本文主要是介绍Enhanced Multi-Channel Graph Convolutional Network for Aspect Sentiment Triplet Extraction论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Enhanced Multi-Channel Graph Convolutional Network for Aspect Sentiment Triplet Extraction (2022 ACL)
参考博客: https://blog.csdn.net/qq_40887846/article/details/125136661
Enhanced Multi-Channel Graph Convolutional Network for Aspect Sentiment Triplet Extraction
用于方面情感三元组提取的增强型多通道图卷积网络 (2022 ACL)
论文地址: https://aclanthology.org/2022.acl-long.212.pdf
论文代码: https://github.com/CCChenhao997/EMCGCN-ASTE
个人阅读笔记, 水平有限,如有错误欢迎指正交流
1. 介绍
1.1 研究目标
Aspect Sentiment Triplet Extraction(ASTE)是一种新兴的情感分析任务。目的是从给定的句子中提取方面术语和意见术语,并确定目标意见对的情感极性。

图1:给出了一个带有依赖树的句子来说明ASTE任务。在三元组集合中,方面术语、观点术语分别以蓝色和黄色突出显示。积极的情绪极性以红色突出显示,而消极的情绪极性以绿色突出显示。
1.1.1 如何利用词与词之间的各种关系来帮助ASTE任务?(这里主要是讲方面术语和意见术语的关系)
以图1为例: 对于词对(“gourmet”、“food”),“gourmet"和"food"属于相同一个方面术语"gourmet food”。同样地,对于词对(“food”,“delicious”),“food"是"delicious"的意见术语并且被赋予积极的情感极性。因此,为了有效地提取意见术语"delicious”,我们期望"delicious"能够获得"food"的信息,反之亦然。为了判断意见术语的情感极性,意见术语"delicious"的信息应该被递送到"food"。简而言之,我们需要学习基于单词之间关系的任务相关的单词表征。
1.1.2 如何利用语言特征来帮助ASTE任务?(词性关系和句法依存)
- 我们观察到方面术语“gourmet food”和“service”是名词,而意见术语“delicious”和“poor”是形容词。因此,由名词和形容词组成的词对倾向于形成方面-意见术语对。(这里主要说的是词性关系)
- 从图1中的句法依存关系树,不同的依存关系类型存在于词对中。例如,“gourmet”和“food”包括复合名词,因为它们之间的依存关系类型是“compound”,而“food”由于类型“nsubj”而成为“delicious”的名词性主语。因此,这些依赖关系类型不仅可以帮助提取方面和意见术语,而且还可以帮助它们的配对。此外,我们考虑了基于树和相对位置的距离,描述了两个词的相关性。(这里主要讲的是句法依存关系)
1.2 科学问题
大多数现有的研究集中在设计一个新的标记方案,使模型提取的情感三元组在端到端的方式。然而,这些方法忽略了ASTE任务中单词之间的关系。
1.3 本文方法
本文提出了一个增强的多通道图卷积网络模型(EMCGCN),以充分利用词之间的关系。
具体来说,我们首先定义了ASTE任务的10种类型的关系(表1),然后采用双仿射注意模块嵌入这些关系作为相邻张量在句子中的单词之间。之后,我们的EMC-GCN将句子转换成一个多通道图,通过将单词和关系相邻张量分别作为节点和边处理。因此可以学习关系感知节点表示。此外,我们考虑不同的语言特征,以增强我们的EMC-GCN模型。最后,我们设计了一个有效的细化策略EMC-GCN的词对表示细化,它考虑了隐含的结果方面和意见提取时,确定词对是否匹配或不匹配。
1.4 创新点/贡献
- 针对ASTE任务提出了一种新的EMC-GCN模型。EMC-GCN利用多通道图来编码单词之间的关系。多通道图上的卷积函数被应用于学习关系感知节点表示。
- 我们提出了一种新的方法来充分挖掘语言特征,以增强我们的基于GCN的模型,包括词性组合,句法依赖类型,句子中每个词对的基于树的距离和相对位置距离。
- 对于精炼词对表示我们提出了一个有效的精炼策略。当检查方面意见术语是否配对是,它考虑到了隐式的方面和意见提取的结果。
- 我们在基准数据集上进行了广泛的实验。实验结果表明了EMC-GCN模型的有效性。
2. 任务案例

