前言:最近jBeanBox项目收尾,感觉用Java初始化块来代替Spring的XML配置这种模式挺好的,手中有了这把锤子,于是看什么都象钉子,这不,又看上了Hibernate, SSH三兄弟,紧跟在Spring后面,也是用XML或Annotation配置,配置也是固定的,不能在运行期动态生成和修改,好了,钉子就是它了。新项目名字都想好了,就叫jSQLBox,用来代替Hibernate。对了,顺便看看Hibernate还有什么其它毛病没有? 可是找来找去,没发现什么缺点,除了太复杂之外,想不出有什么问题。如果只是为了给Hibernate增加一个配置方式而重新发明一遍轮子,岂不是很可笑了,不行,一定要找出点毛病来,没病也得挑出病来。于是左看右看,也不知是我眼花了还是看的时间太长了,现在越看越觉得Hibernate象是一个过度设计的例子。于是本吐槽文诞生了,Hibernate的铁杆拥趸们可以不用看了,因为本文的目的就是贬低Hibernate,借以抬高这个八字还没一撇的jSQLBox。
开始前,先澄清一下"领域逻辑"和"领域模型"这两个词的区别,"领域逻辑"表示企业的内在业务规律,与是否使用了软件无关,这一点应该没什么疑问。 "领域模型"从中文字面理解应该是一个企业的业务模型,与软件术语无关,但是这个词在Martin的《企业架构》书中被转换成另一个含义,就是建立在面象对象基础上的概念模型,模型本身包含数据和行为,这与软件工程中的对象模型概念恰好一一对应,于是"领域模型"往往和"对象模型"等价,并且由面象对象软件来实现。 "领域模型"不是本文讨论的重点。但是笔者的观点是企业应用恰恰是 "领域模型"不能发挥作用的场合,这属于个人观点,如有不同意见请先别拍砖,听听我的理由:1)当一个问题复杂到用表格不能处理,必须借助面象对象模型来实现的地步时,通常已经非常复杂或冗长,已超出了人能理解和操纵的范围,适合计算机处理;而企业逻辑通常和人、钱、物打交道,逻辑简单,是能被企业中的业务专家理解和解释的,用复杂的模型来解决本质上很简单的问题是把问题复杂化。企业业务专家的头脑中基本没有对象、继承这些概念,他们的头脑中通常是一张张数据表,典型的代表就是企业会计,和他们谈面象对象是对牛弹琴。来到哪个国家,就要说哪个国家的语言,这才好交流。2)解决复杂问题的面象对象模型通常不是并发访问的,因为业务本身的复杂性使得并发访问编程难度极大,也就是说当你想解决的问题越来复杂时,业务本身的并发限制就越来越高,就越来越不能被称作企业应用3)面象对象模型通常用树或图结构来表示,往往必须用专用格式来保存,很难用统一的格式来存储,例如Office文档、三维制图、电路排版软件、网页文档等,它们各自有自已的专有文件格式,虽然有XML之类的通用格式,但显然XML是一种树结构而不是可以放进数据库的表结构。个别情况下,对象模型本身就是持久层,如电路板布线图,打印出来就可以用于生产排版。当一个面象对象模型可以用O-R工具来映射成数据库表保存时,只能说明这个模型太简单了,简单到可以直接用少数表格来表达了。4)面象对象模型是随着计算机技术进展才出现的,最常见的应用场合是在计算机帮助下可以建立以往人力不能建立的复杂模型,建模经常是工作的全部或重点;而企业应用建模本身不是重点,因为企业逻辑在面象对象概念提出之前已经存在,软件只是对企业逻辑进行表达和梳理,帮助企业逻辑更好地运作而产生效益。综上而言,用面象对象这个工具来处理企业应用,很可能是杀鸡用牛刀了,牛刀能不能杀鸡? 当然能,但是要练好牛刀很难,让一个开发团队都练好,更难。
