本文主要是介绍基于Python的网络爬虫及数据处理---智联招聘人才招聘特征分析与挖掘的算法实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
收藏和点赞,您的关注是我创作的动力
文章目录
- 概要
- 一、研究背景与意义
- 二、数据采集
- 2.1 采集需求
- 2.2 网页分析
- 2.3 数据爬取
- 三、数据可视化以及研究结果
- 3.1 可视化的实现
- 3.2 研究结果
- 四、总结
- 六、 目录
概要
随着科学技术的发展,人类进入了互联网时代,不仅数据量庞大,而且数据种类繁多,Python简单易学, 语法清晰,在数据操作方面有着一定优势,成为了数据采集和可视化领域的热门语言。本论文主要是使用Python来作为开发语言,并对网上招聘信息进行数据采集和可视化,了解和研究网上招聘的现状。采集数据时使用Scrapy抓取网页招聘信息,采集智联招聘职位数据,并将初始数据储存到MySQL数据库中,并得到可视化结果,从而在短时间内了解数据背后的价值与规律。
关键词:Python 数据采集 Scrapy框架 MySQL数据库
一、研究背景与意义
抓不住关键信息,错失了寻找工作的良机。另一方面,企业的招聘方式已经渐渐跟不上时代的步伐。人才是一个企业甚至国家振兴的动力,人才的招聘和引进关系到一个企业是否能够在激烈的社会竞争中脱颖而出,是否招募到足够的人才决定了企业的兴衰。所以,如何招募到所需要的人才资源成为了一个企业发展过程中最为重要的一环。
在当今这个网络异常发达的大数据时代,网上招聘已经成了一种流行趋势。但是网络招聘也存在了许许多多的问题和不足,比如:
(1)招聘信息真实度难以分辨
当今网络招聘面临最大的挑战就是招聘信息的真实度问题。当求职者在招聘网站输入身份信息的时候,有可能导致招聘信息的泄漏和身份信息的曝光,这就是网络招聘发展的过程中所遇到的最大难题。有某些个别的招聘网站由于自身没有足够用来展示的数据信息,就剽窃其他的招聘网页的数据信息来扩充门面。如果这样的活,就会出现一个公司的招聘已经完成了,但那些已经失去作用的招聘信息仍然出现在公司没有发出过信息的网站之上,就变成误导求职者的虚假信息这种情况,耽误了应聘者的时间及精力。
(2)网络招聘服务并不完善
