本文主要是介绍Semantic-Guided Zero-Shot Learning for Low-Light ImageVideo Enhancement,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Semantic-Guided Zero-Shot Learning for Low-Light Image/Video Enhancement
代码: https://github.com/ShenZheng2000/SemantiGuided-Low-Light-Image-Enhancement
在低光条件下增加亮度的一个可行方法是使用更高的ISO或更长时间的曝光时间。然而,这些策略分别加剧了噪声和引入了运动模糊[2]。另一种合理的方法是使用Photoshop或Lightroom等现代软件进行光线调整。然而,这些软件需要艺术技能,并且对于不同光照条件的大规模数据集效率低下。
近年来,基于深度学习的低照度图像增强方法因其令人瞩目的高效性、准确性和鲁棒性而受到广泛关注。监督方法[33,48,52,45]在上得分最高。一些基准数据集[47,13,35,25]具有出色的图像到图像映射能力。然而,它们需要成对的训练图像(即低/正常光线对),这要么需要昂贵的润饰,要么要求不可实现的具有相同场景但不同照明条件的图像捕捉。另一方面,无监督方法[20]只需要一个未配对的数据集进行训练。尽管如此,人工选择的数据集的数据偏差限制了他们的泛化能力。零样本学习[11,27]方法消除了对成对图像和未配对数据集的需要。然而,它们忽略了语义信息,[37,10,31]表明这对高级视觉任务至关重要。因此,他们增强的图像在次优视觉质量。图1揭示了在以往研究中的局限性.
针对上述局限性,我们提出了语义指导的低照度图像增强零元框架(图 2)。由于我们专注于低照度图像/视频增强,我们首先设计了一个轻量级增强因子提取(EFE)网络,该网络具有深度可分离卷积[15]和对称跳转连接。可分离卷积[15]和对称跳转连接设计轻量级增强因子提取(EFE)网络。EFE 具有很强的自适应能力,可以利用低照度图像的空间信息来增强图像/视频效果。为了以可承受的模型大小执行图像增强,我们随后引入了递归图像增强(RIE)网络。
图像增强(RIE)网络 能够逐步增强图像,将前一阶段的输出作为后一递归阶段的输入。为了在增强过程中保留语义信息,我们最后
最后,我们提出了一种无监督语义分割(USS)网络,无需昂贵的分割注释。该网络USS 接收来自 RIE 的增强图像,并利用
特征金字塔网络 [29] 来计算分割损失。分割损失与其他非参考损失函数合并为总损失,并在训练过程中更新 EFE 的参数。建议工作的贡献总结如下:
- 我们提出了一种新的以语义为指导的零元低照度图像增强网络。据我们所知,我们是第一个将高层次语义信息与低照度图像增强网络相融合的框架。
- 我们开发了一个轻量级的卷积神经网络来自动提取增强因子,它记录了低照度图像像素级的光照不足。
- 设计了一种循环图像增强策略,其中包含五个非参考损失函数,以提高模型对不同光照条件图像的泛化能力。
- 进行了广泛的实验,证明了模型在定性和定量指标上的优越性。我们的模型是低光视频增强的理想选择,因为它可以在单GPU上1秒内处理1000张大小1200 × 900的图像
3.1. Enhancement Factor Extraction Network
增强因子提取(EFE)旨在学习低照度图像的像素级光不足,记录该信息在增强因子中。受启发受U-Net[42]架构的启发,EFE是一个具有对称跳过连接的全卷积神经网络,这意味着它可以处理任意大小的输入图像。没有采用批量归一化或上/下采样,因为它们会破坏增强图像的空间连贯性[43,21,18]。EFE中的每个卷积块由一个3 × 3深度可分离卷积层和随后的ReLU[38]激活层组成。最后一个卷积块将通道数量从32减少到3,并通过Tanh激活输出增强因子xr。图3将从2幅低照度图像中提取的增强因子可视化。可见,低照度图像中较亮的区域对应较低的增强因子值,反之亦然。
3.2. Recurrent Image Enhancement Network
受递归[41,55,28]和光增强曲线[50,11]在低照度图像增强中的成功启发,我们构建了一个递归图像增强(RIE)网络,根据增强因子对低照度图像进行增强,然后输出增强后的图像。每个递归都将前一阶段的输出和增强因子作为其输入。循环增强的过程如下:
其中x为输出,xr为增强因子,t为递归步长。下一步是决定照亮图像的最佳顺序。由于循环网络应该是简单的微分,并且应该是有效的对于渐进减轻,我们只考虑正整数的顺序。考虑到这一点,我们在图中绘制关于不同xr和顺序的递归图像增强。4. 阶数为1时,像素值对xr不敏感,与上一阶段相同。当Order等于3或4时,像素值接近甚至超过1.0,使图像看起来太亮。相比之下,2的顺序赋予最鲁棒的递归增强。
