本文主要是介绍经典目标检测YOLO系列(1)YOLO-V1算法及其在VOC2007数据集上的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
经典目标检测YOLO系列(1)YOLO-V1算法及其在VOC2007数据集上的应用
1 YOLO-V1的简述
1.1 目标检测概述
目标检测有非常广泛的应用, 例如:在安防监控、手机支付中的人脸检测;在智慧交通,自动驾驶中的车辆检测;在智慧商超,无人结账中的商品检测;在工业领域中的钢材、轨道表面缺陷检测。
目标检测关注的是图片中特定目标物体的位置。一个检测任务包含两个子任务,其一是输出目标的类别信息,属于分类任务;其二是输出目标的具体位置信息,属于定位任务。
早期,传统目标检测算法还没有使用深度学习,一般分为三个阶段:
- 区域选取:采用滑动窗口(Sliding Windows)算法(可以想象一个窗口在图像从左到右,从上到下,框出图像内容),选取图像中可能出现物体的位置,这种算法会存在大量冗余框,并且计算复杂度高。
- 特征提取:通过手工设计的特征提取器(如SIFT和HOG等)进行特征提取。
- 特征分类:使用分类器(如SVM)对上一步提取的特征进行分类。
2014年的R-CNN(Regions with CNN features)使用深度学习实现目标检测,从此拉开了深度学习做目标检测的序幕。并且随着深度学习的方法快速发展,基于深度学习的目标检测,其检测效果好,逐渐成为主流。
基于深度学习的目标检测大致可以分为一阶段(One Stage)模型和二阶段(Two Stage)模型。
-
目标检测的一阶段模型是指没有独立地提取候选区域(Region Proposal),直接输入图像得到图中存在的物体类别和相应的位置信息。典型的一阶段模型有SSD(Single Shot multibox-Detector)、YOLO(You Only Look Once)系列模型等。
-
二阶段模型是有独立地候选区域选取,要先对输入图像筛选出可能存在物体的候选区域,然后判断候选区域中是否存在目标,如果存在输出目标类别和位置信息。经典的二阶段模型有R-CNN、Fast R-CNN、Faster R-CNN。
-
如下图,两阶段的检测算法精度会比一阶段检测算法高,而检测速度确不如一阶段的检测算法,二阶段检测算法适合对精度要求高的业务,一阶段检测算法适合对实时性要求高的业务。

1.2 YOLO-V1概述
YOLO(You Only Look Once)是一种基于深度神经网络的对象识别和定位算法,其最大的特点是运行速度很快,可以用于实时系统。
论文下载地址: https://arxiv.org/pdf/1506.02640.pdf
1.2.1 YOLO-V1的网络结构及pytorch代码实现
第一个版本的YOLO的特征提取网络有24个卷积层和2个全连接层。网络结构如下图。

- 可以看出,这个网络中主要采用了1x1卷积后跟着3x3卷积的方式。
- 特征提取网络采用了前20个卷积层,加一个avg-pooling层和一个全连接层,对ImageNet2012进行分类,top-5正确率为88%,输入分辨率为224x224。
- 检测时,将输入分辨率改为448x448,因为网络结构是全卷积的,所以输入分辨率可以改变,整个网络输出为7x7x30维的tensor。
- YOLO网络借鉴了GoogLeNet分类网络结构,有24个卷积层+2个全连接层。
图片参数中的s-2指的是步长为2,这里要注意以下三点:- 在ImageNet中预训练网络时,使用的输入是224 * 224,用于检测任务时,输入大小改为448 * 448,这是通过调整第一个卷积层的步长来实现的;
- 网络使用了很多1*1的卷积层来进行特征降维;
- 最后一个卷积层的输出为(7, 7, 1024),经过flatten后紧跟两个全连接层,形成一个线性回归,最后一个全连接层又被reshape成(7, 7, 30),形成对2个box坐标及20个物体类别的预测(PASCAL VOC)。
pytorch代码实现
"""
Yolo (v1)网络的实现:做了轻微修改,加了BatchNorm
"""import torch
import torch.nn as nnarchitecture_config = [(7, 64, 2, 3), # 四个参数分别对应 (kernel_size, filters, stride, padding)"M", # M代表最大池化kernel=2x2, stride=2(3, 192, 1, 1),"M",(1, 128, 1, 0),(3, 256, 1, 1),(1, 256, 1, 0),(3, 512, 1, 1),"M",[(1, 256, 1, 0), (3, 512, 1, 1), 4], # CNNBlock重复4次,先用1x1卷积,后接3x3卷积(1, 512, 1, 0),(3, 1024, 1, 1),"M",[(1, 512, 1, 0), (3, 1024, 1, 1), 2], # CNNBlock重复2次,先用1x1卷积,后接3x3卷积(3, 1024, 1, 1),(3, 1024, 2, 1),(3, 1024, 1, 1),(3, 1024, 1, 1),
]class CNNBlock(nn.Module):"""CNN块的实现(卷积-BN-ReLU)"""def __init__(self, in_channels, out_channels, **kwargs):super(CNNBlock, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)# 这里做了稍微修改,在卷积后加了BatchNormself.batchnorm = nn.BatchNorm2d(out_channels)self.leakyrelu = nn.LeakyReLU(0.1)def forward(self, x):return self.leakyrelu(self.batchnorm(self.conv(x)))class Yolov1(nn.Module):"""Yolov1网络结构实现"""def __init__(self, in_channels=3, **kwargs):super(Yolov1, self).__init__()self.architecture = architecture_configself.in_channels = in_channelsself.darknet = self._create_conv_layers(self.architecture)self.fcs = self._create_fcs(**kwargs)def forward(self, x):x = self.darknet(x)return self.fcs(torch.flatten(x, start_dim=1))def _create_conv_layers(self, architecture):layers = []in_channels = self.in_channelsfor x in architecture:# 类型为tuple,即(kernel_size, filters, stride, padding)if type(x) == tuple:layers += [CNNBlock(in_channels, x[1], kernel_size=x[0], stride=x[2], padding=x[3],)]in_channels = x[1]# 最大池化层elif type(x) == str:layers += [nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))]# 类型为list,重复的CNNBlockelif type(x) == list:conv1 = x[0]conv2 = x[1]num_repeats = x[2]for _ in range(num_repeats):layers += [CNNBlock(in_channels,conv1[1],kernel_size=conv1[0],stride=conv1[2],padding=conv1[3],)]layers += [CNNBlock(conv1[1],conv2[1],kernel_size=conv2[0],stride=conv2[2],padding=conv2[3],)]in_channels = conv2[1]return nn.Sequential(*layers)def _create_fcs(self, split_size, num_boxes, num_classes):S, B, C = split_size, num_boxes, num_classes# 原始论文中是# nn.Linear(1024*S*S, 4096),# nn.LeakyReLU(0.1),# nn.Linear(4096, S*S*(B*5+C))return nn.Sequential(nn.Flatten(),nn.Linear(1024 * S * S, 496),nn.Dropout(0.0),nn.LeakyReLU(0.1),# 网络输出的特征图会划分为S * S的网格,每个网格会预测B个Bounding Boxes(简称bbox);# x,y是物体中心点坐标, h,w是bbox的长宽;以及每个bbox对应一个置信度confidence,因此需要乘以5# C为数据集的类别# 原始论文中S=7,类别C=20,B=2,因此最终为7x7x(20 + 2x5) = 7x7x30nn.Linear(496, S * S * (C + B * 5)),)if __name__ == '__main__':S = 7B = 2C = 20model = Yolov1(split_size=S, num_boxes=B, num_classes=C)x = torch.randn((2, 3, 448, 448))print(model(x).shape)
LeakyReLU:

1.2.2 网络结构的输出
在YOLO算法中把物体检测(object detection)问题处理成回归问题,用一个卷积神经网络结构就可以从输入图像直接预测bounding box和类别概率。

算法首先把网络输出的特征图(也可说是输入图像,因为输入图像的网格区域与特征图的网格区域有对应关系)划分成S×S的栅格,然后对每个栅格(grid cell)都预测B个bounding boxes,每个bounding box都包含5个预测值:x,y,w,h和confidence。
-
x,y就是bounding box的中心坐标,与grid cell对齐(即相对于当前grid cell的偏移值),使得范围变成0到1; -
w,h进行归一化(分别除以图像的w和h,这样最后的w和h就在0到1范围)。 -
confidence代表了所预测的box中含有object(物体)的置信度和预测的这个框的准度(即这个框定位位置的准确程度)两重信息:
除了确定是否包含物体,还需确定每一个栅格(grid cell)预测的物体类别?对于有C个类别的数据集,会对每个类别预测出类别概率。

因此,网络输出的张量尺寸为 S×S×(5×B + C)。这里5指的是检测框的位置信息和包含物体的概率(x,y,w,h,confidence)。
YOLO V1中S = 7,B = 2,C = 20。因此YOLOV1 网络输出的张量尺寸为7×7×30。张量结构如下图:X1, Y1, W1, H1表示每一个栅格(grid cell)预测的第1个bbox,C1是置信度;X2, Y2, W2, H2表示每一个栅格(grid cell)预测的第2个bbox,C2是置信度;cl1,cl2,...,cl20表示这个物体属于每个类别的概率。

we use S = 7,B = 2. PASCAL VOC has 20 labelled classes so C = 20.Our final prediction is a 7 × 7 × 30 tensor.# 可以看到在原始论文中,作者用S = 7,B = 2,C = 20,因此最终的网络输出为7x7x(20 + 2x5) = 7x7x30
注意:一个物体的中心,落在一个栅格(grid cell)中,那么这个栅格就负责预测这个物体,即一个栅格只属于一个物体类别。因此,当另一个物体的中心(比如一只小鸟)也落在这个栅格中,那么此物体不会被检测到。
每个bbox包含物体的概率confidence如何计算?

