本文主要是介绍Task-oriented Dialogue System for Automatic Disease Diagnosis via Hierarchical RL翻译,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
在本文中,我们专注于在面向任务的对话环境中使用加强学习(RL)方法来学习自动疾病诊断。与常规的RL任务不同,疾病诊断的动作空间(例如,症状)很大,尤其是当疾病数量增加时。但是,现有的方法针对该问题采用了一个flat RL策略,该策略通常在简单任务中效果表现很好,但在诸如疾病诊断之类的复杂情况下面临重大挑战。为此,我们提出将一个两级分层策略整合到对话策略学习中。高级策略由一个名为master的模型组成,该模型负责触发低级策略的模型,低级策略由若干症状检查器和疾病分类器组成。与现有系统相比,在真实世界数据集和合成数据集上的实验结果表明,我们的分层框架在疾病诊断方面的准确性更高。此外,数据集和代码都开源可用,https://github.com/nnbay/MeicalChatbot-HRL。
1.介绍
随着电子健康记录(EHRS)系统的发展,研究员探索了用于自动诊断的不同机器学习方法。尽管已经有工作报道了针对各种疾病识别的令人印象深刻的结果,但它们主要依赖于EHR的构建,这会耗费大量人力。此外,针对一种疾病进行的有监督训练的模型很难迁移到另外一种疾病,因此,每种疾病都需要一个独立的EHR。
为了减轻构建EHR的压力,研究人员引入了面向任务的对话系统,以自动从患者处请求症状,然后进行疾病诊断。他们将任务看作是马尔可夫决策过程(MDP),并采用了基于强化学习(RL)的方法来进行系统的策略学习。现有框架利用了一种 flat policy的方式,即将所有的疾病和症状都看作是动作。尽管基于RL的方法对症状的收集显示了积极的结果,但是当涉及到实际环境中数百种疾病时,flat policy的方式是不切实际的。
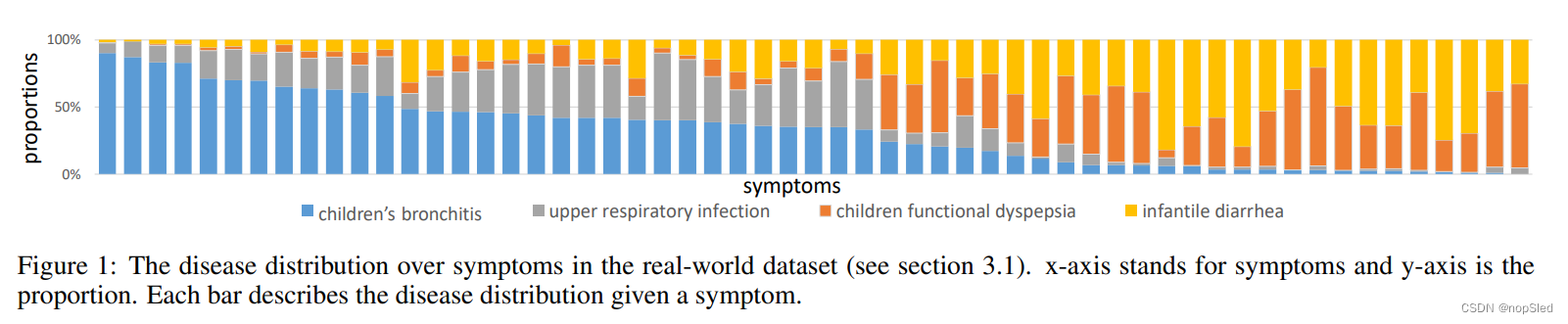
通常,特定的疾病与某些症状有关。也就是说,患病的人通常会同时具有一些对应的症状。如图1所示,我们展示了疾病和症状之间的相关性。x轴代表症状,y轴是相关疾病的比例。我们可以轻松看到一些模式。换句话说,每种疾病都有一组相应的症状,不同症状组之间的重叠是有限的。这促使我们按医院部门的设置,将疾病分为不同的组,并设计症状获取和疾病诊断的分层结构。
最近,分层强化学习(HRL)(通过训练多层策略以执行决策),已成功应用于不同的场景,包括课程推荐,视觉对话,关系提取等。目标任务的自然层次结构是通过手动或自动建模的。受这些研究的启发,我们探索了通过HRL探索疾病的聚类信息,以解决大型动作空间的问题。
在本文中,我们将疾病分为若干组,并建立一个具有两级的分层对话系统,通过使用HRL方法进行自动疾病诊断。高级策略由一个名为master的模型组成,低级策略由若干worker和一个疾病分类器组成。master负责触发低级模型。每个worker负责查询与某些疾病有关的症状,而疾病分类器负责根据worker收集的信息进行最终诊断。所提出的框架模仿了来自不同部门的医生,一起对患者进行诊断。其中,每个worker的动作就像是来自特定部门的医生,而master的行为就像一个任命医生与该患者互动的委员会。当从worker那里收集的信息足够时,master将激活单独的疾病分类器以进行诊断。两个级别的模型共同训练,以更好地诊断疾病。我们构建了一个大型真实数据集和一个合成数据集,以评估我们的模型。实验结果表明,我们的分层框架的性能在两个数据集上都要优于目前最好的方法。
2.Hierarchical Reinforcement Learning Framework for Disease Diagnosis
