本文主要是介绍C++ 朴素贝叶斯模型(Naive Bayesian Model,NBM)实现, 西瓜实验数据集 基于周志华老师机器学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
C++ 朴素贝叶斯模型(Naive Bayesian Model,NBM)实现, 西瓜实验数据集 基于周志华老师机器学习
版权声明:本文为博主原创文章,未经博主允许不得转载。
标注
学习朴素贝叶斯算法得了解一些基本知识,比如全概率公式和贝叶斯公式。大学基本都学过不在赘述。
数据样本
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 2 | 2 | 1 | 3 | 1 | 0.697 | 0.46 | 1 |
| 2 | 3 | 2 | 3 | 1 | 3 | 1 | 0.744 | 0.376 | 1 |
| 3 | 3 | 2 | 2 | 1 | 3 | 1 | 0.634 | 0.264 | 1 |
| 4 | 2 | 2 | 3 | 1 | 3 | 1 | 0.608 | 0.318 | 1 |
| 5 | 1 | 2 | 2 | 1 | 3 | 1 | 0.556 | 0.215 | 1 |
| 6 | 2 | 1 | 2 | 1 | 2 | 2 | 0.403 | 0.237 | 1 |
| 7 | 3 | 1 | 2 | 2 | 2 | 2 | 0.481 | 0.149 | 1 |
| 8 | 3 | 1 | 2 | 1 | 2 | 1 | 0.437 | 0.211 | 1 |
| 9 | 3 | 1 | 3 | 2 | 2 | 1 | 0.666 | 0.091 | 0 |
| 10 | 2 | 3 | 1 | 1 | 1 | 2 | 0.243 | 0.267 | 0 |
| 11 | 1 | 3 | 1 | 3 | 1 | 1 | 0.245 | 0.057 | 0 |
| 12 | 1 | 2 | 2 | 3 | 1 | 2 | 0.343 | 0.099 | 0 |
| 13 | 2 | 1 | 2 | 2 | 3 | 1 | 0.639 | 0.161 | 0 |
| 14 | 1 | 1 | 3 | 2 | 3 | 1 | 0.657 | 0.198 | 0 |
| 15 | 3 | 1 | 2 | 1 | 2 | 2 | 0.36 | 0.37 | 0 |
| 16 | 1 | 2 | 2 | 3 | 1 | 1 | 0.593 | 0.042 | 0 |
| 17 | 2 | 2 | 3 | 2 | 2 | 1 | 0.719 | 0.103 | 0 |
表格含义
色泽 1-3代表 浅白 青绿 乌黑
根蒂 1-3代表 稍蜷 蜷缩 硬挺
敲声 1-3代表 清脆 浊响 沉闷
纹理 1-3代表 清晰 稍糊 模糊
脐部 1-3代表 平坦 稍凹 凹陷
好瓜 1代表 是 0 代表 不是
算法定义
朴素贝叶斯算法定义如下:


代码块
//bayesian.h
#pragma once
//定义训练数据
#define M 17
#define N 9
/*
*色泽 1—3代表 浅白 青绿 乌黑
*根蒂 1-3代表 稍蜷 蜷缩 硬挺
*敲声1-3代表 清脆 浊响 沉闷
*纹理 1-3代表 清晰 稍糊 模糊
*脐部1-3代表 平坦 稍凹 凹陷
*触感 1-2 代表 硬滑 软粘
*好瓜 1代表是 0 代表不是
*/
double A[M][N]= { {2,2,2,1,3,1,0.697,0.460,1},// 1{3,2,3,1,3,1,0.744,0.376,1},// 2{3,2,2,1,3,1,0.634,0.264,1},// 3{2,2,3,1,3,1,0.608,0.318,1},// 4{1,2,2,1,3,1,0.556,0.215,1},// 5{2,1,2,1,2,2,0.403,0.237,1},// 6{3,1,2,2,2,2,0.481,0.149,1},// 7{3,1,2,1,2,1,0.437,0.211,1},// 8{3,1,3,2,2,1,0.666,0.091,0},// 9{2,3,1,1,1,2,0.243,0.267,0},// 10{1,3,1,3,1,1,0.245,0.057,0},// 11{1,2,2,3,1,2,0.343,0.099,0},// 12{2,1,2,2,3,1,0.639,0.161,0},// 13{1,1,3,2,3,1,0.657,0.198,0},// 14{3,1,2,1,2,2,0.360,0.370,0},// 15{1,2,2,3,1,1,0.593,0.042,0},// 16{2,2,3,2,2,1,0.719,0.103,0} // 17}; struct Px1
{ double x1; double y; double p_x1y;
}; struct Px2
{ double x2; double y; double p_x2y;
}; struct Px3
{ double x3; double y; double p_x3y;
};
struct Px4
{ double x4; double y; double p_x4y;
};
struct Px5
{ double x5; double y; double p_x5y;
};
struct Px6
{ double x6; double y; double p_x6y;
};
struct Px7
{ double x7; double y; double p_x7y;
};
struct Px8
{ double x8; double y; double p_x8y;
};
// struct MeAVa
// {
// double mean;
// double stdev;
// }; double p[2];
Px1 px1[6];
Px2 px2[6];
Px3 px3[6];
Px4 px4[6];
Px5 px5[6];
Px6 px6[6];