1.2.3 损失函数公式的理解及实现
一个网络如何学习预测物体类别和物体位置,这就要看损失函数了。
损失函数包含三个部分:(1)中心点、宽、高(即位置);(2)置信度;(3)物体的类别标签

1、中心点、宽、高的损失计算,关于物体边框的回归


| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
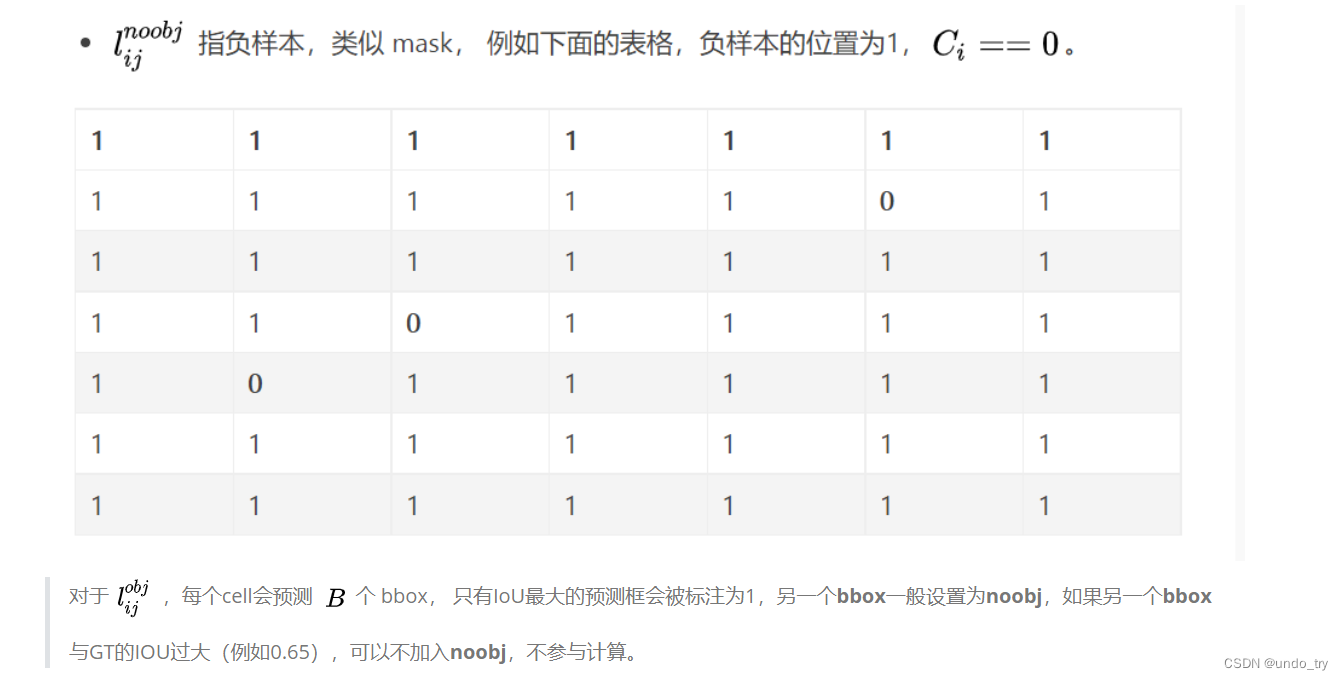
2、置信度的损失计算,关于置信度的回归
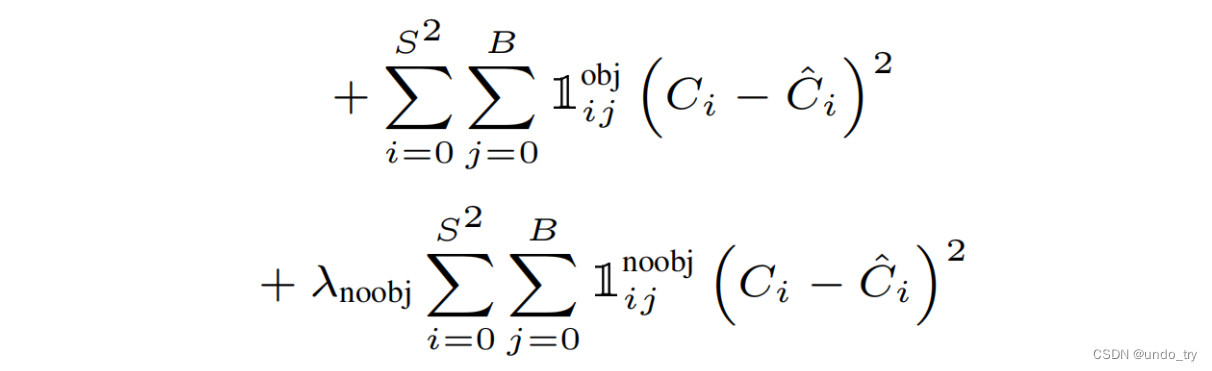

3、类别标签的损失计算,关于类别的预测

每个cell最终只预测一个物体边框,依据预测出B个bbox与标注框计算IOU,选取最大的IOU的物体边框。
loss函数的代码实现
"""
Implementation of Yolo Loss Function from the original yolo paper
"""import torch
import torch.nn as nn
from utils import intersection_over_unionclass YoloLoss(nn.Module):"""计算yolo_v1模型的loss"""def __init__(self, S=7, B=2, C=20):super(YoloLoss, self).__init__()self.mse = nn.MSELoss(reduction="sum")"""S为输入图像(特征图)的切割大小(in paper 7),B为boxes的数量(in paper 2),C为类别数量(in paper and VOC dataset is 20),target : class labels(20) c x y w h """self.S = Sself.B = Bself.C = C# These are from Yolo paper, signifying how much we should# pay loss for no object (noobj) and the box coordinates (coord)self.lambda_noobj = 0.5self.lambda_coord = 5def forward(self, predictions, target):# predictions are shaped (BATCH_SIZE, S*S(C+B*5) when inputtedpredictions = predictions.reshape(-1, self.S, self.S, self.C + self.B * 5)# Calculate IoU for the two predicted bounding boxes with target bbox(only one)iou_b1 = intersection_over_union(predictions[..., 21:25], target[..., 21:25]) # first boxprint('predictions[..., 21:25]:', predictions[..., 21:25])iou_b2 = intersection_over_union(predictions[..., 26:30], target[..., 21:25]) # second boxprint('predictions[..., 26:30]:', predictions[..., 26:30])ious = torch.cat([iou_b1.unsqueeze(0), iou_b2.unsqueeze(0)], dim=0)# Take the box with highest IoU out of the two prediction# Note that bestbox will be indices of 0, 1 for which bbox was bestiou_maxes, bestbox = torch.max(ious, dim=0)exists_box = target[..., 20].unsqueeze(3) # in paper this is Iobj_i# ======================== ## FOR BOX COORDINATES ## ======================== ## Set boxes with no object in them to 0. We only take out one of the two# predictions, which is the one with highest Iou calculated previously.box_predictions = exists_box * ((bestbox * predictions[..., 26:30]+ (1 - bestbox) * predictions[..., 21:25]))# bestbox: 第0个,返回 box_predictions = exists_box * predictions[..., 21:25]# bestbox: 第1个,返回 box_predictions = exists_box * predictions[..., 26:30]box_targets = exists_box * target[..., 21:25]# Take sqrt of width, height of boxes to ensure that'''torch.sign(input, out=None) 说明:符号函数,返回一个新张量,包含输入input张量每个元素的正负(大于0的元素对应1,小于0的元素对应-1,0还是0)'''# torch.sign(box_predictions[..., 2:4]) 为其sqrt(w)添加正负号box_predictions[..., 2:4] = torch.sign(box_predictions[..., 2:4]) * torch.sqrt(torch.abs(box_predictions[..., 2:4] + 1e-6)) # w hbox_targets[..., 2:4] = torch.sqrt(box_targets[..., 2:4]) # (N, S, S, 25)box_loss = self.mse(torch.flatten(box_predictions, end_dim=-2),torch.flatten(box_targets, end_dim=-2),) # (N, S, S, 4) -> (N*S*S, 4)# ==================== ## FOR OBJECT LOSS ## ==================== ## pred_box is the confidence score for the bbox with highest IoUpred_box = (bestbox * predictions[..., 25:26] + (1 - bestbox) * predictions[..., 20:21])# (N*S*S)object_loss = self.mse(torch.flatten(exists_box * pred_box),torch.flatten(exists_box * target[..., 20:21]),)# ======================= ## FOR NO OBJECT LOSS ## ======================= ##max_no_obj = torch.max(predictions[..., 20:21], predictions[..., 25:26])#no_object_loss = self.mse(# torch.flatten((1 - exists_box) * max_no_obj, start_dim=1),# torch.flatten((1 - exists_box) * target[..., 20:21], start_dim=1),#)# (N,S,S,1) --> (N, S*S)no_object_loss = self.mse(torch.flatten((1 - exists_box) * predictions[..., 20:21], start_dim=1),torch.flatten((1 - exists_box) * target[..., 20:21], start_dim=1),)no_object_loss += self.mse(torch.flatten((1 - exists_box) * predictions[..., 25:26], start_dim=1),torch.flatten((1 - exists_box) * target[..., 20:21], start_dim=1))# ================== ## FOR CLASS LOSS ## ================== ## (N,S,S,20) -> (N*S*S, 20)class_loss = self.mse(torch.flatten(exists_box * predictions[..., :20], end_dim=-2,),torch.flatten(exists_box * target[..., :20], end_dim=-2,),)loss = (self.lambda_coord * box_loss # first two rows in paper+ object_loss # third row in paper+ self.lambda_noobj * no_object_loss # forth row+ class_loss # fifth row)return loss
1.2.4 YOLO-V1优缺点
优点: 速度快,简单
缺点:
- 每个栅格(grid cell)只预测一个类别,对拥挤的物体检测不太友好
- 对小物体检测不好,长宽比单一
- 没有Batch Normalize
2 YOLO-V1在VOC2007数据集上的应用
2.1 数据集的下载及介绍
2.1.1 数据集的下载
PASCAL VOC2007数据集(全部)
链接:https://pan.baidu.com/s/1tnTpr6xFY6mK8q2jfhZBZQ
提取码:z8sd
PASCAL VOC2007数据集(只包含训练集和验证集,不包含测试集)
链接:https://pan.baidu.com/s/1-0U9w_XBGzYpzP4ND25blQ
提取码:zmz6
PASCAL VOC2012数据集(只包含训练集和验证集,不包含测试集)
链接:https://pan.baidu.com/s/1cJPer12vhuubqDeLcRQoPQ
提取码:1340
2.1.2 PASCAL VOC2007数据集的介绍
VOC2007数据集有20个类:aeroplane, bicycle, bird, boat, bottle, bus, car, cat, chair, cow, diningtable, dog, horse, motorbike, person, pottedplant, sheep, sofa, train, tv/monitor。
第一个网盘连接中,有三个压缩包。将VOCdevkit_08-Jun-2007.tar、测试集VOCtest_06-Nov-2007.tar、训练集/验证集VOCtrainval_06-Nov-2007.tar分别下载到本地。

