interpolated专题
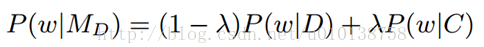
狄里克雷平滑(Dirichlet)、线性插值平滑(Linear Interpolated)、拉普拉斯平滑(Laplacian)
一元语言模型(Unigram Language Model)就是关于全部单词上的一个概率分布,它认为每篇文章都对应一个一元语言模型,文章中的单词都是从这个概率分布中采样得到。所以计算文章和查询语句之间的相关性,相当于计算文章对应的一元语言模型产生出查询语句的概率。 通常我们统计文档中的单词频率分布来估计文章对应的一元语言模型,但是未出现在文档中的单词的概率就被设置为0了,这显然是不合理的。所以需
频谱论文:空间频率插值的无线电地图 Space-Frequency-Interpolated Radio Map
#频谱# K. Sato, K. Suto, K. Inage, K. Adachi and T. Fujii, "Space-Frequency-Interpolated Radio Map," in IEEE Transactions on Vehicular Technology, vol. 70, no. 1, pp. 714-725, Jan. 2021, doi: 10.1109/

基础概念——TP、FP、TN、FN、IOU、PR、AP、Interpolated AP、AUC、mAP
TP、FP、TN、FN 都是站在预测的立场看的: TP:预测为正是正确的 FP:预测为正是错误的 TN:预测为负是正确的 FN:预测为负是错误的 准确率(accuracy),精确率(Precision)和召回率(Recall) 准确度:分类器正确分类的样本数与总样本数之比 (TP+TN)/ (TP+TN+FP+FN) 精准率Precision:所有被预测为正样本的样本中预测对的比例 (T