本文主要是介绍ViT(Vision Transformer) TNT(Transformer in Transformer),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ViT(Vision Transformer)
ViT的结构
ViT将输入图片分为多个patch(16x16),再将每个patch投影为固定长度的向量送入Transformer,后续encoder的操作和原始Transformer中完全相同。但是因为对图片分类,因此在输入序列中加入一个特殊的token,该token对应的输出即为最后的类别预测。
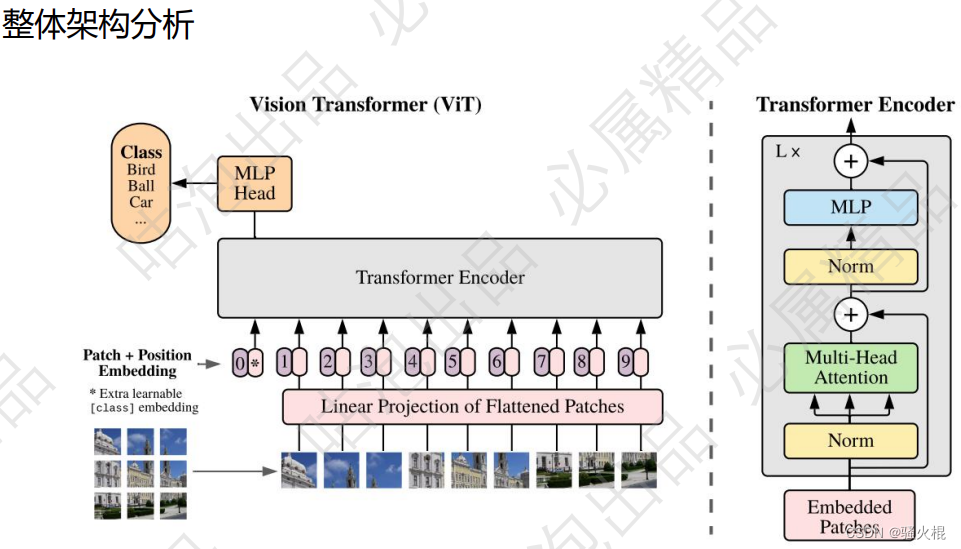
(1) patch embedding
例如输入图片大小为224x224,将图片分为固定大小的patch,patch大小为16x16,则每张图像会生成224x224/16x16=196个patch,即输入序列长度为196,每个patch维度16x16x3=768,线性投射层的维度为768xN (N=768),因此输入通过线性投射层之后的维度依然为196x768,即一共有196个token,每个token的维度是768。这里还需要加上一个特殊字符cls,因此最终的维度是197x768。到目前为止,已经通过patch embedding将一个视觉问题转化为了一个seq2seq问题
(2) positional encoding(standard learnable 1D position embeddings)
ViT同样需要加入位置编码,位置编码可以理解为一张表,表一共有N行,N的大小和输入序列长度相同,每一行代表一个向量,向量的维度和输入序列embedding的维度相同(768)。注意位置编码的操作是sum,而不是concat。加入位置编码信息之后,维度依然是197x768
(3) LN/multi-head attention/LN
LN输出维度依然是197x768。多头自注意力时,先将输入映射到q,k,v,如果只有一个头,qkv的维度都是197x768,如果有12个头(768/12=64),则qkv的维度是197x64,一共有12组qkv,最后再将12组qkv的输出拼接起来,输出维度是197x768,然后在过一层LN,维度依然是197x768
