本文主要是介绍『青年AI自强计划』第6章视觉分类任务LeNet5,AlexNet,ZFNet,VGG,GoogleNet,ResNet,ResNeXt,SENet,MobileNet!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
| 视觉分类任务 |
文章目录
- 一、分类任务简介
- 1.1、分类发展简史
- 二、卷积知识回顾
- 2.1、卷积运算
- 2.2、池化运算
- 2.3、padding运算
- 2.4、三维卷积(池化)
- 2.5、LeNet5 :一切的原点
- 三、AlexNet&ZFNet
- 3.1、AlexNet(2012):深度CNN与BD的首次触电
- 3.2、ZFNet(2013):过渡,对AlexNet小调整
- 四、VGG(2014):“标准模块+堆叠”
- 4.1、VGG16 :“堆叠” block
- 4.2、两个3×3的卷积核替代5×5(三个3×3卷积核替代7×7)分析
- 4.2.1、两个3x3的卷积核替代5x5的卷积核
- 4.2.2、三个3x3的卷积核替代7x7的卷积核
- 4.2.3、优点总结
- 五、GoogleNet :关键词“手动定制”
- 5.1、GoogleNet-Iception V1(2014)
- 5.2、Inception V3 卷积核分解
- 5.3、网络可以有多深?
- 六、ResNet(2015):打破限制,超越人类
- 七、ResNeXt&SENet
- 7.1、ResNeXt(2016):ResNet Plus升级版
- 7.2、SENet(2017):集大成者
- 八、各种网络对比图
- 九、小结&模型压缩
- 9.1、小结
- 9.2、模型压缩:Deep Compression
- 9.3、网络可以有多快?
- 十、MobileNet:轻量化(参数少)
一、分类任务简介

1.1、分类发展简史

二、卷积知识回顾
2.1、卷积运算

2.2、池化运算

2.3、padding运算
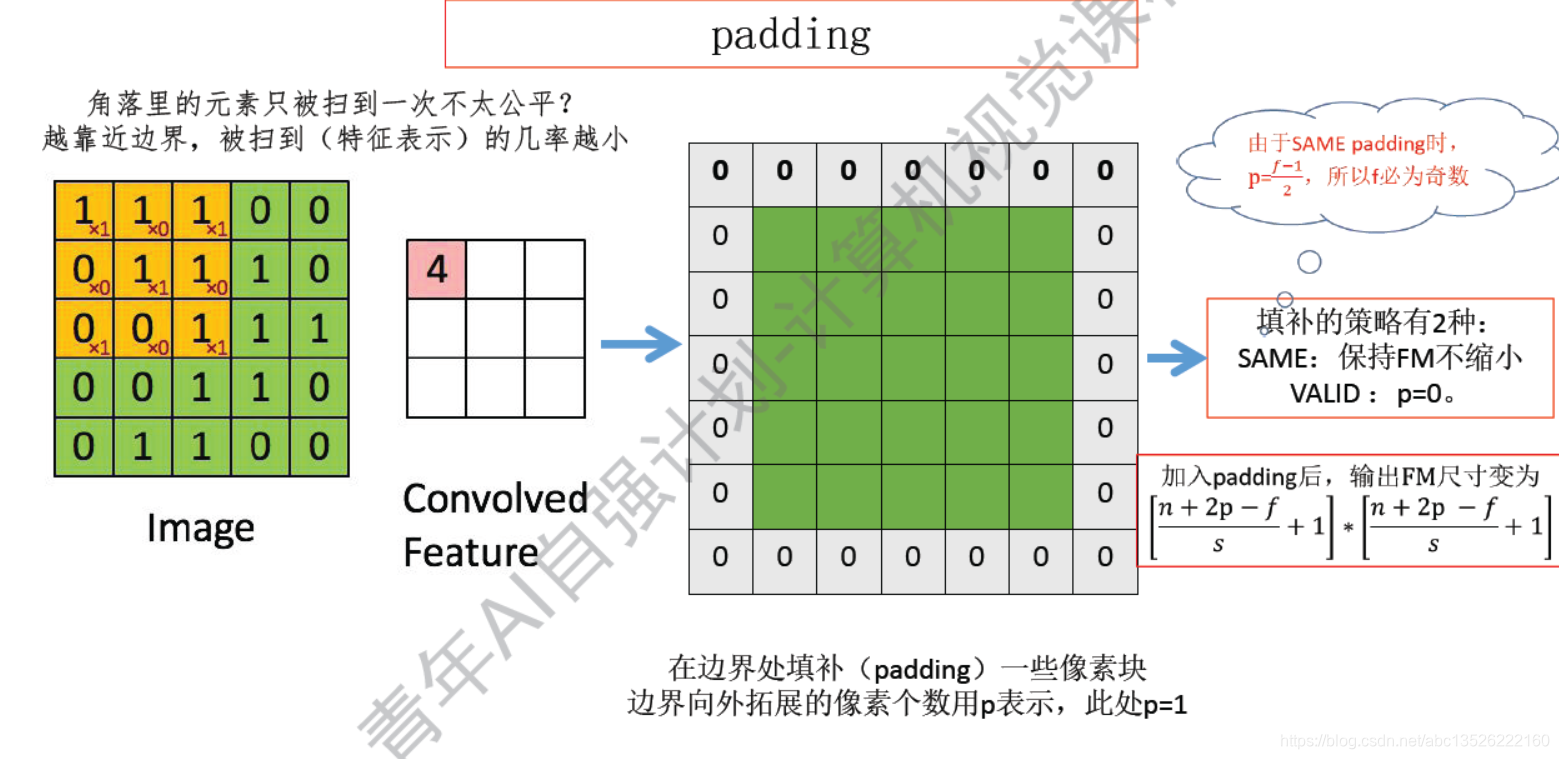
2.4、三维卷积(池化)