在"领域模型"和"领域建模"出现之前,企业应用软件开始编制前,也是要建模的,这通常表示为互相关联的表格,并辅之以文字或图形、线条等来表达这些表格之间的关系,这就是传统的E-R模型(即通常说的”数据建模”)。本文以图1来说明一种基于数据(表)建立企业逻辑模型的优点,(如因转载原因不可见,请打开此图所在网页: https://github.com/drinkjava2/jSQLBox图片文件名为p1.png,因为下文都是基于此图展开讨论)
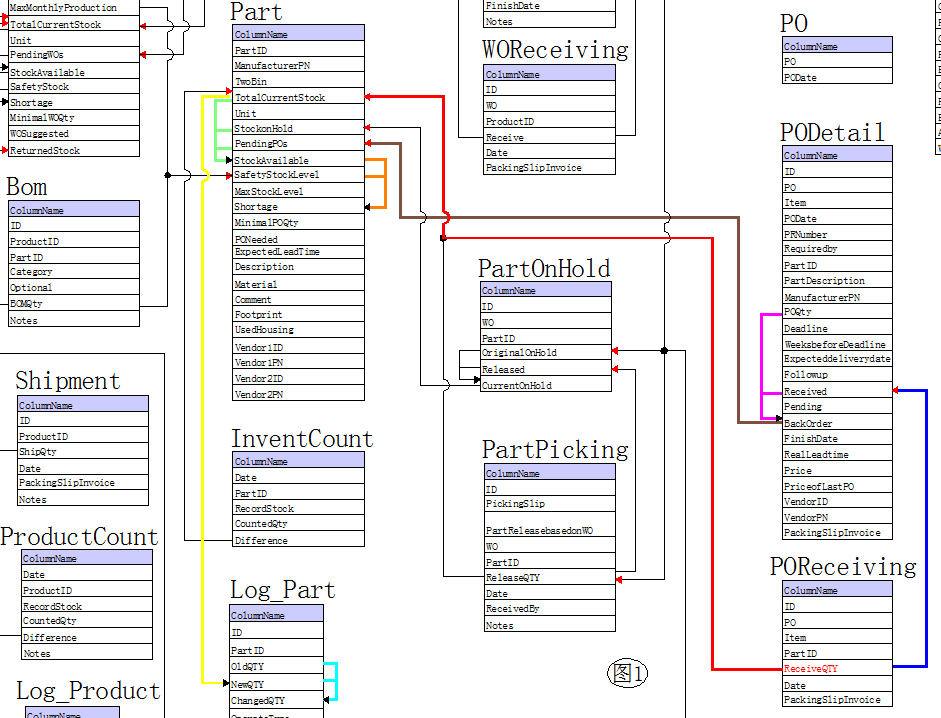
这是我两年前做的一个给公司内部使用的小型MRP程序中提取的数据库建模局部截图,它建立在E-R图基础上,但略有不同,E-R图常见的键关联线没有了,因为不仅太小儿科了,而且干拢了真正的企业逻辑。取而代之的是添上了反映业务逻辑的线条(原图全是黑线,为了讲解本例加粗并上色)。上图线条表示各个字段间的约束或驱动关系,每根线条我称其为领域逻辑线,因为它具有与编程语言无关,与界面无关,只反映业务逻辑,比较稳定的特点,这个例子比较简单,只有数据的驱动关系线,没有约束、检查关系线,也没有用到角色(数据可以驱动角色,角色也可以驱动数据,例如一个标记字段驱动一个审核角色,审核完后又驱动这个字段,然后这个字段又开始驱动下一下审核角色…,日期也可以作为一个驱动的来源,等等)
这里只解说一个业务:收货并销单:
这是一个小企业,业务比较简单,库管收货后稍作检查,立即入库和销订单,以下演示从收到1个部件号为”001”的部件的入库流程,以下伪程序脚本,包含在一个事务中(看不懂没关系,只知道有很多步骤,一个步骤对应一种颜色的线就行了):
第1步(红色字): 订单收货记录表(POReceiveing)收货1件(ReciveQTY =1)
第2步(蓝线): 订单明细表(PODetail)收货数加1 (Received = Received +ReceivedQTY)
第3步(紫线): 更新未交订单数量=订单数-收货数(BackOrder =POQty-Received)
第4步(蓝线): 更新库存表(Part)未交货数(PendingPOs =selectsum(backorder ) from PODetail where PartID=”001”)
第5步(绿线):更新可用库存数=当前库存数-预订数+未交货数(StockAvailible=TotalCurrentStock-StockOnHold+PendingPOs)
第6步(橙线):更新库存短缺数=安全库存数-可用库存数(Shortage=SafetyStockLevel-StockAvailible)
第7步(红线):更改当前实际库存数 (TotalCurrentStock= TotalCurrentStock+ ReceivedQTY)