如今的网络招聘大多都是照葫芦画瓢,原样照搬下来招聘信息就草草了事。网络招聘不仅要对人力资源这一课题有着深刻的认识,还必须需要具备过硬的技术底蕴,而且需要强大的语言组织和策划的能力,这样才能吸引更多的投递简历。
(3)招聘信息的处理难度大
在互联网技术不断地进步,各种各样网络招聘信息也不断地出现并且让人目不暇接。网络技术的进步虽然能加快信息的推广与普及,但是也会招致应聘者对应聘岗位的过度竞争,使得招聘公司收到繁多的简历。这样的话就会意味着招聘公司在网络招聘方面的投入会不断增加,从而增加招聘公司的负担。
因此,一份能够自动爬取网上招聘信息并进行整理存储的爬虫就派上了用场。本篇论文采用Python语言编写的一个采集数据和进行可视化处理系统。本设计使用Scrapy框架来采集需要用到的网络招聘信息,然后把爬取下来的数据存入MySQL数据库之中,在对这些数据进行数据可视化处理。就能够通过这些结果来认识理解相关的招聘因素的关系,让毕业生们更加直观的,清晰地了解相关工作的薪资待遇及工作前景。更加方便的选取适合自己的工作职位。招聘网站数据可视化分析平台从各种的招聘信息中提取出有价值的数据,并以数字图像的形式进行直观化展示。把用户从杂乱无章的数据里面解放出来。通过该设计能够更高效地理解和分析据聘数据信息,快速寻找对于自
身有用的信息。使得招聘信息能够更加有效地传述。有利于求职者明确自己的学习方向,掌握需要的工作技能。
二、数据采集
2.1 采集需求
本篇论文采集的目的网站是智联招聘,需要从其中获取一些职位各种相关的信息,用来为完成后面的数据可视化部分做好准备,需要获取的信息大概包括以下几个方面:各个职位特有的ID,职位所在的城市,职位的薪资水平,职位类型,职位要求学历,职位的标签,职位要求的工作经验等等。
2.2 网页分析
首先打开电脑浏览器,在搜索框中输入智联招聘,点击并且进入智联网站主页。然后在搜索栏中输入通信工程师,并进行搜索。搜索结果如图3.1所示
图 3.1搜索结果图
本篇设计所需要的网络招聘代码数据并没有在这里出现,其实发现数据数据应该是从别地方的请求传递而来的。在这里需要找到浏览器设置,点击进入开发者模式,点击Network。下一步点击XHR–>点击的requests–>在response中可以看到需要的数据就在这里如图3.2。
