本文主要是介绍ArcGIS Pro 优化的热点分析【Optimized Hot Spot Analysis】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ArcGIS Pro 优化的热点分析【Optimized Hot Spot Analysis】Optimized Hot Spot Analysis 优化的热点分析![]() https://mp.weixin.qq.com/s/lfoIls8exW5G6PPJ9gtDew
https://mp.weixin.qq.com/s/lfoIls8exW5G6PPJ9gtDew
em,先给大家推荐一个空间统计分析的学习资源网站
https://spatialstats-analysis-1.hub.arcgis.com/
..........
顾名思义,这个工具就是优化的热点分析。
提起热点分析,通常与热力图有些混淆,两者看着与“温度”和“地图”有关。但是呢,热力图基本可以看做是一个分区统计图,是对点的密度分析。热点分析是对随机性的测试,是寻找具有显著性意义的高值集群和低值集群。
介绍三个东西,下图中有许多面要素1234....n,首先,每一个面要素都需要有一个值,可以是每个面要素中有多少年龄60岁以上的人或者每个面要素中肺炎患者的比例等等等等,因为我要用热点分析工具去寻找它们的高值聚类或者低值聚类(如果所有要素的属性值都差不多那就不存在什么聚类了

)。接着就是要素的邻居啦,每个要素有几个邻居,这应该很熟悉了。
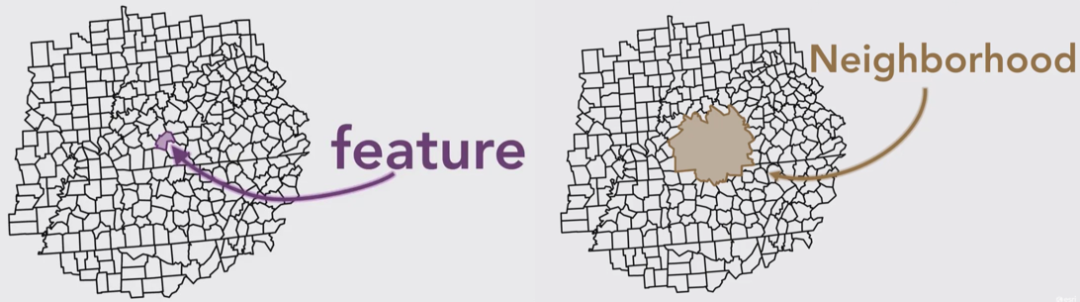
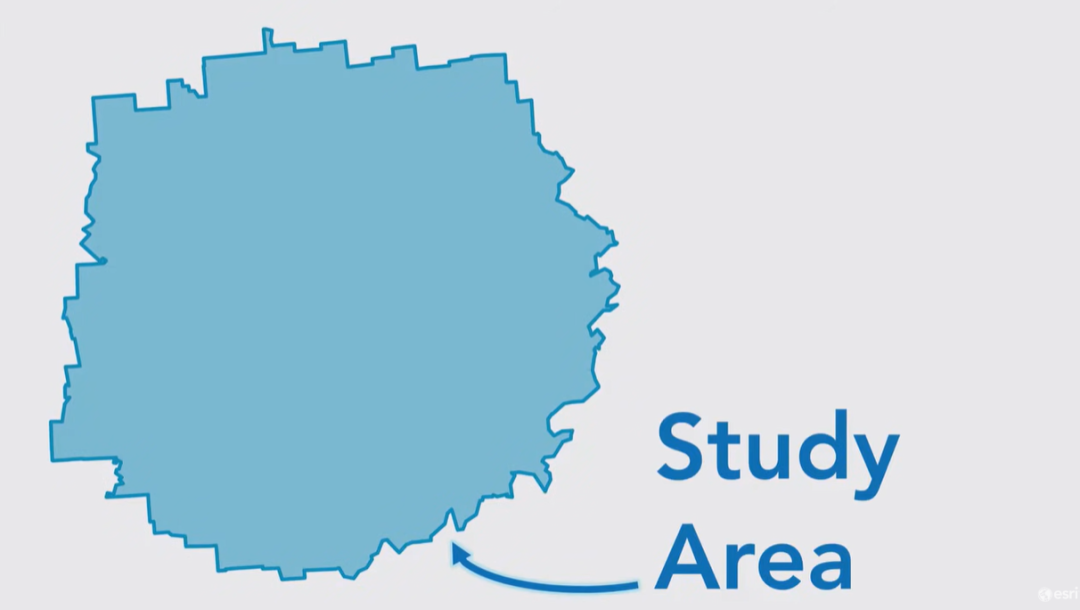
然后是研究区域,是所有的面要素所构成的整体。
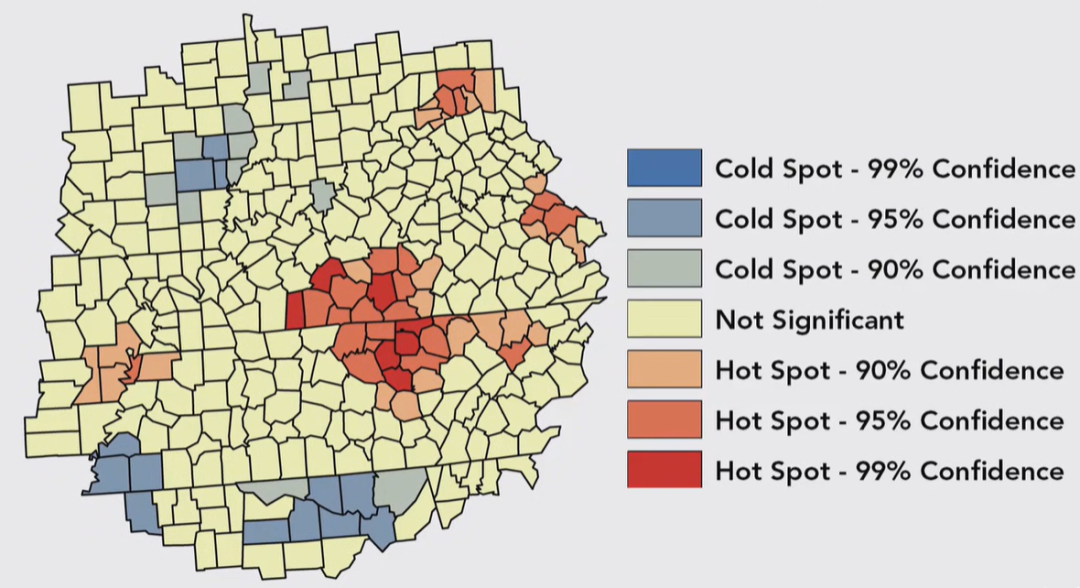
那么,如果这块Neighborhood与研究区域全局平均值相比更高,那就将这个要素标记为热点(也有情况是,你可能有一个要素的值很低甚至是0,但它依然被标记为热点,因为它的邻居有足够高,足以使局部平均值高于全局平均值)这个看虾神的科普更好理解新版白话空间统计(59)热点分析(上)。有三个不同的置信水平,90%、95%、99%确信某个要素属于高值聚类,同样,90%,95%,99%的把握确信某个要素属于低值聚类。
上面演示的是面数据,那么点数据呢,下图是汽车盗窃案件数据,每一个点都代表一个盗窃案,前面说,每一个要素都需要有一个值,所以对于这样的事件点数据,就需要对它们进行聚合,比如以行政边界进行统计,落在每个行政区内有多少个案件,或者创建渔网格进行统计。
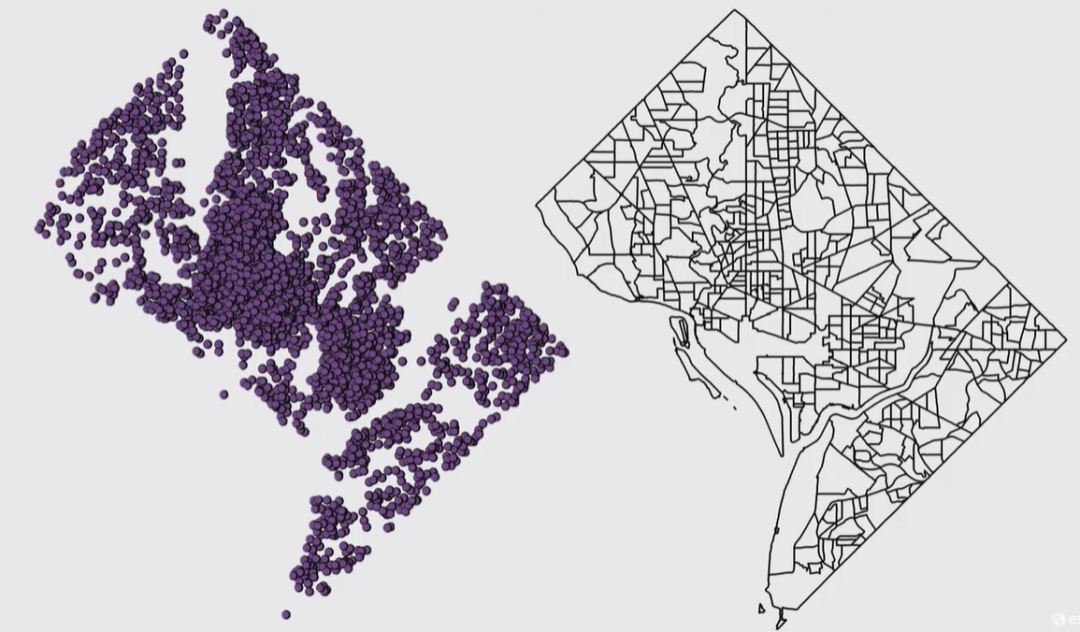
