本文主要是介绍基础概念——TP、FP、TN、FN、IOU、PR、AP、Interpolated AP、AUC、mAP,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
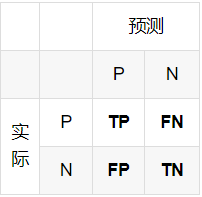
TP、FP、TN、FN
都是站在预测的立场看的:
TP:预测为正是正确的
FP:预测为正是错误的
TN:预测为负是正确的
FN:预测为负是错误的
准确率(accuracy),精确率(Precision)和召回率(Recall)
准确度:分类器正确分类的样本数与总样本数之比
(TP+TN)/ (TP+TN+FP+FN)
精准率Precision:所有被预测为正样本的样本中预测对的比例
(TP) / (TP+NP)
召回率Recall:被正确预测的正样本占所有正样本的比例
(TP)/ (TP+FN)
Precision就代表我们模型检测出来的目标有多大比例是真正的目标物体,是从检测出的目标的角度来看待问题;
Recall就代表所有真实的目标有多大比例被我们的模型检测出来了,是从数据集中奔雷就存在的目标的角度来看待问题。
PR曲线
我们希望Precision 和 Recall 都越高越好,但是实际情况下,我们不可能满足Precision 和 Recall 都很大。
比如在极端情况下,检测模型只检测出来一个目标,而且检测正确了,那么Precision为100%,但是Recall却很小;
