本文主要是介绍随机森林原始论文_“深度学习不能拿来乱用”,Nature论文遭受严重质疑:实验方法有根本缺陷...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
地应栗 发自 凹非寺
量子位 报道 | 公众号 QbitAI
“登上Nature的研究,就是重要的研究,还能有这样的缺陷?”
最近几天,一篇用深度学习预测余震位置的Nature论文,来自哈佛和谷歌,遭受了地震一般的猛烈质疑,被封为“深度学习的错误用法”。

发起挑战的是名叫Rajiv Shah的数据科学家,在伊利诺伊大学芝加哥分校做兼职助理教授。
他用论文作者提供的代码重现了算法,由此提出的问题,几乎可以全盘否定这项研究的意义:
一是,算法在测试集上的表现,远远超过了训练集,这不是有数据泄漏么? 二是,用随机森林之类的简单方法,就能得出和神经网络相当的结果,为什么还要用深度学习?
Shah说,深度学习不是拿来乱用的。
他花了半年时间,对这项研究做了仔细的分析,还把完整分析过程放上了GitHub,供大家自行判断。
在公开发表意见之前,Shah也把自己观察到的问题发给了论文作者和Nature。
虽然,作者团并没有回复他的邮件,却给Nature写了封信。除了逐条回应质疑,也不乏情绪式发言,比如:
这些评论 (指Shah的质疑) 不值得发表,Nature真把它们发出来的话,我们会很失望的。
一来一往,引发了机器学习社区热烈的讨论,Reddit热度已经超过600。
这篇研究,仿佛比一年前登上Nature官网头条的时候,还更加瞩目了。
那么一起来观察一下,论文是怎样的论文,质疑是怎样的质疑。
“打根上就错了”

论文来自哈佛和谷歌的四位科学家,思路大概是这样的:
一次主震发生后,附近岩石中的应力会发生改变。从前科学家也是用这样的改变,来预测余震可能发生的位置,这叫“应力断裂法” (Stress-Failure Method) 。
它已经能解释许多余震地点的规律,但还有更多无法预测的情况。于是,团队便利用神经网络的力量,学习了131,000次主震和余震。
这个算法模拟了一个网格,每格包含主震震中5公里的范围。把每次主震和它的余震情况,以及应力改变的数据都喂给AI,训练出预测每一格余震概率的能力。
团队说,实验证明AI预测比传统的应力断裂法要准。另外,AI还能指示哪些参数对余震预测更重要:比如金属应力的变化,就是从前科学家很少用到的数据。
研究人员觉得,这次研究会给今后的余震预测,带去一些启发。
但在数据科学家Shah的眼里,他们得出的结论,完全建立在有缺陷的根基之上,并不可靠:
1、数据泄漏,结果掺水
Shah用论文作者开源的代码和数据集,跑了跑算法。发现了奇怪的事情:

测试集上的AUC,明显比训练集上要高。
Shah说,测试集比训练集成绩好,根本不正常。出现这种现象,最大的可能性就是数据泄漏 (Data Leakage) 。
不只是推测,观察一下数据集,他便发现了证据:
1985NAHANN01HART,1996HYUGAx01YAGI,1997COLFIO01HERN,1997KAGOSH01HORI,2010NORTHE01HAYE,这些编号的地震, 在训练集和测试集里都出现了。
发现数据集有重叠还不够,要证明这些重叠真的会影响AI的成绩:
保证一次地震的数据,只存在于训练集,或者只存在于测试集,而不能两者都有。
数据集修改之后,测试集上的成绩降下来了,也并没比传统方法更优秀:
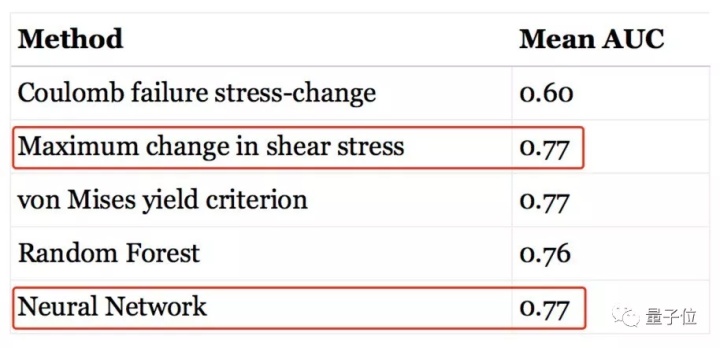
这样一来,Shah便否定了论文得出的结论。
但故事并没有结束。在他眼里,这项研究还有其他诡异的地方。
2、没必要用深度学习
Shah说,机器学习研究通常都会用一些基准算法 (Benchmark Algorithm) ,来衡量自家模型的表现。
随机森林和逻辑回归都是常用的基线。
这篇论文没有跟任何基线作对比。但Shah测试的结果表示,一个随机森林就能解决同样的问题,表现和神经网络几乎无差。
Shah说,论文里的任务的确是随意一个简单模型,如支持向量机 (SVM) 、如广义相加模型 (GAM) ,都可以得出和神经网络相当的结果。
他觉得,论文给了读者一种误导,让人以为只有深度学习才能做到。
如果不是这样的话,能用简单模型解决的问题,就没必要搭个6层的深度网络。
对于自己选用的方法,研究人员应该说明它的优越性,这一点余震论文也没有做到。
再退一步,即便神经网络真的比基线模型表现更好,Shah也提出了针对这一种方法的质疑:
3、1500行数据就能搞定
论文提到,神经网络用了470万行数据,得到了最终的结果。
Shah认为,研究人员没有用学习曲线 (Learning Curve) 。
因为,如果用了就会发现,只要拿数据集的一小部分来训练,已经可以得到很好的结果。
比如,Shah只用了1500行数据、两个Epoch,就获得了和论文里相当的成绩。
也就是说,就算用深度学习是个合理的选择,得出一个这样“简单”的结果,也不该用到那么多数据。