2.5、LeNet5 :一切的原点

三、AlexNet&ZFNet
3.1、AlexNet(2012):深度CNN与BD的首次触电

注意:dropout现在在陆续退出历史舞台,因为大家发现参数初始化的足够好,用了batch_norm的话,可能没有必要使用dropout了,这是一个趋势!
3.2、ZFNet(2013):过渡,对AlexNet小调整

注意:红色框标记的是和AlexNet网络的不同之处,区别不大! 参数:模型本身选择的参数例如权重W,其他都是超参数了!
- 第二层中由于第一层卷积用的步长为4太大了,导致了有非常多的混叠情况;因此改变了AlexNet的第一层即将滤波器的大小11x11变成7x7,并且将步长4变成了2,下图为AlexNet网络结构与ZFNet的比较。在稍微更改了第一层之后,分类性能提升了。
四、VGG(2014):“标准模块+堆叠”

4.1、VGG16 :“堆叠” block

注意:一个7×7的卷积核等价3个3×3卷积核,全部换成3×3的卷积核。实际等价是比较难得。有2个好处:
- 多经过了2个激活函数(过得激活函数越多等于越能把决策边界描述的越细致)!
- 选择参数量减少了!
4.2、两个3×3的卷积核替代5×5(三个3×3卷积核替代7×7)分析
4.2.1、两个3x3的卷积核替代5x5的卷积核
- 知道了一个理论,两个3x3的卷积核替代5x5的卷积核,可以减少计算量,且最终的计算结果是一样的,但是为什么呢?
**一个5*5卷积**
我们使用5*5的卷积核对其卷积,步长为1,不填充
根据计算公式[(n+2*p-f)/2 + 1]向下取整。
得到的结果是:(32-5)/1+1=28
**两个3*3卷积核**
然后我们使用2个卷积核为33的,这里的两个是指进行2层33的卷积:
第一层3*3:
得到的结果是[(32-3)/1+1]=30
第二层3*3:
得到的结果是[(30-3)/1+1]=28
所以我们的最终结果和5x5的卷积核是一样的,都是28。
一个55的计算量为 5x5xchannels = 25xchannels;
两个33的计算量为 3x3xchannels*2 = 18xchannels
明显,两个3x3的卷积的计算量小于一个5x5卷积的计算量
4.2.2、三个3x3的卷积核替代7x7的卷积核
- 同理,一个7x7的卷积核可以用三个个3x3的卷积核来替代。我们假设图片是32*32的
一个7*7卷积
我们使用5*5的卷积核对其卷积,步长为1,不填充
根据计算公式[(n+2*p-f)/2 + 1]
得到的结果是:(32-7)/1+1=26
三个3*3卷积核
然后我们使用2个卷积核为33的,这里的两个是指进行2层33的卷积:
第一层3*3:
得到的结果是(32-3)/1+1=30
第二层3*3:
得到的结果是(30-3)/1+1=28
第三层3*3:
得到的结果是(28-3)/1+1=26
所以我们的最终结果和7x7的卷积核是一样的,都是26。可以互相替换。
一个7x7的计算量为7x7xchannels = 49xchannels;
两个3*3的计算量为 3x3xchannelsx3 = 27xchannels
所以,三个3x3的卷积的计算量小于一个7x7卷积的计算量
以上是我的理解,如有其它更通俗的理解,欢迎指教。
4.2.3、优点总结
- 堆叠含有小尺寸卷积核的卷积层来代替具有大尺寸的卷积核的卷积层,并且能够使得感受野大小不变,而且多个3x3的卷积核比一个大尺寸卷积核有更多的非线性(每个堆叠的卷积层中都包含激活函数),使得decision function更加具有判别性。
五、GoogleNet :关键词“手动定制”

注意:Inception是什么呢(盗梦空间的英文名字)?看成一个黑盒子,本质为特征提取器,展开为:不同尺寸的卷积层,还有池化层,先用1×1卷积核改变通道数,这里为降低通道的维度。看图说!超参数越多,人设计的时候考虑越多!
5.1、GoogleNet-Iception V1(2014)

- GoogleNet家族

注意:V2版本看图中间,除了1×1的卷积核,其他都换成3×3的标准卷积核了。
5.2、Inception V3 卷积核分解

5.3、网络可以有多深?

注意:网络过深错误率上升了?为啥:网络退化!
- 网络退化

- 网络退化的原因?

注意:网络退化的原因:上面一些论文这方面的,我给一个感性的解释:在越多维的空间中画出决策边界越难!
六、ResNet(2015):打破限制,超越人类
 图2
图2  图3:ResNet注意的事项
图3:ResNet注意的事项 
注意:residual block残差块,ResNet其中的Res就是代表残差,残差是什么意思呢?
就是上面第一图中,卷积直接短接了(短路的连接!),一旦短接了,里面的卷积叫做残差了。
- 将输入的浅层信号直接输出特征集合,元素相加,图1中的右侧。
- 这要求:输出的feature map(FP),必须和输入FP的尺寸完全相等。
- 假设起这个短接线名字叫做废物检测器,意思就是接上之后(短接),中间的卷积单元证明是不是废物,如果不是废物的情况下:通过反向传播会学到一些有用的特征,参数值就会改变,左侧的恒等连接(短接)就没与那么重要了;如果这是废物的情况下:参数自己就学成0了。所以信号传输过来它真的是一个废物,他直接从上面的恒等连接(短接)传输走了。所以这个残差单元是有效的!
- 两种版本,ResNet34借鉴VGG中图2中的左侧。ResNet50右侧借鉴GoogleNet,借鉴的网络不通。
七、ResNeXt&SENet
7.1、ResNeXt(2016):ResNet Plus升级版

注意:借鉴了VGG和GoogleNet。进行了融合!