Px7 px7[2];
Px8 px8[2]; //bayesian .cpp
#include "bayesian.h"
#include <iostream>
#include <set>
#include <vector>
#include <numeric>
#include <algorithm>
#include <iomanip>
//#include <math.h>
#include <cmath>
using namespace std;
//好瓜密度概率计算
double m_MeansAndAver(double x)
{double resultSet[17];double p;for (int i = 0; i < M; i++){resultSet[i]=A[i][6];}double sum = std::accumulate(std::begin(resultSet), std::begin(resultSet)+8, 0.0);double mean= sum /8; //均值double accum = 0.0;std::for_each (std::begin(resultSet), std::begin(resultSet)+8, [&](const double d) {accum += (d-mean)*(d-mean);});double stdev = sqrt(accum/(7)); //方差
// std::cout<<"--------------------test1-------------------------------"<<stdev<<endl;
// std::cout<<"均值为"<<mean<<"方差为:"<<stdev<<endl;
// std::cout<<"--------------test---------------"<<endl;p = (1/(sqrt(2*3.14)*stdev))*exp(-(pow((x-mean),2)/(2*pow(stdev,2))));//px7[0]=p;px7[0].p_x7y=p ;return p;
}
//坏瓜密度概率计算
double m_w_MeansAndAver(double x)
{double resultSet[17];double p;for (int i = 0; i < M; i++){resultSet[i]=A[i][6];}double sum = std::accumulate(std::begin(resultSet)+8, std::end(resultSet), 0.0);double mean= sum /9; //均值double accum = 0.0;std::for_each ( std::begin(resultSet)+8,std::end(resultSet), [&](const double d) {accum += (d-mean)*(d-mean);});double stdev = sqrt(accum/(8)); //方差
// std::cout<<"--------------------test2-------------------------------"<<stdev<<endl;
// std::cout<<"均值为"<<mean<<"方差为:"<<stdev<<endl;
// std::cout<<"--------------test---------------"<<endl;p = (1/(sqrt(2*3.14)*stdev))*exp(-(pow((x-mean),2)/(2*pow(stdev,2))));px7[1].p_x7y=p ;return p;
}
//好瓜含糖量概率计算
double h_MeansAndAver(double x)
{double resultSet[17];double p;for (int i = 0; i < M; i++){resultSet[i]=A[i][7];}double sum = std::accumulate(std::begin(resultSet), std::begin(resultSet)+8, 0.0);double mean= sum /8; //均值double accum = 0.0;std::for_each (std::begin(resultSet), std::begin(resultSet)+8, [&](const double d) {accum += (d-mean)*(d-mean);});double stdev = sqrt(accum/(7)); //方差
// std::cout<<"--------------------test3--------------------------------"<<stdev<<endl;
// std::cout<<"均值为"<<mean<<"方差为:"<<stdev<<endl;
// std::cout<<"--------------test---------------"<<endl;p = (1/(sqrt(2*3.14)*stdev))*exp(-(pow((x-mean),2)/(2*pow(stdev,2))));px8[0].p_x8y=p;return p;
}//坏瓜含糖量概率计算
double h_w_MeansAndAver(double x)
{double resultSet[17];double p;for (int i = 0; i < M; i++){resultSet[i]=A[i][7];}double sum = std::accumulate(std::begin(resultSet)+8, std::end(resultSet), 0.0);double mean= sum /9; //均值double accum = 0.0;std::for_each (std::begin(resultSet)+8, std::end(resultSet), [&](const double d) {accum += (d-mean)*(d-mean);});double stdev = sqrt(accum/(8)); //方差
