选自DeepMind
机器之心编译
在今年五月击败柯洁之后,AlphaGo 并没有停止自己的发展。昨天,DeepMind 在《自然》杂志上发表了一篇论文,正式推出 AlphaGo Zero——人工智能围棋程序的最新版本。据称,这一版本的 AlphaGo 无需任何人类知识标注,在历时三天,数百万盘的自我对抗之后,它可以轻松地以 100 比 0 的成绩击败李世乭版本的AlphaGo。DeepMind 创始人哈萨比斯表示:「Zero 是迄今为止最强大,最具效率,最有通用性的 AlphaGo 版本——我们将见证这项技术很快应用到其他领域当中。」
人工智能研究已经在多个领域取得飞速进展,从语音识别、图像分类到基因组学和药物研发。在很多情况下,这些是利用大量人类专业知识和数据的专家系统。
但是,人类知识成本太高,未必可靠,或者只是很难获取。因此,AI 研究的一个长久目标就是跨国这一步,创建在最有难度的领域中无需人类输入就能达到超人性能的算法。在我们最近发表在 Nature 上的论文中,我们展示了通往该目标的关键一步。
这篇文章介绍了 AlphaGo Zero,AlphaGo 的最新版本。AlphaGo 曾打败围棋世界冠军,Zero 甚至更强大,可以说是历史上最强的围棋选手。
之前的 AlphaGo 版本首先基于数千场人类围棋比赛来训练如何学习围棋。但 AlphaGo Zero 跳过了这一步,从自己完全随机的下围棋开始来学习围棋。通过这种方式,它快速超越了人类棋手的水平,并且以 100:0 的比分打败了之前战胜世界冠军的 AlphaGo。
AlphaGo Zero 利用新型强化学习完成这样的壮举,在训练过程中它是自己的老师。该系统的神经网络最初对围棋一无所知,然后它通过将该神经网络与强大的搜索算法结合进行自我对弈。神经网络在下棋过程中得到调整和更新,来预测棋招和比赛的最终胜者。
更新后的神经网络重新与搜索算法连接,创建新的更强大的 AlphaGo Zero,然后重复上述流程。每次迭代中,系统的性能取得小幅上升,自我对弈的比赛质量不断上升,带来更加准确的神经网络和历史最强的 AlphaGo Zero 版本。
