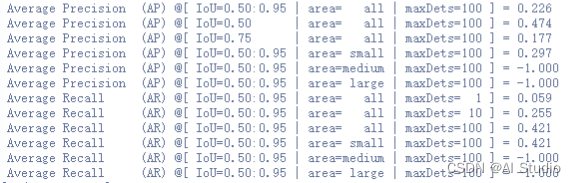
3. 模型评估
在终端运行:
# 3)模型评估
python tools/eval.py -c configs/ppyolo/ppyolo_r18vd_coco.yml -o use_gpu=true weights=output/ppyolo_r18vd_coco/best_model.pdparams
评估结果:
4. 模型预测
可对训练结果进行可视化,感受模型训练效果。
# 4) 模型预测
# 单张图片预测
python tools/infer.py -c configs/ppyolo/ppyolo_r18vd_coco.yml --infer_img=dataset/MiniTACO/Images/trashDet0028.jpg -o weights=output/ppyolo_r18vd_coco/best_model.pdparams# 多张图片预测
python tools/infer.py -c configs/ppyolo/ppyolo_r18vd_coco.yml --infer_dir=dataset/MiniTACO/Images --output_dir output/results -o weights=output/ppyolo_r18vd_coco_best_best/best_model.pdparams
预测结果:

5. 模型导出
5.1 Paddle模型导出
由于Paddle模型导出包含了模型后处理部分,而地平线dnn处理只对模型部分进行BPU转换,因此需要Paddle模型进行处理。
5.1.1 PaddleDetection输出调整
主要分为两步:去掉检测后处理部分(NMS)、调整输出各通道位置
- 去掉检测后处理(NMS)
文件路径:PaddleDetection/ppdet/modeling/architectures/yolo.py
做法:在测试阶段,检测头输出后直接对模型输出,在脚本中添加内容如下注释区域:
class YOLOv3(BaseArch):def __init__(self,......export_onnx=False):self.export_onnx = export_onnx......def _forward(self):body_feats = self.backbone(self.inputs)neck_feats = self.neck(body_feats, self.for_mot)if isinstance(neck_feats, dict):assert self.for_mot == Trueemb_feats = neck_feats['emb_feats']neck_feats = neck_feats['yolo_feats']if self.training:......else:yolo_head_outs = self.yolo_head(neck_feats)### horizon output ###if self.export_onnx:return yolo_head_outs### -------------- ###......
- 调整输出各通道位置
文件路径:PaddleDetection/ppdet/modeling/heads/yolo_head.py
做法:原检测头输出对应[N, C, H, W]格式,需要转为[N, H, W, C]格式输出,与地平线机器人开发平台现有的解析方式匹配。在脚本中添加内容如下注释区域:
class YOLOv3(BaseArch):def __init__(self,......export_onnx=False):self.export_onnx = export_onnx......def forward(self, feats, targets=None):assert len(feats) == len(self.anchors)yolo_outputs = []for i, feat in enumerate(feats):yolo_output = self.yolo_outputs[i](feat)......### horizon output ###if self.export_onnx:yolo_output = paddle.transpose(yolo_output, perm=[0, 3, 2, 1])yolo_output = paddle.transpose(yolo_output, perm=[0, 2, 1, 3])### -------------- ###yolo_outputs.append(yolo_output)
备注:以上两次transpose的做法其实等效于 yolo_output = paddle.transpose(yolo_output, [0, 3, 1, 2]) 。但在实际操作中无法实现,疑似为PaddlePaddle本身的bug。
5.1.2 导出Paddle模型
为方便导出模型,可对5.2.1 修改内容设置 export_onnx 开关,导出Paddle模型:
(备注:导出文件路径 PaddleDetection/inference_model/ppyolo_r18vd_coco/model.pdmodel)
# 5) 模型导出
python tools/export_model.py -c configs/ppyolo/ppyolo_r18vd_coco.yml \-o weights=output/ppyolo_r18vd_coco/best_model.pdparams \YOLOv3.export_onnx=True \YOLOv3Head.export_onnx=True \TestReader.inputs_def.image_shape=[1,3,416,416] \--output_dir inference_model
5.2 导出ONNX模型
5.2.1 环境安装
目前官方提供的paddle2onnx方法,由于最新版本不支持转换onnx < 1.6 的版本,因此使用此前的版本进行安装。并且将onnx安装目录下的三个文件替换到paddle2onnx安装目录下:
- onnx/onnx_ONNX_REL_1_6_ml_pb2.py ——> paddle2onnx/onnx_helper/onnx_ONNX_REL_1_6_ml_pb2.py
- onnx/onnx.proto ——> paddle2onnx/onnx_helper/onnx.proto
- onnx/onnx_pb.py ——> paddle2onnx/onnx_helper/onnx_pb.py
在终端执行命令:
# 6) ONNX环境安装
pip install paddle2onnx==0.7
pip install onnx==1.6cp /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/onnx/onnx_ONNX_REL_1_6_ml_pb2.py /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle2onnx/onnx_helper/onnx_ONNX_REL_1_6_ml_pb2.py
cp /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/onnx/onnx.proto /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle2onnx/onnx_helper/onnx.proto
cp /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/onnx/onnx_pb.py /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle2onnx/onnx_helper/onnx_pb.py
5.2.2 导出ONNX模型
在终端执行命令,导出ppyolo.onnx模型:
# 6) 导出ONNX模型
paddle2onnx --model_dir inference_model/ppyolo_r18vd_coco \--model_filename model.pdmodel \--params_filename model.pdiparams \--opset_version 11 \--save_file inference_model/ppyolo.onnx
5.2.3 修改ONNX模型输入数量N
ONNX模型导出后默认N = -1,而实际模型部署时需要确保N = 1,因此需要对ONNX模型修改。
配置 changeonnx.py 修改脚本:
import onnxdef change_input_dim(model):actual_batch_dim = 1graph = model.graphnodes = list(graph.input) + list(graph.value_info) + list(graph.output)for node in nodes:if not len(node.type.tensor_type.shape.dim):continueif node.type.tensor_type.shape.dim[0].dim_value == -1:print(node)node.type.tensor_type.shape.dim[0].dim_value = actual_batch_dimdef apply(transform, infile, outfile):model = onnx.load(infile)transform(model)onnx.save(model, outfile)apply(change_input_dim, "inference_model/ppyolo.onnx", "inference_model/ppyolo.onnx")
直接在终端运行脚本:
# 7) onnx模型修改
python changeonnx.py
小结
至此,在百度AI studio上相关工作已完成,导出的ppyolo.onnx模型。
后续如何在地平线旭日X3派部署运行?请参考下一篇教程
PPYOLO垃圾检测+地平线旭日X3派部署(下)
地平线机器人开发平台部署示例(敬请期待)
此文章为搬运
原项目链接
这篇关于PPYOLO垃圾检测+地平线旭日X3派部署(上)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







