本文主要是介绍Graph-Evolving Meta-Learning for Low-Resource Medical Dialogue Generation翻译,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
具有良好结构化医学知识的人类医生仅需通过与患者的几次对话就能诊断出疾病。相比之下,现有的基于知识的对话系统通常需要大量的对话样例来学习,因为它们无法捕获不同疾病之间的相关性,而忽略了其中共享的诊断经验。为了解决这个问题,我们提出了一个更自然,更实用的范式,即低资源医疗对话生成,可以将诊断经验从源疾病转移到具有少数数据目标疾病。它在常识知识图上大写,以表征先前的疾病症状关系。此外,我们开发了一种 Graph-Evolving Meta-Learning
(GEML) 框架,该框架学会了在常识图推理新疾病和其它症状的关系,从而有效地减轻了大量对话的需求。更重要的是,通过动态进化的疾病症状图,GEML还很好地解决了现实世界存在的挑战,即每种疾病的疾病症状关系可能随着更多的诊断病例增加而改变或进化。在CMDD数据集和我们新收集的Chunyu数据集上的广泛实验结果证明了我们的方法优于SOTA方法。此外,我们的GEML可以以在线方式生成丰富的对话敏感知识图,这也可以使其他基于知识图的任务受益。
1.介绍
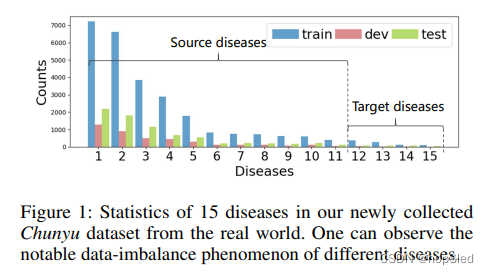
医疗对话系统(MDS)旨在通过与患者交谈,来询问不存在自我报告中的其他症状并自动进行诊断,这引起了研究员的广泛关注。它具有简化诊断过程并减轻从患者收集信息的成本的重要潜力。此外,MDS产生的初步诊断报告可能会帮助医生更有效地进行诊断。由于这些巨大的好处,许多研究人员致力于解决MDS中的关键子问题以建立令人满意的MDS,例如自然语言理解,对话策略学习,对话管理。
医疗对话生成(MDG)在MDS中至关重要,但很少研究,该任务以自然语言的形式生成请求症状或做出诊断的语句。传统的对话生成模型通常采用神经序列建模,并且在缺乏医学知识的情况下无法直接应用于医疗对话场景。最近,在大规模无监督语料库上训练的预训练语言模型取得了巨大的成功。但是,在医学领域中对大型语言模型进行微调需要足够的特定于任务的数据,以学习疾病与症状之间的相关性。不幸的是,如图1所示,有很大一部分疾病在现实中中只有少数几个样例,这意味着在现实诊断场景中新出现的疾病通常处于低资源条件。因此,非常希望将诊断经验从高资源疾病转移到其他数据稀缺的疾病。此外,现有的基于知识的方法可能无法很好地执行此类迁移,因为它们仅学习所有疾病的统一模型,而忽略了不同疾病的特殊性和关系。最后,在实践中,每种疾病的疾病症状关系可能会随着更多病例而变化或进化,这在先前的工作中也不曾考虑。
Contributions:
(1)我们首先为低资源医疗对话生成提出了一种端到端的对话系统。该模型无缝集成了三个组件,分层上下文编码器,元知识图推理(MGR)网络和图指导的响应生成器。其中,上下文编码器将对话编码为层次表示。对于MGR,它主要包含一个参数化的元知识图,该图由先验常识图初始化,表征了疾病和症状之间的相关性。当融入上下文信息时,MGR可以适应进化其元知识图以推理疾病症状相关性,然后在下一个响应中预测患者的相关症状以进一步确定疾病。最后,响应生成器在元知识图的指导下生成了症状请求的响应。
(2)第二个贡献是,我们进一步提出了一种新的Graph-Evolving Meta-Learning (GEML) 框架,以在低资源场景中迁移诊断经验。首先,GEML在元学习框架下训练上述医学对话模型。它将少量对话的响应生成看作是一项任务,并学习上述对话模型的初始化参数,该模型可以通过在有限的对话数据快速适应新的疾病诊断。通过这种方式,学习的模型参数包含来自所有源疾病的足够的元知识,并且可以作为良好的模型初始化参数,以快速将元知识迁移到新疾病中。更重要的是,GEML还学到了MGR模块中良好的参数化元知识图,以表征来自源疾病的疾病症状关系。具体而言,在元学习框架下,对于每种疾病,GEML通过在线对话示例构造全局症状图来丰富元知识图。通过这种方式,学到的元知识图可以弥补常识医学图和真实诊断对话之间的差距,因此可以快速适应新的目标疾病。随着图的进化,对话模型可以更有效地请求患者潜在的症状,从而提高诊断准确性。此外,GEML还可以很好地应对现实世界中的挑战,即疾病 - 症状相关性可能会随着更多情况而变化,因为元知识图是根据收集的对话示例训练的。