这项技术比起前几个版本的 AlphaGo 更加强大,因为它不再受人类知识极限的约束。相反,它从一张白纸的状态开始,和世界最强的围棋选手 AlphaGo(它自己)学习下棋。
它与之前的版本在以下几个方面存在差异:
- AlphaGo Zero 只需要围棋棋盘中的黑子和白子作为输入,而前几个版本的 AlphaGo 还包括少量手工设计的特征。
- 它只有一个神经网络,而再不是两个。早期几个版本的 AlphaGo 使用「决策网络」选择下一步棋的位置,使用「价值网络」预测每一个位置上决定的胜者。这两个网络在 AlphaGo Zero 中被结合起来,从而使其更高效地训练和评估赛况。
- AlphaGo Zero 不使用「rollouts」(其它围棋程序使用的快速、随机的下棋方式,以从当前的棋盘位置分布预测哪一个棋手会赢),取而代之,它依靠其优质的神经网络评估下棋位置。
所有这些区别都有助于提高系统的性能,并使其更加一般化,然而算法上的变化才是系统更加强大和高效的重要原因。
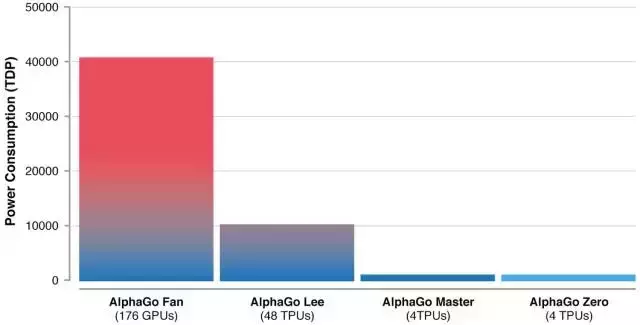
由于硬件和算法的进步才使得 AlphaGo 能持续地变得越来越高效——Zero 版本只需 4 块 TPU 即可运行。
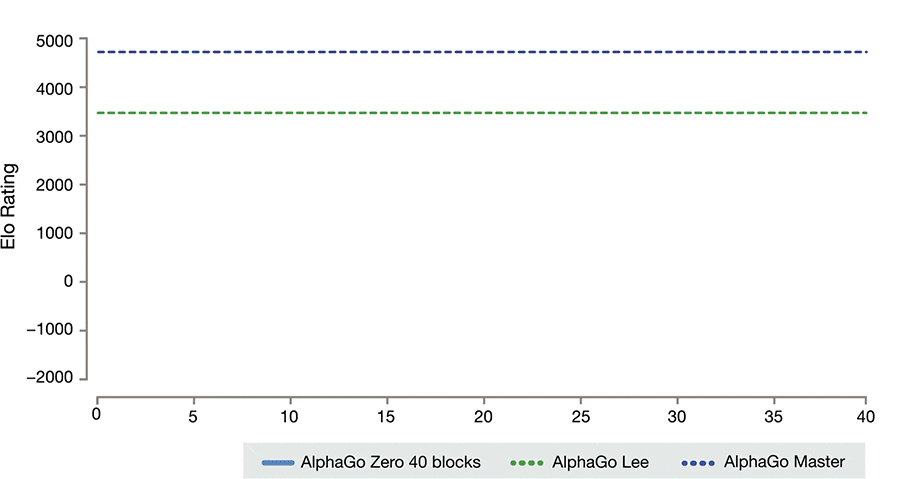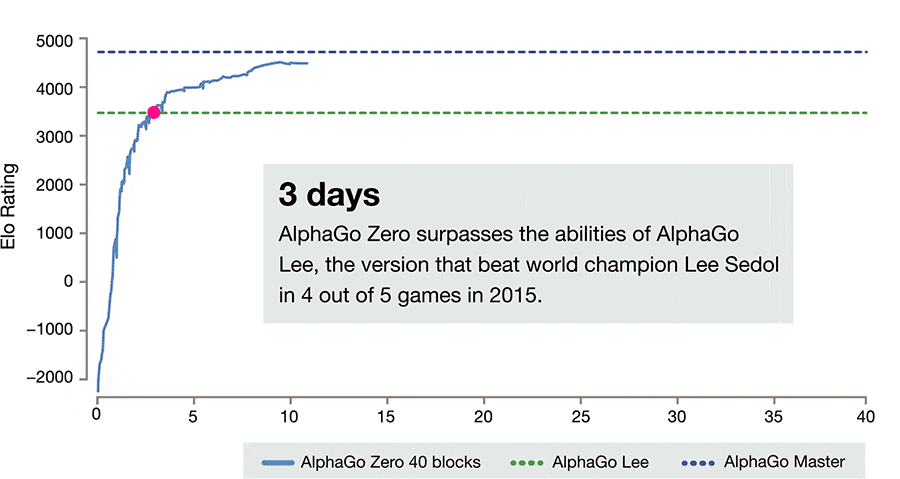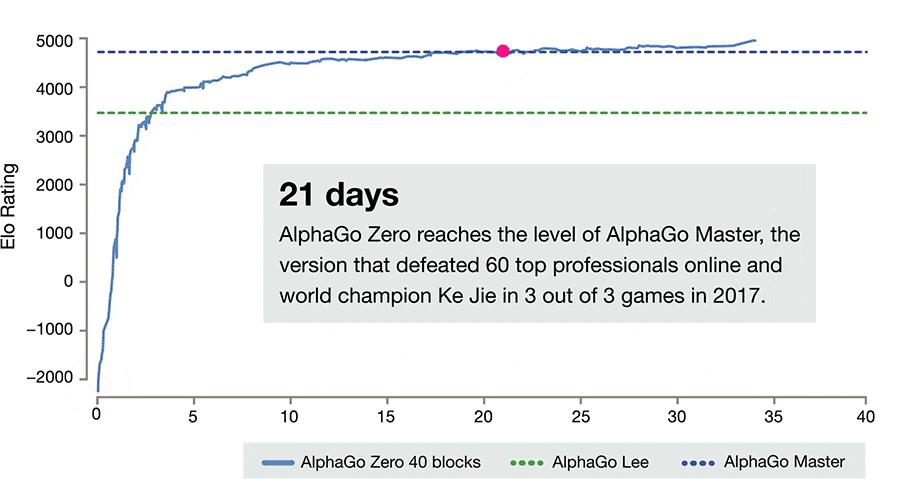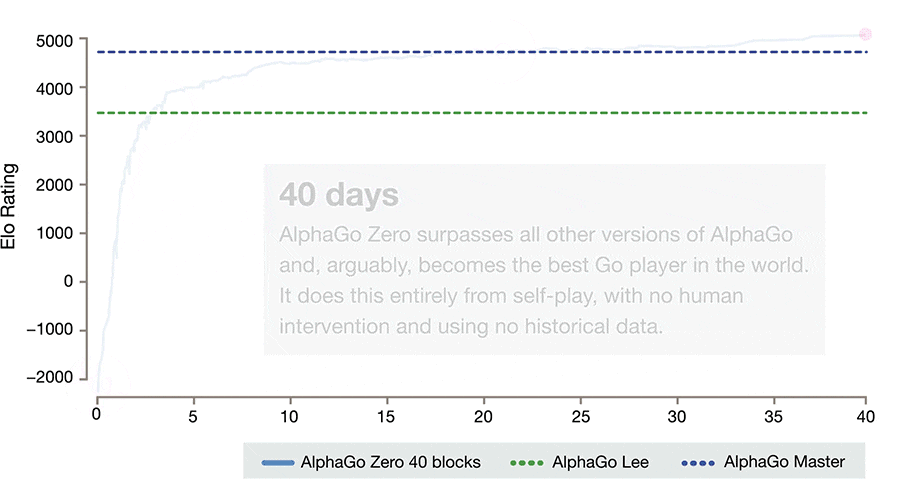
仅仅经过三天的自我对抗训练,AlphaGo Zero很干脆地以100:0的战绩打败了之前的AlphaGo版本(它曾18次击败世界冠军李世石)。又经过40天的自我对抗训练,AlphaGo Zero变得更加强大,甚至优于打败世界头号选手柯洁的AlphaGo版本「Master」。
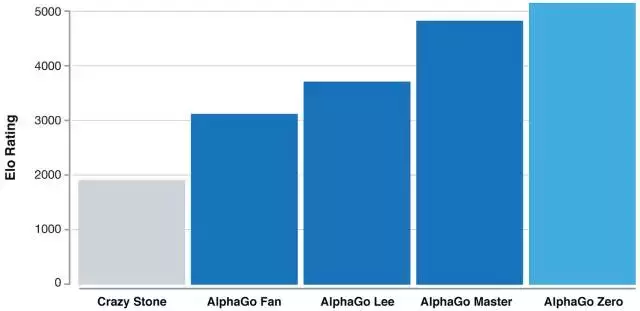
等级分排名(在围棋等竞争性比赛中对选手的相关技巧的水平的度量):显示 AlphaGo 如何在发展过程中逐渐变得强大。