(4) MLP
将维度放大再缩小回去,197x768放大为197x3072,再缩小变为197x768一个block之后维度依然和输入相同,都是197x768,因此可以堆叠多个block。最后会将特殊字符cls对应的输出 作为encoder的最终输出 ,代表最终的image presentation(另一种做法是不加cls字符,对所有的tokens的输出做一个平均),如下图公式,后面接一个MLP进行图片分类。

参考链接:https://zhuanlan.zhihu.com/p/445122996
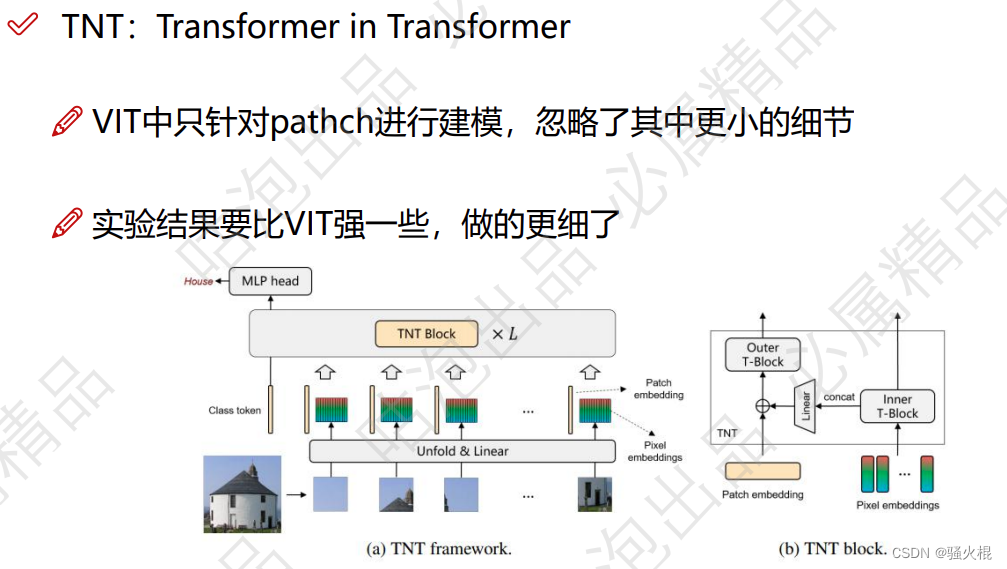
TNT(Transformer in Transformer)
ViT只是利用一个标准Transformer来处理patches序列,而这种patches序列破坏每个patch的局部结构
相反,Transformer-iN-Transformer (TNT)架构来学习图像中的全局和局部信息。



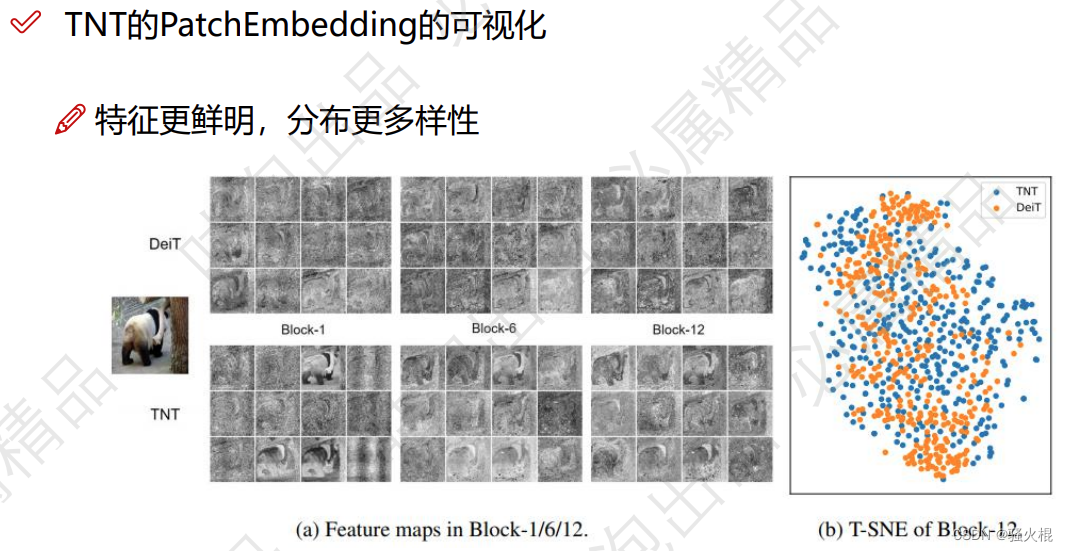
总结
TNT 将图像均匀分割为图像块序列,并将每个图像块视为像素序列。本文还提出了一种 TNT block,其中外 transformer block 用于处理 patch embedding,内 transformer block 用于建模像素嵌入之间的关系。在线性层投影后,将像素嵌入信息加入到图像块嵌入向量中。通过堆叠 TNT block,构建全新 TNT 架构。与传统的视觉 transformer(ViT)相比,TNT 能更好地保存和建模局部信息,用于视觉识别。在 ImageNet 和下游任务上的大量实验都证明了所提出的 TNT 架构的优越性。
参考链接:https://www.jiqizhixin.com/articles/2021-03-03-5
这篇关于ViT(Vision Transformer) TNT(Transformer in Transformer)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