分别解压这个三个压缩包到当前文件夹【注意:解压选项为当前文件夹】。解压后,如图所示。
其中,VOCdevkit_08-Jun-2007.tar中的文件是 development kit code and documentation ,即一些开发工具包代码和文档,如下图所示。有一些MATLAB代码,就是用这些代码处理的这个数据集,还有一个devkit_doc.pdf, 是一个比较详细的说明书。

解压后的文件夹VOC2007中有以下五个部分,如下图所示。

Annotations
这个文件夹里都是.xml文件,文件名是图像名称,如下图所示。每个文件里面保存的是每张图像的标注信息,训练时要用的label信息其实就来源于此文件夹。

例如000007.xml文件如下所示:
<annotation><folder>VOC2007</folder><filename>000007.jpg</filename><source><database>The VOC2007 Database</database><annotation>PASCAL VOC2007</annotation><image>flickr</image><flickrid>194179466</flickrid></source><owner><flickrid>monsieurrompu</flickrid><name>Thom Zemanek</name></owner><size><width>500</width><height>333</height><depth>3</depth></size><segmented>0</segmented><object><name>car</name><pose>Unspecified</pose><truncated>1</truncated><difficult>0</difficult><bndbox><xmin>141</xmin><ymin>50</ymin><xmax>500</xmax><ymax>330</ymax></bndbox></object>
</annotation>
ImageSets
这个文件夹里面是图像划分的集合 ,打开之后有3个文件夹:Layout 、 Main、 Segmentation,如下图所示,这3个文件夹对应的是 VOC challenge 3类不同的任务。

VOC challenge的Main task,其实是classification和detection,所以在Main文件夹中,包含的就是这两个任务要用到的图像集合,如下图所示。
共有84个.txt文件
-
其中4个文件为训练集
train.txt、验证集val.txt、训练集和验证集汇总trainval.txt、测试集test.txt,这4个文件里面保存的是图像的ID号; -
还有20类目标,每个类别有该类的
类别名_train.txt、类别名_val.txt、类别名_trainval.txt、类别名_test.txt这4个文本,共80个文件。这80个文件中每一行的图像ID后面还跟了一个数字,要么是-1, 要么是1,有时候也可能会出现0,意义为:-1表示当前图像中,没有该类物体;1表示当前图像中有该类物体;0表示当前图像中,该类物体只露出了一部分。

还有两个taster tasks :Layout和Segmentation,这两个任务也有各自需要用到的图像,就分别存于Layout和Segmentation两个文件夹中,如下图所示,分别有4个文件:训练集train.txt、验证集val.txt、训练集和验证集汇总trainval.txt、测试集test.txt。

JPEGImages
这个文件夹里面保存的是数据的原始图片,打开之后全是.jpg图片,如下图所示,共有9963张图像。

SegmentationClass
这个文件夹里面保存的是专门针对Segmentation任务做的图像,里面存放的是Segmentation任务的label信息。

SegmentationObject
这个任务叫做Instance Segmentation(样例分割),就同一图像中的同一类别的不同个体要分别标出来,也是单独给的label信息,因为每个像素点要有一个label信息。

2.2 数据预处理
我们仅仅选取6个数据(类别均为狗),作为代码测试。

2.2.1 划分训练集、验证集以及测试集
数据集划分流程:
- 获取’/VOC2007/Annotations’ 下以’.xml’结尾的文件名。
- 从总的样本中按照数据集比例抽取样本,得到每个数据集的索引。
- 不同数据集的存储地址。
- 遍历样本,根据抽取的样本索引放入不同的数据集中。
- 关闭文件。
'''
dataSplit将数据划分为训练集、验证集、测试集
'''
import os
import randomxml_path = r'../data/VOCdevkit/VOC2007/Annotations'
base_path = r'../data/VOCdevkit/VOC2007/ImageSets/Main'# 1 样本名字
tmp = []
img_names = os.listdir(xml_path)
for i in img_names:if i.endswith('.xml'):tmp.append(i[:-4])# 2 数据集划分
trainval_ratio = 0.9 # 训练集和验证集一共占0.9,测试集占0.1
train_ratio = 0.9 # 训练集占(训练集和验证集之和)的0.9
N = len(tmp)
trainval_num = int(trainval_ratio * N)
train_num = int(train_ratio * trainval_num)
trainval_idx = random.sample(range(N), trainval_num)
train_idx = random.sample(trainval_idx, train_num)# 3 数据集的存储地址
ftrainval = open(os.path.join(base_path, 'yyds_trainval.txt'), 'w')
ftrain = open(os.path.join(base_path, 'yyds_train.txt'), 'w')
fval = open(os.path.join(base_path, 'yyds_val.txt'), 'w')
ftest = open(os.path.join(base_path, 'yyds_test.txt'), 'w')# 4 写入数据
for i in range(N):name = tmp[i] + '\n'if i in trainval_idx:ftrainval.write(name)if i in train_idx:ftrain.write(name)else:fval.write(name)else:ftest.write(name)# 5 关闭文件
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
运行代码,生成4个文件,文件内容是.xml文件的文件名

2.2.2 把图片信息和xml信息放在一起
把图片信息和xml信息放在一起。
- 遍历每个数据集获取数据集图片名。生成解析文件,用来存储图片地址和框的信息。
- 遍历每张图片,解析文件写入图片地址,打开xml文件,读入类别信息和框的信息。
- 关闭解析文件
# python中专门的库用于提取xml文件信息名为"ElementTree"
import xml.etree.ElementTree as ETsets = [('2007','train'),('2007','val'),('2007','test')]# 20种类别
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle","bus", "car", "cat", "chair", "cow", "diningtable","dog", "horse", "motorbike", "person", "pottedplant","sheep", "sofa", "train", "tvmonitor"] # len(classes) = 20def convert_annotation(year,img_id,list_file):list_file.write("../data/VOCdevkit/VOC%s/JPEGImages/%s.jpg"%(year,img_id))in_file = open('../data/VOCdevkit/VOC%s/Annotations/%s.xml'%(year,img_id))root = ET.parse(in_file).getroot()for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult)==1:continuecls_id = classes.index(cls)xml_box = obj.find('bndbox')b = (int(xml_box.find('xmin').text),int(xml_box.find('ymin').text),int(xml_box.find('xmax').text),int(xml_box.find('ymax').text))list_file.write(" "+','.join([str(i) for i in b])+','+str(cls_id))for year ,img_set in sets:img_ids = open('../data/VOCdevkit/VOC%s/ImageSets/Main/yyds_%s.txt'%(year ,img_set)).read().strip().split()list_file = open('%s_%s.txt'%(year,img_set),'w')for img_id in img_ids:convert_annotation(year,img_id,list_file)list_file.write('\n')list_file.close()
运行后,生成3个文件

