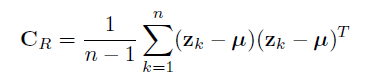本文主要是介绍CS224W5.2——Relational and Iterative Classification,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本节中,我们介绍用于节点分类的关系分类器和迭代分类。
- 从关系分类器开始,我们展示了如何基于邻居的标签迭代更新节点标签的概率。
- 然后讨论迭代分类,通过根据邻居的标签及其特征预测节点标签来改进集体分类。
文章目录
- 1. 框架
- 2. 关系分类
- 3. 迭代分类
- 4. 总结
1. 框架

2. 关系分类

此时,不需要节点特征信息。
如何去做更新:

举例:
初始化:

更新节点3:

在更新节点3之后更新节点4:

再更新节点5:

经过第一轮迭代更新后:

经过第2轮迭代更新后:

经过第3轮迭代更新后:

经过第4轮迭代:

收敛:

以上是关系分类,它仅仅基于每个节点的标签,而没有用到每个节点的特征信息。
3. 迭代分类



迭代分类的架构:

举例:



第一步:

第二步:


第三步:


继续迭代直至收敛:


4. 总结

这篇关于CS224W5.2——Relational and Iterative Classification的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!