在本节中,我们介绍了用于疾病诊断的分层强化学习框架。我们从flat policy设置开始,然后从两个级别介绍我们的分层结构策略。我们通过奖赏设计技术进一步提高模型的性能。
2.1 Reinforcement Learning Formulation for Disease Diagnosis
对于基于RL的自动诊断模型,agent的动作空间为 A = D ∪ S \mathcal A=D\cup S A=D∪S,其中 D D D是所有疾病的集合和 S S S是与这些疾病有关的所有症状的集合。在第 t t t轮时,给定状态 s t ∈ S s_t∈\mathcal S st∈S,agent根据其策略 a t 〜 π ( a ∣ s t ) a_t〜π(a|s_t) at〜π(a∣st)来选择动作,并从环境(患者/用户)接收中间奖赏 r t = R ( s t , a t ) r_t=R(s_t,a_t) rt=R(st,at)。如果 a t ∈ S a_t\in S at∈S,那么agent会选择一个症状来询问患者或用户。然后,用户以 t r u e / f a l s e / u n k n o w n true/false/unknown true/false/unknown来响应agent,并表示为对应症状的3维one-hot向量 b ∈ R 3 b\in \mathbb R^3 b∈R3。如果 a t ∈ D a_t\in D at∈D,那么agent将对应疾病作为诊断结果告知用户,并且对话过程将因诊断的success/fail而被终止。状态被表示为 s t = [ b 1 T , b 2 T , ⋅ ⋅ ⋅ , b ∣ S ∣ T ] s_t=[b^T_1,b^T_2,···,b^T_{|S|}] st=[b1T,b2T,⋅⋅⋅,b∣S∣T],即,由每种症状的3维one-hot编码拼接得到,对于没被提及的症状则表示为 b = [ 0 , 0 , 0 ] b=[0,0,0] b=[0,0,0]。
agent的目标是找到最优策略,以便它可以获取到最大化的期望累积衰减奖赏 R t = ∑ t ′ = t T γ t ′ − t r t ′ R_t=\sum^T_{t'=t}γ^{t'-t}r'_t Rt=∑t′=tTγt′−trt′,其中 γ ∈ [ 0 , 1 ] γ∈[0,1] γ∈[0,1]是衰减因子, T T T是当前对话的最大轮次。 Q − v a l u e Q-value Q−value函数是在状态 s s s时基于策略 π π π来选择动作 a a a的期望价值,如下所示:
Q π ( s , a ) = E [ R t ∣ s t = s , a t = a , π ] Q^{\pi}(s,a)=\mathbb E[R_t|s_t=s,a_t=a,\pi] Qπ(s,a)=E[Rt∣st=s,at=a,π]
最优 Q − v a l u e Q-value Q−value函数是所有可能策略中的最大Q值: Q ∗ ( s , a ) = m a x π Q π ( s , a ) Q^∗(s,a)=max_πQ^π(s,a) Q∗(s,a)=maxπQπ(s,a)。它遵循贝尔曼方程:
Q ∗ ( s , a ) = E s ′ [ r + γ m a x a ′ ∈ A Q ∗ ( s ′ , a ′ ) ∣ s , a ] Q^*(s,a)=\mathbb E_{s'}[r+\gamma~\mathop{max}\limits_{a'\in \mathcal A}Q^*(s',a')|s,a] Q∗(s,a)=Es′[r+γ a′∈AmaxQ∗(s′,a′)∣s,a]