但是如果我们把所有的结果都返回,那么Recall 就很大,但是Precison却很小。
在不同的场合,我们对 Precision 和 Recall 有不同的要求,可以结合PR曲线进行分析。
假设我们的数据集中有5个目标,目标检测模型检测出10个候选框,我们按照置信度的顺序对候选框进行排列。
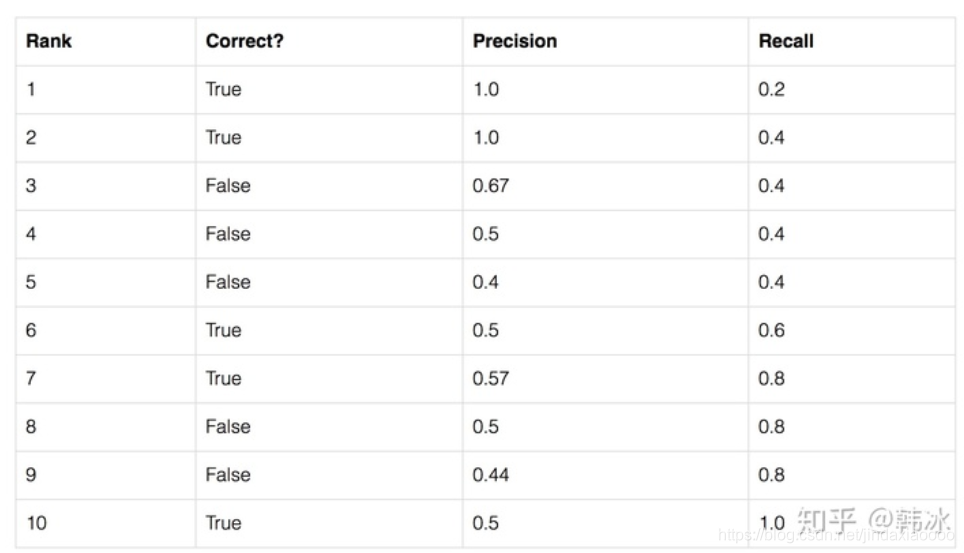
第二列为候选框是否检测正确,也就是是否存在目标框和这个候选框的交并比大于阈值0.5。
第三、四列为当以同行的候选框的置信度为阈值时(大于这个阈值的候选框就预测为正样本),求取的Precision和Recall
第一行:
TP 为1 ; FN为4
FP 为0;
Precision = 1/1=1
Recall = 1/(1+4) = 0.2
第二行:
TP 为2 ; FN为3
FP 为0;
Precision = 2/2=1
Recall = 2/(2+3) = 0.4
第三行:
TP 为2 ; FN为3
FP 为1;
Precision = 2/(2+1)=0.67
Recall = 2/(2+3) = 0.4
…
下面的案例更加具体:
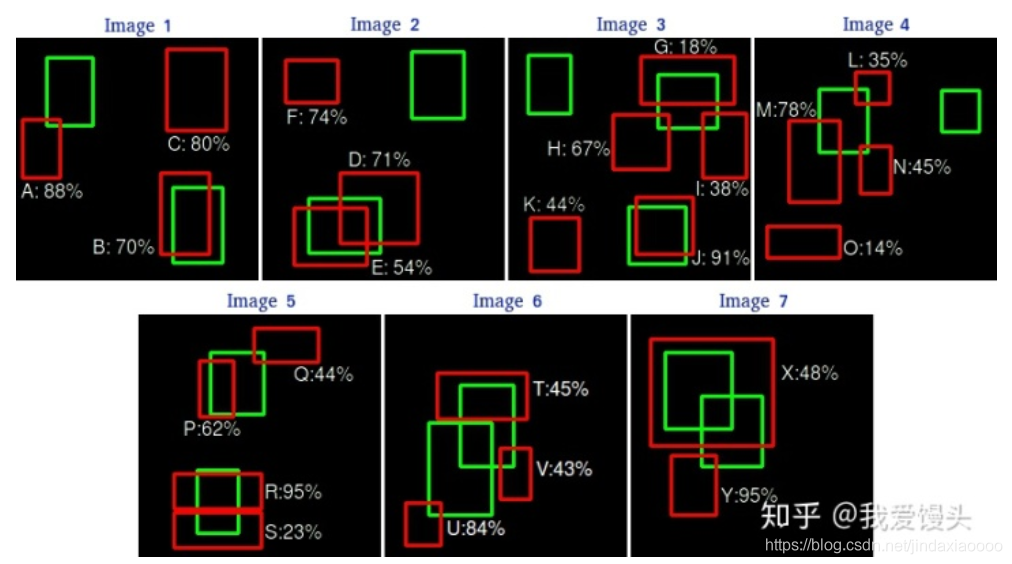
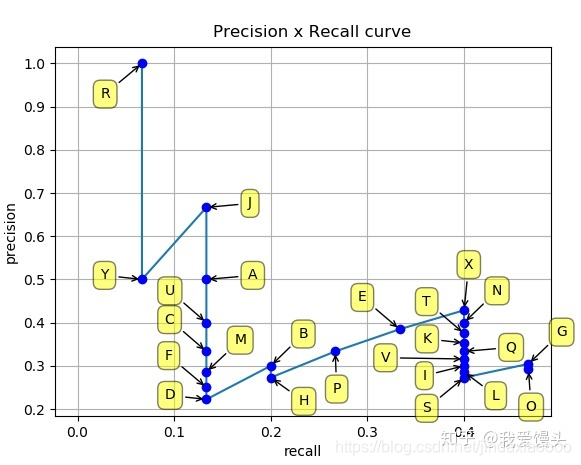
上面七张图每张图片的检测结果均已标出,绿色是Ground Truth,红色是检测到的对象(总共24个,A~Y)。对上面的所有检测结果按照confidence排名统计出一个表如下:
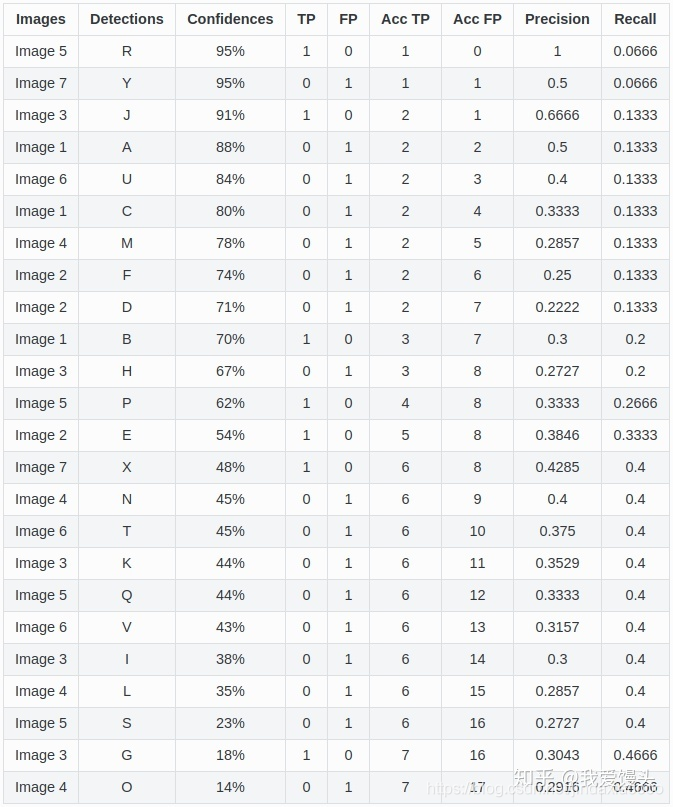
由上表以Recall值为横轴,Precision值为纵轴,我们就可以得到PR曲线。我们会发现,Precision与Recall的值呈现负相关,在局部区域会上下波动。(实际计算时,当Precision下降到一定程度时,后面就直接默认为0,不算了。):
AP
上图PR曲线下的面积就定义为AP,即:
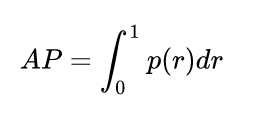
上面就是AP的基本思想,实际计算过程中,PASCAL VOC,COCO比赛在上述基础上都有不同的调整策略。
Interpolated AP(PASCAL VOC 2008的评测指标)
在PASCAL VOC 2008中,在计算AP之前会对上述曲线进行平滑,平滑方法为,对每一个Precision值,使用其右边最大的Precision值替代。
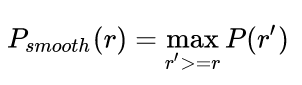
具体示意图如下:
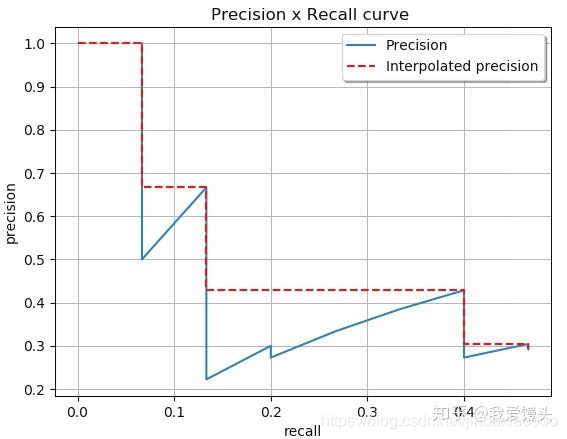
通过平滑策略,上面蓝色的PR曲线就变成了红色的虚线了。平滑的好处在于,平滑后的曲线单调递减,不会出现摇摆的情况。这样的话,随着Recall的增大,Precision逐渐降低,这才是符合逻辑的。实际计算时,对平滑后的Precision曲线进行均匀采样出11个点(每个点间隔0.1),然后计算这11个点的平均Precision。具体如下:(实际计算时,当Precision下降到一定程度时,后面就直接默认为0,所以最后6个点取0):
