本文主要是介绍《超详细》小白如何用pycharm进行RMB识别(含模型建立,损失函数,优化函数与具体组合实现功能的具体流程),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、模型板块
模型构建经验总结
1. 在init函数中设定自己想要的卷积层和线性层
2.在forward函数中制定数据信息变化过程
基础模型 Module
init函数部分
forward函数部分
Sequential模型(本项目并没有用到,但还是说一说)
最简单的序贯模型
给每一个层添加名称
二、损失函数与优化函数
1.损失函数
2.优化函数
三、具体组合实现功能的流程
参数设定
数据部分的实例化
循环训练部分
四.运行结果展示
总结
一、模型板块
模型构建经验总结
1. 在init函数中设定自己想要的卷积层和线性层
self.conv1 = nn.Conv2d(输入层数, 输出层数, 卷积核大小)
self.fc1 = nn.Linear(层数*长*宽, 想要的数值)(最终目的是缩小为分类的种类数,但不能直接一步成,必须分成几次达成)
2.在forward函数中制定数据信息变化过程
先是依次进行以下操作,直到无法继续缩小图片信息为止(长宽不满足执行条件) out = F.relu(self.conv1(x)) (长宽减少,层数增加) 执行条件:满足卷积神将网络的计算公式:N=(W-F+2P)/S+1其中N:输出大小W:输入大小F:卷积核大小P:填充值的大小S:步长大小out = F.max_pool2d(out, 2) (长宽减半,层数不变)执行条件:长宽为偶数
当无法继续缩小图片信息后,执行设定好的线性层即可。
基础模型 Module
- 如果你想做一个网络,需要先定义一个Class,继承 nn.Module(这个是必须的,所以先import torch.nn as nn,nn是一个工具箱,很好用)
- 这个Class里面主要写两个函数,一个是初始化的__init__函数,另一个是forward函数。
下面是使用 Module 的模板:
class 网络名字(nn.Module):def __init__(self, 一些定义的参数):super(网络名字, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5)self.layer1 = nn.Linear(num_input, num_hidden)self.layer2 = nn.Sequential(...)...定义需要用的网络层def forward(self, x): # 定义前向传播x1 = self.layer1(x)x2 = self.layer2(x)x = x1 + x2...return xinit函数部分
1. __init__里面就是定义卷积层及线性层,先得super()一下,给父类nn.Module初始化一下。在这个里面主要就是定义卷积层的,比如第一层,我们叫它conv1,把它定义成输入3通道,输出6通道,卷积核5*5的的一个卷积层。
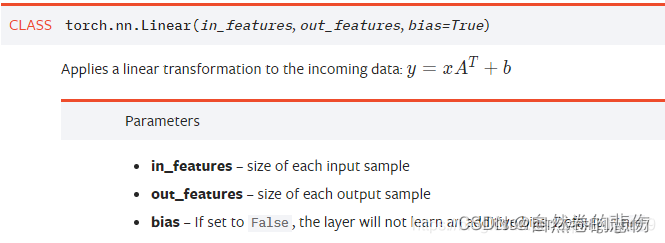
2. 而torch.nn.Linear就是神经网络中的线性层,可以实现形如y=Xweight^T+b的加和功能。
forward函数部分
forward里面就是真正执行数据的流动。比如下面的代码,输入的x先经过定义的conv1,再经过激活函数F.relu()。下一步的F.max_pool2d池化也是一样的。在一系列流动以后,最后把x返回到外面去。
本项目的 forward函数部分 如下:
def forward(self, x): #4 3 32 32 ->nn.Conv2d(3, 6, 5)-> 4 6 28 28out = F.relu(self.conv1(x)) #32->28 4 6 28 28out = F.max_pool2d(out, 2) #4 6 14 14out = F.relu(self.conv2(out)) # 4 16 10 10out = F.max_pool2d(out, 2) # 4 16 5 5out = out.view(out.size(0), -1) #4 400out = F.relu(self.fc1(out))out = F.relu(self.fc2(out))out = self.fc3(out)return out补充:池化与下采样的关系如下
下采样和池化应该是包含关系,池化属于下采样,而下采样不局限于池化,如果卷积 stride=2,此时也可以把这种卷积叫做下采样。
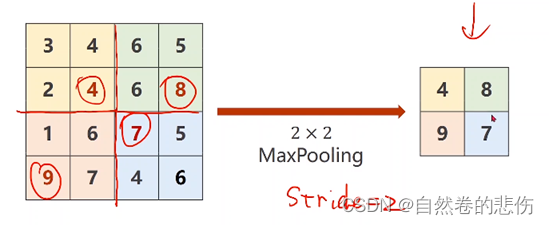
池化方法:1. max-pooling:对邻域内特征点取最大值
2. mean-pooling:对邻域内特征点求平均。
池化作用:1. 降维,减少网络要学习的参数数量
2. 防止过拟合
3. 扩大感受野
4. 实现不变性(平移、旋转、尺度不变性)
Sequential模型(本项目并没有用到,但还是说一说)
概念:
- 类似于keras中的序贯模型,当一个模型较简单的时候,我们可以使用torch.nn.Sequential类来实现简单的顺序连接模型。
- 这个模型也是继承自Module类的。
特点:
1. 具有顺序性,各网络层之间严格按照顺序执行。
最简单的序贯模型
import torch.nn as nn
model = nn.Sequential(nn.Conv2d(1,20,5),nn.ReLU(),nn.Conv2d(20,64,5),nn.ReLU())print(model)
print(model[2]) # 通过索引获取第几个层
'''运行结果为:
Sequential((0): Conv2d(1, 20, kernel_size=(5, 5), stride=(1, 1))(1): ReLU()(2): Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1))(3): ReLU()
)
Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1))