当且仅当对于每个状态和动作,满足 Q π ( s , a ) = Q ∗ ( s , a ) Q^π(s,a)=Q^∗(s,a) Qπ(s,a)=Q∗(s,a)时,策略π才是最优的。然后可以通过 π ( a ∣ s ) = a r g m a x a ∈ A Q ∗ ( s , a ) π(a|s)=argmax_{a∈\mathcal A}Q∗(s,a) π(a∣s)=argmaxa∈AQ∗(s,a)确定性需要选择的动作。
2.2 Hierarchical Policy of Two Levels
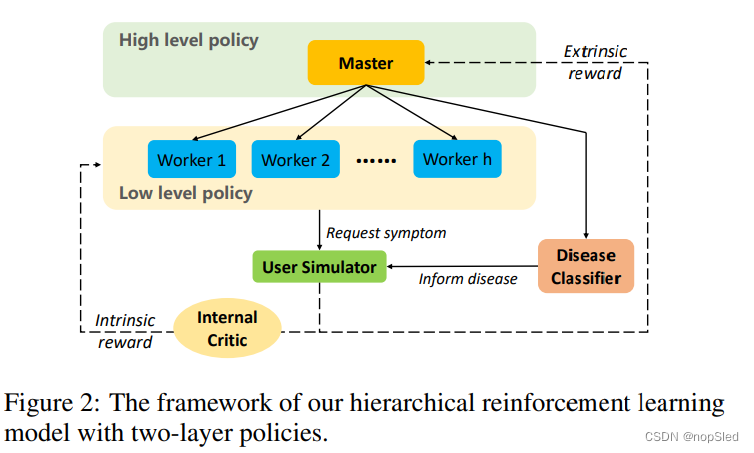
为了减少大型动作空间的问题,我们将上述RL形式扩展到具有两层策略的分层结构,以进行自动诊断。基于options框架,我们的框架的设计如图2所示。该框架中一共有五个组件:master,workers,disease classifier,internal critic和user simulator。
具体而言,我们将 D D D中的所有疾病分为 h h h个子集 D 1 , D 2 , . . . , D h D_1,D_2,...,D_h D1,D2,...,Dh,其中 D 1 ∪ D 2 ∪ ⋅ ⋅ ⋅ ∪ D h = D D_1∪D_2∪···∪D_h=D D1∪D2∪⋅⋅⋅∪Dh=D并且 D i ∩ D j = ∅ D_i∩D_j=∅ Di∩Dj=∅。每个 D i D_i Di都与一组症状 S i ⊆ S S_i\subseteq S Si⊆S有关,其症状与 D i D_i Di中的疾病有关。同时worker w i w^i wi负责从用户收集有关症状 S i S_i Si的信息。
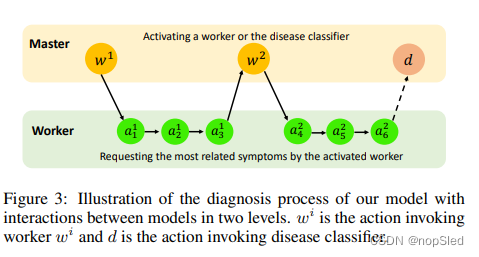
在第 t t t轮,master决定是从用户那里收集症状信息(挑选一个worker与用户交互若干轮),还是告知用户诊断结果(选择疾病分类器以输出预测的疾病)。图3中显示了模型之间相互作用的诊断过程。对于internal criti,它既负责将奖赏返回给worker,又要告诉被调用worker的子任务是否完成。此外,用户模拟器被用于与我们的模型进行交互,并返回外部奖赏。
2.2.1 Master
master的动作空间为 A m = { w i ∣ i = 1 , 2 , ⋅ ⋅ ⋅ , h } ∪ { d } \mathcal A^m=\{w^i|i=1,2,···,h\}∪\{d\} Am={wi∣i=1,2,⋅⋅⋅,h}∪{d}。动作 w i w^i wi表示激活worker w i w^i wi,而 d d d是一个原始动作,表示激活疾病分类器。在每个对话轮次 t t t中,master将对话状态 s t ∈ S s_t∈\mathcal S st∈S作为输入,并根据其策略 π m ( a t m ∣ s t ) π^m(a^m_t|s_t) πm(atm∣st)来选择动作 a t m ∈ A m a^m_t∈\mathcal A^m atm∈Am。外部奖赏 r t e r^e_t rte将从环境中获取并返回给的master。
master的决策过程不是一个标准的MDP。master激活一个worker后,该worker将与用户交互N轮,直到子任务终止。然后,master才能采取新的行动并观察新的对话状态。正如[7]指出的那样,master的学习问题可以作为半马尔可夫决策过程(SMDP)提出,在这种过程中,在用户和所选worker交互期间返回的外部奖赏可以作为master的中间奖赏进行累积。也就是说,在采取动作 a t m a^m_t atm之后,可以将master的奖赏 r t m r^m_t rtm定义为:
r t m = { ∑ t ′ = 1 N γ t ′ r t + t ′ e , i f a t m = w i r t e , i f a t m = d r^m_t= \begin{cases} \sum^N_{t'=1}\gamma^{t'}r^e_{t+t'},& if~ a^m_t=w^i\\ r^e_t,& if~ a^m_t=d \end{cases} rtm={∑t′=1Nγt′rt+t′e,rte,if atm=wiif atm=d