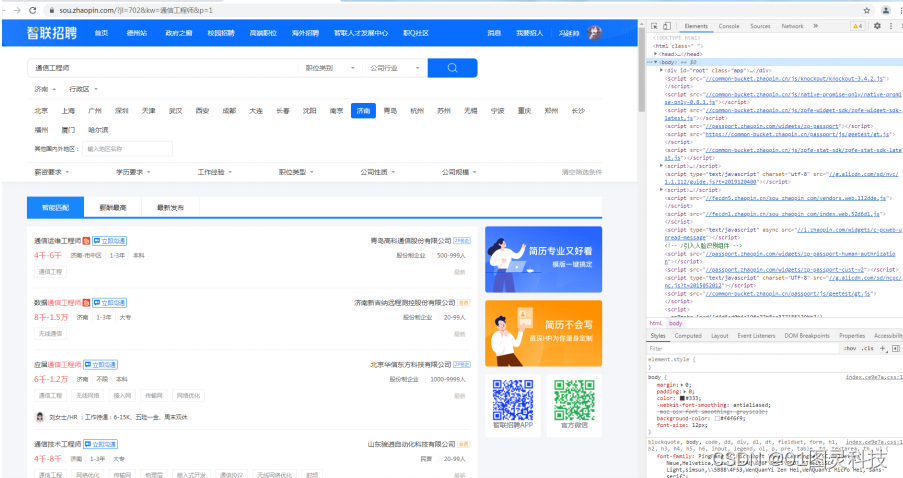
图 3.2源代码效果图
从图3.2发现这些服务器返回数据格式是是json类型,这样就很方便解析了。
2.3 数据爬取
因为爬虫抓取的数据量工作较大,所以为了更加高效地进行数据分析,采用Excel的方式工作效率开始明显降低。
因此,采用数据库技术进行存储是必要的[2]。从这里开始,正式开始构建程序的大体框架,首先需要用代码来模拟虚拟用户向智联网站的服务器发送请求查询数据。正因为如此,这里需要构造相关参数的程序请求头请求智联官网网页,相关的代码如3.3图所示:

三、数据可视化以及研究结果
3.1 可视化的实现
在获取到所以需要的数据之后,剩下的最后一步就是可视化的实现,由于从数据库获取到的数据类型是dict类型,我们先用a来等于字典全部的键,用b来等于字典全部的值。做可视化采用Python很方便,使用plt.bar,这样一来就能得到一个直方图,再通过show将图展示出来,并使用savefig将图存储成图片就完成了。
3.2 研究结果
通过本篇论文设计程序的运行,最终得到了结果图6.1,图6.2,图6.3,图6.4所示:
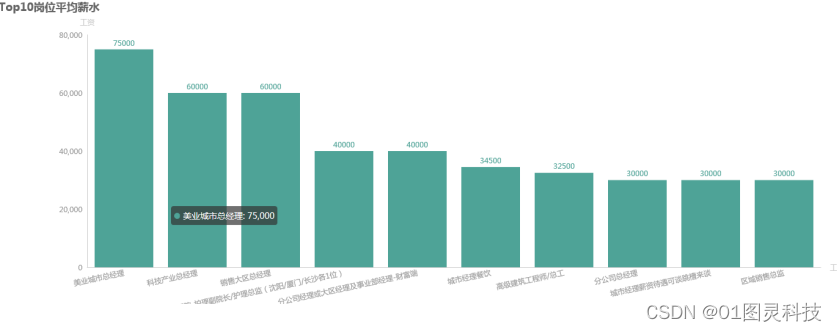
图 6.1不同岗位的平均薪资
从上图可以清楚地看到不同职位之间的薪资水平以及差距,这就大大减少了求职者时间与精力的浪费,为求职者职位挑选提供了可靠地参考。
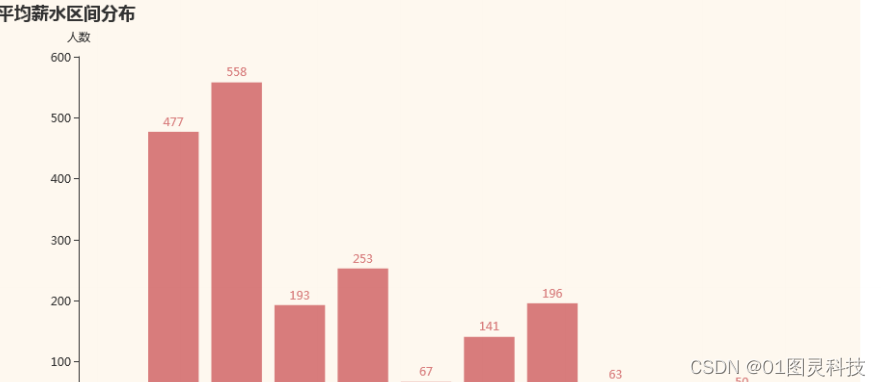
图 6.2工作平均薪资的分布水平
通过图6.2可见,大多数职位的薪资大都集中在1000-5000之间,随着薪水增长,所对应的人数更加稀少。
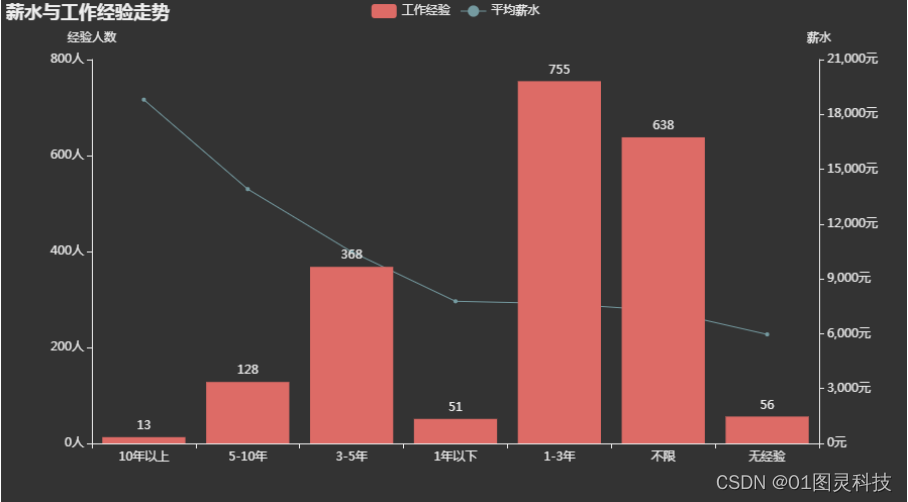
图 6.3薪资与工作经验的关系
由图6.3所示,招聘人数最多的往往要求工作经历在1到3年之间,而要求10年的招聘岗位最少,这说明,随着互联网技术的发展,各种岗位的更新换代也在不断加速,企业最需要的都是有经验的新生代劳动力。
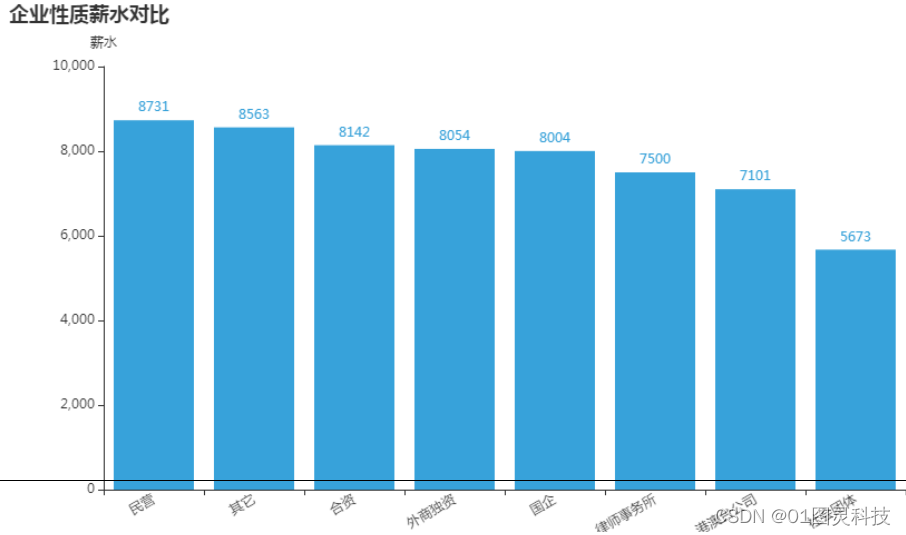
图 6.4 招聘企业薪水水平
通过上图6.4可以清晰地看出,社会团体提供的薪资水平最低,民营企业提供的薪资水平最高。