第8 步(黄线和青线):新增一条库存变动记录 (oldQTY=上次库存数,newQTY=TotalCurrentStock,变动数量ChangedQTY=NewQTY-OldQTY)
第9步(绿线)同第5步
第10步(橙线)同第6步
以上是一个完整的收货并销单的操作,这是一个典型的(臭名昭著的)事务脚本式操作,UI调用Service, Service里用10个步骤直接操作数据库并打包在一个事务里,见图2。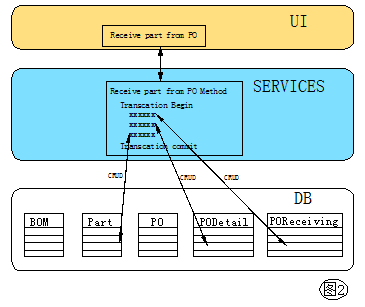
数据建模+事务脚本模式的优点有:
1)实现上,领域逻辑和事务脚本一一对应,技术简单成熟,非常利于领域逻辑到实际代码和单元测试的转化,开发快,项目成功率高,即便是很烂的数据库设计(例如图1中库存表和部件号表共用一张表且承担了需求分析的重任) 和怪异的客户需求(我上一个项目是先发货出厂,再将流水线上的货收入库),只要领域逻辑线条都划上去了,一根不缺,能够自圆其说,不出现循环调用等业务逻辑错误,项目就不大可能失败(外部因素除外)。
2)没有什么高深的理论,就是一张张表格,便于和业务人员交流,表格和线条是业务人员能理解的语言。我公司机械设计部门经理(他是MRP需求提出人)将图1(全图)打印在A3纸上贴在墙上研究,他看懂了整个流程。
缺点有:
1) Service太厚重,所有逻辑放在同一个事务脚本中,不同需求所对应脚本有可能存在重复代码,不利于维护。
2) 对数据库有重复读写现象,加大数据库负担。
3) 单元测试必须依赖数据库。
4) 当领域逻辑非常复杂时,或数据库设计人员对业务不精通或对表格、字段设计不合理,上图中的线条可能非常多且杂乱。另一个极端是,程序员根本就不知道使用绘图工具,很难掌握复杂的领域逻辑关系。事实上,目前建立在事务脚本基础上的很多项目,可能根本就没有类似图1的领域逻辑模型,拿到需求,直接开工裸奔了,这简直是在跟维护人员开玩笑。作为一个机械工程师,设计的第一步就是总装草图,图纸的归档也是以总装图为纲。如果我设计的仪器没有总装图,第二天就得卷铺盖回家了。所以,如果我是软件项目经理,第一件事就是让程序员去学AutoCAD,做软件的学为什么不能学学做机械的画个总装图呢? 太复杂A3纸画不下可能用A2纸,再画不下还可以用1号、0号图纸。Google一下”领域模型图”,出来的大多是一个个孤伶伶的小方块,之间用一两根反映一对多,多对一之类的线单薄地连系着,在一个机械工程师的眼里,这种图太简单了,和小孩玩具似的,没有什么实用价值,反映不出复杂的多表业务装配关系,和只有单薄的键关联线的E-R图基本就是一路货色。UML有许多种图形,但能拿出来和机械的总装图相比,能够反映模块间装配细节的,还真是难找。
对于以上事务脚本缺点的四个缺点,下面我们逐一分析:
1)Service所有逻辑放在同一个脚本事务中,多个不同脚本间存在重复代码。如果是业务本身重复了,在逻辑图中就可以看出来同一个位置有两根线,如果确认这两根线代表了相同的业务逻辑(AutoCAD可以无级放大,在线上可以加小号的文字或图形说明),直接删除其中一根线即可。一些数据访问代码之类的重复,可以将这些底层代码放在公共子程序中。上例中的脚本一共有10步,基本上对应10个子过程调用。