其中 i = 1 , . . . , h i=1,...,h i=1,...,h, r t e r^e_t rte是环境在第 t t t轮返回的外部奖赏, γ γ γ是master的衰减因子, N N N是worker的对话轮次。我们可以将master的Bellman方程写为如下所示:
Q m ( s , a m ) = r m + E { s ′ , a m ′ } [ γ N Q m ( s ′ , a m ′ ) ∣ s , a m , π m ] Q_m(s,a^m)=r^m+\mathbb E_{\{s',a^{m'}\}}[\gamma^NQ_m(s',a^{m'})|s,a^m,\pi^m] Qm(s,am)=rm+E{s′,am′}[γNQm(s′,am′)∣s,am,πm]
其中 s ′ s' s′是master采取动作后观察到的对话状态, a m ′ a^{m'} am′是状态为 s ′ s' s′时的下一个动作。
master的目标是通过SMDP来最大化外部奖赏,因此我们可以按以下方式写出master的损失函数:
L ( θ m ) = E s , a m , r m , s ′ ∼ B m [ ( y − Q m ( s , a m ; θ m ) ) 2 ] \mathcal L(\theta_m)=\mathbb E_{s,a^m,r^m,s'\sim \mathcal B^m}[(y-Q_m(s,a^m;\theta_m))^2] L(θm)=Es,am,rm,s′∼Bm[(y−Qm(s,am;θm))2]
其中 y = r m + γ N m a x a m ′ Q m ( s ′ , a m ′ ; θ m − ) y=r^m+γ^Nmax_{a^{m'}}Q_m(s',a^{m'};θ^-_m) y=rm+γNmaxam′Qm(s′,am′;θm−), θ m θ_m θm是当前迭代的网络参数, θ m − θ^-_m θm−是上一次迭代的网络参数,而 B m \mathcal B^m Bm是从master的固定缓冲区中采样的。
2.2.2 Worker
worker w i w^i wi对应于疾病 D i D_i Di和症状 S i S_i Si集合。worker w i w^i wi的动作空间为: A i w = { r e q u e s t ( s y m p t o m ) ∣ s y m p t o m ∈ S i } \mathcal A^w_i=\{request(symptom)|symptom∈S_i\} Aiw={request(symptom)∣symptom∈Si}。在第 t t t轮,如果调用了worker w i w^i wi,master的当前状态 s t s_t st将传递给worker w i w^i wi,然后worker w i w^i wi将从 s t s_t st中提取 s t i s^i_t sti并以 s t i s^i_t sti作为输入来生成动作 a t i ∈ A w i a^i_t∈\mathcal A^{w^i} ati∈Awi。状态提取函数如下所示:
s t i = E x t r a c t S t a t e ( s t , w i ) = [ b ( 1 ) i T , b ( 2 ) i T , . . . , b ( k i ) i T ] T s^i_t=ExtractState(s_t,w^i)=[b^{iT}_{(1)},b^{iT}_{(2)},...,b^{iT}_{(k_i)}]^T sti=ExtractState(st,wi)=[b(1)iT,b(2)iT,...,b(ki)iT]T