3.3. Unsupervised Semantic Segmentation Network
无监督语义分割(USS)网络旨在对增强后的图像进行精确的像素分割,在渐进图像增强的过程中保持语义信息。与[7,32,46,12]类似,我们在训练期间冻结分割网络的所有层。在这里,我们使用两个路径,包括bottom- bottom路径,它使用ResNet-50[14]与ImageNet[5]权重,以及top-down路径,它使用高斯初始化,均值为0,标准差为0.01。两条通路都有四个卷积块,它们通过横向连接相互连接。权重初始化的选择将在消融研究中解释。
来自RIE的增强图像将首先进入自下而上的路径进行特征提取。然后,自上而下的路径将高语义层转换为高分辨率层,以进行空间感知的语义分割。自顶向下方法中的每个卷积块对图像执行双线性上采样,并将其与横向结果连接。为了更好的感知质量,在拼接后应用了两个平滑的3×3卷积层。最后,我们将中每个块的结果连接起来并计算分割。
3.4. Loss Functions
采用5种无参考损失函数,包括Lspa、Lrgb、Lbri、Ltv和Lsem。我们没有考虑由于配对训练图像不可用而造成的内容损失或感知损失[35]。
**空间一致性损失**这种空间一致性损失通过在增强过程中保留相邻像素的差异,有助于保持低照度图像和增强图像之间的空间一致性。与[11,27]只考虑相邻单元不同,我们还包括与非相邻单元的空间一致性(见图5)。空间一致性损失为:
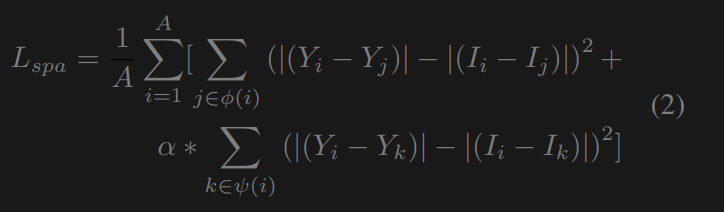
其中,Y和I分别是增强图像和低照度图像中a × a局部区域的平均像素值。A为局部区域的一侧,根据消融研究,我们将设为4。ψ(i)是四个相邻的邻域值(top, down, left, right), ψ(i)是四个不相邻的邻域值(top left, top right, lower left, lower right)。α值为0.5是因为非相邻邻居的权重不那么重要。
RGB 损失 色彩损失[45, 52, 11]通过桥接不同的色彩通道来减少增强图像中的色彩不正确性。我们采用的是 Charbonnier 损失,它有助于高质量图像重建[23, 19]。RGB 损失为
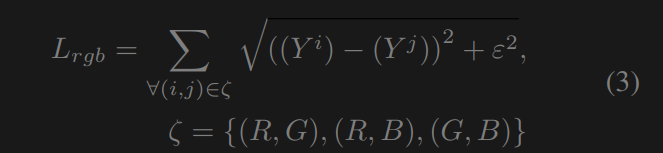
其中,ε是一个惩罚项,根据经验将其设置为10−6,以提高训练稳定性。
亮度损失 受[34,45,11]的启发,我们设计了亮度损失来限制图像中的曝光不足/过度。损失衡量的是两者之间的L1差特定区域到预定义曝光水平e的平均像素值,亮度损失为
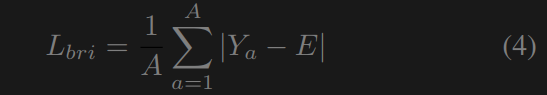
其中E是理想的图像曝光等级,设置为0。消融研究显示60。总变差损失总变差损失[3]测量图像中相邻像素之间的差异。我们在这里使用全变差损失来减少噪声并增加图像的平滑性。与之前的低照度图像增强工作[48,52,45,11]不同,我们在损失中额外考虑通道间(R, G和B)关系以改善颜色亮度。我们的总变差损失为:
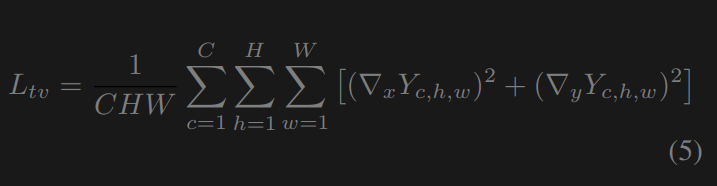
其中C、H、W分别表示图像的通道、高度、宽度。∇x和∇y分别是水平和垂直的梯度运算。语义损失语义损失有助于在增强过程中保持图像的语义信息。我们参考焦点损失[30]来编写我们的成本函数。消融研究推荐的语义损失不需要分割标签,只需要一个预先初始化的模型。语义损失为:
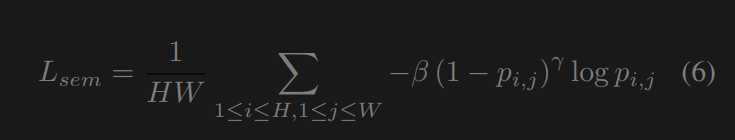
其中,p为分割网络对一个像素的估计类概率。受[7]的启发,我们选择焦点系数β和γ分别为1和2。
代码
需要两个网络成分,一个是递归网络络,一个是分割网络(不需要优化)

class enhance_net_nopool(nn.Module):def __init__(self, scale_factor, conv_type='dsc'):super(enhance_net_nopool, self).__init__()self.relu = nn.ReLU(inplace=True)self.scale_factor = scale_factorself.upsample = nn.UpsamplingBilinear2d(scale_factor=self.scale_factor)number_f = 32# Define Conv typeif conv_type == 'dsc':self.conv = DSCelif conv_type == 'dc':self.conv = DCelif conv_type == 'tc':self.conv = TCelse:print("conv type is not available")# zerodce DWC + p-sharedself.e_conv1 = self.conv(3, number_f)self.e_conv2 = self.conv(number_f, number_f)self.e_conv3 = self.conv(number_f, number_f)self.e_conv4 = self.conv(number_f, number_f)self.e_conv5 = self.conv(number_f * 2, number_f)self.e_conv6 = self.conv(number_f * 2, number_f)self.e_conv7 = self.conv(number_f * 2, 3)def enhance(self, x, x_r):x = x + x_r * (torch.pow(x, 2) - x)x = x + x_r * (torch.pow(x, 2) - x)x = x + x_r * (torch.pow(x, 2) - x)enhance_image_1 = x + x_r * (torch.pow(x, 2) - x)x = enhance_image_1 + x_r * (torch.pow(enhance_image_1, 2) - enhance_image_1)x = x + x_r * (torch.pow(x, 2) - x)x = x + x_r * (torch.pow(x, 2) - x)enhance_image = x + x_r * (torch.pow(x, 2) - x)return enhance_imagedef forward(self, x):if self.scale_factor == 1:x_down = xelse:x_down = F.interpolate(x, scale_factor=1 / self.scale_factor, mode='bilinear')# extractionx1 = self.relu(self.e_conv1(x_down))x2 = self.relu(self.e_conv2(x1))x3 = self.relu(self.e_conv3(x2))x4 = self.relu(self.e_conv4(x3))x5 = self.relu(self.e_conv5(torch.cat([x3, x4], 1)))x6 = self.relu(self.e_conv6(torch.cat([x2, x5], 1)))x_r = F.tanh(self.e_conv7(torch.cat([x1, x6], 1)))#稠密链接提取图像的特征(放大系数)if self.scale_factor == 1:x_r = x_relse:x_r = self.upsample(x_r)#保证x_r 的大小和图像的大小一致# enhancement#zero-dce 的网络结构不同的是x_r是变化的,而本文的x_r得到以后就不会变化了(只是在 self.enhance中)enhance_image = self.enhance(x, x_r)return enhance_image, x_r
对比zero-dce网络的结构
"""
Model File
"""from mindspore import nn
from mindspore import ops
from mindspore.common.initializer import Normalclass ZeroDCE(nn.Cell):"""Main Zero DCE Model"""def __init__(self, *, sigma=0.02, mean=0.0):super().__init__()self.relu = nn.ReLU()number_f = 32self.e_conv1 = nn.Conv2d(3, number_f, 3, 1, pad_mode='pad', padding=1, has_bias=True,weight_init=Normal(sigma, mean))self.e_conv2 = nn.Conv2d(number_f, number_f, 3, 1, pad_mode='pad', padding=1, has_bias=True,weight_init=Normal(sigma, mean))self.e_conv3 = nn.Conv2d(number_f, number_f, 3, 1, pad_mode='pad', padding=1, has_bias=True,weight_init=Normal(sigma, mean))self.e_conv4 = nn.Conv2d(number_f, number_f, 3, 1, pad_mode='pad', padding=1, has_bias=True,weight_init=Normal(sigma, mean))self.e_conv5 = nn.Conv2d(number_f * 2, number_f, 3, 