图1:给出了一个带有依赖树的句子来说明ASTE任务。在三元组集合中,方面术语、观点术语分别以蓝色和黄色突出显示。积极的情绪极性以红色突出显示,而消极的情绪极性以绿色突出显示。
3. 模型架构
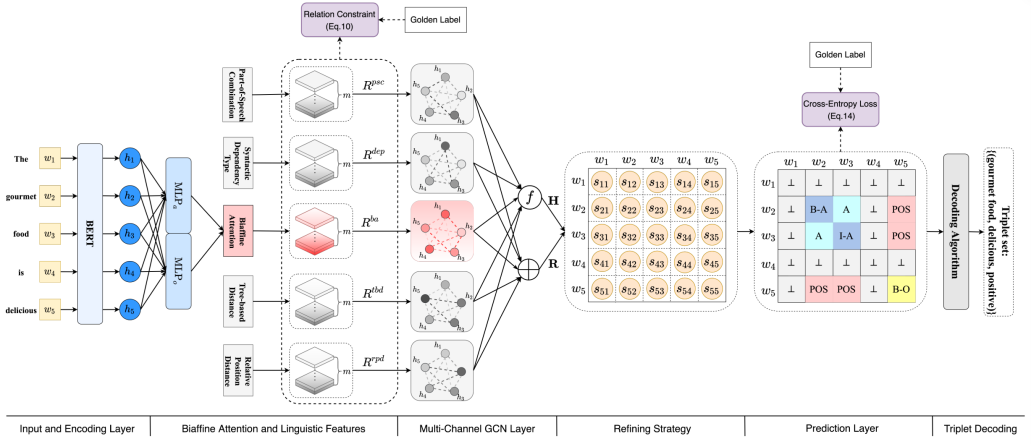
图2:我们的端到端模型EMC-GCN的整体体系结构。
3.1 任务定义
给定具有 n n n个单词的输入句子 X = { w 1 , w 2 , ⋅ ⋅ ⋅ , w n } X = \{w1,w2,· · ·,wn\} X={w1,w2,⋅⋅⋅,wn},模型的目标是输出一组三元组 T = { ( a , o , s ) m } ∣ T ∣ m = 1 T = \{(a,o,s)_m\}^|T|_{m=1} T={(a,o,s)m}∣T∣m=1,其中 a a a和 o o o分别表示方面项和意见项。给定方面的情感极性 s s s属于情感标签集 S = { p o s , n e g , n e u } S = \{pos,neg,neu\} S={pos,neg,neu}。也就是说,情感标签集包括三个情感极性:积极、中立和消极。句子X的总数为 ∣ T ∣ |T| ∣T∣三元组。
3.2 关系定义和表格填写
似曾相识, 和GTS论文很像,但是论文说这是GTS的进化版本。
在一个句子中的ASTE任务, 我们定义了10种类型的关系。这些关系如表1所示。
四个关系或标签 { B − A , I − A , B − O , I − O } \{B-A,I-A,B-O,I-O\} {B−A,I−A,B−O,I−O}旨在提取方面术语和观点术语。

表1:我们定义的十个关系的含义。注意,这些关系也可以被视为标签。

图3:用于句子中的三元组提取的表格填充。每个单元格表示具有关系或标签的词对。有关关系的定义,请参阅表1。
3.3 三元组解码
为了简单起见,我们使用上三角表来解码三元组。(因为table是对称矩阵)
- 基于主对角线使用的预测关系的所有词对 ( w i , w i ) (wi,wi) (wi,wi),提取方面的方面术语和意见术语。(基于主对角线找到方面意见术语)
- 需要判断提取的方面术语和意见术语是否匹配。特别地,对于方面术语 a a a和意见术语 o o o,我们统计所有词对 ( w i , w j ) (wi,wj) (wi,wj)的预测关系,其中 w i ∈ a w_i \in a wi∈a且 w j ∈ o w_j \in o wj∈o。如果在预测的关系中存在任何情感关系,则认为方面术语和观点术语是配对的,否则这两者不配对。(如何配对)
- 为了判断方面-意见对的情感极性,最预测的情感关系 s ∈ S s \in S s∈S被视为情感极性。至此, 我们收集一个三元组 ( a , o , s ) (a,o,s) (a,o,s)。
4. EMC-GCN Model
4.1 输入和编码层 (感觉这里可以通过分词提升模型的效果)
利用BERT作为句子编码器来提取隐藏的上下文表示。给定输入句子 X = { w 1 , w 2 , … w n } X = \{w_1,w_2,…w_n\} X={w1,w2,…wn},在最后一个Transformer块的编码层输出隐藏表示序列 H = { h 1 , h 2 , … h n } H = \{h_1,h_2,…h_n\} H={h1,h2,…hn}。
4.2 双仿射注意模块 (双MLP)
利用双仿射注意模块来捕获句子中每个词对的关系概率分布,双仿射注意在句法依赖分析中已被证明是有效的。双仿射注意过程被公式化为。(这里的双仿射就是双MLP不要被名字吓到了)

其中使用多层感知器。得分向量 r i , j ∈ R 1 × m r_{i,j} \in R^{1×m} ri,j∈R1×m对 w i w_i wi和 w j w_j wj之间的关系进行建模, m m m是关系类型的数量, r i , j , k r_{i,j,k} ri,j,k表示词对 ( w i , w j ) (wi,wj) (wi,wj)的第k种关系类型的得分。邻接张量 R ∈ R n × n × m R\in R^{n×n×m} R∈Rn×n×m描述单词之间的关系,每个通道对应一种关系类型。 U 1 U_1 U1、 U 2 U_2 U2和B是可训练的权重和偏置。 ⊕ \oplus ⊕表示连接。公式(5)收集公式(1)到(4)的过程。
4.3 多通道GCN
为了对单词之间的各种关系进行建模,我们的EMC-GCN扩展了vanilla GCN,其中多通道邻接张量 R b a ∈ R n × n × m R^{ba}\in R^{n×n×m} Rba∈Rn×n×m由上述双仿射注意模块构建。邻接张量的每个通道表示在表1中定义的单词之间的关系的建模。然后,我们利用一个GCN聚合信息沿着每个节点的每个通道。我们将该过程公式化如下。

