本文主要是介绍论文慢递2:PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- abstract
- 方法
- 模型结构
- 基于混淆集的掩码策略
- 嵌入层
- Encoder层
- Output层
- 训练方法
- finetune
abstract
将拼写错误知识加入到预训练掩码语言模型,使用修正混淆集来代替预测掩码,加入语音级和字形级信息来辅助模型学习纠错;
方法

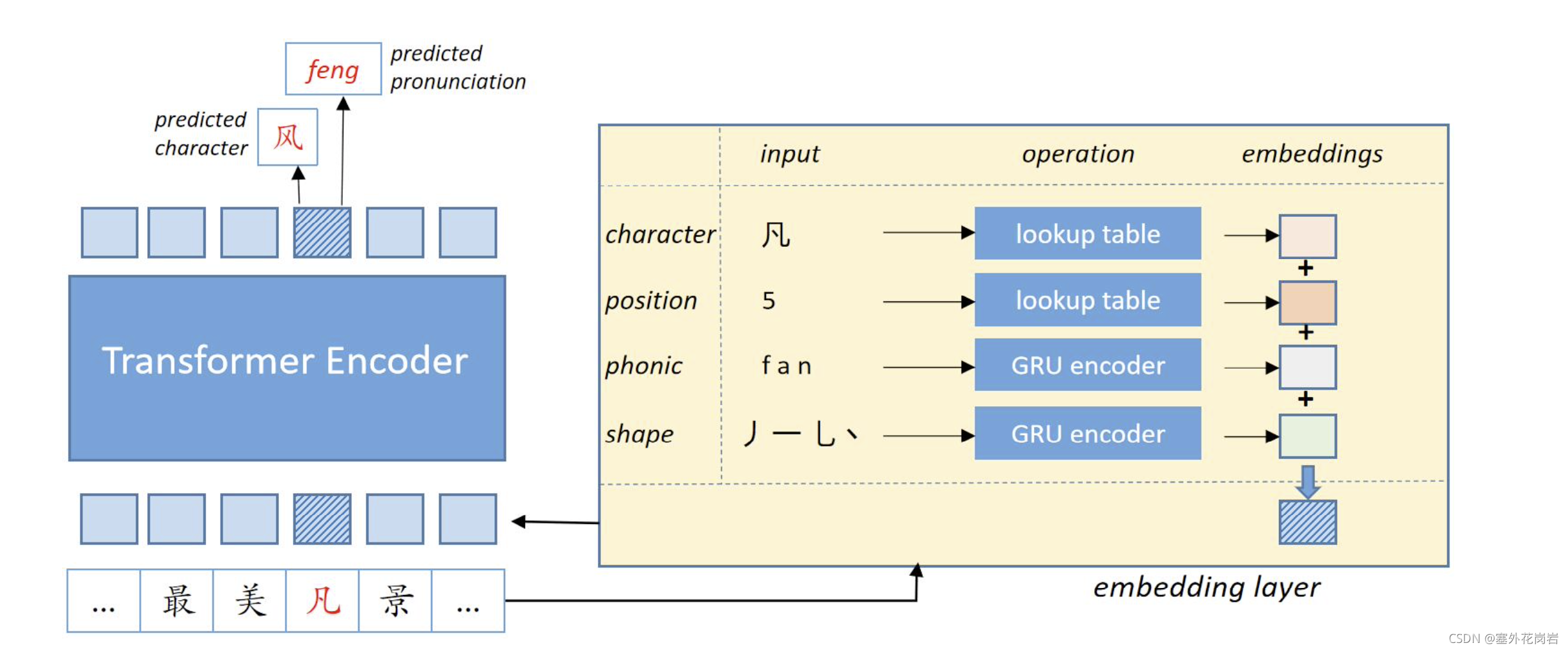
模型结构
将拼音与笔画加入embedding层辅助
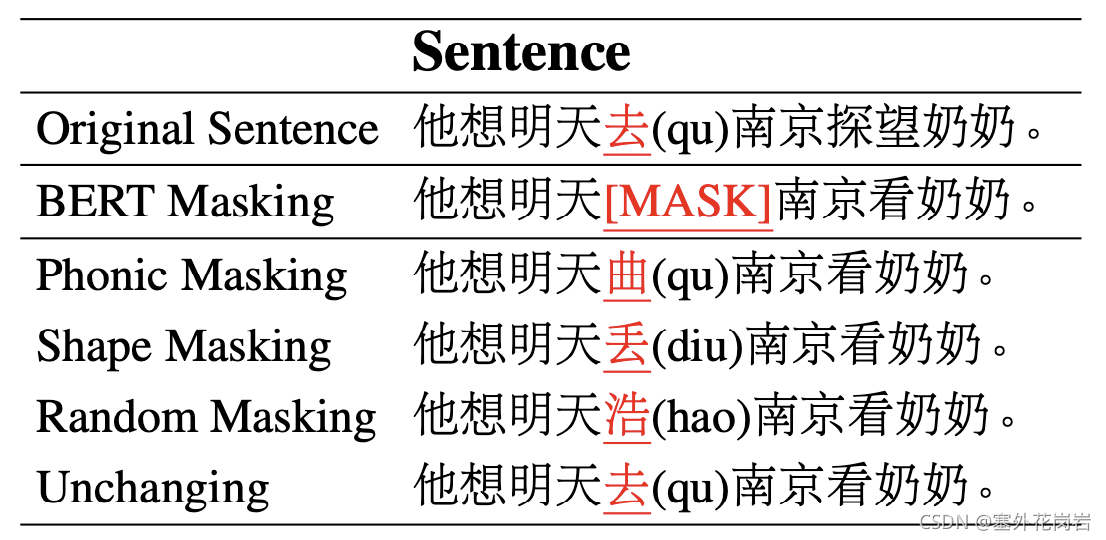
基于混淆集的掩码策略
相较于bert直接MASK,采用混淆集辅助MASK,通过形近和音近字进行掩码使模型纠错有的放矢;除此之外,为了增加模型鲁棒性,还有概率进行随机掩码;为了防止模型总是倾向于纠错,也有概率维持不变;
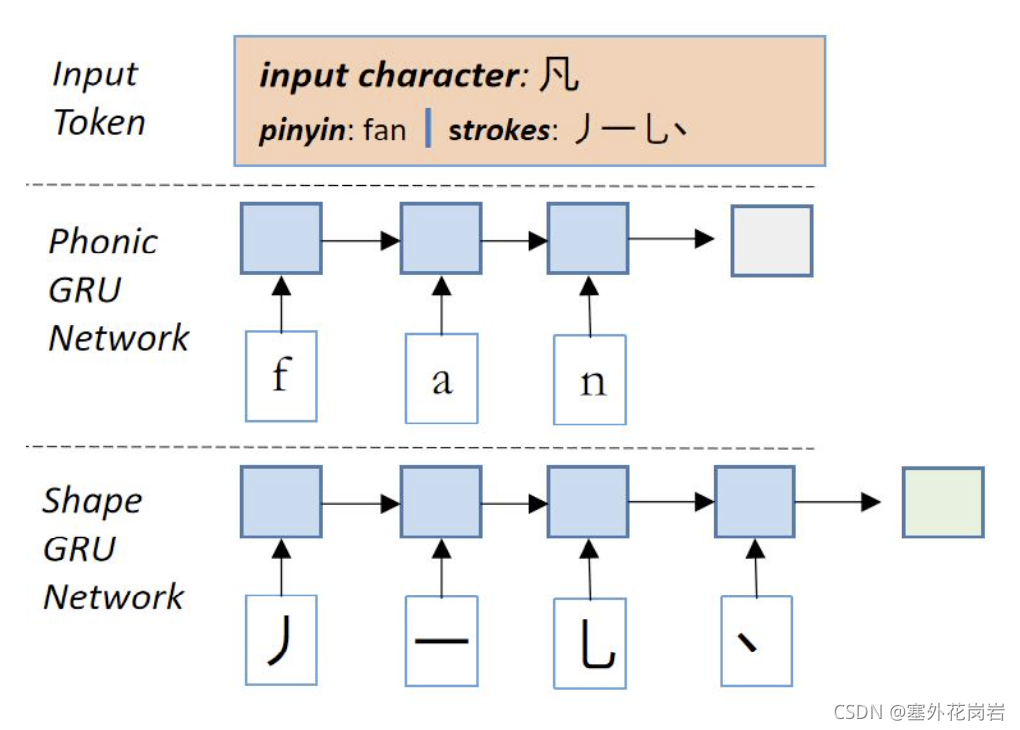
嵌入层
通过GRU编码字音与字形信息(通过拼音与笔画)
Encoder层
基本与BERT相同
Output层
由上文中的模型结构图可知,模型对字的字形与字音均进行了预测;
- 对于字形预测,预测正确的概率为
p c ( y i = j ∣ X ) = s o f t m a x ( W c h i + b c ) [ j ] p_c(y_i=j|X)=softmax(W_ch_i+b_c)[j] pc(yi=j∣X)=softmax(Wchi+bc)[j] - 对于拼音预测,预测正确概率为:
p p ( g i = k ∣ X ) = s o f t m a x ( W p h i + b p ) [ k ] p_p(g_i=k|X)=softmax(W_ph_i+b_p)[k] pp(gi=k∣X)=softmax(Wphi+bp)[k]