2.2.3 数据增强处理
此文件主要任务就是根据txt文件内的信息制作ground truth,并且还会进行一定的数据增强。最终输出一个7×7×30的张量。
注意:进行数据增强比如对图片进行拉长或者旋转其bbox信息也会随之改变,但是用pytorch自带的数据增强方法并不会改变bbox信息,所以这里都是自己定义的增强方法,在对图片进行变换的过程后也会输出bbox更改后的信息。
对图片数据增强,增加样本,提高模型的泛化能力。
- 首先把图片名称、框、类别信息分别存储。
- 生成迭代器,对每个图片进行数据增强。翻转、缩放、模糊、随机变换亮度、随机变换色度、随机变换饱和度、随机平移、随机剪切。
- 编码。对于增强后的图片,根据图片宽高,获取框在图片的相对位置、去均值、统一图片尺寸、编码。编码的关键在于找到真实框在特征图上的相对位置。先把真实框左上角和右下角坐标转换为中心点和宽高,中心点坐标x特征图宽高后,向下取整在-1就得到真实框在特征图上的位置ij。中心点坐标x特征图宽高-ij得到真实偏移。根据ij输入偏移、宽高、类别信息。
''' 数据增强 '''import os
import sys
import cv2
import torch
import random
import os.path
import numpy as np
import matplotlib.pyplot as plt
import torch.utils.data as data
import torchvision.transforms as transformsclass yoloDataset(data.Dataset):image_size = 448def __init__(self,root,list_file,train,transform):print('data init')self.root = root ## img.jpg_pathself.train = train ## bool:True,如果是训练模式,就进行数据增强。self.transform = transform # 转置self.fnames = [] # 存储图片名 eg: 00014.jpgself.boxes = [] # 存放真实框信息self.labels = [] # 存放标签self.mean = (123,117,104) # 图片各个通道均值,用于归一化数据,加速训练。with open(list_file) as f:lines = f.readlines() # 读取数据# line: /VOCdevkit/VOC2007/JPEGImages/000022.jpg 68,103,368,283,12 186,44,255,230,14for line in lines:splited = line.strip().split()self.fnames.append(splited[0]) # 保存图片名num_boxes = (len(splited)-1) # 一张图片中真实框的个数box = [] # 存储框label = [] # 存储标签for i in range(1,num_boxes+1): # 遍历每个框tmp = [float(j) for j in splited[i].split(',')] # 把真实框油字符变为float类型,并用‘,’隔开。box.append(tmp[:4])label.append(int(tmp[4])+1)self.boxes.append(torch.Tensor(box))self.labels.append(torch.LongTensor(label))self.num_samples = len(self.boxes)def __getitem__(self,idx):fname = self.fnames[idx] # 用迭代器遍历每张图片img = cv2.imread(fname) # 读取图片 cv2.imread(os.path.join(self.root+fname))boxes = self.boxes[idx].clone()labels = self.labels[idx].clone()if self.train:img,boxes = self.random_flip(img,boxes) # 随机翻转img,boxes = self.randomScale(img,boxes) # 随机伸缩变换img = self.randomBlur(img) # 随机模糊处理img = self.RandomBrightness(img) # 随机调整图片亮度img = self.RandomHue(img) # 随机调整图片色调img = self.RandomSaturation(img) # 随机调整图片饱和度img,boxes,labels = self.randomShift(img,boxes,labels) # 随机平移img,boxes,labels = self.randomCrop(img,boxes,labels) # 随机裁剪h,w,_ = img.shapeboxes /= torch.Tensor([w,h,w,h]).expand_as(boxes) # 坐标归一化处理,为了方便训练img = self.BGR2RGB(img)img = self.subMean(img,self.mean) # 减去均值img = cv2.resize(img,(self.image_size,self.image_size)) # 将所有图片都resize到指定大小(448,448)target = self.encoder(boxes,labels) # 将图片标签编码到7x7x30的向量for t in self.transform:img = t(img)return img,targetdef __len__(self):return self.num_samplesdef encoder(self,boxes,labels):"""编码: 输出ground truth (一个7*7*30的张量)"""grid_num = 7target = torch.zeros((grid_num,grid_num,30))wh = boxes[:,2:] - boxes[:,:2]cxcy = (boxes[:,2:] + boxes[:,:2])/2for i in range(cxcy.size()[0]):cxcy_sample = cxcy[i]ij = (cxcy_sample*grid_num).ceil()-1dxy = cxcy_sample*grid_num-ijtarget[int(ij[1]),int(ij[0]),:2] = target[int(ij[1]),int(ij[0]),5:7] = dxytarget[int(ij[1]),int(ij[0]),2:4] = target[int(ij[1]),int(ij[0]),7:9] = wh[i]target[int(ij[1]),int(ij[0]),4] = target[int(ij[1]),int(ij[0]),9] = 1target[int(ij[1]),int(ij[0]),int(labels[i])+9] = 1return targetdef BGR2RGB(self,img):return cv2.cvtColor(img,cv2.COLOR_BGR2RGB)def BGR2HSV(self,img):return cv2.cvtColor(img,cv2.COLOR_BGR2HSV)def HVS2BGR(self,img):return cv2.cvtColor(img,cv2.COLOR_HSV2BGR)def RandomBrightness(self,bgr):if random.random()<0.5:hsv = self.BGR2HSV(bgr)h,s,v = cv2.split(hsv)v = v.astype(float)v *= random.choice([0.5,1.5])v = np.clip(v,0,255).astype(hsv.dtype)hsv = cv2.merge((h,s,v))bgr = self.HVS2BGR(hsv)return bgrdef RandomSaturation(self,bgr):if random.random()<0.5:hsv = self.BGR2HSV(bgr)h,s,v = cv2.split(hsv)s = s.astype(float)s *= random.choice([0.5,1.5])s = np.clip(s,0,255).astype(hsv.dtype)hsv = cv2.merge((h,s,v))bgr = self.HVS2BGR(hsv)return bgrdef RandomHue(self,bgr):if random.random() < 0.5:hsv = self.BGR2HSV(bgr)h,s,v = cv2.split(hsv)h = h.astype(float)h *= random.choice([0.5,1.5])h = np.clip(h,0,255).astype(hsv.dtype)hsv=cv2.merge((h,s,v))bgr = self.HVS2BGR(hsv)return bgrdef randomBlur(self,bgr):if random.random() < 0.5:bgr = cv2.blur(bgr,(5,5))return bgrdef randomShift(self,bgr,boxes,labels):center = (boxes[:,2:]+boxes[:,:2])/2if random.random()<0.5:height,width,c = bgr.shapeafter_shift_imge = np.zeros((height,width,c),dtype=bgr.dtype)after_shift_imge[:,:,:] = (104,117,123)shift_x = random.uniform(-width*0.2,width*0.2)shift_y = random.uniform(-height*0.2,height*0.2)if shift_x>=0 and shift_y>=0:after_shift_imge[int(shift_y):,int(shift_x):,:] = bgr[:height-int(shift_y),:width-int(shift_x),:]elif shift_x>=0 and shift_y<0:after_shift_imge[:height+int(shift_y),int(shift_x):,:] = bgr[-int(shift_y):,:width-int(shift_x),:]elif shift_x <0 and shift_y >=0:after_shift_imge[int(shift_y):,:width+int(shift_x),:] = bgr[:height-int(shift_y),-int(shift_x):,:]elif shift_x<0 and shift_y<0:after_shift_imge[:height+int(shift_y),:width+int(shift_x),:] = bgr[-int(shift_y):,-int(shift_x):,:]shift_xy = torch.FloatTensor([[int(shift_x),int(shift_y)]]).expand_as(center)center = center + shift_xymask1 = (center[:,0]>0)& (center[:,0]>height)mask2 = (center[:,1]>0)& (center[:,1]>width)mask = (mask1 & mask2).view(-1,1)boxes_in = boxes[mask.expand_as(boxes)].view(-1,4)if len(boxes_in) == 0:return bgr,boxes,labelsbox_shift = torch.FloatTensor([[int(shift_x),int(shift_y),int(shift_x),int(shift_y)]]).expand_as(boxes_in)boxes_in = boxes_in+box_shiftlabels_in = labels[mask.view(-1)]return after_shift_imge,boxes_in,labels_inreturn bgr,boxes,labelsdef randomScale(self,bgr,boxes):if random.random() < 0.5:scale = random.uniform(0.8,1.2)h,w,c = bgr.shapebgr = cv2.resize(bgr,(int(w*scale),h))scale_tensor = torch.FloatTensor([[scale,1,scale,1]]).expand_as(boxes)boxes = boxes*scale_tensorreturn bgr,boxesreturn bgr,boxesdef randomCrop(self,bgr,boxes,labels):if random.random() < 0.5:center = (boxes[:,:2]+boxes[:,2:])/2height,width,c = bgr.shapeh = random.uniform(0.6*height,height)w = random.uniform(0.6*width,width)x = random.uniform(0,width-w)y = random.uniform(0,height-h)x,y,h,w = int(x),int(y),int(h),int(w)center = center - torch.FloatTensor([[x,y]]).expand_as(center)mask1 = (center[:,0]>0) & (center[:,0]<w)mask2 = (center[:,1]>0) & (center[:,0]<h)mask = (mask1 & mask2).view(-1,1)boxes_in = boxes[mask.expand_as(boxes)].view(-1,4)if(len(boxes_in)==0):return bgr,boxes,labelsbox_shift = torch.FloatTensor([[x,y,x,y]]).expand_as(boxes_in)boxes_in = boxes_in-box_shiftboxes_in[:,0]=boxes_in[:,0].clamp(0,w)boxes_in[:,2]=boxes_in[:,2].clamp(0,w)boxes_in[:,1]=boxes_in[:,1].clamp(0,h)boxes_in[:,3]=boxes_in[:,3].clamp(0,h)labels_in = labels[mask.view(-1)]img_croped = bgr[y:y+h,x:x+w,:]return img_croped,boxes_in,labels_inreturn bgr,boxes,labelsdef subMean(self,bgr,mean):mean = np.array(mean,dtype=np.float32)bgr = bgr - meanreturn bgrdef random_flip(self,im,boxes):if