对于业务上上永远绑定在一起的逻辑,可以将它们打包在一起,如上例中当前库存数的变动,将总是触发绿、橙、黄、青四色线条,则可以将这四个子过程打包成一个,这样在Service中总的脚本数将减少。上例是用Delphi做的,实际编程中也是这样实践的。对于Java来说原理一样,只不过通常利用Spring的声明式服务,将公共子程序移到了单例Service类中,单例就等于全局静态方法,自已不能有局部变量保持状态,所有参数放在方法参数里传进来。配成单例的唯一目的就是为了在创建时利用Spring生成代理单例,从而实现声明式事务而已。静态方法很难在运行期知道方法的名字,除非用编译期预处理的方式,否则不能根据方法名在事务上做花样。基于事务脚本的程序,方法就代表了业务逻辑,是一等公民。至于方法放在哪个类里,并不太重要。因为在总装图里,代表业务的那根线条始终在那个固定的位置。可能会变化的企业逻辑,可以放在单独的service中,固定的逻辑,不需要考虑重构的,可以写死成数据集的属性方法或service的子方法,当其它业务逻辑访问数据集属性或service时自动触发子方法,这样可以减少事务中重复脚本数量,通过以上优化,10步脚本最终可以简化成2个脚本,其余的脚本将自动被触发。当然这是比较理想的业务之间存在固定的联动关系,实际中是否允许自动触发要视业务本身的松紧藕合来定。
2) 对数据库可能有重复读写现象,加大数据库负担 (我瞎猜估计在2~10倍之间) ,这是个难点,不太好克服。如果不较真的话,可以无视,因为这是一个性能问题,现在的电脑足够快了,通常性能不是问题,如果真成了问题,还可以用钱来解决。钱能解决的问题对于软件业来说就不是问题。但是如果钱少,又要较真的话,或手工在事务脚本里维护一个业务数据缓存,但会造成子程序反向依赖于脚本的严重问题;或使用类似于Hibernate之类的具有一级缓存的,具有脏数据检查功能的ORM或Active Record工具,同一事务中对数据库的访问先从一级缓存中找,从而实现跨越多个子过程的透明持久化(如果Hibernate只能选一个优点,我会投透明持久化这一票)。如果找不到合适的透明持久化工具,可以暂时用Hibernate代替。但个人不是太喜欢Hibernate,因为太复杂了,而且招牌是ORM,容易被误用成面向对象建模,不符合本文提倡的面向数据库建模的思路,即然都沦落到了下嫁数据库表格的地步,还与对象打得火热,也不想想对象的数据结构可能和表构不匹配。大多数面向对象软件用户从不花时间考虑如何存储的问题,只有Hibernate是个特例,使用者不仅要考虑,还必须是专家,因为这是企业应用。不仅需要了解每个数据表字段对应哪个对象属性,同时也要了解每个字段对应哪个业务属性,必要时要调用原生SQL。我构想中的JSQLBox工具应该和Hibernate极为相似,具有它的大部分功能但是去除O-R映射这块,只需要面向数据库而不用考虑面向对象,设计上基于ActiveRecord,这样Dao可以成为ActiveRecord的属性,Session(等同数据库连接)在Spring或jBeanBox(此处纯属广告)的声明事务中注入Dao,不再需要显示获取和注入DAO和Session,脚本中甚至可以直接调用ActiveRecord类的CRUD方法,对简化编程非常有效。 