在几百万盘 AlphaGo 自我博弈的竞赛之后,系统在尝试中逐渐学会了围棋游戏,在短短几天内积累了人类数千年的知识。AlphaGo Zero 同时还发现了新的知识,发展出非常规和具有创意性的下法,这些技术已经超越了此前 AlphaGo 与李世石和柯洁对弈时展现的水平。

AlphaGo 展现的创造力让我们有理由相信人工智能将会成为人类智慧的放大器,帮助我们实现自己的使命,去解决人类面临的最具挑战的问题。
尽管 AlphaGo Zero 仍然在发展初期,但是它完成了通向该目标的关键一步。如果类似的技术可以应用到蛋白质折叠等其他结构化问题中,减少能量消耗或搜索最新的材料,则它带来的突破有可能给整个社会带来积极的影响。
论文:Mastering the game of Go without human knowledge

论文地址:https://deepmind.com/documents/119/agz_unformatted_nature.pdf
长期以来,人工智能有一个目标就是算法能够在难度较高的领域从零开始学得超人的性能。近期,AlphaGo 成为在围棋领域第一个打败人类世界冠军的程序。AlphaGo 中的树搜索使用深度神经网络评估位置,选择棋招。这些神经网络通过监督学习从人类专家的棋招中学习,然后通过强化学习进行自我对弈。本文,我们介绍一种算法,该算法仅依靠强化学习,不使用游戏规则以外的人类数据、指导或领域知识。AlphaGo 成为自己的老师:我们训练一种神经网络来预测 AlphaGo 的下一步以及 AlphaGo 游戏的获胜者。该神经网络提升树搜索的能力,带来下一次迭代中更高质量的棋招选择和更强大的自我对弈。新程序 AlphaGo Zero 从头开始学习,并达到了超人的性能,以 100-0 的比分打败曾经战胜人类世界冠军的 AlphaGo。
AlphaGo Zero 所采用的神经网络是一种新颖的强化学习算法,即自我对抗(self-play)的竞争性训练。此前,OpenAI 曾发表论文表示自我对抗训练可以在简单环境下产生远超环境复杂度的行为。而这一次 AlphaGo Zero 和此前 AlphaGo Fan 与 AlphaGo Lee 的很大区别就是采用了这种自我对抗式的训练策略。