四、总结
本篇论文主要是利用Python的网络爬虫,通过相应的程序代码,从智联网站上爬取我们所需要的招聘数据,并将这些爬取下来的json类型的网页数据存储进我们建立的关系型数据库(Relational database)MySQL之中,最后通过字段确定,数据获取,可视化实现来展示出我们所需要的结果图,例如平均工资与职位之间的关系,工作经验对于工作薪资待遇的影响等等。
在这次毕业设计中,因为我对Python这门语言一知半解,加上爬取过程相对来说比较复杂,这导致了我在爬取智联招聘网站时花费了大量的实践与精力。虽然说最后勉勉强强完成了一部分指导老师交代的课题要求,但是还存在着许许多多的缺陷与不足,由于之前从未涉及过Python这门语言和MySQL数据库,再加上我的编程功底确实不尽如人意,这让我在Python的过程中频频出错,漏洞百出。在编程过程中,因为对Python语言的不熟悉,我都是一边从网上搜集资料,一边查阅相关Python的书籍进行代码的编写。这样就会有好多Python底层代码特别容易产生逻辑性
错误,面对这些我充分认识到了自己在编程方面还存在着很多不足,这份程序也有待改进。希望在未来的日子里,我也可以通过不断的学习强化自身能力,不辜负学校老师的教育和指导。
六、 目录
1 绪论2
1.1 研究背景及意义2
1.2 研究现状3
1.2.1 国外研究现状3
1.2.2 国内研究现状3
1.3 论文的结构安排4
2 设计原理4
2.1 应用软件介绍4
2.1.1 Python介绍4
2.1.2 爬取框架选择5
2.2 设计思路6
3 数据采集6
3.1 采集需求6
3.2 网页分析7
3.3 数据爬取8
3.4 进行网站数据的分析9
4 MySQL数据库9
4.1 数据库选择9
4.2 将数据存储进数据库10
5 数据的分析处理11
5.1 字段确定11
5.2 招聘数据的获取12
6 数据可视化以及研究结果13
6.1 可视化的实现13
6.2 研究结果13
7 结论及展望16
参考文献:17
致谢18
这篇关于基于Python的网络爬虫及数据处理---智联招聘人才招聘特征分析与挖掘的算法实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