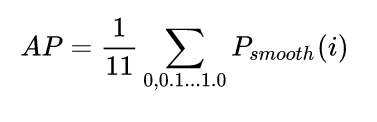
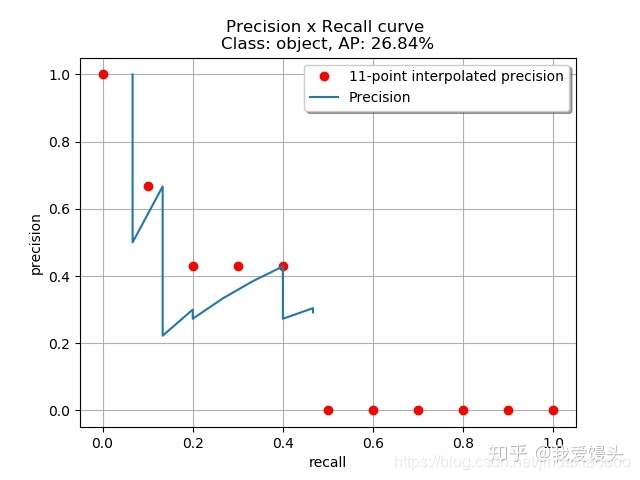
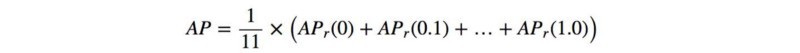
在本例子中,
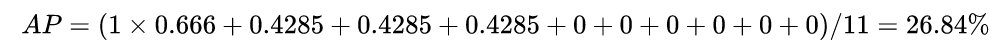 这种计算方法也叫插值AP(Interpolated AP)。对于PASCAL VOC有20个类别,那么mAP就是对20个类别的AP进行平均。
这种计算方法也叫插值AP(Interpolated AP)。对于PASCAL VOC有20个类别,那么mAP就是对20个类别的AP进行平均。
Area under curve AUC,PASCAL VOC2010–2012评测指标
上述11点插值的办法由于插值点数过少,容易导致结果不准。一个解决办法就是内插所有点。所谓内插所有点,其实就是对上述平滑之后的曲线算曲线下面积。
这样计算之所以会更准确一点,可以这么看!原先11点采样其实算的是曲线下面积的近似,具体近似办法是:取10个宽为0.1,高为Precision的小矩形的面积平均。现在这个则不然,现在这个算了无数个点的面积平均,所以结果要准确一些。