1, pad_mode='pad', padding=1,has_bias=True, weight_init=Normal(sigma, mean))self.e_conv6 = nn.Conv2d(number_f * 2, number_f, 3, 1, pad_mode='pad', padding=1,has_bias=True, weight_init=Normal(sigma, mean))self.e_conv7 = nn.Conv2d(number_f * 2, 24, 3, 1, pad_mode='pad', padding=1, has_bias=True,weight_init=Normal(sigma, mean))self.split = ops.Split(axis=1, output_num=8)self.cat = ops.Concat(axis=1)def construct(self, x):"""ZeroDCE inference"""x1 = self.relu(self.e_conv1(x))x2 = self.relu(self.e_conv2(x1))x3 = self.relu(self.e_conv3(x2))x4 = self.relu(self.e_conv4(x3))x5 = self.relu(self.e_conv5(self.cat([x3, x4])))x6 = self.relu(self.e_conv6(self.cat([x2, x5])))x_r = ops.tanh(self.e_conv7(self.cat([x1, x6])))r1, r2, r3, r4, r5, r6, r7, r8 = self.split(x_r)x = x + r1 * (ops.pows(x, 2) - x)x = x + r2 * (ops.pows(x, 2) - x)x = x + r3 * (ops.pows(x, 2) - x)enhance_image_1 = x + r4 * (ops.pows(x, 2) - x)x = enhance_image_1 + r5 * (ops.pows(enhance_image_1, 2) - enhance_image_1)x = x + r6 * (ops.pows(x, 2) - x)x = x + r7 * (ops.pows(x, 2) - x)enhance_image = x + r8 * (ops.pows(x, 2) - x)r = self.cat([r1, r2, r3, r4, r5, r6, r7, r8])return enhance_image, r语义分割网络
#这里的calss 文中默认参数为21
class fpn(nn.Module):def __init__(self, numClass):super(fpn, self).__init__()# Res netself.resnet = resnet50(True)# fpn moduleself.fpn = fpn_module(numClass)#详细的代码看作者公开的代码# init fpnfor m in self.fpn.children():nn.init.normal_(m.weight, mean=0, std=0.01)nn.init.constant_(m.bias, 0)def forward(self, x):# Top-downc2, c3, c4, c5 = self.resnet.forward(x)#特征来自于预训练模型的不同尺度特征return self.fpn.forward(c2, c3, c4, c5)#输出是一个二维的张量为28个通道类别的概率
网络的训练:
def train(self):self.net.train()for epoch in range(self.num_epochs):for iteration, img_lowlight in enumerate(self.train_loader):img_lowlight = img_lowlight.to(device)enhanced_image, A = self.net(img_lowlight)#需要学习的网络loss = self.get_loss(A, enhanced_image, img_lowlight, self.E)#需要优化的损失self.optimizer.zero_grad()loss.backward()torch.nn.utils.clip_grad_norm(self.net.parameters(), self.grad_clip_norm)self.optimizer.step()if ((iteration + 1) % self.display_iter) == 0:print("Loss at iteration", iteration + 1, ":", loss.item())if ((iteration + 1) % self.snapshot_iter) == 0:torch.save(self.net.state_dict(), self.snapshots_folder + "Epoch" + str(epoch) + '.pth')