'''注:这样做有一个问题,每一个层是没有名称,默认的是以0、1、2、3来命名,从上面的运行结果也可以看出。下文会给出如何给每一个层添加名称。
而其真正运用与项目时,代码举例如下:
class LeNetSequential(nn.Module):def __init__(self, classes):super(LeNetSequential, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 6, 5),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, 5),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.classifier = nn.Sequential(nn.Linear(16*5*5, 120),nn.ReLU(),nn.Linear(120, 84),nn.ReLU(),nn.Linear(84, classes),)def forward(self, x):x = self.features(x)x = x.view(x.size()[0], -1)x = self.classifier(x)return x主要是起到了将顺序执行的多个网络层进行包装的作用。
给每一个层添加名称
import torch.nn as nn
from collections import OrderedDict
model = nn.Sequential(OrderedDict([('conv1', nn.Conv2d(1,20,5)),('relu1', nn.ReLU()),('conv2', nn.Conv2d(20,64,5)),('relu2', nn.ReLU())]))print(model)
print(model[2]) # 通过索引获取第几个层
'''运行结果为:
Sequential((conv1): Conv2d(1, 20, kernel_size=(5, 5), stride=(1, 1))(relu1): ReLU()(conv2): Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1))(relu2): ReLU()
)
Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1))
'''注意:从上面的结果中可以看出,这个时候每一个层都有了自己的名称,但是此时需要注意,我并不能够通过名称直接获取层,依然只能通过索引index,即
model[2] 是正确的
model["conv2"] 是错误的
而对于其在具体项目中的运用方式,也是差不多的。代码如下:
class LeNetSequentialOrderDict(nn.Module):def __init__(self, classes):super(LeNetSequentialOrderDict, self).__init__()self.features = nn.Sequential(OrderedDict({'conv1': nn.Conv2d(3, 6, 5),'relu1': nn.ReLU(inplace=True),'pool1': nn.MaxPool2d(kernel_size=2, stride=2),'conv2': nn.Conv2d(6, 16, 5),'relu2': nn.ReLU(inplace=True),'pool2': nn.MaxPool2d(kernel_size=2, stride=2),}))self.classifier = nn.Sequential(OrderedDict({'fc1': nn.Linear(16*5*5, 120),'relu3': nn.ReLU(),'fc2': nn.Linear(120, 84),'relu4': nn.ReLU(inplace=True),'fc3': nn.Linear(84, classes),}))def forward(self, x):x = self.features(x)x = x.view(x.size()[0], -1)x = self.classifier(x)return x二、损失函数与优化函数
1.损失函数
代码如下(示例):
criterion = nn.CrossEntropyLoss() # 提前选择好合适的损失函数# 以下三行用于数据集的循环中对以每一个batch为单位进行的操作
optimizer.zero_grad() # 用于清除现有梯度值,防止在循环中不断和之前计算得出的梯度累加
loss = criterion(outputs, labels) # 根据计算得出的outputs和已知的labels计算loss
loss.backward() # 调用backward函数,便于下一步的优化
2.优化函数
代码如下(示例):
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略+# update weights 用在每一轮数据集中的每一个batch中
optimizer.step()# 在每轮数据集结束时使用
scheduler.step() # 更新学习率- lr- 学习率
- step_size(int)- 学习率下降间隔数,若为 30,则会在 30、 60、 90…个 step 时,将学习率调整为 lr*gamma。(step 通常是指 epoch)
- gamma(float)- 学习率调整倍数,默认为 0.1 倍,即下降 10 倍。
三、具体组合实现功能的流程
参数设定
# 参数设置
MAX_EPOCH = 3 # 数据模块
BATCH_SIZE = 5 # 数据模块
LR = 0.01 # 学习率
log_interval = 10 # 用于在循环中的特定轮次打印训练信息
val_interval = 1 # 用于每轮数据集结束后进行验证集的测试数据部分的实例化
注意:(详细内容参考之前我发的博客)