训练方法
分为字形与拼音损失:
L c = − ∑ i = 1 n l o g p c ( y i = l i ∣ X ) L_c=-\sum_{i=1}^n log p_c(y_i=l_i|X) Lc=−i=1∑nlogpc(yi=li∣X)
L p = − ∑ i = 1 n l o g p p ( g i = r i ∣ X ) L_p=-\sum_{i=1}^n log p_p(g_i=r_i|X) Lp=−i=1∑nlogpp(gi=ri∣X)
训练阶段损失为:
L = L c + L p L=L_c+L_p L=Lc+Lp
finetune
训练参照训练方法,预测阶段采用两概率乘积表示该字最终概率:
p j ( y i = j ∣ X ) = p c ( y i = j ∣ X ) × p p ( g i = j p ∣ X ) p_j(y_i=j|X)=p_c(y_i=j|X)\times p_p(g_i=j^p|X) pj(yi=j∣X)=pc(yi=j∣X)×pp(gi=jp∣X)
最终联合概率分布可以表示为:(其中 I ∈ R n c × n p I \in R^{n_c \times n_p} I∈Rnc×np )
p j ( y i ∣ X ) = [ p p ( g i ∣ X ) ⋅ I T ] ⊙ p c ( y i ∣ X ) p_j(y_i|X)=[p_p(g_i|X)\cdot I^T]\odot p_c(y_i|X) pj(yi∣X)=[pp(gi∣X)⋅IT]⊙pc(yi∣X)
这篇关于论文慢递2:PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)