用行政边界聚合有一个优点是它附带了很多其它自身的数据,像是某区有人口、GDP、就业等等,可以用人口算一下这个区人均汽车被盗窃次数或者其它组合信息之类的。But,在[跟练]基于七普修正Worldpop人口栅格数据(附2020年worldpop100m人口栅格)也提到过这么个事情:行政单元(省、市、县、乡镇等)与实际研究中的自然单元(流域、土壤类型单元、植被类型单元、样带等)边界不一致,从而造成地学研究中的“可变元问题”(Openshaw et al,1983;杨小唤等,2002)。动植物们才不会关心你是上海的还是北京的。所以不同场景要适用不同的方法。
当然不是不可以对点进行热点分析,如果每个点都有它自己的属性值的话就可以,比如每个点都是一个人,年龄有大有小,我就可以寻找年龄高的或者低的在哪聚集。(那既然都一样写这点要素玩意跟题目有关吗...)

优化的热点分析工具,此工具可以直接聚合为渔网、六边形

说到这还有一个老生常谈的问题,邻居的多少是怎么确定的,这里提过空间自相关—莫兰指数。
比如固定距离,假定30m,那蓝色方框30距离内的要素都是它的邻居。

选择这个距离的方式取决于你的分析,那就要祭出此工具了ArcGIS增量空间自相关工具,我在这篇文章里头也提过,这个工具就是为某些需要选择距离参数的工具选择合适的距离阈值或半径,典型的比如核密度分析、热点分析。