// std::cout<<"--------------------test4--------------------------------"<<stdev<<endl;
// std::cout<<"均值为"<<mean<<"方差为:"<<stdev<<endl;
// std::cout<<"--------------test---------------"<<endl;p = (1/(sqrt(2*3.14)*stdev))*exp(-(pow((x-mean),2)/(2*pow(stdev,2))));px8[1].p_x8y=p;return p;
}
//计算先验概率和条件概率
void calP()
{//计算先验 //double p[2]; int i, j, k; multiset<double> m_x1, m_x2,m_x3, m_x4,m_x5, m_x6,m_x7, m_x8, m_y;//多重集容器 multiset<double>::iterator pos1; set<double> x1, x2,x3, x4,x5, x6,x7, x8, y;//集合容器 set<double>::iterator pos2, pos3; //运用多重集容器和集合容器 for(i = 0; i < M; i++) {m_x1.insert(A[i][0]); m_x2.insert(A[i][1]);m_x3.insert(A[i][2]);m_x4.insert(A[i][3]);m_x5.insert(A[i][4]);m_x6.insert(A[i][5]);m_x7.insert(A[i][6]);m_x8.insert(A[i][7]);m_y.insert(A[i][8]); x1.insert(A[i][0]); x2.insert(A[i][1]);x3.insert(A[i][2]);x4.insert(A[i][3]);x5.insert(A[i][4]);x6.insert(A[i][5]);x7.insert(A[i][6]);x8.insert(A[i][7]);y.insert(A[i][8]); } p[0] = m_y.count(1) / (double)M; //p(Y = 1) p[1] = m_y.count(0) / (double)M; //p(Y = 2) cout << endl << "************先验***********" << endl;
//p[0]代表好瓜所占的比例 p[1]代表坏瓜所占的比例cout << "p(Y = 1) = " << p[0] << endl; cout << "p(Y = 0) = " << p[1] << endl; //计算条件概率 cout << endl; cout << "*********条件概率********" << endl; // int px1_num = 3 * 2; // int px2_num = 3 * 2;
//p(x1 | y)概率j=0; for(pos2 = y.begin(); pos2 != y.end(); pos2++) { for(pos3 = x1.begin(); pos3 != x1.end(); pos3++) { px1[j].y = *pos2; px1[j].x1 = *pos3; int count_x1y = 0; for(k = 0; k < M; k++) { if(A[k][0] == px1[j].x1 && A[k][8] == px1[j].y) count_x1y++; } px1[j].p_x1y = count_x1y / (double)m_y.count(px1[j].y);//计算p(x1 | y)的概率 j++; } } cout << "p(x1 | y):" << endl; for(j = 0; j < 6; j++) { cout << px1[j].x1 << " " << px1[j].y << " " << px1[j].p_x1y << endl; }
//p(x2|y)概率j=0; for(pos2 = y.begin(); pos2 != y.end(); pos2++) { for(pos3 = x2.begin(); pos3 != x2.end(); pos3++) { px2[j].y = *pos2; px2[j].x2 = *pos3; int count_x2y = 0; for(k = 0; k < M; k++) { if(A[k][1] == px2[j].x2 && A[k][8] == px2[j].y) count_x2y++; } px2[j].p_x2y = count_x2y / (double)m_y.count(px2[j].y);//计算p(x2 | y)的概率 j++; } } cout << "p(x2 | y):" << endl; for(j = 0; j < 6; j++) { cout << px2[j].x2 << " " << px2[j].y << " " << px2[j].p_x2y << endl; } //p(x3|y)概率j=0; for(pos2 = y.begin(); pos2 != y.end(); pos2++) { for(pos3 = x3.begin(); pos3 != x3.end(); pos3++) { px3[j].y = *pos2; px3[j].x3 = *pos3; int count_x3y = 0; for(k = 0; k < M; k++) { if(A[k][2] == px3[j].x3 && A[k][8] == px3[j].y) count_x3y++; } px3[j].p_x3y = count_x3y / (double)m_y.count(px3[j].y);//计算p(x2 | y)的概率 j++; } } cout << "p(x3 | y):" << endl; for(j = 0; j < 6; j++) { cout << px3[j].x3 << " " << px3[j].y << " " << px3[j].p_x3y << endl; }