其中 b ( j ) i b^{i}_{(j)} b(j)i是症状 j j j的表示向量。
在选择行动 a t i ∈ A w i a^i_t∈\mathcal A^{w^i} ati∈Awi之后,对话被更新为 s t + 1 s_{t+1} st+1,worker w i w^i wi将从 internal critic 模块中获得固定奖赏 r t i r^i_t rti。因此,worker的目的是最大化期望累积的内部衰减奖赏。worker w i w^i wi的损失函数可以写为:
L ( θ w i ) = E s i , a i , r i , s i ′ ∼ B i w [ ( y i − Q w i ( s i , a i ; θ w i ) ) 2 ] \mathcal L(\theta^i_w)=\mathbb E_{s^i,a^i,r^i,s^{i'}\sim \mathcal B^w_i}[(y_i-Q^i_w(s^i,a^i;\theta^i_w))^2] L(θwi)=Esi,ai,ri,si′∼Biw[(yi−Qwi(si,ai;θwi))2]
其中 y i = r i + γ w m a x a i ′ Q w i ( s i ′ , a i ′ ; θ w i − ) y_i=r^i+γ_wmax_{a^{i'}} Q^i_w(s^{i'},a^{i'};θ^{i-}_w) yi=ri+γwmaxai′Qwi(si′,ai′;θwi−), γ w γ_w γw是worker的衰减因子, θ w i θ^i_w θwi是当前迭代时的网络参数, θ w i − θ^{i-}_w θwi−是上一次迭代的网络参数, B i w \mathcal B^w_i Biw是worker w i w^i wi样本的固定长度缓冲区。
2.2.3 Disease Classifier
一旦疾病分类器被master激活,它将以主状态 s t s_t st作为输入,并输出向量 p ∈ R ∣ D ∣ \textbf p∈\mathbb R^{|D|} p∈R∣D∣,其表示了在所有疾病上的概率分布。具有最高概率的疾病将作为诊断结果返回给用户。此处使用两层多层感知器(MLP)进行疾病诊断。
2.2.4 Internal Critic
internal critic模块负责在第 t t t轮选择行动 a t i a^i_t ati后,为worker w i w^i wi生成一个固有的奖励 r t i r^i_t rti。如果工人要向用户请求症状,则 r t i r^i_t rti等于 + 1 +1 +1。如果worker w i w^i wi生成了重复的动作或子任务轮数到达 T s u b T^{sub} Tsub,则 r t i r^i_t rti为 − 1 -1 −1。 否则, r t i r^i_t rti为 0 0 0。
internal critic模块还负责判断worker的终止条件。在我们的任务中,当生成了重复的动作或子任务轮数到达 T s u b T^{sub} Tsub,worker被视为失败而终止。当用户对agent请求的症状做出确认响应时,工人被视为成功而终止。这意味着目前的worker通过收集足够的症状信息来完成子任务。
2.2.5 User Simulator
与[4]和[5]类似,我们使用用户模拟器与agent进行交互。在每个对话的开始,用户模拟器随机从训练池中采样了一个用户目标。被采样用户目标的所有显式症状均用于初始化会话。在对话过程中,根据某些规则,模拟器根据用户目标与agent进行交互。如果agent做出正确的诊断,则将作为成功终止对话。如果通知的疾病不正确或对话轮次达到最大轮次 T T T,则将作为失败终止对话。为了提高相互的效率,当系统选择重复动作时,对话将被终止。
2.3 Reward Shaping