这三点质疑,原本都是写在Shah发给论文作者的邮件里。只是一直没有收到回复。
后来,他又把这些问题发给Nature编辑部。
这次终于有回复,但Nature认为虽然数据泄漏确有严重嫌疑,模型的选择问题也会令实验结果无效,但是觉得并没有必要去纠正这些错误。因为:
DeVries et al (作者们) 主要的点在于,把深度学习作为探索自然界的一个工具,而 不在于算法设计中的细节。
一边失望,Shah一边决定把自己的所有分析,直接公开给全世界看。
他说,机器学习从一个小众领域,变成迅猛发展的行业了。
有一大波ML扩增、自动化、GUI工具,让各行各业的人都能把深度学习用到自己的工作上去。
而问题就在这里:
这些工具是降低了机器学习/数据科学的门槛,但人类的知识水平并没有跟上。
数据科学家是接受过训练的,他们能够发现一些非常根本、但普通人不易察觉的问题。
前文提到的数据泄漏,就是典型的例子。
除了发现问题的能力之外,勇于承认“这结果也太好了,好到不像真的”,也是一种修为。
换句话说,不能被好结果冲昏了头,要记得自己做的是严谨的科学。

Shah说,去年这篇论文登上Nature之后,关注度爆炸,还获得了广泛的认可。
就连谷歌发文宣传TensorFlow 2.0,讲到深度学习都能做些什么,举的第一个例子就是这项研究。
把论文里的问题指出来,可以给整个社区一个好的反例,告诉大家常见的错误都有哪些,真正的机器学习研究应该是什么样的。
所以,虽然有同事劝他发条推特就别再管了,Shah依然坚持把全部见解发布了。
他的分析结果,还得到了许多人的赞同。
有位网友 (sensetime,这名字怎么有点熟悉) 说:
如果我在一个机器学习会议上审到这篇论文,应该也会提出差不多的问题吧。至少Ablation还是要做的吧。
注:Ablation Stuties是判断一个结构是否有用的方法。加上这个结构,去掉这个结构,看两者的表现之间有没有差异。目的是,能用简单的方法解决问题,就不用复杂的方法。
走出机器学习,Ablation就是著名的控制变量法。大概是所有实验科学,都离不开的方法了。
那么,面对针针见血的质疑,余震研究的作者是怎样回应的?
给Nature写了封信
三点质疑,作者一一给出了解释。
第一个问题是数据泄漏,团队并不认为有这样的情况存在。
他们的说法是:
训练集和测试集是基于不同的主震,随机分的。
而主震B本身,可能就是主震A的一次余震。所以,主震B的余震,和主震A的余震,也会有重叠。
如果主震A在训练集里,主震B在测试集里, 训练集和测试集就会有重叠。评论说的是事实。
即便如此,作者也不觉得这是数据泄漏,理由是:
训练集里,是把主震A造成的应力变化,映射到余震位置上。
而主震B在测试集里,是把B造成的应力变化,映射到余震位置上。 测试集里要做的映射,和训练集里的完全不一样。明明是要预测同样的余震,主震却不是那个主震了。
所以,数据集里并没有额外信息,能帮AI在测试集里表现得更好,反而可能降低AI的表现。
然而,占领Reddit讨论版顶楼的,是这样一句话:
看了这些人的回应, 感觉他们并不知道什么是数据泄漏。