//p(x4|y)概率j=0; for(pos2 = y.begin(); pos2 != y.end(); pos2++) { for(pos3 = x4.begin(); pos3 != x4.end(); pos3++) { px4[j].y = *pos2; px4[j].x4 = *pos3; int count_x4y = 0; for(k = 0; k < M; k++) { if(A[k][3] == px4[j].x4 && A[k][8] == px4[j].y) count_x4y++; } px4[j].p_x4y = count_x4y / (double)m_y.count(px4[j].y);//计算p(x4 | y)的概率 j++; } } cout << "p(x4 | y):" << endl; for(j = 0; j < 6; j++) { cout << px4[j].x4 << " " << px4[j].y << " " << px4[j].p_x4y << endl; }
//p(x5|y)概率j=0; for(pos2 = y.begin(); pos2 != y.end(); pos2++) { for(pos3 = x5.begin(); pos3 != x5.end(); pos3++) { px5[j].y = *pos2; px5[j].x5 = *pos3; int count_x5y = 0; for(k = 0; k < M; k++) { if(A[k][4] == px5[j].x5 && A[k][8] == px5[j].y) count_x5y++; } px5[j].p_x5y = count_x5y / (double)m_y.count(px5[j].y);//计算p(x5 | y)的概率 j++; } } cout << "p(x5 | y):" << endl; for(j = 0; j < 6; j++) { cout << px5[j].x5 << " " << px5[j].y << " " << px5[j].p_x5y << endl; }
//p(x6|y)概率j=0; for(pos2 = y.begin(); pos2 != y.end(); pos2++) { for(pos3 = x6.begin(); pos3 != x6.end(); pos3++) { px6[j].y = *pos2; px6[j].x6 = *pos3; int count_x6y = 0; for(k = 0; k < M; k++) { if(A[k][5] == px6[j].x6 && A[k][8] == px6[j].y) count_x6y++; } px6[j].p_x6y = count_x6y / (double)m_y.count(px6[j].y);//计算p(x6 | y)的概率 j++; } } cout << "p(x6 | y):" << endl; for(j = 0; j < 6; j++) { cout << px6[j].x6 << " " << px6[j].y << " " << px6[j].p_x6y << endl; }
//p(x7|y)概率}
int main()
{ int i = 0, j = 0; //输出训练数据 cout << "***********训练数据************" << endl; for(i = 0; i < M; i++) { for(int j = 0; j < N; j++) { cout << " "<< A[i][j]; } cout << endl; } calP();//计算先验和条件概率 int s_x1, s_x2, s_x3, s_x4, s_x5, s_x6;double s_x7, s_x8; double result[2]; int class_y = 1; cout<< "##########################< 提 示 >##########################"<<endl;cout<<setw(10)<<"色泽"<<setw(10)<<"1-3代表"<<setw(10)<<"浅白"<<setw(10)<<"青绿"<<setw(10)<<"乌黑"<<endl;cout<<setw(10)<<"根蒂"<<setw(10)<<"1-3代表"<<setw(10)<<"稍蜷"<<setw(10)<<"蜷缩"<<setw(10)<<"硬挺"<<endl;cout<<setw(10)<<"敲声"<<setw(10)<<"1-3代表"<<setw(10)<<"清脆"<<setw(10)<<"浊响"<<setw(10)<<"沉闷"<<endl;cout<<setw(10)<<"纹理"<<setw(10)<<"1-3代表"<<setw(10)<<"清晰"<<setw(10)<<"稍糊"<<setw(10)<<"模糊"<<endl;cout<<setw(10)<<"脐部"<<setw(10)<<"1-3代表"<<setw(10)<<"平坦"<<setw(10)<<"稍凹"<<setw(10)<<"凹陷"<<endl;cout<<setw(10)<<"触感"<<setw(10)<<"1-2代表"<<setw(10)<<"硬滑"<<setw(10)<<"软粘"<<endl;cout<<" 密度以及含糖量 0<Xi<1 "<<endl;cout<<" 