这个工具已经被纳入优化的热点分析了,这也就是优化热点分析来选择距离所用的方式,不用自己再去算一遍了。这是系统计算后默认的最佳距离。
看到这有人心里会不会有疑问,我怎么选择一个合适的正确的权威的距离,系统默认计算的对不对之类的。
Lauren Bennett他们最初弄这个工具的时候觉得用户不再考虑像元大小,距离多少,分析过程等意味着什么不太好,后来觉得大多数人用这些工具的时候一直用的默认值吧,不会自己去折腾多远多近合适,只是想看到最后会显示些什么结果,是不是跟自己预想的一样。既然这样还不如弄一个更靠谱的默认值,于是优化的热点分析就这样做出来了,距离的选择也确实更可靠了。
“我已阅读并同意以上条款”,就好像你们读过一样

。其它方法如共邻边、角、K邻接(k代表邻居数量)等,还有一个网络空间权重Network Spatial Weights,如设定15min之内的要素是邻居。太长不再多说。
最后我用[ArcGIS Pro 时空模式挖掘工具] 时空立方体 第一弹这里面的单车数据做了一下,结果没有任何意义,只是走个形式。

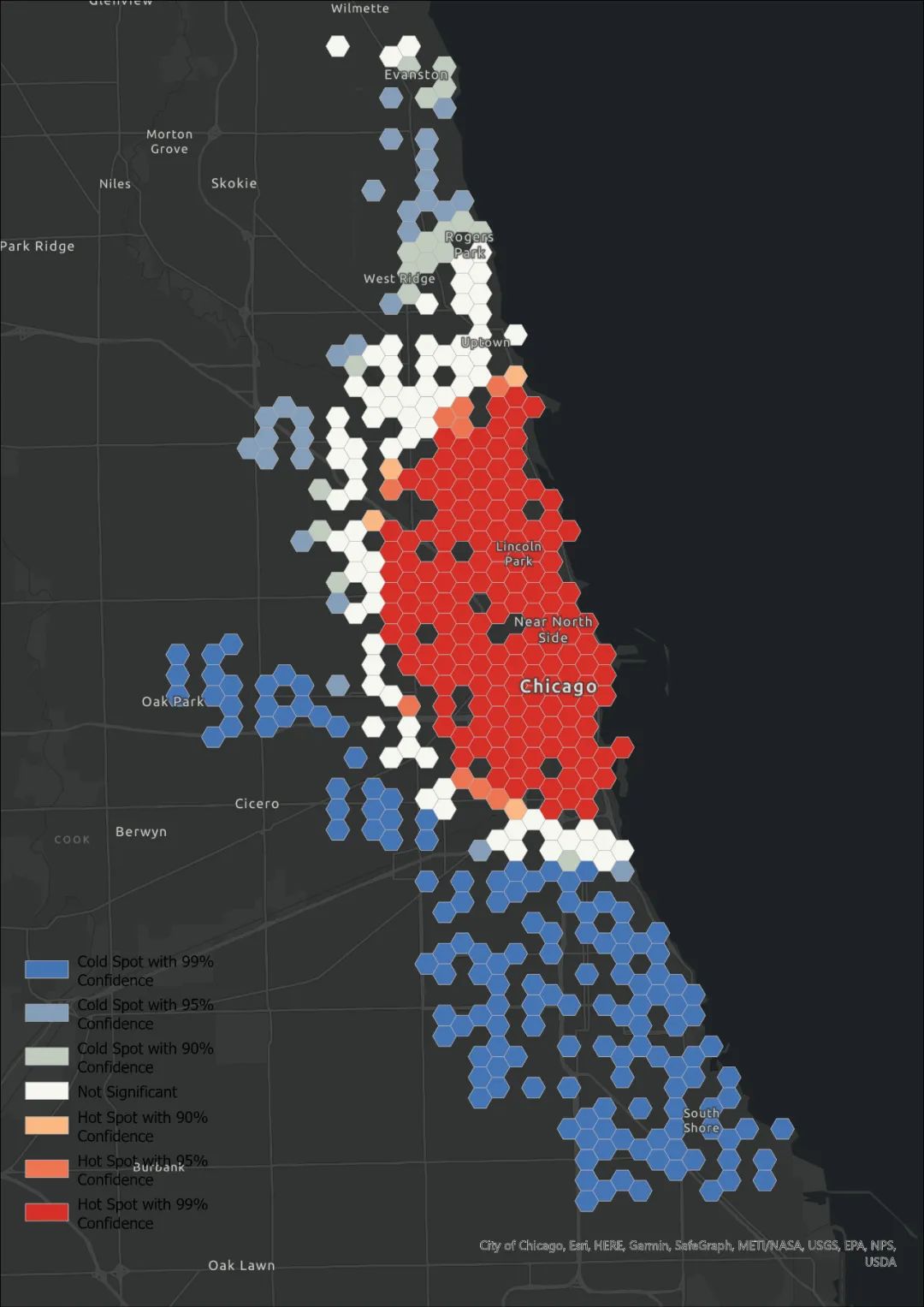
如有错误请多指正。
这篇关于ArcGIS Pro 优化的热点分析【Optimized Hot Spot Analysis】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