random.random() < 0.5:im_lr = np.fliplr(im).copy()h,w,_ = im.shapexmin = w - boxes[:,2]xmax = w - boxes[:,0]boxes[:,0] = xminboxes[:,2] = xmaxreturn im_lr,boxesreturn im,boxesdef random_bright(self,im,delta=16):alpha = random.random()if alpha > 0.3:im = im * alpha + random.randrange(-delta,delta)im = im.clip(min=0,max=255).astype(np.uint8)return imif __name__=='__main__':from torch.utils.data import DataLoaderimport torchvision.transforms as transformsfile_root ='D:\python\py_works\deep_learning\_04_computer_cv\_01_yolo_v1_code' ## xx.jpglist_f = r'D:\python\py_works\deep_learning\_04_computer_cv\_01_yolo_v1_code\2007_train.txt'train_dataset = yoloDataset(root=file_root,list_file=list_f,train=True,transform = [transforms.ToTensor()])train_loader = DataLoader(train_dataset,batch_size=1,shuffle=False,num_workers=0)train_iter = iter(train_loader)# for i in range(5):# img,target = next(train_iter)# print(target[target[...,0]>0])for i,(images,target) in enumerate(train_loader):print(1111111111111111111111)print(target)print(images)
2.3 yolo_v1的训练
论文中的主干模型是由24层卷积和两个全联接组成。下面代码中训练主要包括backbone(ResNet、VGG)、LOSS、代入数据训练模型。
2.3.1 主干网络backbone
2.3.1.1 利用ResNet作为主干网络
ResNet主要分为三部分。首先通过卷积和池化进行两次步长为2的下采样,然后通过残差模块layer1~layer5扩展通道数和三次步长为2的下采样,最后一次卷积、批归一化、激活得到特征图[7,7,30]。
我们使用下面的resnet50网络,按照YOLOV1的要求输入图像的尺寸为448×448×3,要求输出7×7×30的张量,而ResNet50可以输入224任意倍数的彩色三通道图片(当然也包括448),所以与YOLOV1算法契合度较高。若输入448×448×3的图片经过ResNet50会得到2048×14×14的张量,所以还需要进行后续处理。
import math
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
import torch.nn.functional as F__all__ = ['ResNet','resnet18','resnet34','resnet50','resnet101','resnet152']model_urls = {'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth','resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',# 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth','resnet50': 'https://download.pytorch.org/models/resnet50-0676ba61.pth','resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth','resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
}def conv3x3(in_planes,out_planes,stride=1):return nn.Conv2d(in_planes,out_planes,kernel_size=3,stride=stride,padding=1,bias=False)class BasicBlock(nn.Module):expansion = 1def __init__(self,inplanes,planes,stride=1,downsample=None):super(BasicBlock, self).__init__()self.conv1 = conv3x3(inplanes, planes, stride)self.bn1 = nn.BatchNorm2d(planes)self.relu = nn.ReLU(inplace=True)self.conv2 = conv3x3(planes, planes)self.bn2 = nn.BatchNorm2d(planes)self.downsample = downsampleself.stride = stridedef forward(self,x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)if self.downsample is not None:residual = self.downsample(x)out += residualout = self.relu(out)return outclass Bottleneck(nn.Module):expansion = 4def __init__(self, inplanes, planes, stride=1, downsample=None):super(Bottleneck, self).__init__()self.conv1 = nn.Conv2d(inplanes,planes,kernel_size=1,bias=False)self.bn1 = nn.BatchNorm2d(planes)self.conv2 = nn.Conv2d(planes,planes,kernel_size=3,stride=stride,padding=1,bias=False)self.bn2 = nn.BatchNorm2d(planes)# self.conv3 = nn.Conv2d(inplanes, planes * self.expansion, kernel_size=1,bias=False)self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1,bias=False)self.bn3 = nn.BatchNorm2d(planes* self.expansion)self.relu = nn.ReLU(inplace=True)self.downsample = downsampleself.stride = stridedef forward(self,x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)if self.downsample is not None:residual = self.downsample(x)out += residualout = self.relu(out)return outclass detnet_bottleneck(nn.Module):# no expansion# dilation = 2# type B use 1x1 convexpansion = 1def __init__(self, in_planes, planes, stride=1, block_type='A'):super(detnet_bottleneck, self).__init__()self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)self.bn1 = nn.BatchNorm2d(planes)self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=2, bias=False,dilation=2)self.bn2 = nn.BatchNorm2d(planes)self.conv3 = nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False)self.bn3 = nn.BatchNorm2d(self.expansion*planes)self.downsample = nn.Sequential()if stride != 1 or in_planes != self.expansion*planes or block_type == 'B':self.downsample = nn.Sequential(nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(self.expansion*planes))def forward(self, x):out = F.relu(self.bn1(self.conv1(x)))out = F.relu(self.bn2(self.conv2(out)))out = self.bn3(self.conv3(out))out += self.downsample(x)out = F.relu(out)return outclass ResNet(nn.Module): # model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs)def __init__(self, block, layers, num_classes=1470):self.inplanes = 64super(ResNet, self).__init__()self.conv1 = nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3,bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3,stride=2,padding=1) # torch.Size([2, 64, 112, 112])self.layer1 = self._make_layer(block,64,layers[0])self.layer2 = self._make_layer(block,128,layers[1],stride=2)self.layer3 = self._make_layer(block,256,layers[2],stride=2)self.layer4 = self._make_layer(block,512,layers[3],stride=2)# self.layer5 = self._make_detnet_layer(in_channels=512) self.layer5 = self._make_detnet_layer(in_channels=2048) # (in_channels=2048)self.avgpool = nn.AvgPool2d(2) # 添加平均池化层,kernel_size = 2 , stride = 2self.conv_end = nn.Conv2d(256,30,kernel_size=3,stride=1,padding=1,bias=False)self.bn_end = nn.BatchNorm2d(30)for m in self.modules():if isinstance(m,nn.Conv2d):n = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsm.weight.data.normal_(0,math.sqrt(2./n))elif isinstance(m,nn.BatchNorm2d):m.weight.data.fill_(1)m.bias.data.zero_()def _make_layer(self,block, planes, blocks, stride=1): # 64,3downsample = Noneif stride != 1 or self.inplanes != planes * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.inplanes,planes*block.expansion,kernel_size=1,stride=stride,bias=False),nn.BatchNorm2d(planes*block.expansion),)layers = []layers.append(block(self.inplanes,planes,stride,downsample))self.inplanes = planes*block.expansionfor i in range(1,blocks):layers.append(block(self.inplanes,planes))return nn.Sequential(*layers)def _make_detnet_layer(self,in_channels):layers = []layers.append(detnet_bottleneck(in_planes=in_channels, planes=256, block_type='B'))layers.append(detnet_bottleneck(in_planes=256, planes=256, block_type='A'))layers.append(detnet_bottleneck(in_planes=256, planes=256, block_type='A'))return nn.Sequential(*layers)def forward(self,x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)# print(x.shape)x = self.layer5(x)# print(x.shape)x = self.avgpool(x) # batch_size*256*7*7# print(x.shape)x = self.conv_end(x)x = self.bn_end(x)x = F.sigmoid(x)x = x.permute(0,2,3,1)return xdef resnet18(pretrained=False,**kwargs):model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)if pretrained:model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))return modeldef resnet34(pretrained=False,**kwargs):model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs)if pretrained:model.load_state_dict(model_zoo.load_url(model_urls['resnet34']))return modeldef resnet50(pretrained=False,**kwargs):model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)if pretrained:model.load_state_dict(model_zoo.load_url(model_urls['resnet50']))return modeldef resnet101(pretrained=False,**kwargs):model = ResNet(BasicBlock, [3, 4, 23, 3], **kwargs)if pretrained:model.load_state_dict(model_zoo.load_url(model_urls['resnet101']))return modeldef resnet152(pretrained=False,**kwargs):model = ResNet(BasicBlock, [3, 8, 36, 3], **kwargs)if pretrained:model.load_state_dict(model_zoo.load_url(model_urls['resnet152']))return modeldef test():import torchfrom torch.autograd import Variable# model = resnet18()model = resnet50()x = torch.rand(1, 3, 448, 448)# x = torch.rand(1, 3, 224, 224)x = Variable(x)out = model(x)print(out.shape)if __name__ == '__main__':test()