(3)最后,我们构建了一个名为Chunyu的大型医学对话数据集。它完全涵盖了15种疾病和12,842种对话示例,并且比现有的CMDD医学对话数据集大得多。更具挑战性的基准可以更好地评估医学对话系统的性能。在两个数据集上的广泛实验结果表明,我们的方法优于目前最新的方法。
2.相关工作
Medical Dialogue System (MDS)。关于MD的最新研究主要集中在基于pipline对话系统中的自然语言理解(NLU)或对话管理(DM)模块。已经有大量关于NLU问题的研究,以改善MDS性能,例如实体推理,症状抽取和槽填充。对于医疗对话管理,大多数工作都专注于基于面向任务对话系统的强化学习(RL)。Wei et al. (2018) 提出使用RL学习对话策略,以促进自动诊断。Xu et al. (2019) 通过RL将知识推理融入对话管理中。但是,目前还没有研究关注医疗对话生成,这是MDS中的关键部分。与现有方法不同,我们调查直接建立端到端的图指导的对话生成模型。
Knowledge-grounded Dialog Generation。最近,基于额外知识的对话生成是迈向类人对话AI的重要一步,在该方法中,知识可以从开放领域知识图或从非结构化文档中检索到。与它们不同的是,我们的MDG模型建立在专用的医学领域知识图上,并需要其能不断进化以满足对现实世界诊断的需求。
Meta-Learning。通过从训练任务中元训练一个模型初始化参数,能够加快模型在新任务上的适应能力,meta-learning在许多NLP领域(例如机器翻译,面向任务的对话和文本分类)取得了令人鼓舞的结果。但是,很少有研究将元学习应用到MD,这需要基于外部医学知识以及疾病症状间相关性的推理。在这项工作中,我们采用了Reptile,这是一种一阶模型无关的元学习方法,由于它的效率和有效性,能通过元知识图推理及进化来增强它。
3.Task Definition: Low-Resource MDG
基于外部医学知识图 A A A,医学对话生成模型将对话上下文 U = { u 1 , . . . , u t − 1 } U=\{u_1,...,u_{t-1}\} U={u1,...,ut−1}作为输入,目的是(1)生成下一个响应 R = u t R=u_t R=ut,并(2)预测在下一个响应中出现的疾病或症状实体 E = e t E=e_t E=et:
f θ ( R , E ∣ U , A ; θ ) = p ( u t , e t ∣ u 1 : t , A ; θ ) , (1) f_{\theta}(R,E|U,A;\theta)=p(u_t,e_t|u_{1:t},A;\theta),\tag{1} fθ(R,E∣U,A;θ)=p(ut,et∣u1:t,A;θ),(1)
给定具有K个不同源疾病 S k S_k Sk的大量对话样例,低资源的MDG任务需要在元训练过程中获得良好的模型初始化:
θ m e t a : ( U , A ) × S k → ( R s o u r c e , E ) . (2) \theta_{meta}:(U,A)\times S_k\rightarrow (R_{source},E).\tag{2} θmeta:(U,A)×Sk→(Rsource,E).(2)
为了适应新的目标疾病 T T T,我们对具有少量对话样例(例如, 1 % ∼ 10 % 1\%\sim 10\% 1%∼10%的源疾病)的模型 θ m e t a \theta_{meta} θmeta进行微调,并要求微调后的模型 θ t a r g e t θ_{target} θtarget在目标疾病中表现良好:
θ t a r g e t : ( U , A ) × T → ( R t a r g e t , E ) . (3) \theta_{target}:(U,A)\times T\rightarrow (R_{target},E).\tag{3} θtarget:(U,A)×T→(Rtarget,E).(3)
4.End-to-End Medical Dialogue Model
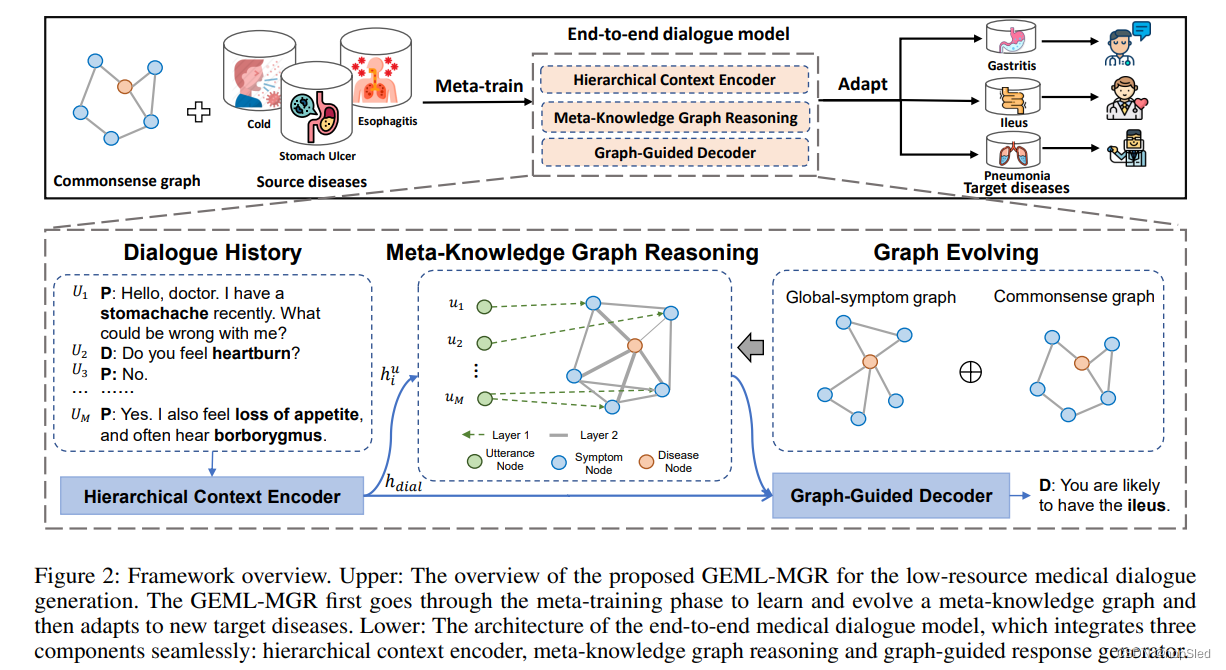
在本节中,我们详细阐述了端到端对话模型,其框架在图2中进行了说明。所提出的方法无缝集成了三个组件,包括分层上下文编码器,元知识图推理(MGR)和图指导的响应生成器。具体而言,上下文编码器首先将对话历史记录编码为分层的上下文表示。然后,MGR将所获得的表示融入知识图推理过程中,以理解疾病症状间相关性。最后,图指导的解码器通过精心设计的基于图实体节点的复制机制,来生成信息丰富的响应。
4.1 Hierarchical Context Encoder
我们首先使用分层上下文编码器来编码对话历史记录并获取上下文的分层隐藏表示。正式地,给定一个对话上下文 U = ( u 1 , . . . , u l ) U=(u_1,...,u_l) U=(u1,...,ul),分层上下文编码器首先利用长短期记忆(LSTM)网络,将每个语句编码为隐藏的表示:
h i u = L S T M θ u ( e 1 i , . . . , e j i , . . . , e l i i ) , (4) \textbf h^u_i=LSTM_{\theta_u}(\textbf e^i_1,...,\textbf e^i_j,...,\textbf e^i_{l_i}),\tag{4} hiu=LSTMθu(e1i,...,eji,...,elii),(4)
其中, e j i e^i_j eji是第 i i i个语句中第 j j j个字符的嵌入。然后,这些隐藏表示 { h i u , i = 1 , ⋅ ⋅ ⋅ , l } \{h^u_i,i=1,···,l\} {hiu,i=1,⋅⋅⋅,l}被送入另一个LSTM,以获取整个对话历史的表示:
h d i a l = L S T M θ d ( h 1 u , . . . , h j u , . . . , h l u ) . (5) \textbf h_{dial}=LSTM_{\theta_d}(\textbf h^u_1,...,\textbf h^u_j,...,\textbf h^u_l).\tag{5} hdial=LSTMθd(h1u,...,hju,...,hlu).(5)
如图2所示,在获得语句级和对话级的表示后,我们使用 h i u \textbf h^u_i hiu初始化知识图中语句节点的特征,然后使用 h d i a l \textbf h_{dial} hdial作为解码器LSTM的初始状态。
4.2 Meta-Knowledge Graph Reasoning
根据获得的语句表示,我们需要学习疾病症状间相关性,并进一步询问患者是否存在相关症状以进行验证。为此,我们设计了一个元知识图推理(MGR)网络来学习和推理上述相关性。实际上,人们经常有一个有关疾病-症状关系的先验知识,大致包含了相关性,例如,症状咳嗽表示了感冒。我们的MGR的目标是(1)通过与患者的对话推理出疾病和症状的相关性,(2)在下一次对患者的询问或响应中预测出可能出现的症状,(3)使用图进化元学习框架(GEML)将常识图进化为元知识图。在本节中,我们重点介绍前两个点,并在下一节中介绍我们的GEML。