实际上,一个患者患有的症状数要比症状集合S中的症状数少的多,这就导致了特征空间稀疏的问题。换句话说,agent很难找到用户真正遭受的症状。为了鼓励master选择一个可以发现更多正确症状的worker,我们采用与[12]类似的方法,使用奖赏设计方法为原始的外部奖赏增加一个额外的辅助奖励,同时保持最优的强化学习策略不变。
从状态 s t s_t st到 s t + 1 s_{t+1} st+1的辅助奖赏函数被定义为 f ( s t , s t + 1 ) = γ ϕ ( s t + 1 ) − ϕ ( S t ) f(s_t,s_{t+1})=γ\phi(s_{t+1})-\phi(S_t) f(st,st+1)=γϕ(st+1)−ϕ(St),其中 ϕ ( s ) \phi(s) ϕ(s)是潜在函数,可以定义为:
ϕ ( s ) = { λ × ∣ { j : b j = [ 1 , 0 , 0 ] } ∣ , i f s ∈ S / S ⊥ 0 , o t h e r w i s e \phi(s)= \begin{cases} \lambda\times |\{j:b_j=[1,0,0]\}|,& if ~ s\in \mathcal S/\mathcal S_{\perp}\\ 0,& otherwise \end{cases} ϕ(s)={λ×∣{j:bj=[1,0,0]}∣,0,if s∈S/S⊥otherwise
其中 ϕ ( s ) \phi(s) ϕ(s)计算给定状态 s s s情况下的确认症状的数目, λ > 0 λ>0 λ>0是一个超参数,控制奖赏设计的大小, S ⊥ \mathcal S_{\perp} S⊥是终止状态集。因此,master的奖励函数将变为 R t ϕ = r t + f ( s t , s t + 1 ) R^{\phi}_t=r_t+f(s_t,s_{t+1}) Rtϕ=rt+f(st,st+1)。
2.4 Training
master策略 π m π^m πm和每个worker的策略 π w i π^{w^i} πwi均通过深度Q网络进行参数化。在DQN中,经常按照 ϵ \epsilon ϵ贪心策略选择动作。在我们的分层结构框架中,master和worker在训练时都采用 ϵ \epsilon ϵ贪心策略选择动作,测试时则使用贪心策略。在训练过程中,我们将 ( s t , a t m , r t m , s t + N ) (s_t,a^m_t,r^m_t,s_{t+N}) (st,atm,rtm,st+N)存储在 B m \mathcal B^m Bm中,并将 ( s t i , a t w , r t i , s t + 1 i ) (s^i_t,a^w_t,r^i_t,s^i_{t+1}) (sti,atw,rti,st+1i)存储在 B w i \mathcal B^{w^i} Bwi中。在每个训练步骤,我们都会执行经验回放,以分别更新master和worker的当前网络,而在经验回放过程中,目标网络是固定的。仅当一次经验回放结束时,目标网络才会更新(由当前网络替换)。在每个步骤中,当前网络将在训练集上进行评估,只有当当前网络的性能优于任何成功率的任何版本时,体验缓冲区才会刷新。因此,以前的迭代中生成的样品将从体验缓冲区中删除,并会加快训练过程。至于疾病分类器,在每10个时期对主人进行培训后,它将使用末端状态和相应的疾病标签进行更新。
3.Dataset
3.1 Real-world Dataset
3.2 Synthetic Dataset
这篇关于Task-oriented Dialogue System for Automatic Disease Diagnosis via Hierarchical RL翻译的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