图 1:AlphaGo Zero 中的自我对抗强化学习
a:AlphaGo Zero 和自己进行 s_1,...,s_T 对弈。在每一个位置 s_t 处使用最新的神经网络 f_θ执行蒙特卡罗树搜索(MCTS)α_θ(见图 2)。根据 MCTS 计算的搜索概率选择棋招(a_t ∼ π_t)。最终位置 s_T 的得分根据游戏规则计算,进而计算游戏获胜者 z。b: AlphaGo Zero 中的神经网络训练。神经网络使用原始棋盘位置 s_t 作为输入,使用参数θ将其传播通过多个卷积层,然后输出代表棋招概率分布的向量 p_t,和代表当前选手在 s_t 获胜的概率标量值 v_t。神经网络的参数θ得到更新以最大化策略向量 p_t 和搜索概率π_t 的相似性,并将预测获胜者 v_t 和获胜者 z 之间的误差最小化(见公式 1)。新的参数将在下一次迭代的自我对抗中使用。
根据神经网络 f_θ,在每一个位置 s 处执行 MCTS 搜索。
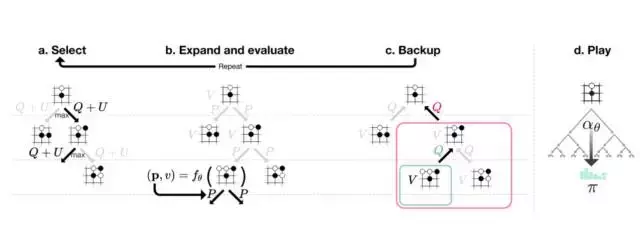
图2:AlphaGo Zero中的MCTS。
a:每一次模拟通过选择最大化行动价值Q的边来遍历整棵树,加上上面的(依赖于一个已储存的先验概率P)置信边界U,并访问边的总数N(每遍历一次增加1)。
b,叶结点得到扩展,并且相关的位置由神经网络 (P(s, ·),V(s)) = f_θ(s)评估;P值的向量存储在s的外向边(outgoing edges)中。
c,行动价值Q被更新以追踪当前行动下的子树的所有评估V的平均值。
d,一旦搜索完成,会返回搜索概率值(search probabilities)π,和N^(1/τ)成比例,其中N是每一次行动自根状态(root state)以来的访问总数,τ是控制温度(temperature)的参数。

原文链接:https://deepmind.com/blog/alphago-zero-learning-scratch/







