本文主要是介绍基于BERT和双向LSTM的微博评论倾向性分析研究-笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
14天阅读挑战赛
努力是为了不平庸~
基于BERT和双向LSTM的微博评论倾向性分析研究-笔记
一、模型介绍
针对传统语言模型在词向量表示中无法解决词语 多义性的问题,提出采用BERT模型来提取微博评论文本的语义特征表示,然后将获取的词语语义特征输入到双向LSTM模型中进行倾向性分类。
选取新浪微博评论数据进行了对比实验。实验结果表明,提出的基于BERT和双向LSTM的微博评论倾向性分类模型的F1值达到91.45%,优于其他主流的倾向性分析模型,证明了方法的有效性。
[局限] 双向 LSTM 模型训练的计算复杂度较高,BERT模型只能依赖于谷歌发布的预训练模型。
文本语义表示方法从最初的 One-Hot 表示法发展到当 前主流的 Word2Vec、Glove 等基于神经网络的方法,虽然在一定程度上解决了词语上下文关系的问题,但还没有解 决词语在不同语境下具有不同含义这个多义词问题。本文提出利用BERT作为语言特征提取与表示方法,既能获取 微博评论文本的丰富的语法、语义特征,又能解决传统基 于神经网络结构的语言特征表示方法忽略词语多义性的问题。
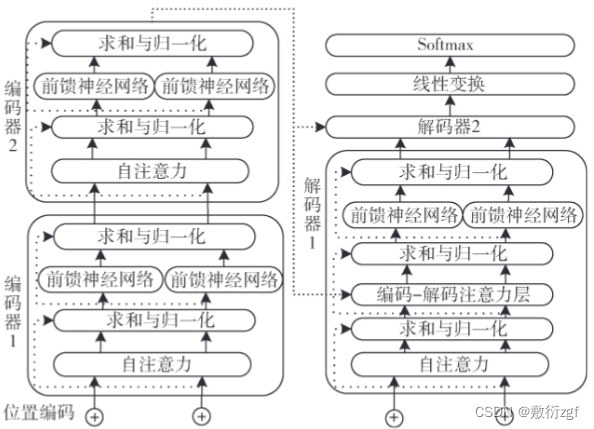
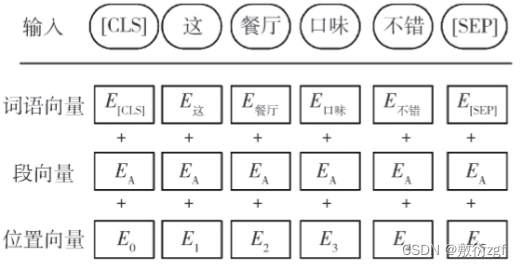
BERT在预训练目标函数时采用遮蔽语言模型(Masked Language Model,MLM),随机遮蔽一些词语,再在预训练过程中对其进行预测,这样可以学习到能够融合两个不同方向文本的表征。对于BERT模型的输入,每一个词语的表示都有词语向量(Token E吗beddings)、段向量(Segment Embeddings)和位置向量(Positional Embeddings)相加产生。
首先对数据进行预处理,完成数据集的预处理。 接着将训练集和验证集数据使用 BERT 模型进行预训练, 预训练过程中会在输入词序列中随机遮蔽 15% 的词,然 后再对被遮蔽的词进行预测,而被遮蔽的词 80% 的时间 用 [MASK] 替换,10% 的时间用随机词替换,10% 的时 间让选择的词不变,这样更能偏向实际观察到的词。除此 之外,预训练时还会进行下一句预测任务。在完成预训练 任务之后,便可以获取 BERT 模型对输入句子的表示,即 获取 BERT 模型的最后一层作为双向 LSTM 模型的特征输 入,并在双向 LSTM 后接上一个全连接层,并对全连接层 采用 Softmax 函数实现分类。在建模完成后,利用测试集 数据进行文本倾向性分析预测,最后采用 F1 值评价模型的性能。
二、实验介绍
作者将BERT-BLSTM模型与
1.baseline:利用BERT模型在语料库上预训练得到文本特征后,通过一个全连接层直接输入到 Softmax 分类器中;
2.Word2Vec-BLSTM: 将输入句子采用 Word2Vec 训练出词向量表示,并将其作为特征输入到 BLSTM 中进行分类;
3.EC-BLSTM: 利用注意力机制改进输入词向量来增强倾向性信息的学习,再输入到 BLSTM中进行语义信息的学习,最后实现分类;
4.ELMo-BLSTM: 将输入句子采用ELMo训练出词语特征向量后,将其输入到BLSTM 中进行分类;
5.GPT-BLSTM: 采用 OpenAI GPT 对输入句子进 行训练得到新的表示后,输入到 BLSTM 中进行分类;
6.BERT-SVM: 利用BERT预训练得到文本特征表示 之后输入到 SVM 中进行分类;7.BERT-RNN: 利用BERT预训练得到文本特征表示 之后输入到RNN 中完成特征训练及分类;
8.BERT-CNN: 利用BERT预训练得到文本特征表示 之后输入到CNN 中完成特征训练及分类。
这八类模型进行详细的对比,最终BERT-BLSTM模型获得最高的准确率、召回率和F1值。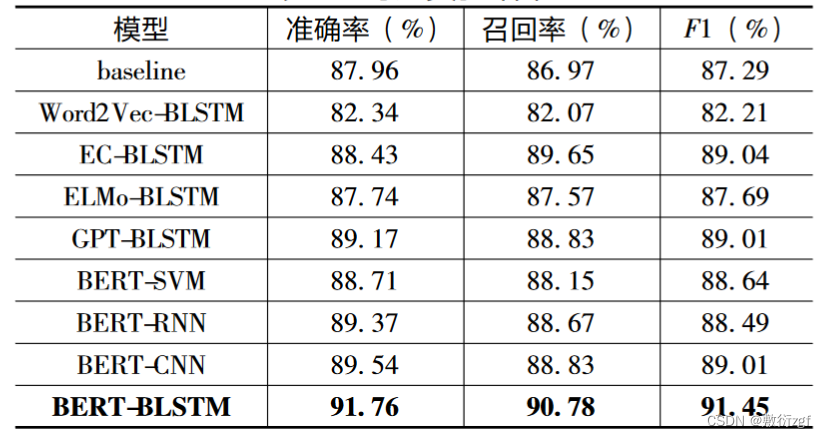
三、缺陷和局限
本文方法也存在一 定的问题,一个是双向 LSTM 模型训练的计算复杂度较高,另一个是BERT模型复现比较困难,只能依赖于谷歌团队发布的预训练模型。在今后的工作中将针对这些问题 进行改进,以期获得更高效的倾向性分析模型。
这篇关于基于BERT和双向LSTM的微博评论倾向性分析研究-笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