实际上,常识疾病症状图可以从OpenKG中的中国症状库中获取。该库包含了大量的三元组,例如(腹泻,相关症状,肠胃炎)。正式地,我们将常识图表示为 G = ( V e , A , X ) \mathcal G=(\mathcal V^e,\mathcal A,\mathcal X) G=(Ve,A,X),其中 V e = { v 1 e , . . . , v m e } \mathcal V^e=\{v^e_1,...,v^e_m\} Ve={v1e,...,vme}是实体节点集合, A \mathcal A A是相应的邻接矩阵, X ∈ R ∣ V e ∣ × F \mathcal X∈\mathcal R^{|\mathcal V^e|×F} X∈R∣Ve∣×F是节点的特征矩阵( F F F是每个节点中特征数)。在图 G \mathcal G G中,每个实体节点 v i e ∈ V e v^e_i∈\mathcal V^e vie∈Ve表示一个症状或疾病。每个实体节点的特征向量,即特征矩阵 X \mathcal X X的每一行,都是可训练的。此外,我们还有一个语句节点集合,表示为 V u = { v 1 u , . . . , v l u } \mathcal V^u=\{v^u_1,...,v^u_l\} Vu={v1u,...,vlu},其中每个语句节点的输入特征 v i u v^u_i viu是由在等式(4)中获得的表示 h i u \textbf h^u_i hiu初始化的。为了将上下文信息合并到知识图推理中,我们将每个语句节点和其所包含的所有实体节点联系起来。
现在,我们引入有关疾病和症状的图推理过程。为了增强实体节点之间的信息传播,我们构建了一个元知识图,其中每个实体节点表示一个疾病或症状。受图注意力网络的启发,我们设计了由两个图推理层组成的元知识图推理(MGR)网络。在第一层中,出现在对话历史记录中的实体节点通过聚合来自对应语句中其它节点的信息进行激活。然后在第二层中,这些被激活的实体节点将信息扩散到其邻接节点以进行相关性推理。接下来,我们提出用于构建MGR的单个图推理层(通过堆叠该层构建)。基于邻接矩阵 X \mathcal X X,令 N i \mathcal N_i Ni表示节点 i i i的邻居集合。使用一些邻居节点 j ∈ N i j\in \mathcal N_i j∈Ni的输入特征 h j e \textbf h^e_j hje,节点 i i i的表示通过图推理层更新为:
h i e = σ ( ∑ j ∈ N i α i j W 0 h j e ) α i j = s o f t m a x j ( e i j ) = e x p ( e i j ) / ∑ k ∈ N i e x p ( e i k ) (6) \begin{array}{cc} \textbf h^e_i=\sigma(\sum_{j\in \mathcal N_i}\alpha_{ij}\textbf W_0\textbf h^e_j)\\ \alpha_{ij}=softmax_j(e_{ij})=exp(e_{ij})/\sum_{k\in \mathcal N_i}exp(e_{ik}) \end{array} \tag{6} hie=σ(∑j∈NiαijW0hje)αij=softmaxj(eij)=exp(eij)/∑k∈Niexp(eik)(6)
其中 W 0 ∈ R F × F \textbf W_0∈\mathcal R^{F×F} W0∈RF×F是一个权重矩阵,而 e i j e_{ij} eij是表示实体节点 j j j对节点 i i i重要性的注意力系数。类似 (Bahdanau, Cho, and Bengio 2014) ,注意力系数 e i j e_{ij} eij被计算为:
e i j = S i g m o i d ( a T W 1 [ h i e ∣ ∣ h j e ] ) , (7) e_{ij}=Sigmoid(\textbf a^T\textbf W_1[\textbf h^e_i||\textbf h^e_j]),\tag{7} eij=Sigmoid(aTW1[hie∣∣hje]),(7)