def get_loss(self, A, enhanced_image, img_lowlight, E):Loss_TV = 1600 * self.L_TV(A)loss_spa = torch.mean(self.L_spa(enhanced_image, img_lowlight))loss_col = 5 * torch.mean(self.L_color(enhanced_image))loss_exp = 10 * torch.mean(self.L_exp(enhanced_image, E))loss_seg = self.get_seg_loss(enhanced_image)loss = Loss_TV + loss_spa + loss_col + loss_exp + 0.1 * loss_segreturn loss
本文主要提出的损失函数
def get_NoGT_target(inputs):sfmx_inputs = F.log_softmax(inputs, dim=1)#按照行或者列来做归一化的,再做多一次log运算target = torch.argmax(sfmx_inputs, dim=1)#将输入input张量,无论有几维,首先将其reshape排列成一个一维向量,然后找出这个一维向量里面最大值的索引return targetdef get_seg_loss(self, enhanced_image):# segment the enhanced imageseg_input = enhanced_image.to(device)seg_output = self.seg(seg_input).to(device)# build seg outputtarget = (get_NoGT_target(seg_output)).data.to(device)# calculate seg. lossseg_loss = self.seg_criterion(seg_output, target)return seg_loss
self.seg_criterion = FocalLoss(gamma=2).to(device)
class FocalLoss(nn.Module):# def __init__(self, device, gamma=0, eps=1e-7, size_average=True):def __init__(self, gamma=0, eps=1e-7, size_average=True, reduce=True):super(FocalLoss, self).__init__()self.gamma = gammaself.eps = epsself.size_average = size_averageself.reduce = reduce# self.device = devicedef forward(self, input, target):# y = one_hot(target, input.size(1), self.device)y = one_hot(target, input.size(1))probs = F.softmax(input, dim=1)probs = (probs * y).sum(1) # dimension ???probs = probs.clamp(self.eps, 1. - self.eps)log_p = probs.log()# print('probs size= {}'.format(probs.size()))# print(probs)batch_loss = -(torch.pow((1 - probs), self.gamma)) * log_p# print('-----bacth_loss------')# print(batch_loss)if self.reduce:if self.size_average:loss = batch_loss.mean()else:loss = batch_loss.sum()else:loss = batch_lossreturn loss
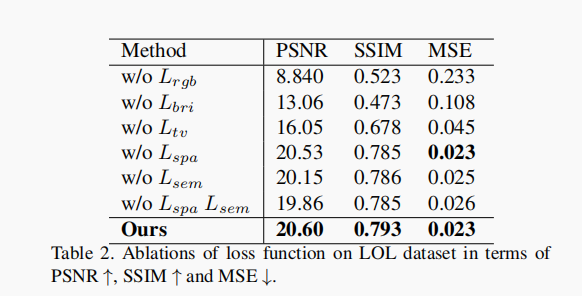
公布的实验结果
这篇关于Semantic-Guided Zero-Shot Learning for Low-Light ImageVideo Enhancement的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