2.3.1.2 利用VGG作为主干网络
VGG 模型分为两大部分,一部分用卷积、池化提取特征,然后通过两次全连接得到特征。
import math
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.model_zoo as model_zoo__all__ = ['VGG','vgg11','vgg11_bn','vgg13','vgg13_bn', 'vgg16','vgg16_bn','vgg19','vgg19_bn']model_urls = {'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth','vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth','vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth','vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth','vgg11_bn': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth','vgg13_bn': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth','vgg16_bn': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth','vgg19_bn': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth',
}class VGG(nn.Module):def __init__(self,features,num_classes=1000,image_size=448):super(VGG,self).__init__()self.features = featuresself.image_size = image_sizeself.classifier = nn.Sequential(nn.Linear(512*7*7,4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096,1470))self._initialize_weights()def forward(self,x):x = self.features(x)x = x.view(x.size(0),-1)x = self.classifier(x)x = F.sigmoid(x)x = x.view(-1,7,7,30)return xdef _initialize_weights(self):for m in self.modules():if isinstance(m,nn.Conv2d):n = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsm.weight.data.normal_(0,math.sqrt(2./n))if m.bias is not None:m.bias.data.zero_()elif isinstance(m, nn.BatchNorm2d):m.weight.data.fill_(1)m.bias.data.zero_()elif isinstance(m, nn.Linear):m.weight.data.normal_(0, 0.01)m.bias.data.zero_()def make_layers(cfg,batch_norm=False):layers = []in_channels = 3first_flag = Truefor v in cfg:s = 1if (v == 64 and first_flag):s = 2first_flag = Falseif v == 'M':layers += [nn.MaxPool2d(kernel_size=2,stride=2)]else:conv2d = nn.Conv2d(in_channels,v,kernel_size=3,stride=s,padding=1)if batch_norm:layers += [conv2d,nn.BatchNorm2d(v),nn.ReLU(inplace=True)]else:layers += [conv2d,nn.ReLU(inplace=True)]in_channels = vreturn nn.Sequential(*layers)cfg = { 'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M']}def vgg11(pretrained=False,**kwargs):model = VGG(make_layers(cfg['A']),**kwargs)if pretrained:model.load_state_dict(model_zoo.load_url(model_urls['vgg11']))return modeldef vgg11_bn(pretrained=False,**kwargs):model = VGG(make_layers(cfg['A'],batch_norm=True),**kwargs)if pretrained:model.load_state_dict(model_zoo.load_url([vgg11_bn]))return modeldef vgg13(pretrained=False,**kwargs):model = VGG(make_layers(cfg['B']),**kwargs)if pretrained:model.load_state_dict(model_zoo.load_url(model_urls['vgg13']))return modeldef vgg13_bn(pretrained=False, **kwargs):model = VGG(make_layers(cfg['B'], batch_norm=True), **kwargs)if pretrained:model.load_state_dict(model_zoo.load_url(model_urls['vgg13_bn']))return modeldef vgg16(pretrained=False, **kwargs):model = VGG(make_layers(cfg['D']), **kwargs)if pretrained:model.load_state_dict(model_zoo.load_url(model_urls['vgg16']))return modeldef vgg16_bn(pretrained=False, **kwargs):model = VGG(make_layers(cfg['D'], batch_norm=True), **kwargs)if pretrained:model.load_state_dict(model_zoo.load_url(model_urls['vgg16_bn']))return modeldef vgg19(pretrained=False, **kwargs):model = VGG(make_layers(cfg['E']), **kwargs)if pretrained:model.load_state_dict(model_zoo.load_url(model_urls['vgg19']))return modeldef vgg19_bn(pretrained=False, **kwargs):model = VGG(make_layers(cfg['E'], batch_norm=True), **kwargs)if pretrained:model.load_state_dict(model_zoo.load_url(model_urls['vgg19_bn']))return modeldef test():import torchfrom torch.autograd import Variablemodel = vgg16()img = torch.rand(2,3,448,448)img = Variable(img)output = model(img)print(output.size())if __name__ == '__main__':test()
2.3.2 损失函数
2.3.2.1 损失函数
YOLOV1计算损失的特殊性:用MSE计算损失,对框回归的宽高先开方在进行MSE,解决大小物体损失差异过大的问题。对回归和前景分类赋予不同的权重,解决正负样本不均衡问题。
计算损失时,输入的是真实框target_tensor、和解码后的预测框pred_tensor[batch_size,7,7,30].
(1)计算损失流程:
- 根据真实框的置信度对target_tensor和pred_tensor取出没有真实框的样本sample_nobj[-1,30],在取出样本的第5列和第10列,用mse计算负样本的损失noobj_loss。
- 根据真实框的置信度对target_tensor和pred_tensor取出没有真实框的样本sample_obj[-1,30]。对取出的样本分别在提取target_tensor和pred_tensor的框和物体类别,计算类别损失。
- 根据sample_obj,计算预测框和真实框的IuO,根据IuO选出与真实框匹配的样本,计算框的回归损失和正样本的损失。预测正样本的真实值用IuO计算。
- 对各种损失加权以平衡正负样本不平衡
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variableclass yoloLoss(nn.Module):def __init__(self,S,B,l_coord,l_noobj):super(yoloLoss, self).__init__()self.S = Sself.B = Bself.l_coord = l_coordself.l_noobj = l_noobjdef compute_iou(self,box1,box2):'''Args:box1[N,4],box2[M,4]Return:iou, sized [N,M].'''N = box1.size()[0]M = box2.size()[0]lt = torch.max(box1[:,:2].unsqueeze(1).expand(N,M,2),box2[:,:2].unsqueeze(0).expand(N,M,2))rd = torch.min(box1[:,2:].unsqueeze(1).expand(N,M,2),box2[:,2:].unsqueeze(0).expand(N,M,2))wh = rd-ltwh[wh<0] = 0inter = wh[...,0] * wh[...,1]area1 = ((box1[:,2]-box1[:,0])*(box1[:,3]-box1[:,1])).unsqueeze(1).expand_as(inter)area2 = ((box2[:,2]-box2[:,0])*(box2[:,3]-box2[:,1])).unsqueeze(0).expand_as(inter)iou = inter/(area1+area2-inter)return ioudef forward(self,pred_tensor,target_tensor):''' pred_tensor[b,S,S,B*5+20] ; target_tensor[b,S,S,30]'''# 1 mask_obj_nobjN = pred_tensor.size(0)coo_mask = target_tensor[...,4] > 0 # 存在物体的mask [batch_size,7,7]noo_mask = target_tensor[...,4] == 0 # 不存在物体的maskcoo_mask = coo_mask.unsqueeze(-1).expand_as(target_tensor) # [b,7,7,30]noo_mask = noo_mask.unsqueeze(-1).expand_as(target_tensor)# 2 nobj lossnoo_pred = pred_tensor[noo_mask].view(-1,30) # 没有物体的预测值# print('noo_mask.shape:',noo_mask.shape)# print('pred_tensor.shape:',pred_tensor.shape)# print('noo_pred.shape:',noo_pred.shape)noo_target = target_tensor[noo_mask].view(-1,30) # 存在物体的预测值noo_pred_c = noo_pred[:,[4,9]].flatten() # 取出预测值中的负样本的置信度noo_target_c = noo_target[:,[4,9]].flatten() # 取出标签中负样本的置信度noobj_loss = F.mse_loss(noo_pred_c,noo_target_c,size_average=False) # 计算负样本损失# 3 obj: box , classcoo_pred = pred_tensor[coo_mask].view(-1,30) # 存在物体的预测值box_pred = coo_pred[:,:10].contiguous().view(-1,5) # 预测框class_pred = coo_pred[:,10:] # 预测类别coo_target = target_tensor[coo_mask].view(-1,30) # 存在物体的标签box_target = coo_target[:,:10].contiguous().view(-1,5) # 真实框class_target = coo_target[:,10:] # 真实类别# 3.1 class lossclass_loss = F.mse_loss(class_pred,class_target,size_average=False) # 类别损失# 4 obj_iou(每个网格上有两个预测框,根据IoU选出与真实框最匹配的预测框计算回归损失和正样本损失)coo_response_mask = torch.ByteTensor(box_target.size()).zero_()# coo_response_mask = torch.tensor(coo_response_mask,dtype=torch.bool)box_target_iou = torch.zeros(box_target.size())for i in range(0,box_target.size(0),2): # 遍历存在物体的框box1 = box_pred[i:i+2] # 存在物体的两个预测框box1_xy = Variable(torch.FloatTensor(box1.size()))box1_xy[:,:2] = box1[:,:2] / 14. - 0.5*box1[:,2:4]box1_xy[:,2:4] = box1[:,:2] / 14. + 0.5*box1[:,2:4]box2 = box_target[i].view(-1,5) # 存在物体的一个真实框box2_xy = Variable(torch.FloatTensor(box2.size()))box2_xy[:,:2] = box2[:,:2] / 14. - 0.5*box2[:,2:4]box2_xy[:,2:4] = box2[:,:2] / 14. + 0.5*box2[:,2:4]iou = self.compute_iou(box1_xy[:,:4],box2_xy[:,:4])max_iou,max_index = iou.max(0) # 计算预测框和真实框的IoU,并返回最有的IoU和预测框的下标coo_response_mask[i+max_index] = 1box_target_iou[i+max_index,4] = max_ioubox_target_iou = Variable(box_target_iou)# 4.1 obj_lossbox_pred_response = box_pred[coo_response_mask].view(-1,5) # 与真实框最匹配的预测框box_target_response = box_target[coo_response_mask].view(-1,5) # 真是框,这一步多余。box_target_response_iou = box_target_iou[coo_response_mask].view(-1,5) # 正样本的概率# 4.1.1 contain_losscontain_loss = F.mse_loss(box_pred_response[:,4],box_target_response_iou[:,4],size_average = False) # 正样本损失# 4.1.2 loc_lossloc_loss = F.mse_loss(box_pred_response[:,:2],box_target_response[:,:2],size_average = False)+ \F.mse_loss(torch.sqrt(box_pred_response[:,2:]),torch.sqrt(box_target_response[:,2:]),size_average = False) # 框的回归损失return (self.l_noobj*noobj_loss + class_loss + 2*contain_loss + self.l_coord*loc_loss)/N 加权平均损失if __name__ == '__main__':pred_tensor = torch.randn(2,14,14,30)target_tensor = pred_tensor+0.01yolo_loss = yoloLoss(14,8,5,0.5)loss = yolo_loss(pred_tensor,target_tensor)print(loss)
2.3.2.2 IoU的计算
I. 计算框相交部分的左上角和右下角坐标lt,rd。
II. 计算交集面积inter和相交框的各自面积area1、area2。
III.根据以上步骤计算交并比iou。
def compute_iou(self,box1,box2):'''Args:box1[N,4],box2[M,4]Return:iou, sized [N,M].'''N = box1.size()[0]M = box2.size()[0]lt = torch.max(box1[:,:2].unsqueeze(1).expand(N,M,2), # box1.shape[N,4]-->box1[:,:2].shape[N,2]-->box1[:,:2].unsqueeze(1).shape[N,1,2]-->lt.shape[N,M,2]box2[:,:2].unsqueeze(0).expand(N,M,2))rd = torch.min(box1[:,2:].unsqueeze(1).expand(N,M,2),box2[:,2:].unsqueeze(0).expand(N,M,2))wh = rd-lt # wh.shape(N,M,2)wh[wh<0] = 0inter = wh[...,0] * wh[...,1] # [N,M]area1 = ((box1[:,2]-box1[:,0])*(box1[:,3]-box1[:,1])).unsqueeze(1).expand_as(inter) # area1.shape[N,M]area2 = ((box2[:,2]-box2[:,0])*(box2[:,3]-box2[:,1])).unsqueeze(0).expand_as(inter)iou = inter/(area1+area2-inter) # iou.shape[N,M]return iou
2.3.3 训练
训练流程:
- 导入库
- 设置超参数
- 模型
- 导入模型参数
- 损失函数
- 设置优化器
- 导入数据
- 训练
# 1 导入库
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
import torch
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision import models
from torch.autograd import Variablefrom _05_vgg_yolo import vgg16_bn
from _04_resnet_yolo import resnet50
from _06_yolo_loss import yoloLoss
from _03_data_enhance import yoloDataset# 忽略烦人的红色提示
import warnings
warnings.filterwarnings("ignore")
import numpy as np# 2 设置参数
use_gpu = torch.cuda.is_available()
file_root = r'D:\python\py_works\deep_learning\_04_computer_cv\_01_yolo_v1_code'
learning_rate = 0.001
num_epochs = 50
batch_size = 3
use_resnet = True# 3 backbone
if use_resnet:net = resnet50()
else:net = vgg16_bn()
# print(net)# 3.1 导入预训练参数(我们用restnet50进行训练,这里演示仅仅用了6张图像进行训练)
if use_resnet:resnet = models.resnet50(pretrained=True) # Truenew_state_dict = resnet.state_dict()dd = net.state_dict()for k in new_state_dict.keys():if k in dd.keys() and not k.startswith('fc'):dd[k] = new_state_dict[k]net.load_state_dict(dd)
else:vgg = models.vgg16_bn(pretrained=False)new_state_dict = vgg.state_dict()dd = net.state_dict()for k in new_state_dict.keys():if k in dd.keys() and k.startswith('features'):dd[k] = new_state_dict[k]net.load_state_dict(dd)
if False:net.load_state_dict(torch.load('best.pth'))# 4 Loss
criterion = yoloLoss(7,2,5,0.5)if use_gpu:net.cuda()
# 模型训练
net.train()# 5 参数
params = []
params_dict = dict(net.named_parameters())for k,v in params_dict.items():if k.startswith('features'):params += [{'params':[v],'lr':learning_rate*1}]else:params += [{'params':[v],'lr':learning_rate*1}]# 6 优化器
optimizer = torch.optim.SGD(params,lr=learning_rate,momentum=0.9,weight_decay=5e-4)# 7 导入数据train_dataset = yoloDataset(root=file_root,list_file='2007_train.txt',train=True,transform = [transforms.ToTensor()] )
train_loader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=0)test_dataset = yoloDataset(root=file_root,list_file='2007_test.txt',train=False,transform = [transforms.ToTensor()] )
test_loader = DataLoader(test_dataset,batch_size=batch_size,shuffle=False,num_workers=0)print('the dataset has %d images' % (len(train_dataset)))
print('the batch_size is %d' % (batch_size))
logfile = open('log.txt', 'w')num_iter = 0
best_test_loss = 1000# 8 训练
num_batches = len(train_loader)
for epoch in range(num_epochs):net.train() # 设置为训练模式if epoch == 30:learning_rate = 0.0001if epoch == 40:learning_rate = 0.00001for params_group in optimizer.param_groups:params_group['lr'] = learning_rateprint('\n\nStarting epoch %d / %d' % (epoch + 1, num_epochs))print('Learning Rate for this epoch: {}'.format(learning_rate))total_loss = 0.for i,(images,target) in enumerate(train_loader):images = Variable(images)print(images.shape)target = Variable(target)if use_gpu:images,target = images.cuda(),target.cuda()pred = net(images)# print('pred.shape:',pred.shape)# print('target.shape:',target.shape)loss = criterion(pred,target)total_loss += loss.data.item()optimizer.zero_grad()loss.backward()optimizer.step()if (i+1) % 2 == 0:print ('Epoch [%d/%d], Iter [%d/%d] Loss: %.4f, average_loss: %.4f'%(epoch+1, num_epochs, i+1, len(train_loader), loss.data.item(), total_loss / (i+1)))num_iter += 1print('loss_train = ', total_loss / (i+1) )validation_loss = 0.0net.eval() # 设置为评估模式for i,(images,target) in enumerate(test_loader):images = Variable(images,volatile=True)target = Variable(target,volatile=True)if use_gpu:images,target = images.cuda(),target.cuda()pred = net(images)loss = criterion(pred,target)validation_loss += loss.item()validation_loss /= len(test_loader)print('loss_val = ',validation_loss)print('best_test_loss = ', best_test_loss)if best_test_loss > validation_loss:best_test_loss = validation_lossprint('get best test loss %.5f' % best_test_loss)torch.save(net.state_dict(),'best.pth')logfile.writelines(str(epoch) + '\t' + str(validation_loss) + '\n')logfile.flush()torch.save(net.state_dict(),'yolo.pth')