请按照以上范围输入"<<endl;cout<< "###############################################################"<<endl;/************************************************************************//* 色泽 1-3代表 浅白 青绿 乌黑根蒂 1-3代表 稍蜷 蜷缩 硬挺敲声 1-3代表 清脆 浊响 沉闷纹理 1-3代表 清晰 稍糊 模糊脐部 1-3代表 平坦 稍凹 凹陷触感 1-2代表 硬滑 软粘 好瓜 1代表 是 0 代表 不是 *//************************************************************************/cout <<endl<< "##########################< 预 测 >##########################"<<endl; cout <<endl<<"Input:"; cin >> s_x1 >> s_x2>> s_x3>> s_x4>> s_x5>> s_x6>> s_x7>> s_x8; cout << "##########<连续属性X7与x8的 p(x7|y)、<p(x8|y)计算结果>##########"<<endl<<endl; cout<<"好瓜密度其概率为:"<<m_MeansAndAver(s_x7)<<endl;//当前密度,在是好瓜的情况下可能发生的概率cout<<"坏瓜密度的概率"<<m_w_MeansAndAver(s_x7)<<endl;//准确cout<<"好瓜其概率为:"<<h_MeansAndAver(s_x8)<<endl;//准确cout<<"好瓜其概率为:"<<h_w_MeansAndAver(s_x8)<<endl<<endl;//准确for(i = 0; i < 2; i++) { double s_px_1, s_px_2, s_px_3, s_px_4, s_px_5, s_px_6, s_px_7, s_px_8; for(j = 0; j < 6; j++) { if(s_x1 == px1[j].x1 && px1[j].y == class_y) s_px_1 = px1[j].p_x1y; if(s_x2 == px2[j].x2 && px2[j].y == class_y)s_px_2 = px2[j].p_x2y; if(s_x3 == px3[j].x3 && px3[j].y == class_y)s_px_3 = px3[j].p_x3y; if(s_x4 == px4[j].x4 && px4[j].y == class_y)s_px_4 = px4[j].p_x4y; if(s_x5 == px5[j].x5 && px5[j].y == class_y)s_px_5 = px5[j].p_x5y; if(s_x6 == px6[j].x6 && px6[j].y == class_y)s_px_6 = px6[j].p_x6y; } s_px_7=px7[i].p_x7y;s_px_8=px8[i].p_x8y;result[i] = p[i] * s_px_1 * s_px_2*s_px_3* s_px_4* s_px_5* s_px_6*s_px_7*s_px_8; //p[0]代表好瓜所占的比例 p[1]代表坏瓜所占的比例class_y--; } cout << "###########################<分类结果>###########################"<<endl; cout << endl << "all results:"; cout <<"可能为好瓜的概率"<< result[0] << " " <<"可能为坏瓜的概率"<< result[1] << endl<<endl; //0代表否(不是好瓜),1代表是好瓜,其中result[0]存放好瓜可能概率result[1]坏瓜所占比例cout << "###########################<预测结果>###########################"<<endl<<endl; i =0;if(result[i] < result[i+1]) //如果坏瓜概率>好瓜概率{ class_y = 0; cout << "属性为:("<< s_x1 << "," << s_x2 << "," << s_x3 << "," << s_x4 << "," << s_x5 << "," << s_x6<< "," << s_x7<< "," << s_x8 << ")所属的类是:" << class_y<< "-----------坏瓜"<<endl<<endl; } else //好瓜概率>坏瓜概率{class_y=1;cout << "属性为:("<< s_x1 << "," << s_x2 << "," << s_x3 << "," << s_x4 << "," << s_x5 << "," << s_x6 << "," << s_x7<< "," << s_x8 << ")所属的类是:" << class_y <<"-----------好瓜"<< endl<<endl; }/*cout << "("<< s_x1 << "," << s_x2 << ")所属的类是:" << class_y + 1 << endl; */system("pause");return 0;
} “`
分类结果

UML 图:
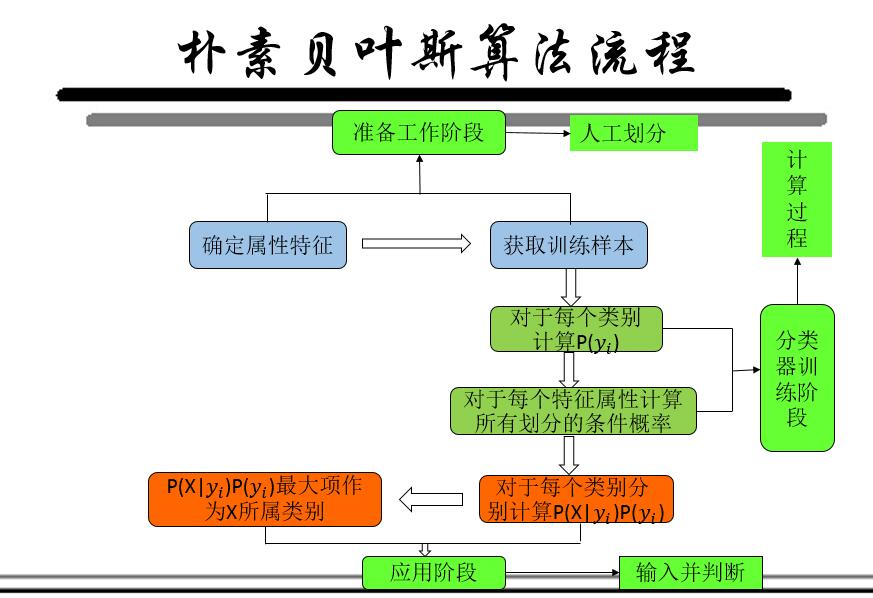
源码下载地址
http://download.csdn.net/detail/u011557212/9700532
这篇关于C++ 朴素贝叶斯模型(Naive Bayesian Model,NBM)实现, 西瓜实验数据集 基于周志华老师机器学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