split_dir = os.path.join(".", "RMB_data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]train_transform = transforms.Compose([transforms.Resize((32, 32)),transforms.RandomCrop(32, padding=4),transforms.ToTensor(),transforms.Normalize(norm_mean, norm_std),
])valid_transform = transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(),transforms.Normalize(norm_mean, norm_std),
])# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
循环训练部分
代码如下,注释部分已经写得超级详细了,应该不存在看不懂的情况了
for epoch in range(MAX_EPOCH): # MAX_EPOCH:数据集循环的最大轮数loss_mean = 0. # 平均损失值correct = 0. # 正确识别的次数total = 0. # 总共进行了几次识别net.train() # 反正就是每次数据集训练前必须加上for i, data in enumerate(train_loader): # train_loader里面存放了所有的数据集信息# enumerate(train_loader)则表示存放了几 组batch(36组,每组5张图片的信息)和具 体图片信息的列表集合# forwardinputs, labels = data # data里存放了enumerate(train_loader)中 的36组图片信息(数据和标签)分别赋给 inputs和labels outputs = net(inputs) # 将数据集代入模型,outputs中为5个集合, (因为一个batch包含5张图) 每个集合中有2个数据(对应图片为1元或者 100元的概率)# backwardoptimizer.zero_grad()loss = criterion(outputs, labels)loss.backward()# update weightsoptimizer.step() # 根据backward返回的梯度改变对图片每个点 的权重(输入模型的为3层32*32的图片信 息)# 统计分类情况_, predicted = torch.max(outputs.data, 1) # predicted为一个集合,存有5张图片对应种 类(根据outputs集合中的每个集合里的2个 概率的数值谁更大),_存放了一些相应数 据,但不需要管total += labels.size(0) # 累加得出一共识别了几张图片correct += (predicted == labels).squeeze().sum().numpy()# 累加得出一共正确识别了几张图片# 打印训练信息loss_mean += loss.item() # 累加loss的值,用于之后求loss的平均值train_curve.append(loss.item())if (i+1) % log_interval == 0: # 每当进行了10个batch后输出训练信息loss_mean = loss_mean / log_intervalprint("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))loss_mean = 0. # len(train_loader):训练集中共有36个 batchcorrect / total:表示正确率scheduler.step() # 更新学习率# 每轮训练集结束后进行验证集测试 if (epoch+1) % val_interval == 0:correct_val = 0.total_val = 0.loss_val = 0.net.eval() # 跟上面的net.train()差不多,必须要加上with torch.no_grad(): # 验证集不需要返回梯度# 循环部分跟上面内容差不多for j, data in enumerate(valid_loader): inputs, labels = dataoutputs = net(inputs)loss = criterion(outputs, labels)_, predicted = torch.max(outputs.data, 1)total_val += labels.size(0)correct_val += (predicted == labels).squeeze().sum().numpy()loss_val += loss.item()valid_curve.append(loss_val)print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val, correct / total))四.运行结果展示
代码如下:
train_x = range(len(train_curve)) # 总共识别的batch数目train_y = train_curve # 存放的每个batch对应的loss的平均值train_iters = len(train_loader) # 点对应的数目plt.plot(train_x, train_y, label='Train') plt.legend(loc='upper right')
plt.ylabel('Loss') # 设定纵坐标名称
plt.xlabel('batch') # 设定横坐标名称
plt.show()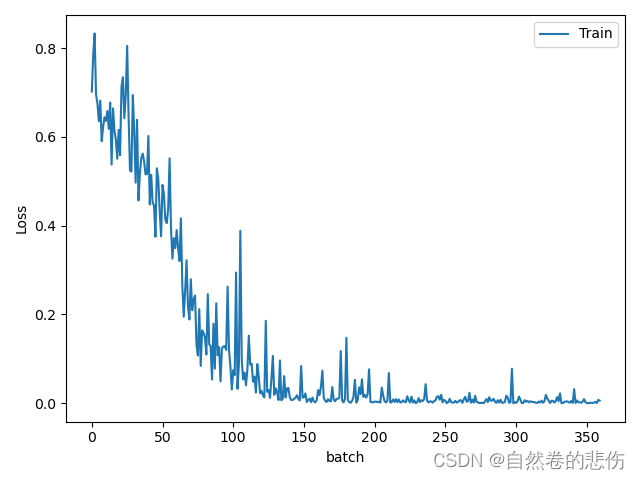
总结
这一周已经成功过了一遍RMB识别这个简单的项目,了解了整体流程主干和大致代码内容(类,函数起到的功能所需要的输入内容,输出内容的含义和格式等等),接下来会学习fgsm相关的知识,并结合该项目进行实践。
这篇关于《超详细》小白如何用pycharm进行RMB识别(含模型建立,损失函数,优化函数与具体组合实现功能的具体流程)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








