本文主要是介绍狄里克雷平滑(Dirichlet)、线性插值平滑(Linear Interpolated)、拉普拉斯平滑(Laplacian),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一元语言模型(Unigram Language Model)就是关于全部单词上的一个概率分布,它认为每篇文章都对应一个一元语言模型,文章中的单词都是从这个概率分布中采样得到。所以计算文章和查询语句之间的相关性,相当于计算文章对应的一元语言模型产生出查询语句的概率。
通常我们统计文档中的单词频率分布来估计文章对应的一元语言模型,但是未出现在文档中的单词的概率就被设置为0了,这显然是不合理的。所以需要对得到的一元语言模型进行平滑,使其更接近真实的概率分布。(说白了就是给那些未出现在文档中的单词分配些概率)
一,线性插值平滑
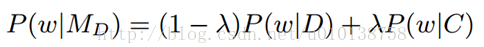
上式是线性插值平滑法,其中P(w|D)表示从文档中估计得到的单词w的概率(也就是单词w的在文档D中出现的个数除以文档D中单词总数)。P(w|C)是从语料库中估计得到的单词w的概率(也就是单词w的在语料库C中出现的个数除以语料库C中单词总数)。λ是平滑参数,调整两种概率之间的权重。MD是最后得到的一元语言模型,P(w|MD)表示一元语言模型MD产生单词w的概率。
文档中单词个数有限,对一些和本文档主题无关的单词w,它的P(w|D)很可能为0。但是语料库C表示所有文档的集合,所以P(w|C)
这篇关于狄里克雷平滑(Dirichlet)、线性插值平滑(Linear Interpolated)、拉普拉斯平滑(Laplacian)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