2.3.4 预测
NMS步骤:
(1)对于类别1, 从概率最大的bbox F开始,分别判断A、B、C、D、E与F的IOU是否大于设定的阈值。
(2) 假设B、D与F的重叠度超过阈值,那么就扔掉B、D(将其置信度置0),然后保留F。
(3) 从剩下的矩形框A、C、E中,选择概率最大的E,然后判断A、C与E的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
(4) 重复这个过程,找到此类别所有被保留下来的矩形框。
(5) 对于类别2,类别3等等…都要重复以上4个步骤。
-
首先需要导入模型以及参数,并且设置好有关NMS的两个参数:
置信度以及IOU最大值。然后就可以开始预测了。首先需要通过opencv读取图片并且将其resize为448✖448的RGB图像,将其进行均值处理后输入神经网络得到7✖7✖30的张量。 -
然后运行 decode 方法:因为一个grid ceil只预测一个物体,而一个grid ceil生成两个bbox。这里对grid ceil进行以下操作。
- 1、选择置信度较高的bbox。
- 2、选择20种类别概率中的最大者作为这个grid ceil预测的类别。
- 3、置信度乘以物体类别概率作为物体最终的概率。
- 最终输入一个7✖7✖6的张量,7✖7代表grid ceil。6 = bbox的4个坐标信息+类别概率+类别代号
-
最后运行 NMS 方法对bbox进行筛选:因为bbox的4个坐标信息为(xc,yc,w,h)需要将其转化为(x,y,w,h)后才能进行非极大值抑制处理。
import torch
from torch.autograd import Variable
from _04_resnet_yolo import resnet50
import torchvision.transforms as transforms
import cv2
import numpy as np
import matplotlib.pyplot as plt# 忽略烦人的红色提示
import warnings
warnings.filterwarnings("ignore")Color = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0], [0, 0, 128],[128, 0, 128],[0, 128, 128],[128, 128, 128],[64, 0, 0],[192, 0, 0],[64, 128, 0],[64, 0, 128],[192, 128, 0],[192, 0, 128],[64, 128, 128],[192, 128, 128],[0, 64, 0],[128, 64, 0],[0, 192, 0],[128, 192, 0],[0, 64, 128]]VOC_CLASSES = ( 'aeroplane', 'bicycle', 'bird', 'boat','bottle', 'bus', 'car', 'cat', 'chair','cow', 'diningtable', 'dog', 'horse','motorbike', 'person', 'pottedplant','sheep', 'sofa', 'train', 'tvmonitor')CLASS_NUM = len(VOC_CLASSES)confident = 0.5
iou_con = 0.5class Pred():def __init__(self, model, img_root):self.model = modelself.img_root = img_rootdef result(self):img = cv2.imread(self.img_root)h, w, _ = img.shapeimage = cv2.resize(img, (448, 448))img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)mean = (123, 117, 104) # RGBimg = img - np.array(mean, dtype=np.float32)transform = transforms.ToTensor()img = transform(img)img = img.unsqueeze(0) # 输入要求是4维的Result = self.model(img) # 1*7*7*30bbox = self.Decode(Result)bboxes = self.NMS(bbox) # n*6 bbox坐标是基于7*7网格需要将其转换成448if len(bboxes) == 0:print("未识别到任何物体")print("可调小 confident 以及 iou_con")print("也可能是由于训练不充分,可在训练时将epoch增大")for i in range(0, len(bboxes)): # bbox坐标将其转换为原图像的分辨率bboxes[i][0] = bboxes[i][0] * 64bboxes[i][1] = bboxes[i][1] * 64bboxes[i][2] = bboxes[i][2] * 64bboxes[i][3] = bboxes[i][3] * 64x1 = bboxes[i][0].item() # 后面加item()是因为画框时输入的数据不可一味tensor类型x2 = bboxes[i][1].item()y1 = bboxes[i][2].item()y2 = bboxes[i][3].item()class_name = bboxes[i][5].item()label = VOC_CLASSES[int(class_name)]print('预测的框及类别:', x1, x2, y1, y2, label)label = VOC_CLASSES[int(class_name)] + str(round(bboxes[i][4].item(), 2)) # 类别及confidencecolor = Color[int(class_name)]text_size, baseline = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), color) # 画矩形框cv2.putText(image, text=label,org=(int(x1), int(y1) + text_size[1]), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=0.5,color = (255,255,255),thickness=1)cv2.imshow('img', image)cv2.waitKey(0)def Decode(self, result): # x -> 1**7*30result = result.squeeze() # 7*7*30grid_ceil1 = result[:, :, 4].unsqueeze(2) # 7*7*1grid_ceil2 = result[:, :, 9].unsqueeze(2)grid_ceil_con = torch.cat((grid_ceil1, grid_ceil2), 2) # 7*7*2grid_ceil_con, grid_ceil_index = grid_ceil_con.max(2) # 按照第二个维度求最大值 7*7 一个grid ceil两个bbox,两个confidenceclass_p, class_index = result[:, :, 10:].max(2) # size -> 7*7 找出单个grid ceil预测的物体类别最大者class_confidence = class_p * grid_ceil_con # 7*7 真实的类别概率bbox_info = torch.zeros(7, 7, 6)for i in range(0, 7):for j in range(0, 7):bbox_index = grid_ceil_index[i, j]bbox_info[i, j, :5] = result[i, j, (bbox_index * 5):(bbox_index + 1) * 5] # 删选bbox 0-5 或者5-10bbox_info[:, :, 4] = class_confidencebbox_info[:, :, 5] = class_indexreturn bbox_info # 7*7*6 6 = bbox4个信息+类别概率+类别代号def NMS(self, bbox, iou_con=iou_con):"""非极大值抑制"""for i in range(0, 7):for j in range(0, 7):# xc = bbox[i, j, 0] # 目前bbox的四个坐标是以grid ceil的左上角为坐标原点 而且单位不一致# yc = bbox[i, j, 1] # (xc,yc) 单位= 7*7 (w,h) 单位= 1*1# w = bbox[i, j, 2] * 7# h = bbox[i, j, 3] * 7# Xc = i + xc# Yc = j + yc# xmin = Xc - w/2 # 计算bbox四个顶点的坐标(以整张图片的左上角为坐标原点)单位7*7# xmax = Xc + w/2# ymin = Yc - h/2# ymax = Yc + h/2 # 更新bbox参数 xmin and ymin的值有可能小于0xmin = j + bbox[i, j, 0] - bbox[i, j, 2] * 7 / 2 # xminxmax = j + bbox[i, j, 0] + bbox[i, j, 2] * 7 / 2 # xmaxymin = i + bbox[i, j, 1] - bbox[i, j, 3] * 7 / 2 # yminymax = i + bbox[i, j, 1] + bbox[i, j, 3] * 7 / 2 # ymaxbbox[i, j, 0] = xminbbox[i, j, 1] = xmaxbbox[i, j, 2] = yminbbox[i, j, 3] = ymaxbbox = bbox.view(-1, 6) # 49*6bboxes = []ori_class_index = bbox[:, 5]class_index, class_order = ori_class_index.sort(dim=0, descending=False)class_index = class_index.tolist() # 从0开始排序到7bbox = bbox[class_order, :] # 更改bbox排列顺序a = 0for i in range(0, CLASS_NUM):num = class_index.count(i)if num == 0:continuex = bbox[a:a + num, :] # 提取同一类别的所有信息score = x[:, 4]score_index, score_order = score.sort(dim=0, descending=True)y = x[score_order, :] # 同一种类别按照置信度排序if y[0, 4] >= confident: # 物体类别的最大置信度大于给定值才能继续删选bbox,否则丢弃全部bboxfor k in range(0, num):y_score = y[:, 4] # 每一次将置信度置零后都重新进行排序,保证排列顺序依照置信度递减_, y_score_order = y_score.sort(dim=0, descending=True)y = y[y_score_order, :]if y[k, 4] > 0:area0 = (y[k, 1] - y[k, 0]) * (y[k, 3] - y[k, 2])for j in range(k + 1, num):area1 = (y[j, 1] - y[j, 0]) * (y[j, 3] - y[j, 2])x1 = max(y[k, 0], y[j, 0])x2 = min(y[k, 1], y[j, 1])y1 = max(y[k, 2], y[j, 2])y2 = min(y[k, 3], y[j, 3])w = x2 - x1h = y2 - y1if w < 0 or h < 0:w = 0h = 0inter = w * hiou = inter / (area0 + area1 - inter)# iou大于一定值则认为两个bbox识别了同一物体删除置信度较小的bbox# 同时物体类别概率小于一定值则认为不包含物体if iou >= iou_con or y[j, 4] < confident:y[j, 4] = 0for mask in range(0, num):if y[mask, 4] > 0:bboxes.append(y[mask])a = num + areturn bboxesif __name__ == '__main__':model = resnet50()print('load model...')model.load_state_dict(torch.load('best.pth'))model.eval()#model.cuda()image_name = 'D:\python\py_works\deep_learning\_04_computer_cv\data\VOCdevkit\VOC2007\JPEGImages/000018.jpg'image = cv2.imread(image_name)print(image.shape)print('predicting...')pred = Pred(model,image_name)pred.result()

这篇关于经典目标检测YOLO系列(1)YOLO-V1算法及其在VOC2007数据集上的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