其中 a ∈ R H × 1 \textbf a∈\mathcal R^{H×1} a∈RH×1是可训练的向量, W 1 ∈ R H × 2 F \textbf W_1∈\mathcal R^{H×2F} W1∈RH×2F是权重矩阵, ∣ ∣ || ∣∣表示拼接。注意,在我们仅计算节点 i i i的邻居 j j j时,将图结构(即邻接矩阵 A \mathcal A A)注入图推理层。在下一节中,我们将详细说明如何在元学习范式中进化元知识图结构。通过堆叠两个图推理层,每个实体节点可以从其他相关节点中掌握足够的信息。如图2所示,然后我们将最终实体节点表示 { h i e , i = 1 , . . . , m } \{h^e_i,i=1,...,m\} {hie,i=1,...,m}送入响应生成器中,以在下一步响应中推断可能的实体。为此,我们引入了响应生成以外的实体预测任务。具体而言,我们将最终节点表示 { h i e , i = 1 , . . . , m } \{h^e_i,i=1,...,m\} {hie,i=1,...,m}送入前馈层中,并通过在所有图实体节点上进行二分类,来预测下一个响应中可能包含的实体。通过这种方式,我们的MGR网络可以挖掘和推理疾病 - 症状相关性,以更准确地诊断。
4.3 Graph-guided Response Generator
为了将知识图融入到生成器中,我们设计了一个基于复制机制的图指导响应生成器,其中复制机制主要在图节点分布上进行,而不是输入源文本。更具体地,在实体节点表示 { h i e , i = 1 , . . . , m } \{\textbf h^e_i,i=1,...,m\} {hie,i=1,...,m}的指导下,解码器在时刻 t t t通过从词表采样或直接从图实体节点集 E E E复制来生成每个单词,如下所示:
P o u t ( t ) = g t ⋅ P V ( t ) + ( 1 − g t ) ⋅ P E ( t ) , (8) \textbf P^{(t)}_{out}=g_t\cdot \textbf P^{(t)}_V+(1-g_t)\cdot \textbf P^{(t)}_{E},\tag{8} Pout(t)=gt⋅PV(t)+(1−gt)⋅PE(t),(8)
其中 P V ( t ) P^{(t)}_V PV(t)是解码器LSTM的归一化词表分布, p E ( t ) p^{(t)}_E pE(t)是图实体节点上的注意力分布。给定解码器输入 x t \textbf x_t xt和解码器状态 s t \textbf s_t st,用于从采样还是复制中进行选择的软开关 g t ∈ [ 0 , 1 ] g_t\in[0,1] gt∈[0,1]被按如下方式计算:
g t = σ ( W 2 ⋅ [ x t ; s t ; h t a ] ) h t a = ∑ i α i e ⋅ h i e , (9) g_t=\sigma(\textbf W_2\cdot[\textbf x_t;\textbf s_t;\textbf h^a_t])\quad \textbf h^a_t=\sum_i\alpha^e_i\cdot\textbf h^e_i,\tag{9} gt=σ(W2⋅[xt;st;hta])hta=i∑αie⋅hie,(9)
其中 W 2 \textbf W_2 W2是可训练的矩阵,而 σ σ σ是sigmoid函数。矢量 h t a \textbf h^a_t hta是通过对节点表示 h t e \textbf h^e_t hte进行加权求和计算出来的,而 α i e α^e_i αie是参照(Bahdanau, Cho, and Bengio 2014)计算的注意力权重。使用上述图指导的复制机制,响应生成器可以实现更准确的症状询问和疾病诊断。
5.Graph-Evolving Meta-Learning
在本节中,我们提出了一个Graph-Evolving Meta-Learning (GEML)框架,该框架有助于上述端到端的医疗对话模型处理低资源配置。这种情况更加实用和具有挑战性,因为现实世界中的许多疾病都很罕见且标注成本高昂。为了应对这一挑战,GEML使用元知识迁移和元知识图进化来转移不同疾病的诊断经验。我们将依次介绍它们。