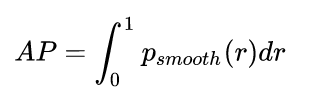
示意图如下:
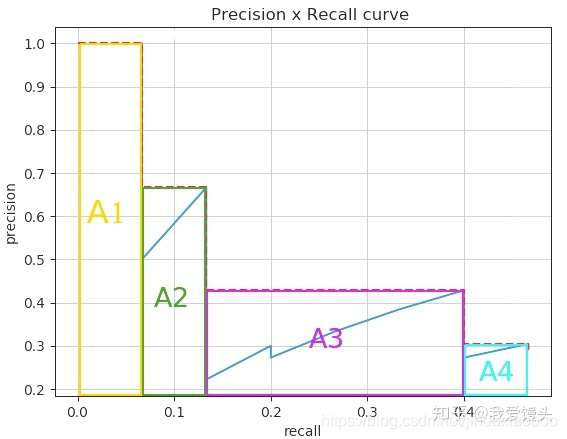
在本例中,

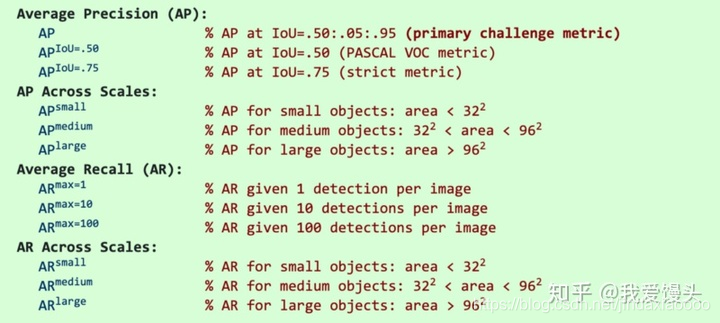
COCO mAP
COCO mAP使用101个点的内插mAP(Interpolated AP),此外,COCO还使用了不同IOU阈值,不同尺度下的AP平均来作为评测结果,比如AP @ [.5 : .95]对应于IoU的平均AP,从0.5到0.95,步长为0.05。下面是具体评价指标介绍:
再比如我们看一下YOLOv3的作者在论文中展示的在coco数据集上的实验结果
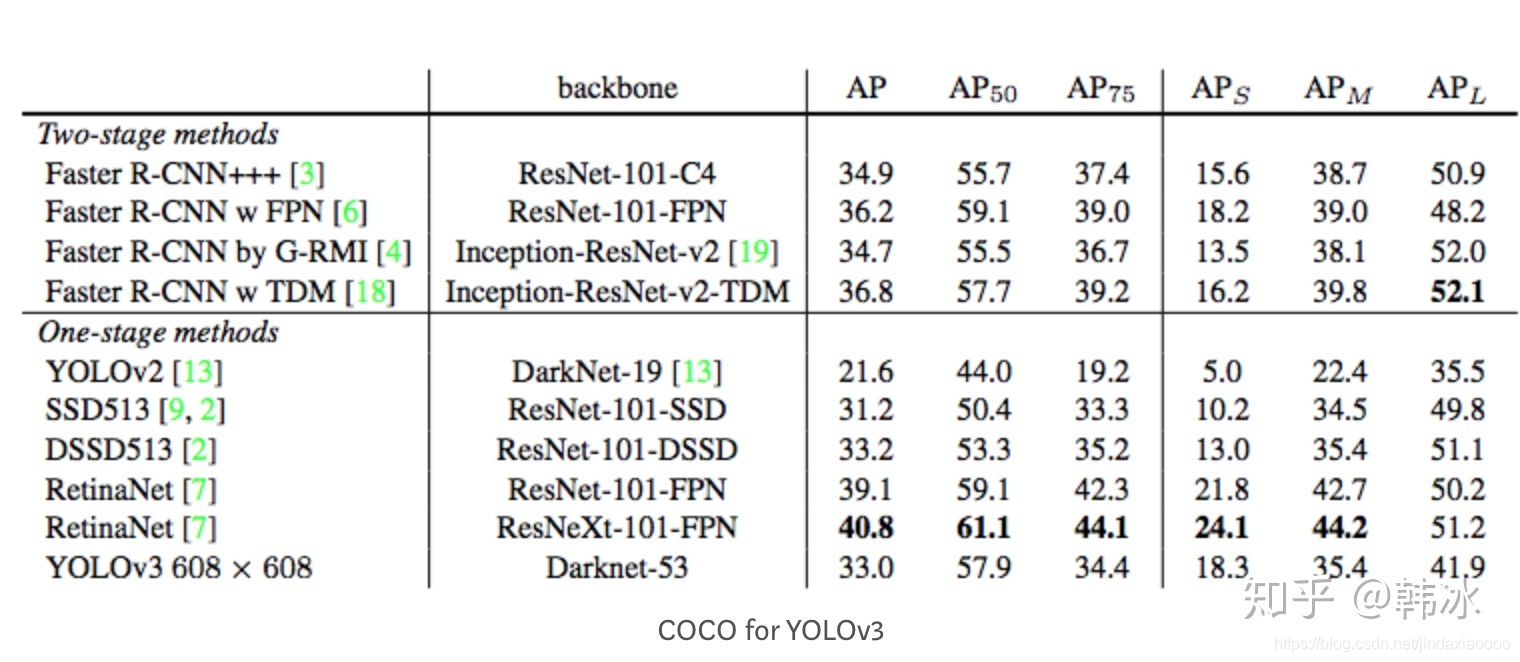

注:通常来说AP是在单个类别下的,mAP是AP值在所有类别下的均值。,值得注意的是,COCO的AP就是指mAP,没有刻意区分二者。
ImageNet目标检测评测指标
在ImageNet目标检测数据集里面则采用上面介绍的AUC方法来计算mAP。一般来说,不同的数据集mAP介绍方法会有一些细微差异。
————————
白话mAP
目标检测中的AP,mAP
这篇关于基础概念——TP、FP、TN、FN、IOU、PR、AP、Interpolated AP、AUC、mAP的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