关于第二个问题,该不该用深度学习,作者解释:
在比较浅或者非感知 (non-perceptual) 的机器学习任务里,神经网络和随机森林通常都表现差不多。一点也不奇怪。
这篇论文的意义在于,一个神经网络用简单的应力数据,就学会了余震位置的预测。 如果纠结其他方法是不是也做得到,就找错重点了。
读到这样的回应,Shah有些哭笑不得。他在博客里写到:
只要用了预测模型,实验结果的说服力就取决于模型的质量。
你的工作变成了数据科学的工作,也该有数据科学上的严谨。
不是一句“这不是机器学习论文,是地震科学论文”就能混过去。
还有第三个问题,学个简单规律是不是用了太多数据?
团队的回应里却没有提到“太多数据”这件事:
对,就是学到了一个简单的规律,这个事实就是整篇论文的全部意义了。
神经网络从一堆非常简单、却被人遗忘的数据里,学到一个预测方法。论文花了很大的篇幅来写这一点,也是因为它就是意义。
只记得强调,自己发现了从前没被当作预测工具的一些参数。
这封信的内容,大家并不买账。台下的看客甚至开始了调侃:
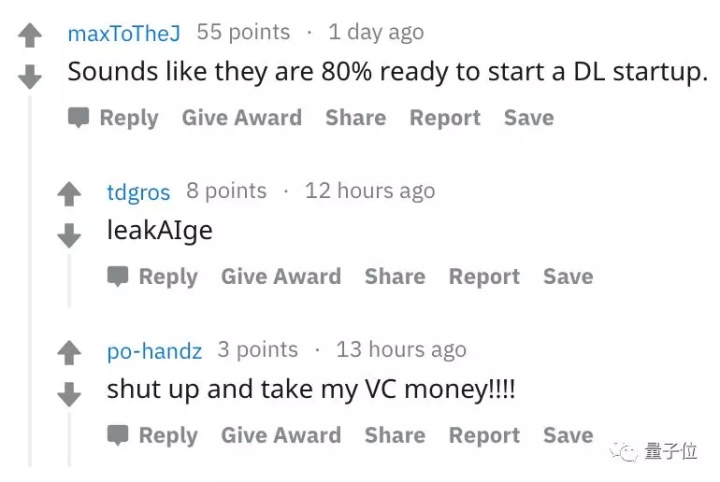
听他们的口气,似乎就快做好准备,开家深度学习创业公司了。
就叫 leakAIge。
别说了,拿好我的天使投资!!!
如果说上面的三条解释,只是令观众感到苍白而已。那么来欣赏作者的一段情绪式发言:
这些评论,并不值得发表在Nature上。
它们也不会推动这个领域向前走。
事实上,这些评论要么是错的,要么是全然误解了科学的意义,听上去还很居高临下。
全都是没有科学依据的。
如果Nature把这些评论发布出来,我们会很失望。
这些激愤的字句,引起了网友 (sensetime) 的一串惊奇问号:
质疑为啥不值得发在Nature上啊 ?为啥要被河蟹啊 ?难道不是把它们公开,才能促进健康的学术讨论么 ?
同理,对于Nature编辑部的不作为,也有人 (darchon30704) 表示了相似的不满:
这种对待批评的态度,非常不成熟了。
那么,这篇看上去千疮百孔的研究,和它的作者团,就真的没有一丝优点了么?
One More Thing
提出三大质疑的Shah,最终还是为这支团队讲了句话:
感谢作者们开源了代码,公开了数据集,不然就没办法找到里面的问题。
开源也是整个领域都应该坚持做下去的事情。
论文传送门:http://sci-hub.tw/https://www.nature.com/articles/s41586-018-0438-y
代码传送门:https://github.com/phoebemrdevries/Learning-aftershock-location-patterns
作者回应:https://github.com/rajshah4/aftershocks_issues/blob/master/correspondence/Authors_DeVries_Response.pdf
Shah的分析过程:https://github.com/rajshah4/aftershocks_issues
Shah的博客:https://towardsdatascience.com/stand-up-for-best-practices-8a8433d3e0e8
其他人也质疑过这项研究,还发了两篇论文:
1、http://sci-hub.tw/https://link.springer.com/chapter/10.1007/978-3-030-20521-8_1
2、https://arxiv.org/abs/1904.01983
Reddit讨论版:https://www.reddit.com/r/MachineLearning/comments/c4ylga/d_misuse_of_deep_learning_in_nature_journals/
— 完 —
量子位 · QbitAI
վ'ᴗ' ի 追踪AI技术和产品新动态
戳右上角「+关注」获取最新资讯↗↗
如果喜欢,请分享or点赞吧~比心❤
这篇关于随机森林原始论文_“深度学习不能拿来乱用”,Nature论文遭受严重质疑:实验方法有根本缺陷...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





