本文主要是介绍【20年扬大真题】设顺序表va中的数据元素递增有序。试写一算法,将x插入到顺序表的适当位置上,以保障该表的有序性。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【20年扬大真题】
设顺序表va中的数据元素递增有序。
试写一算法,将x插入到顺序表的适当位置上,以保障该表的有序性。
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<malloc.h>
#define MaxSize 9//定义最大长度
int InitArr[10] = { 1,2,3,5,6,7,8,9,10 };typedef struct {int data[MaxSize];//用静态的数据存放数据元素int length;//顺序表当前长度
}Sqlist;//顺序表的类型定义//初始化一个顺序表
void InitList(Sqlist* L)
{for (int i = 0;i < MaxSize;i++){L->data[i] = InitArr[i];//将所有数据元素设置为默认初始值}L->length = 9;//顺序表初始长度
}void print(Sqlist* L)
{for (int i = 0;i < L->length;i++){printf("%d ", L->data[i]);}
}void InsertL(Sqlist* L,int x) {int i = 0;for (i = L->length-1;i >=0;i--){if ((*L).data[i] > x) {(*L).data[i + 1] = (*L).data[i];}else {(*L).data[i + 1] = x;break;}}
}
int main()
{Sqlist L;InitList(&L);//初始化一个顺序表1 2 3 5 6 7 8 9 10printf("原始顺序表为:");print(&L);printf("\n");InsertL(&L, 4);printf("插入4后顺序表为:");print(&L);
}
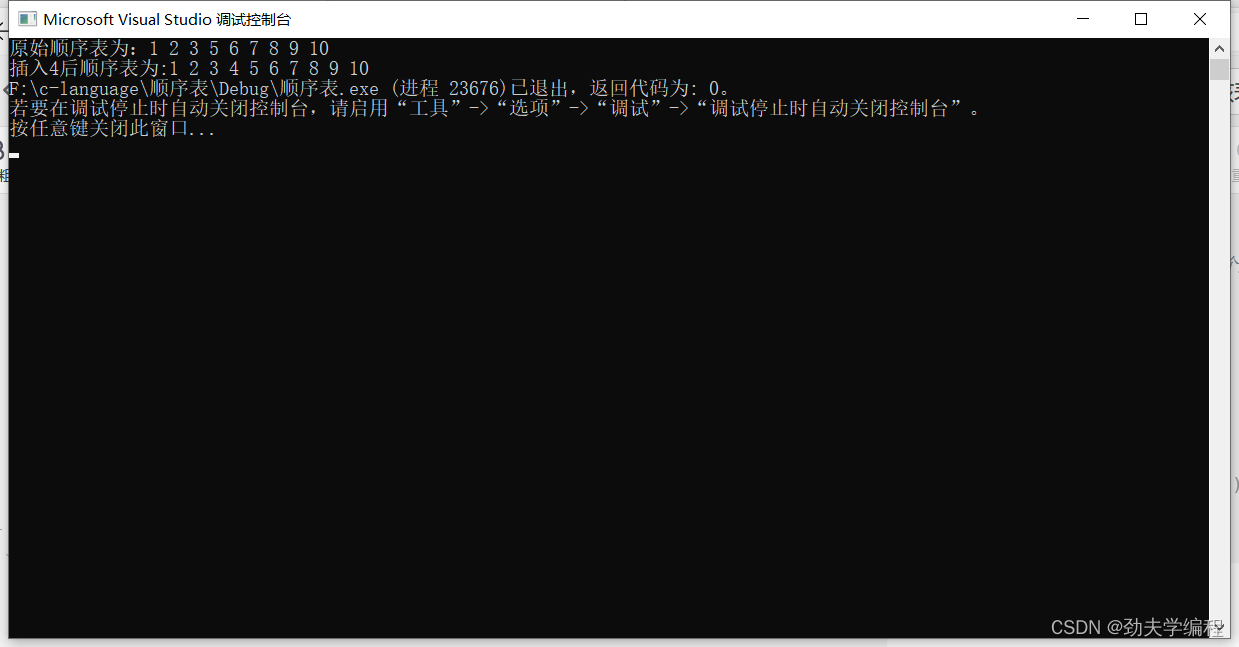
这篇关于【20年扬大真题】设顺序表va中的数据元素递增有序。试写一算法,将x插入到顺序表的适当位置上,以保障该表的有序性。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