5.1 Meta-Knowledge Transfer
元知识迁移的方法是元训练一个由 θ m e t a \theta_{meta} θmeta参数化的端到端的医疗对话模型 f θ m e t a f_{\theta_{meta}} fθmeta,并且具有快速适应新疾病能力。为此,我们遵循元学习框架,并使用现有的 k k k个源疾病的对话数据来创建任务集 T = { { T i 1 } i = 1 N 1 , { T i 2 } i = 1 N 2 , . . . , { T i k } i = 1 N k } \mathcal T=\{\{\mathcal T^1_i\}^{N_1}_{i=1},\{\mathcal T^2_i\}^{N_2}_{i=1},...,\{\mathcal T^k_i\}^{N_k}_{i=1}\} T={{Ti1}i=1N1,{Ti2}i=1N2,...,{Tik}i=1Nk},其中每个任务 T i k \mathcal T^k_i Tik代表第 k k k个疾病中的对话数据。每个任务 T i k ∈ T \mathcal T^k_i∈\mathcal T Tik∈T只有几个对话样本,可以将其进一步分为训练(support)集 D t r T i \mathcal D^{\mathcal T_i}_{tr} DtrTi和验证(query)集 D v a T i \mathcal D^{\mathcal T_i}_{va} DvaTi。然后在元训练阶段,给定一个模型初始化 θ m e t a θ_{meta} θmeta,我们要求 θ m e t a θ_{meta} θmeta通过一次梯度更新就能快速适应任何任务 T i ∈ T \mathcal T_i∈\mathcal T Ti∈T:
θ i = θ m e t a − β ∇ θ L D t r T i ( f θ m e t a ) , (10) \theta_i=\theta_{meta}-\beta\nabla_{\theta}\mathcal L_{\mathcal D^{\mathcal T_i}_{tr}}(f_{\theta_{meta}}),\tag{10} θi=θmeta−β∇θLDtrTi(fθmeta),(10)
其中 L D t r T i \mathcal L_{\mathcal D^{\mathcal T_i}_{tr}} LDtrTi是任务 T i \mathcal T_i Ti的训练损失函数, β \beta β表示学习率。为了测量适应参数 θ i θ_i θi的质量,一种基于优化的元学习方法MAML,要求 θ i θ_i θi在验证集 D v a T i \mathcal D^{\mathcal T_i}_{va} DvaTi上具有较小的验证损失。这样,它可以计算验证集损失的梯度并将 θ m e t a θ_{meta} θmeta更新为:
θ m e t a = θ m e t a − γ ∇ L D v a T i ( θ m e t a − β ∇ θ L D t r T i ( f θ m e t a ) ) , (11) \theta_{meta}=\theta_{meta}-\gamma\nabla\mathcal L_{\mathcal D^{\mathcal T_i}_{va}}(\theta_{meta}-\beta\nabla_{\theta}\mathcal L_{\mathcal D^{\mathcal T_i}_{tr}}(f_{\theta_{meta}})),\tag{11} θmeta=θmeta−γ∇LDvaTi(θmeta−β∇θLDtrTi(fθmeta)),(11)
其中 γ γ γ是步长的大小。为了缓解等式(11)中二阶梯度(即海森矩阵)带来的计算成本,Reptile将验证损失的二阶导数近似为:
θ m e t a ← θ m e t a + γ 1 ∣ { T i } ∣ ∑ T i ∼ p ( T ) ( θ i − θ m e t a ) . (12) \theta_{meta}\leftarrow \theta_{meta}+\gamma\frac{1}{|\{\mathcal T_i\}|}\sum_{\mathcal T_i\sim p(\mathcal T)}(\theta_i-\theta_{meta}).\tag{12} θmeta←θmeta+γ∣{Ti}∣1Ti∼p(T)∑(θi−θmeta).(12)
在这项工作中,我们使用Reptile来更新初始化 θ m e t a θ_{meta} θmeta,因为其有效性和高效。在获得初始化 θ m e t a θ_{meta} θmeta后,给定一个只有几个训练数据 D t r \mathcal D_{tr} Dtr的目标疾病,我们可以通过几次梯度步骤调整具有 θ m e t a \theta_{meta} θmeta的模型 f θ m e t a f_{\theta_{meta}} fθmeta,以获得适应新疾病的参数。
请注意,此元知识迁移仅考虑模型参数的快速适应,而忽略了常识图中的稀疏性缺陷。为了解决这个问题,我们设计了一种方法来进化常识图,以便可以根据当前的疾病调整图并与对话实例更好地整合。
5.2 Meta-Knowledge Graph Evolving
由于常识图很稀疏,并且没有涵盖足够的症状实体,因此这种先验图与真实对话示例之间存在差距。例如,“dysbacteriosis”可能出现在患者的咨询中,但是其在常识图中不存在。为了应对此挑战,我们提出在对话实例上进化常识图,并在元训练和适应阶段学习元知识图。受 Lin et al. (2019) 的启发,其显示相关症状实体在同一对话中具有一定的共现概率,我们构建了一个全局-症状图 G ∗ = ( V ∗ , A ∗ , X ∗ ) \mathcal G^∗=(\mathcal V^∗,\mathcal A^∗,\mathcal X^∗) G∗=(V∗,A∗,X∗),其中 V ∗ = { v 1 , . . . , v n } \mathcal V^∗=\{v_1,...,v_n\} V∗={v1,...,vn}是一组节点, A ∗ \mathcal A^∗ A∗是相应的邻接矩阵, X ∗ ∈ R ∣ v ∗ ∣ × N \mathcal X^∗∈\mathbb R^{|v^∗|×N} X∗∈R∣v∗∣×N是节点的特征矩阵。具体而言,提出的方法首先以在线方式收集所有观察到的对话示例。然后,如果两个实体在对话示例中同时出现,则两个节点之间都有一个边。元知识图用先前的常识图的邻接矩阵 A \mathcal A A初始化,并更新为:
A m e t a = A ⊕ A ∗ , (13) \mathcal A_{meta}=\mathcal A\oplus\mathcal A^*,\tag{13} Ameta=A⊕A∗,(13)
其中 ⊕ ⊕ ⊕表示逐元素OR逻辑运算符。这样,更新后的邻接矩阵 A m e t a \mathcal A_{meta} Ameta可以推论实体节点之间边的存在性。随着和更多的对话样例一起动态进化,这是一个同步的元知识图,即添加更多节点和边。
上述图结构进化的方法可以推断出疾病症状的相关性,但忽略了其强度。为了更细致地表征此类关系,GEML进一步使用等式(6)学习元知识图 A m e t a \mathcal A_{meta} Ameta的权重值。最后,GEML利用实体预测任务的交叉熵损失来有效地指导 A m e t a \mathcal A_{meta} Ameta的学习,我们将其表示为 L e \mathcal L_e Le。
5.3 End-to-End Training Loss

这篇关于Graph-Evolving Meta-Learning for Low-Resource Medical Dialogue Generation翻译的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