目前已经有很多ActiveRecord工具与上述描述功能类似,但是剔去ORM不谈,总体功能上反倒都不如Hibernate这个ORM工具好用,主要体现在不支持setter方法名重构、缺少透明持久化、原生SQL包装不好或是重新发明另一套SQL语法,当然Hibernate的强势使得它们不流行从而缺少开发者也是一个因素。顺便提一下,面象对象模型和基于ActiveRecord的面向数据表模型,都可以模拟复杂的数据结构,这是它们能解决复杂问题的根本,数据库表也可以表达图、树等结构。如果对象和数据库结构不匹配,就成了麻烦的根源。但是如果对象和数据库结构设计成一模一样,那我要你对象干什么? 绕个弯回来一看,哦,领域建模和数据库建模画出了两张一样的模型图!不同于Hibernate的POJO对象,ActiveRecord模式占用了宝贵的Java单继承,但是ActiveRecord本身就是数据库的一部分,从静态结构来说,数据库本身就可以表达任意结构的数据结构,从动态来说,业务逻辑线就代表了方法,面向数据库建模同时已经具备了数据结构和方法两大编程要素了,这和面象对象模型是相通的,所以有了ActiveRecord就不再需要重复面象对象建模了,使用面象对象时语法糖多一点(一对多,多对一自动关联了,不用手工来加载),但是业务模型本质是一样的。至于面象对象的另一要素“封装”,在企业应用中就是个笑话,企业逻辑的代名词就是“不讲道理的,存在即合理的逻辑”,任何不相干的属性,在下一个需求变更中都有可能发生关联,每一笔发货之前可能发生更改部件号和电话号码这种不常见的关联(地下工厂?),也可能关联计算厂长外甥去年这个月收入这种匪夷所思的需求。所以,忘了封装这码事吧。当然,如果你能拍板,把外甥开除是干净利落得到一个漂亮模型的好方法,可你只是个敲码工,总不好意思对厂长说“把外甥开除吧,这样我编程序会容易一些”,所以还是老老实实地实现这些怪异的需求,就把数据表的每个字段都当成public的就好了。
3)单元测试必须依赖数据库。测试时每次清空数据库填充数据,可能有点麻烦,但个人认为这是个可以忍受的小问题,可以无视。但即然有这个问题,那就顺便提一下。如果使用跨数据库的工具(如Hibernate或想象中的八字没一撇的jSQLBox)来填充数据是可以做到测试代码不依赖于特定数据库的(原生SQL除外,但原生SQL本身也是易移植的)。Mock数据库倒象是个反模式。
4) 领域逻辑非常复杂时,类似于图1的领域逻辑图会很大(真有可能用到0号图纸),且很复杂,从而很难读懂和检查错误。这个问题的解决我有几个思路,或者说是猜测,因为我只是个画图的,编软件纯属客串,没碰到过复杂的业务模型:
第一种可能:领域逻辑图的设计人员有问题,更换一个对业务更熟悉的数据库设计人员即可以加以优化。
第二种可能:同时具备规模非常大(即数据库表格很多)且非常复杂(表格间关联关系象蜘蛛网一样纵横交错,见图3)的领域逻辑根本就不存在或根本就是个错误的假想中的业务设计,因为企业模型是和人打交道的,太复杂的逻辑不光是设计人员设计不出来,使用它的人也会无法理解,所以不用担心领域逻辑图会复杂到不能设计出来和不能读懂,一个好的业务逻辑体现在图纸上也必然具有高内聚,低耦合的特性,见图4。