7.2、SENet(2017):集大成者



注意:这是ImageNet 的最后一次比赛。2010年开始的。
- 之前的网络没有学习通道特征,平均池化。图1中。
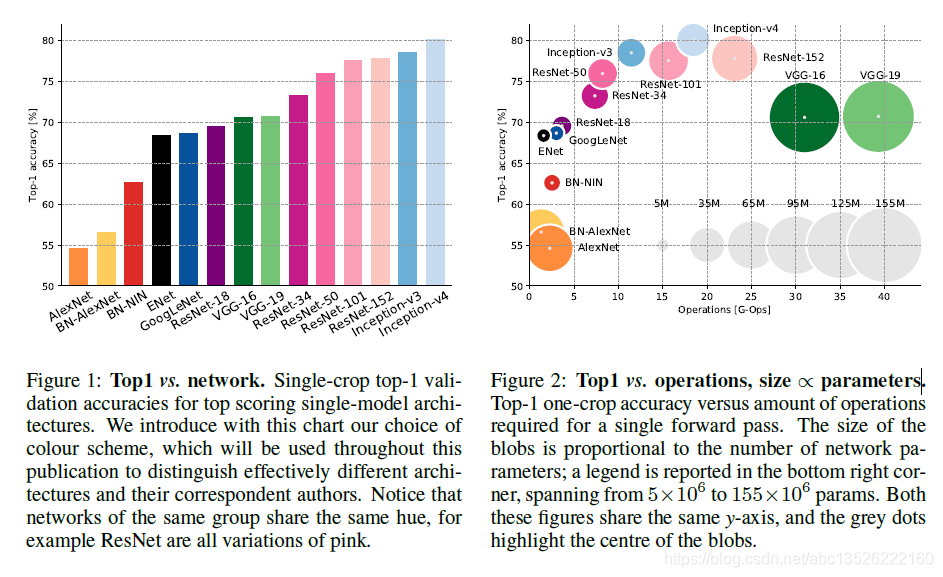
八、各种网络对比图
- 图中的坐标轴我们可以看出横坐标是操作的复杂度,纵坐标是精度。模型设计一开始的时候模型权重越多模型越大,其精度越高,后来出现了resNet、GoogleNet、Inception等网络架构之后,在取得相同或者更高精度之下,其权重参数不断下降。值得注意的是,并不是意味着横坐标越往右,它的运算时间越大。在这里并没有对时间进行统计,而是对模型参数和网络的精度进行了纵横对比。
- 从图中我们可以看出来,AlexNet一类的模型没有考虑太多权重参数的问题,因此圆圈比较大。一开始AlexNet只是希望用深度网络能够找到更多图像当中的高维特征,后来发现当网络越深的时候需要的参数越多,硬件总是跟不上软件的发展,这个时候如果加深网络的话GPU的显存塞不下更多的参数,因此硬件限制了深度网络的发展。为了能够提高网络的深度和精度,于是大神们不断地研究,尝试使用小的卷积核代替大的卷积核能够带来精度上的提升,并且大面积地减少参数,于是网络的深度不再受硬件而制约。
可是另外一方面,随着网络的深度越深,运算的时间就越慢,这也是个很蛋疼的事情,不能两全其美。作者相信在未来2-3年我们能够亲眼目睹比现有网络更深、精度更高、运算时间更少的网络出现。因为硬件也在快速地发展,特斯拉使用的NVIDIA Driver PX 2的运算速率已经比现在Titan X要快7倍。
九、小结&模型压缩
9.1、小结


注意:并不是网络深度越高精度越高,也不是参数越多精度越高,真正发挥左右的是“参数效率”!
- 下面一个分支:之前一直考虑精度,之前运行在GPU资源。现在人手一部手机,比如人脸识别在手机上进行,还比如自动驾驶,这些设备算力比较小,和手机相当的水平。
- 所以从2016年开始,分类这件事已经超过人类了,新的需求来了,想保证预测精度不太下降的情况下,减少参数让模型跑的更快,有两种方法:一种是模型压缩,不改变网络设计,比如还用VGG,直接在训练的网络上压缩一下,压缩的足够小,就可以使用了;一种是抛弃之前的网络街结构,从新设计一个轻量级网络结构。
9.2、模型压缩:Deep Compression



9.3、网络可以有多快?



十、MobileNet:轻量化(参数少)


注意:这是特殊的网络的设计2017年,它也涉及一个特殊的卷积姿势。
参考文献:
- 清华大学AI自强计划
这篇关于『青年AI自强计划』第6章视觉分类任务LeNet5,AlexNet,ZFNet,VGG,GoogleNet,ResNet,ResNeXt,SENet,MobileNet!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