其中 R : , : , k b a ∈ R n × n R^{ba}_{:,:,k} \in R^{n×n} R:,:,kba∈Rn×n表示 R b a R^{ba} Rba的第 k ¥个信道切片。 k¥个信道切片。 k¥个信道切片。W_k 和 和 和b_k 是可学习的权重和偏差。 σ 是激活函数(例如, R e L U )。平均池化函数 是可学习的权重和偏差。σ是激活函数(例如,ReLU)。平均池化函数 是可学习的权重和偏差。σ是激活函数(例如,ReLU)。平均池化函数f(·)$应用于所有通道的节点隐藏表示。
4.4 语法特征

我们为每个词对引入了四种类型的语言特征,如图4所示,包括词性组合、句法依赖类型、基于树的距离和相对位置距离。
1.句法依赖类型,我们为每个词对 ( w i , w i ) (wi,wi) (wi,wi)添加自依赖类型。特别是,我们基于这些特征随机初始化四个邻接张量,即 R p s c R^{psc} Rpsc, R d e p R^{dep} Rdep, R t b d R^{tbd} Rtbd和 R r p d R^{rpd} Rrpd。以句法依赖类型特征为例。如果在 w i wi wi和 w j wj wj之间存在依赖弧,并且依赖类型是 n s u b j nsubj nsubj,则 R i , j , : d e p R^{dep}_{i,j,:} Ri,j,:dep通过查找可训练的嵌入表被初始化为 n s u b j nsubj nsubj的嵌入;否则,我们初始化 R i , j , : d e p R^{dep}_{i,j,:} Ri,j,:dep一个 m m m维零向量随后,使用这些邻接张量重复图卷积运算以获得节点表示 H p s c H^{psc} Hpsc、 H d e p H^{dep} Hdep、 H t b d H^{tbd} Htbd和 H r p d H^{rpd} Hrpd。最后,我们分别将平均池化函数和级联操作形式化地应用于所有节点表示和所有边。

其中 H = { h 1 , h 2 , . . . , h n } H = \{h_1,h_2,...,h_n\} H={h1,h2,...,hn}和 R = { r 1 , 1 , r 1 , 2 , … r n , n } R = \{r_{1,1},r_{1,2},…r_{n,n}\} R={r1,1,r1,2,…rn,n}表示词对的节点表示和边表示。
4.5 关系约束
为了精确地捕捉单词之间的关系,我们对从仿射模块模获得的相邻张量施加约束,即

其中 I ( ⋅ ) I(·) I(⋅)表示指示符函数, y i j y_{ij} yij是词对 ( w i , w j ) (wi,wj) (wi,wj)的真实标签,并且 C C C表示关系集。同样,我们施加的关系约束的四个相邻的张量产生的语言特征。约束成本表示为 L p s c L_{psc} Lpsc、 L d e p L_{dep} Ldep、 L t b d L_{tbd} Ltbd和 L r p d L_{rpd} Lrpd。
4.6 细化策略和预测层
为了获得用于标签预测的词对 ( w i , w j ) (wi,wj) (wi,wj)的表示,我们将它们的节点表示hi,hj和它们的边缘表示rij连接起来。此外,由分类器链(Read等人,2011)方法在多标签分类任务中的应用,设计了一种有效的细化策略,该策略在判断词对是否匹配时考虑了方面术语和意见术语的隐式结果。具体地,假设 w i w_i wi是方面术语中的词并且 w j w_j wj是观点术语中的词,则词对 ( w i , w j ) (wi,wj) (wi,wj)更可能被预测为情感关系,即, P O S POS POS、 N E U NEU NEU或 N E G NEG NEG。否则,它们不太可能匹配。因此,我们引入 r i i r_{ii} rii和 r j j r_{jj} rjj来细化词对 ( w i , w j ) (wi,wj) (wi,wj)的表示 s i j s_{ij} sij,即,

最后,我们将词对表示 s i j s_{ij} sij馈送到线性层中,随后是 s o f t m a x softmax softmax函数以产生标签概率分布 p i j p_{ij} pij,即,
其中 W p W_p Wp和 b p b_p bp是可学习的权重和偏差。

4.7 损失函数
我们的目标是最小化目标函数

其中系数 α α α和 β β β用于调整对应关系约束损失的影响。标准交叉熵损失 L p L_p Lp用于ASTE任务,即,
5. 实验结果
5.1 对比实验


5.2 消融实验
对论文提出的改进进行消融实验。
分别是十种关系,语义特征,关系约束,以及细化策略

细化策略。

这篇关于Enhanced Multi-Channel Graph Convolutional Network for Aspect Sentiment Triplet Extraction论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