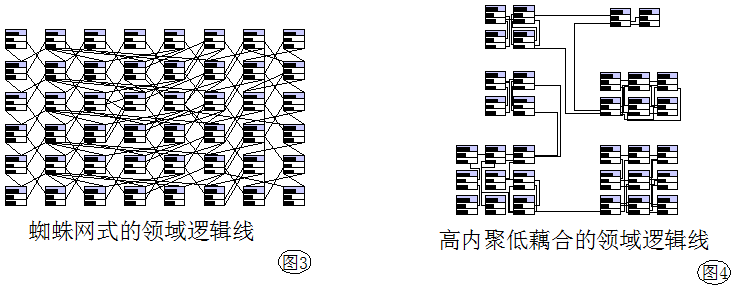
这不是巧合,这和人脑处理问题的方式有关,人脑不习惯处理一堆乱麻的信息,人类社会早就把具有紧密关联的事物划在一起以方便处理,这是这个社会运作的基本道理,是已经存在的事实现状,我们只需要乐享其成就行了。(很多ERP实施失败的原因就在于模型虽然完美,但是太复杂了,超过了使用者在有限的培训时间里能理解的极限;或是将本来是松耦合的模块作了太多关联,严丝合扣,导致一个部门的停顿会使得整个系统停摆。) 请记住一个关键(重要事情说几遍来着):企业应用是所有软件类别中比较简单低等的一类,它必须简单到被业务人员提出和使用,必须简单到能很快被业务外行的程序员理解。
第三种可能是:表格多且表间连线又多又复杂的企业应用确实存在(虽然怀疑这点),那么可以参考集成电路排版,利用一个类似电子板自动布线软件(这个倒是真正面向对象的了)来代替AutoCAD手工布线,把线布置得规距平整,线上可以附注解,可以帮助设计和阅图人员更容易读懂图,这里布线成了重点,目前一些工具如Rose或PowerDesigner之类的,可能已经已有此功能,也可能没有,我不是太熟悉。甚至有可能利用软件来自动生成所有子程序名称,单元测试过程名称,从总体架构上把软件粗略搭出个草稿出来,因为基于数据库表设计的模型是接地气的,表模型即等于数据库表,线条即等于方法名(驱动方法、约束方法等),而且我猜想规模越大、线条越多的结构图,单个方法反而越简单,道理同上,因为符合人们处理事物的方式,看看集成电路上成千上万个晶体管就知道了,越是复杂的芯片数量越少,越是简单的芯片数量越多。
综上所述,基于数据建模的事务脚本优点很多,缺点有一些但还是有办法改进,相比于问题重重,甚至有些疑问连专家(联想到以其昏昏,使人昭昭这个成语了) 都讲不清的领域模型来说,数据建模+事务脚本无疑应是以完工为第一目标的程序员的首选。至于可维护性,如果能做到始终保持代码和企业逻辑线图大体一致,可维护性也是非常好的,不管再复杂,线条多少,哪怕一天中复制粘贴一万行脚本,如果概念上清晰就不容易出错,可维护性并不见得与代码行数相关。另外说一下,数据建模并不完全排斥面象对象,在某些场合需要利用对象的威力的时候不防用之,如 BOM的展开计算可以将BOM表读入内存后转为对象树结构以方便操作,这是局部利用,但整个系统没必要全改成对象,还是以数据建模为主。实际上ActiveRecord也是一种对象,只不过是一种和数据库表格行一对一的贫血的对象而已,即使把业务逻辑方法写进去等待自动触发,它还是贫血的,因为逻辑方法只属于总装图或局部总装图,不属于哪个数据表,要随时做好把方法删除、修改、移出去的心理准备,原因只有一个:因为这是低级的、不讲理的企业应用。
以上内容纯属个人见解,如有不同见解者,请试举一实例来反驳。有哪个企业应用不能用数据建模(加上领域逻辑线)的方式来表示业务逻辑,而必须用领域建模来表示? 或是用了领域建模之后,不能用数据建模方式来表达的? 或是使用领域建模在建模速度和代码实现上,远远快于用数据建模的方式来实现的? (这里先不谈可维护性,因为目前大多数事务脚本项目都没有我所说的这种总装图,这是不才两年前才发明的,如有雷同将纯属巧合了。)








